Hyper-Text Markup Language
Hyper-Text Markup Language
Providing structured content to the web since 1993
Providing structured content to the web since 1993
Hyper-Text Markup Language (HTML) alongside Hyper-Text Transfer Protocol (HTTP) formed the core of Sir Tim Berners-Lee’s world-wide web. As the name implies, HTTP is a markup language, one that combines the text of what is being said with instructions on how to display it.
The other aspect of HTML is its hyper-text nature. Hyper-text refers to text that links to additional resources - primarily the links in the document, but also embedded multimedia.
This ability to author structured pages that linked to other structured pages with a single mouse click is at the heart of the World-Wide-Web.
The HTML standard, along with many other web technologies, is maintained by the World-Wide-Web Consortium (abbrivated W3C), stakeholders who create and maintain web standards. The full description of the Hyper-Text Markup Language can be found here w3c’s HTML page.
HTML was built from the SGML (Structured Generalized Markup Language) standard, which provides the concept of “tags” to provide markup and structure within a text document. Each element in HTML is defined by a unique opening and closing tag, which in turn are surrounded by angle brackets (<>).
For example, a top-level heading in HTML would be written:
<h1>Hello World</h1>
And render:
The <h1> is the opening tag and the </h1> is the closing tag. The name of the tag appears immediately within the <> of the opening tag, and within the closing tag proceeded by a forward slash (/). Between the opening tag and closing tag is the content of the element. This can be text (as in the case above) or it can be another HTML element.
For example:
<h1>Hello <i>World</i>!</h1>
Renders:
An element nested inside another element in this way is called a child of the element it is nested in. The containing element is a parent. If more than one tag is contained within the parent, the children are referred to as siblings of one another. Finally, a element nested several layers deep inside another element is called a descendant of that element, and that element is called an ancestor.
Every opening tag must have a matching closing tag. Moreover, nested tags must be matched in order, much like when you use parenthesis and curly braces in programming. While whitespace is ignored by HTML interpreters, best developer practices use indentation to indicate nesting, i.e.:
<div>
<h1>Hello World!</h1>
<p>
This is a paragraph, followed by an unordered list...
</p>
<ul>
<li>List item #1</li>
<li>List item #2</li>
<li>List item #3</li>
</ul>
</div>Getting tags out of order results in invalid HTML, which may be rendered unpredictably in different browsers.
Also, some elements are not allowed to contain content, and should not be written with an end tag, like the break character:
<br>
However, there is a more strict version of HTML called XHTML which is based on XML (another SGML extension). In XHTML void tags are self-closing, and must include a / before the last >, i.e.:
<br/>
In practice, most browsers will interpret <br> and <br/> interchangeably, and you will see many websites and even textbooks use one or the other strategy (sometimes both on the same page). But as a computer scientist, you should strive to use the appropriate form based type of document you are creating.
Similarly, by the standards, HTML is case-insensitive when evaluating tag names, but the W3C recommends using lowercase characters. In XHTML tag names must be in lowercase, and React’s JSX format uses lowercase to distinguish between HTML elements and React components. Thus, it makes sense to always use lowercase tag names.
XHTML is intended to allow HTML to be interpreted by XML parsers, hence the more strict formatting. While it is nearly identical to HTML, there are important structural differences that need to be followed for it to be valid. And since the point of XHTML is to make it more easily parsed by machines, these must be followed to meet that goal. Like HTML, the XHTML standard is maintained by W3C: https://www.w3.org/TR/xhtml11/.
In addition to the tag name, tags can have attributes embedded within them. These are key-value pairs that can modify the corresponding HTML element in some way. For example, an image tag must have a src (source) attribute that provides a URL where the image data to display can be found:
<img src="/images/Light_Bulb_or_Idea_Flat_Icon_Vector.svg" alt="Light Bulb">
This allows the image to be downloaded and displayed within the browser:
Note that the <img> element is another void tag. Also, <img> elements should always have an alt attribute set - this is text that is displayed if the image cannot be downloaded, and is also read by a screen reader when viewed by the visually impaired.
Attributes come in the form of key-value pairs, with the key and value separated by an equal sign (=) and the individual attributes and the tag name separated by whitespace. Attributes can only appear in an opening or void tag. Some attributes (like readonly) do not need a value.
