Hyper-Text Transfer Protocol
Responding to requests since 1991
Responding to requests since 1991
At the heart of the world wide web is the Hyper-Text Transfer Protocol (HTTP). This is a protocol defining how HTTP servers (which host web pages) interact with HTTP clients (which display web pages).
It starts with a request initiated from the web browser or other client. This request is sent over the Internet using the TCP protocol to a web server. Once the web server receives the request, it must decide the appropriate response - ideally sending the requested resource back to the browser to be displayed. The following diagram displays this typical request-response pattern.
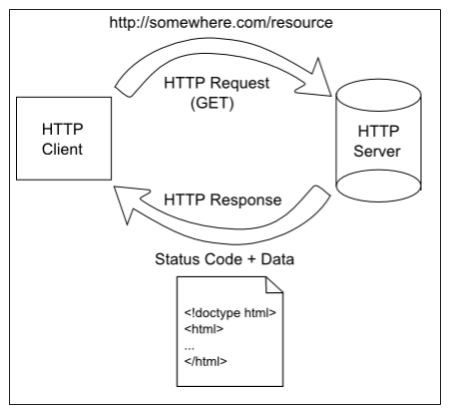
This HTTP request-response pattern is at the core of how all web applications communicate. Even those that use websockets begin with an HTTP request.
The HTTP standard, along with many other web technologies, is maintained by the World-Wide-Web Consortium (abbreviated W3C), stakeholders who create and maintain web standards. The full description of the Hyper-Text Transfer Protocol can be found here w3c’s protocols page.
Before a web request can be made, the browser needs to know where the resource requested can be found. This is the role that a Universal Resource Locator (a URL) plays. A URL is a specific kind of Universal Resource Indicator (URI) that specifies how a specific resource can be retrieved.
URLs and URIs The terms URL and URI are often used interchangeably in practice. However, a URL is a specific subset of URIs that indicate how to retrieve a resource over a network; while a URI identifies a unique resource, it does not necessarily indicate how to retrieve it. For example, a book’s ISBN can be represented as a URI in the form urn:isbn:0130224189. But this URI cannot be put into a browser’s Location to retrieve the associated book.
A URI consists of several parts, according to the definition (elements in brackets are optional):
URI = scheme:[//[userinfo@]host[:port]]path[?query][#fragment]
Let’s break this down into individual parts:
scheme: The scheme refers to the resource is identified and (potentially) accessed. For web development, the primary schemes we deal with are http (hyper-text transfer protocol), https (secure hyper-text transfer protocol), and file (indicating a file opened from the local computer).
userinfo: The userinfo is used to identify a specific user. It consists of a username optionally followed by a colon (:) and password. We will discuss its use in the section on HTTP authentication, but note that this approach is rarely used today, and carries potential security risks.
host: The host consists of either a fully quantified domain name (i.e. google.com, cs.ksu.edu, or gdc.ksu.edu) or an ip address (i.e. 172.217.1.142 or [2607:f8b0:4004:803::200e]). IPv4 addresses must be separated by periods, and IPv6 addresses must be closed in brackets. Additionally, web developers will often use the loopback host, localhost, which refers to the local machine rather than a location on the network.
port: The port refers to the port number on the host machine. If it is not specified (which is typical), the default port for the scheme is assumed: port 80 for HTTP, and port 443 for HTTPS.
path: The path refers to the path to the desired resource on the server. It consists of segments separated by forward slashes (/).
query: The query consists of optional collection of key-value pairs (expressed as key:value), separated by ampersands (&), and proceeded by a question mark (?). The query string is used to supply modifiers to the requested resource (for example, applying a filter or searching for a term).
fragment: The fragment is an optional string proceeded by a hashtag (#). It identifies a portion of the resource to retrieve. It is most often used to auto-scroll to a section of an HTML document, and also for navigation in some single-page web applications.
Thus, the URL https://google.com indicates we want to use the secure HTTP scheme to access the server at google.com using its port 443. This should retrieve Google’s main page.