There should be no spaces between the attribute key, the equal sign (=), and the attribute value. Attribute values should be quoted using single or double quotes if they contain a space character, single quote, or double quote character.
Additionally, while there are specific attributes defined within the HTML standard that browsers know how to interpret, specific technologies like Angular and React add their own, custom attributes. Any attribute a browser does not know is simply ignored by the browser.
When authoring an HTML page, HTML elements should be organized into an HTML Document. This format is defined in the HTML standard. HTML that does not follow this format are technically invalid, and may not be interpreted and rendered correctly by all browsers. Accordingly, it is important to follow the standard.
The basic structure of a valid HTML5 document is:
<!doctype HTML>
<html lang="en">
<head>
<title>Page Title Goes Here</title>
</head>
<body>
<p>Page body and tags go here...</p>
</body>
</html>We’ll walk through each section of the page in detail.
The SGML standard that HTML is based on requires a !doctype tag to appear as the first tag on the page. The doctype indicates what kind of document the file represents. For HTML5, the doctype is simply HTML. Note the doctype is not an element - it has no closing tag and is not self-closing.
For SGML, the doctype normally includes a URL pointing at a definition for the specific type of document. For example, in HTML4, it would have been <!DOCTYPE HTML PUBLIC "-//W3C//DTD HTML 4.01//EN" "http://www.w3.org/TR/html4/strict.dtd">. HTML5 broke with the standard by only requiring HTML be included, making the doctype much easier to remember and type.
The next element should be an <html> element. It should include all other elements in the document, and its closing tag should be the last tag on the page. It is best practice to include a lang attribute to indicate what language is used in the document - here we used "en" for English. The <html> element should only contain two children - a <head> and <body> tag in that order.
The next element is the <head> element. A valid HTML document will only have one head element, and it will always be the first child of the <html> element. The head section contains metadata about the document - information about the document that is not rendered in the document itself. This typically consists of meta and link elements, as well as a <title>. Traditionally, <script> elements would also appear here, though current best practice places them as the last children of the <body> tag.
The <head> element should always have exactly one child <title> element, which contains the title of the page (as text; the <title> element should never contain other HTML elements). This title is typically displayed in the browser tab.
The next element is the <body> element. A valid HTML document will only have one body element, and it will always be the second child of the <html> element. The <body> tag contains all the HTML elements that make up the page. It can be empty, though that makes for a very boring page.
Given that the role of HTML is markup, i.e. providing structure and formatting to text, HTML elements can broadly be categorized into two categories depending on how they affect the flow of text - inline and block.
Inline elements referred to elements that maintained the flow of text, i.e. the bring attention to (<b>) element used in a paragraph of text, would bold the text without breaking the flow:
<p>The quick brown <b>fox</b> lept over the log</p>
The quick brown fox lept over the log
In contrast, block elements break the flow of text. For example, the <blockquote> element used to inject a quote into the middle of the same paragraph:
<p>The quick brown fox <blockquote>What does the fox say? - YLVIS</blockquote> lept over the log</p>
The quick brown fox
What does the fox say? - YLVISlept over the log
While HTML elements default to either block or inline behavior, this can be changed with the CSS display property.
Tables were amongst the first addition to HTML (along with images), as they were necessary for the primary role of early HTML, disseminating research.
A table requires a lot of elements to be nested in a specific manner. It is best expressed through an example:
<table>
<thead>
<tr>
<th>Name</th>
<th>Role</th>
</tr>
</thead>
<tbody>
<tr>
<td>Darth Vader</td>
<td>Antagonist</td>
</tr>
<tr>
<td>Luke Skywalker</td>
<td>Coming-of-age protagonist</td>
</tr>
<tr>
<td>Princess Lea</td>
<td>Heroic resistance fighter</td>
</tr>
<tr>
<td>Obi-Wan Kenobi</td>
<td>Wise old man</td>
</tr>
<tr>
<td>Han Solo</td>
<td>Likeable scoundrel</td>
</tr>
<tr>
<td>Chewbacca</td>
<td>The muscle</td>
</tr>
<tr>
<td>Threepio</td>
<td>Comedic foil</td>
</tr>
<tr>
<td>Artoo Deetoo</td>
<td>Plot driver</td>
</tr>
</tbody>
</table>It renders as:
| Name | Role |
|---|---|
| Darth Vader | Antagonist |
| Luke Skywalker | Coming-of-age protagonist |
| Princess Lea | Heroic resistance fighter |
| Obi-Wan Kenobi | Wise old man |
| Han Solo | Likeable scoundrel |
| Chewbacca | The muscle |
| 3PO | Comedic foil |
| R2-D2 | Plot driver |
Tables should only be used for displaying tabular data. There was a time, not long ago, when early web developers used them to create layouts by cutting images into segments and inserting them into table cells. This is very bad practice! It will not display as expected in all browsers, and wreaks havoc with screen readers for the visually impaired. Instead, pages should be laid out with CSS, as is discussed in the CSS layouts section.
A far more detailed discussion of tables can be found in MDN’s guides.
Forms were also amongst the first additions to the HTML standard, and provide the ability to submit data to a web server. A web form is composed of <input>, <textarea>, <select> and similar elements nested within a <form> element.
The form element primarily is used to organize input elements and specify how they should be submitted. In its simplest form, it is simply a tag that other elements are nested within:
<form></form>
However, it can be modified with a number of attributes:
action The action attribute specifies the url that this form data should be sent to. By default, it is the page the form exists on (i.e. if the form appears on http://foo.com/bar, then it will submit to http://foo.com/bar). The url can be relative to the current page, absolute, or even on a different webserver. See the discussion of URLs in the HTTP section.
enctype The enctype attribute specifies the format that form data will be submitted in. The most common values are application/x-www-form-urlencoded (the default), which serializes the key/value pairs using the urlencoding strategy, and multipart/form-data, which uses the multipart encoding scheme, and can interweave binary (file) data into the submission. These encoding strategies are discussed more thoroughly in the chapter on submitting form data.
method The method attribute specifies the HTTP method used to submit the form. The values are usually GET or POST. If the method is not specified, it will be a GET request.
target The target attribute specifies how the server response to the form submission will be displayed. By default, it loads in the current frame (the _self) value. A value of _blank will load the response in a new tab. If <iframe> elements are being used, there are additional values that work within <iframe> sets.
Most inputs in a form are variations of the <input> element, specified with the type attribute. Many additional specific types were introduced in the HTML5 specification, and may not be available in older browsers (in which case, they will be rendered as a text type input). Currently available types are (an asterisk indicate a HTML5-defined type):
checked, which is a boolean specifying if it is checked.In addition to the type attribute, some other commonly used input attributes are:
In addition to the <input> element, some other elements exist that provide input-type functionality within a form, and implement the same attributes as an <input>. These are:
The <textarea> element provides a method for entering larger chunks of text than a <input type="text"> does. Most importantly, it preserves line-breaks (the <input type="text"> removes them). Instead of using the value attribute, the current value appears inside the opening and closing tags, i.e.:
<textarea name="exampleText">
This text is displayed within the textarea
</textarea>In addition, the rows and cols attribute can be used to specify the size of the textarea in characters.
The <select> element allows you to define a drop-down list. It can contain as children, <option> and <optgroup> elements. The <select> element should have its name attribute specified, and each <option> element should have a unique value attribute. The selected <option>’s value is then submitted with the <select>’s name as a key/value pair.
Each <select> element should also have a closing tag, and its child text is what is displayed to the user.
The <optgroup> provides a way of nesting <option> elements under a category identifier (a label attribute specified on the <optgroup>).
An example <select> using these features is:
<select name="headgear">
<option value="none">None</option>
<optgroup label="Hats">
<option value="ball cap">Ball Cap</option>
<option value="derby">Derby</option>
<option value="fedora">Fedora</option>
</optgroup>
<optgroup value="Ceremonial">
<option value="crown">Crown</option>
<option value="mitre">Mitre</option>
<option value="war bonnet">War Bonnet</option>
</optgroup>
</select>Finally, multiple selections can be allowed by specifying a multiple attribute as true.