Similarly, the url https://google.com/search?q=HTML will open a Google search result page for the term HTML (Google uses the key q to identify search terms).
Now that we’ve discussed the request-response pattern and address resolution, let’s turn our attention to how requests are processed in the browser. The following tutorial from Google describes the network panel in Chrome:
YouTube VideoAlso, open the Get Started Demo page it references. (This example is outdated. Feel free to try any other website to test the features )
Or, if you prefer you can work through the written version of the tutorial
Similar developer tools exist in other browsers:
Now that you are familiar with the network panel, let’s explore the primary kind of request you’re already used to making - requests originating from a browser. Every time you use a browser to browse the Internet, you are creating a series of HTTP (or HTTPS) requests that travel across the networks between you and a web server, which responds to your requests.
When you type in an address in your browser (or click a hyperlink), this initiates a HTTP request against the server located at that address. Ideally, the request succeeds, and you are sent the webpage you requested. As the browser parses that webpage, it may also request additional resources linked in that page (such as images, CSS files, and JavaScript files).
To help illustrate how these requests are made, we’ll once again turn to our developer tools. Open the example page this link. On that tab, open your developer tools with CTRL + SHIFT + i or by right-clicking the page and selecting “Inspect” from the context menu. Then choose the “Network” tab:
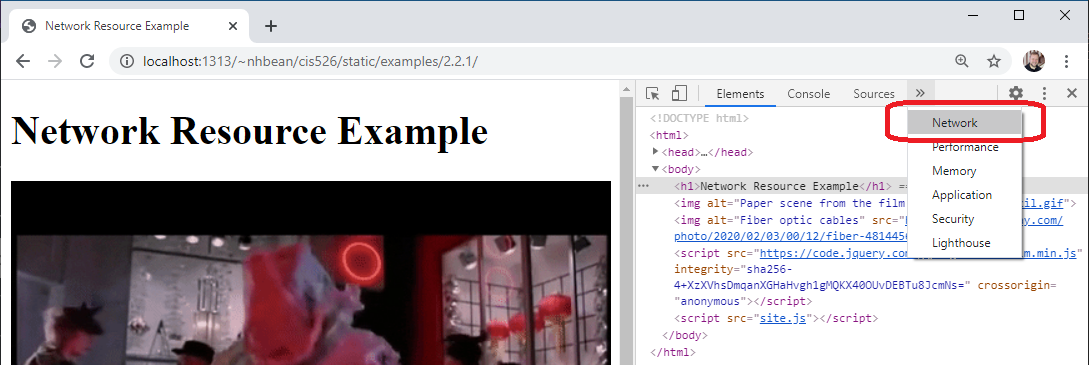
The network tab displays details about each request the browser makes. Initially it will probably be empty, as it does not log requests while not open. Try refreshing the page - you should see it populate with information:
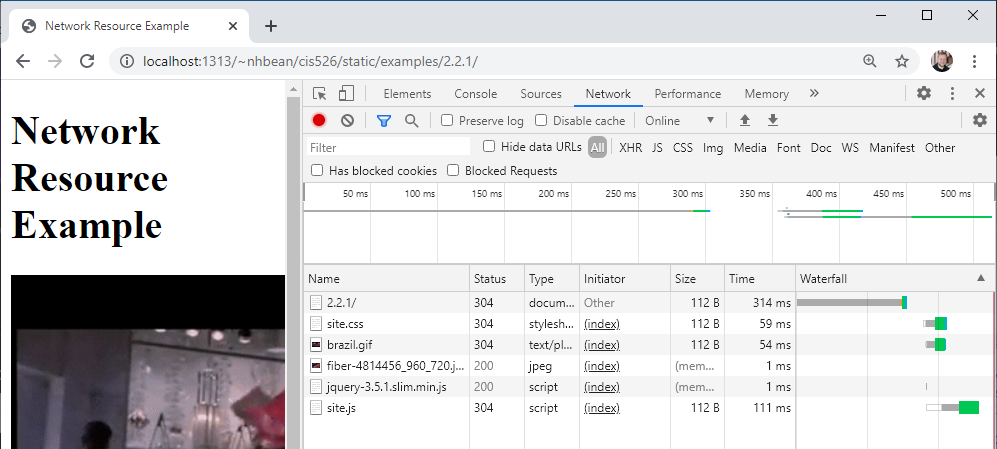
The first entry is the page itself - the HTML file. But then you should see entries for site.css, brazil.gif, fiber-4814456_960_720.jpg, jquery-3.5.1.slim.min.js, and site.js. Each of these entries represents an additional resource the browser fetched from the web in order to display the page.