In addition to inputs, a <form> often uses <label> elements to help identify the inputs and their function. A label will typically have its for attribute set to match the name attribute of the <input> it corresponds to. When connected in this fashion, clicking the label will give focus to the input. Also, when the <input type="checkbox">, clicking the label will also toggle the checked attribute of the checkbox.
Finally, the <fieldset> element can be used to organize controls and labels into a single subcontainer within the form. Much like <div> elements, this can be used to apply specific styles to the contained elements.
This page details some of the most commonly used HTML elements. For a full reference, see MDN’s HTML Element Reference.
These elements describe the basic structure of the HTML document.
The <html> element contains the entire HTML document. It should have exactly two children, the <head> and the <body> elements, appearing in that order.
The <head> element contains any metadata describing the document. The most common children elements are <title>, <meta>, and <link>.
The <body> element should be the second child of the <html> element. It contains the actual rendered content of the page, typically as nested HTML elements and text. Elements that appear in the body can define structure, organize content, embed media, and play many other roles.
These elements add properties to the document.
The <link> element links to an external resource using the href attribute and defines that resource’s relationship with the document with the rel attibute.
This is most commonly used to link a stylesheet which will modify how the page is rendered by the browser (see the chapter on CSS). A stylesheet link takes the form:
<link href="path-to-stylesheet.css" rel="stylesheet"/>
It can also be used to link a favicon (the icon that appears on your browser tab):
<link rel="icon" type="image/x-icon" href="http://example.com/favicon.ico" />
The <meta> elements is used to describe metadata not covered by other elements. In the early days, its most common use was to list keywords for the website for search engines to use:
<meta keywords="html html5 web development webdev"/>
However, this was greatly abused and search engines have stopped relying on them. One of the most common uses today is to set the viewport to the size of the rendering device for responsive design (see the chapter on responsive design):
<meta name="viewport" content="width=device-width, initial-scale=1.0">
Also, best practice is to author HTML documents in utf-8 character format and specify that encoding with a metadata tag with the charset attribute:
<meta charset="utf-8">
The style element allows for embedding CSS text directly into the head section of the HTML page. The Separation of Concerns discussion discusses the appropriateness of using this approach.
The <title> element should only appear once in the <head> element, and its content should be text (no HTML elements). It specifies the title of the document. In modern browsers, the title is displayed on the browser tab displaying the document. In earlier browsers, it would appear in the window title bar.
Many HTML Elements help define the structure of the document by breaking it into sections. These are intended to hold other elements and text. These elements are block type elements.
The <h1>, <h2>, <h3>, <h4>, <h5>, and <h6> elements are headings and subheadings with six possible levels of nesting. They are used to enclose the title of the section.
A <main> element identifies the content most central in the page. There should be only one per page (or, if multiple main elements are used, the others should have their visible attribute set to false).
An <aside> element identifies content separate from the main focus of the page. It can be used for callouts, advertisements, and the like.
An <article> element identifies a stand-alone piece of content. Unlike an aside, it is intended for syndication (reprinting) in other forms.
The <header> element identifies a header for the page, often containing the site banner, navigation, etc.
The <footer> element identifies a footer for the page, often containing copyright and contact information.
The <nav> element typically contains navigation links and/or menus.
A <section> element is a general-purpose container for sectioning a page where a more specific container does not make sense.
These HTML elements are used to organize text content. Each of these is a block element, meaning it breaks up the flow of text on the page.
The <blockquote> is used to contain a long quotation.
The <figure> is used to contain a figure (typically a <img> or other media element).
The <figcaption> provides a caption for a figure
The <hr> provides a horizontal rule (line) to separate text.
There are three types of lists available in HTML, ordered, unordered, and definition. Ordered lists number their contents, and consist of list item elements (<li>) nested in an ordered list element (<ol>). Unordered lists are bulleted, and consist of list item elements (<li>) nested in an unordered list element (<ul>). List items can contain any kind of HTML elements, not just text.
Definition lists nest a definition term (<dt>) and its corresponding definition (<dd>) inside a definition list (<dl>) element. While rarely used, they can be handy when you want to provide lists of definitions (as in a glossary) in a way a search engine will recognize.
The <div> element provides a wrapper around text content that is normally used to attach styles to.
The <pre> tag informs the browser that its content has been preformatted, and its contents should be displayed exactly as written (i.e. whitespace is respected, and angle brackets (<>) are rendered rather than interpreted as HTML. It is often used in conjunction with a <code> element to display source code within a webpage.
The following elements modify nested text while maintaining the flow of the page. As the name suggests, these are inline type elements.
The <a> anchor element is used to link to another document on the web (i.e. ‘anchoring’ it). This element is what makes HTML hyper-text, so clearly it is important. It should always have a source (src) attribute defined (use "#" if you are overriding its behavior with JavaScript).
A number of elements seek to draw specific attention to a snippet of text, including <strong>, <mark>, <em>, <b>, <i>
The <strong> element indicates the text is important in some way. Typically browsers will render its contents in boldface.
The <em> element indicates stress emphasis on the text. Typically a browser will render it in italics.
The <mark> element indicates text of specific relevance. Typically the text appears highlighted.
The bring to attention element (<b>) strives to bring attention to the text. It lacks the semantic meaning of the other callouts, and typically is rendered as boldface (in early versions of HTML, it referred to bold).
The <i> element sets off the contained text for some reason other than emphasis. It typically renders as italic (in early versions of HTML, the i referred to italics).
The break element (<br>) inserts a line break into the text. This is important as all whitespace in the text of an HTML document is collapsed into a single space when interpreted by a browser.
The <code> element indicates the contained text is computer code.
The <span> element is the inline equivalent of the <div> element; it is used primarily to attach CSS rules to nested content.
A number of elements bring media into the page.
The <img> element represents an image. It should have a source (src) attribute defined, consisting of a URL where the image data can be retrieved, and an alternative text (alt) attribute with text to be displayed when the image cannot be loaded or when the element is read by a screen reader.
The <audio> element represents audio data. It should also have a source (src) attribute to provide the location of the video data. Alternatively, it can contain multiple <source> elements defining alternative forms of the video data.
The <video> element represents a video. It should also have a source (src) attribute to provide the location of the video data. Alternatively, it can contain multiple <source> elements defining alternative forms of the audio data.
The <source> element specifies one form of multimedia data, and should be nested inside a <video> or <audio> element. Providing multiple sources in this way allows the browser to use the first one it understands (as most browsers do not support all possible media formats, this allows you to serve the broadest possible audience). Each <source> element should have a source attribute (src) defining where its multimedia data can be located, as well as a type attribute defining what format the data is in.
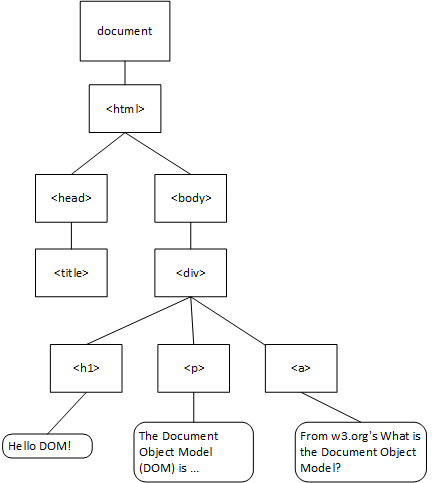
The Document Object Model (or DOM) is a data structure representing the content of a web page, created by the browser as it parses the website. The browser then makes this data structure accessible to scripts running on the page. The DOM is essentially a tree composed of objects representing the HTML elements and text on the page.
Consider this HTML:
<!DOCTYPE html>
<html>
<head>
<title>Hello DOM!</title>
<link href="site.css"/>
</head>
<body>
<div class="banner">
<h1>Hello DOM!</h1>
<p>
The Document Object Model (DOM) is a programming API for HTML and XML documents. It defines the logical structure of documents and the way a document is accessed and manipulated. In the DOM specification, the term "document" is used in the broad sense - increasingly, XML is being used as a way of representing many different kinds of information that may be stored in diverse systems, and much of this would traditionally be seen as data rather than as documents. Nevertheless, XML presents this data as documents, and the DOM may be used to manage this data.