Take, for example, the two images brazil.gif and fiber-4814456_960_720.jpg. These correspond to <img> tags in the HTML file:
<img alt="Paper scene from the film Brazil" src="brazil.gif"/>
<img alt="Fiber optic cables" src="https://cdn.pixabay.com/photo/2020/02/03/00/12/fiber-4814456_960_720.jpg"/>
The important takeaway here is that the image is requested separately from the HTML file. As the browser reads the page and encounters the <img> tag, it makes an additional request for the resource supplied in its src attribute. When that second request finishes, the downloaded image is added to the web page.
Notice too that while one image was on our webserver, the other is retrieved from Pixabay.com’s server.
You can use the network tab to help debug issues with resources. Click on one of the requested resources, and it will open up details about the request:
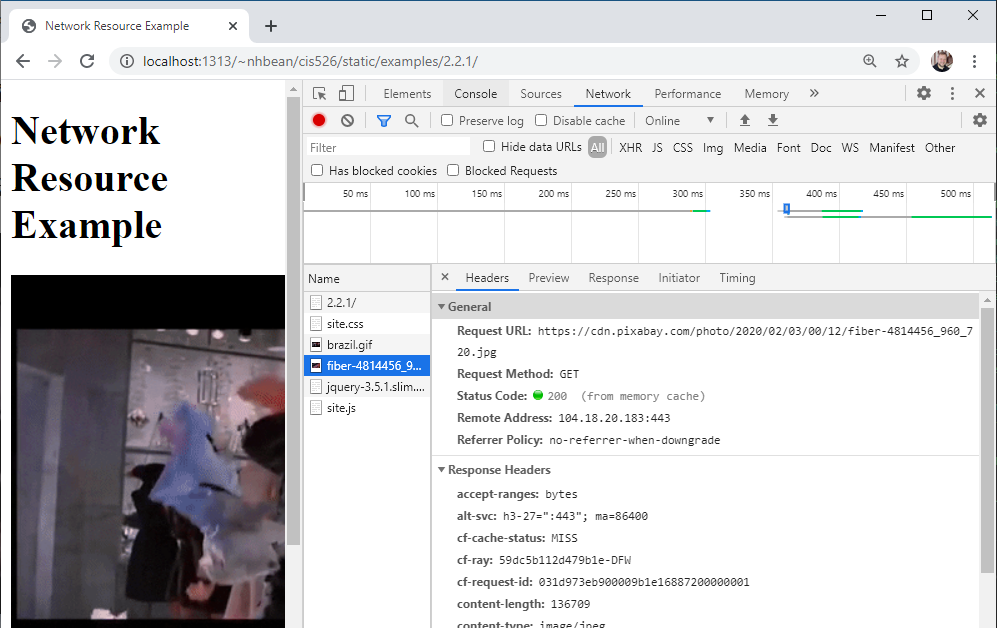
Notice that it reports the status code along with details about the request and response, and provides a preview of the requested resource.
A HTTP response includes a status code - a numeric code and a human-readable description. The codes themselves are 3-digit numbers, with the first number indicating a general category the response status falls into. Essentially, the status code indicates that the request is being fulfilled, or the reason it cannot be.