</p>
<a href="https://www.w3.org/TR/WD-DOM/introduction.html">From w3.org's What is the Document Object Model?</a>
</div>
</body>
<html>When it is parsed by the browser, it is transformed into this tree:
Most browsers also expose the DOM tree through their developer tools. Try opening the example page in Chrome or your favorite browser using this link.
Now open the developer tools for your browser:
CTRL + SHIFT + i or right-click and select ‘Inspect’ from the context menu.CTRL + SHIFT + i or right-click and select ‘Inspect element’ from the context menu.CTRL + SHIFT + i or right-click and select ‘Inspect Element’ from the context menu.You should see a new panel open in your browser, and under its ’elements’ tab the DOM tree is displayed:
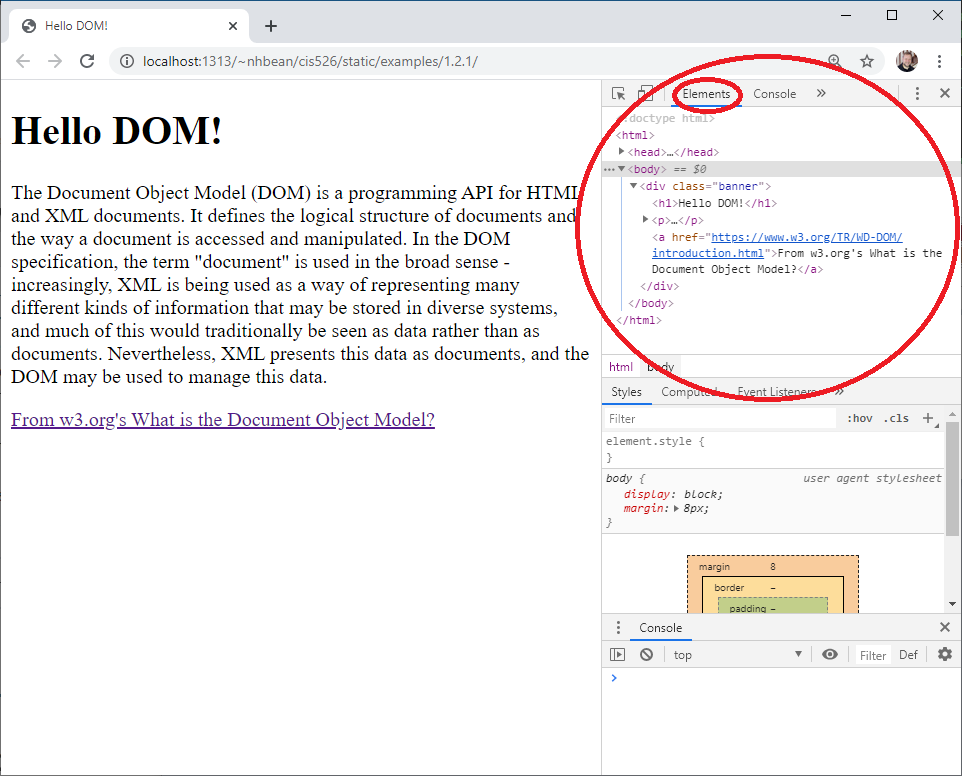
Collapsed nodes can be expanded by clicking on the arrow next to them.
Try moving your mouse around the nodes in the DOM tree, and you’ll see the corresponding element highlighted in the page. You can also dynamically edit the DOM tree from the elements tab by right-clicking on a node.
Try right-clicking on the <h1> node and selecting ’edit text’. Change the text to “Hello Browser DOM”. See how it changes the page?
The page is rendered from the DOM, so editing the DOM changes how the page appears. However, the initial structure of the DOM is derived from the loaded HTML. This means if we refresh the page, any changes we made to the DOM using the developer tools will be lost, and the page will return to its original state. Give it a try - hit the refresh button.
For convenience, this textbook will use the Chrome browser for all developer tool reference images and discussions, but the other browsers offer much of the same functionality. If you prefer to use a different browser’s web tools, look up the details in that browser’s documentation.
You’ve now seen how the browser creates the DOM tree by parsing the HTML document and that DOM tree is used to render the page. We’ll revisit this concept in the chapters on CSS and JavaScript when we see how those technologies interact with the DOM.