Codes falling in the 100’s provide some kind of information, often in response to a HEAD or upgrade request. See the MDN Documentation for a full list.
Codes in the 200’s indicate success in some form. These include:
200 OK A status of 200 indicates the request was successful. This is by far the most common response.
201 Created Issued in response to a successful POST request, indicates the resource POSTed to the server has been created.
202 Accepted Indicates the request was received but not yet acted upon. This is used for batch-style processes. An example you may be familiar with is submitting a DARS report request - the DARS server, upon receiving one, adds it to a list of reports to process and then sends a 202 response indicating it was added to the list, and should be available at some future point.
There are additional 200 status codes. See the MDN Documentation for a full list.
Codes in the 300’s indicate redirects. These should be used in conjunction with a Location response header to notify the user-agent where to redirect. The three most common are:
301 Moved Permanently Indicates the requested resource is now permanently available at a different URI. The new URI should be provided in the response, and the user-agent may want to update bookmarks and caches.
302 Found Also redirects the user to a different URI, but this redirect should be considered temporary and the original URI used for further requests.
304 Not Modified Indicates the requested resource has not changed, and therefore the user-agent can use its cached version. By sending a 304, the server does not need to send a potentially large resource and consume unnecessary bandwidth.
There are additional 300 status codes. See the MDN Documentation for a full list.
Codes in the 400’s indicate client errors. These center around badly formatted requests and authentication status.
400 Bad Request is a request that is poorly formatted and cannot be understood.
401 Unauthorized means the user has not been authenticated, and needs to log in.
403 Forbidden means the user does not have permissions to access the requested resource.
404 Not Found means the requested resource is not found on the server.
There are many additional 400 status codes. See the MDN Documentation for a full list.
Status codes in the 500’s indicate server errors.
500 Server Error is a generic code for “something went wrong in the server.”
501 Not Implemented indicates the server does not know how to handle the request method.
503 Service Unavailable indicates the server is not able to handle the request at the moment due to being down, overloaded, or some other temporary condition.
There are additional 500 status codes. See the MDN Documentation for a full list.
When a web client like a browser makes a request, it must specify the request method, indicating what kind of request this is (sometimes we refer to the method as a HTTP Verb).
The two most common are GET and POST requests, as these are typically the only kinds supported by browsers. Other request methods include PUT, PATCH, and DELETE, which are typically used by other kinds of web clients. We’ll focus on just GET and POST requests here.
A GET request seeks to retrieve a specific resource from the web server - often an HTML document or binary file. GET requests typically have no body and are simply used to retrieve data. If the request is successful, the response will typically provide the requested resource in its body.
The POST request submits an entity to the resource, i.e. uploading a file or form data. It typically will have a body, which is the upload or form.
You can learn about other HTTP Methods in the MDN Web Docs. HTTP Methods are defined in W3C’s RFC2616.
Request headers take the form of key-value pairs, and represent specific aspects of the request. For example:
Accept-Encoding: gzipIndicates that the browser knows how to accepted content compressed in the Gzip format.
Note that request headers are a subset of message headers that apply specifically to requests. There are also message headers that apply only to HTTP responses, and some that apply to both.
As HTTP is intended as an extensible protocol, there are a lot of potential headers. IANA maintains the official list of message headers as well as a list of proposed message headers. You can also find a categorized list in the MDN Documentation
While there are many possible request headers, some of the more commonly used are:
Accept Specifies the types a server can send back, its value is a MIME type.
Accept-Charset Specifies the character set a browser understands.
Accept-Encoding Informs the server about encoding algorithms the client can process (most typically compression types)
Accept-Language Hints to the server what language content should be sent in.
Authorization Supplies credentials to authenticate the user to the server. Will be covered in the authentication chapter.
Content-Length The length of the request body sent, in octets
Content-Type The MIME type of the request body
Content-Encoding The encoding method of the request body
Cookie Sends a site cookie - see the section on cookies later
User-Agent A string identifying the agent making the request (typically a browser name and version)