Chapter 3
Introduction to Data Structures & Algorithms
The big introduction to new content!
The big introduction to new content!
One way to look at a computer program is to think of it as a list of instructions that the computer should follow. However, in another sense, many computer programs are simply ways to manipulate data to achieve a desired result. We’ve already written many programs that do this, from calculating the minimum and maximum values of a list of numbers, to storing and retrieving data about students and teachers in a school.
As we start to consider our programs as simply ways to manipulate data, we may quickly realize that we are performing the same actions over and over again, or even treating data in many similar ways. Over time, these ideas have become the basis for several common data structures that we may use in our programs.
Broadly speaking, a data structure is any part of our program that stores data using a particular format or method. Typically data structures define how the data is arranged, how it is added to the structure, how it can be removed, and how it can be accessed.
Data structures can give us very useful ways to look at how our data is organized. In addition, a data structure may greatly impact how easy, or difficult, it can be to perform certain actions with the data. Finally, data structures also impose performance limitations on our code. Some structures may be better at performing a particular operation than others, so we may have to consider that as well when choosing a data structure for our program.
In this class, we’ll spend the majority of our time learning about these common data structures, as well as algorithmic techniques that work well with each one. By formalizing these structures and techniques, we are able to build a common set of building blocks that every programmer is familiar with, making it much easier to build programs that others can understand and reuse.
First, let’s review some of these common data structures and see how they could be useful in our programs.
File:Binary tree.svg. (2019, September 14). Wikimedia Commons, the free media repository. Retrieved 22:18, February 7, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Binary_tree.svg&oldid=365739199. ↩︎

First, we can broadly separate the data structures we’re going to learn about into two types, linear and non-linear data structures.
A linear data structure typically stores data in a single dimension, just like an array. By using a linear data structure, we would know that a particular element in the data structure comes before another element or vice-versa, but that’s about it. A great example is seen in the image above. We have a list of numbers, and each element in the list comes before another element, as indicated by the arrows.
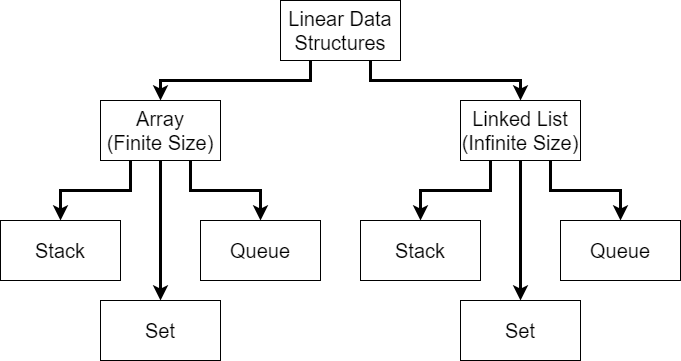
Linear data structures can further be divided into two types: arrays, which are typically finite sized; and linked lists, which can be infinitely sized. We’ve already worked with arrays extensively by this point, but linked lists are most likely a new concept. That’s fine! We’ll explore how to build our own later in this course.
Using either arrays or linked lists, we can build the three most commonly used linear data structures: stacks, queues, and sets. However, before we learn about each of those, let’s review a bit more about what the list data structure itself looks like.
The list data structure is the simplest form of a linear data structure. As we can guess from the definition, a list is simply a grouping of data that is presented in a given order. With lists, not only do the elements in the list matter, but the order matters as well. It’s not simply enough to state that elements $8$, $6$ and $7$ are in the list, but generally we also know that $8$ comes before $6$, which comes before $7$.
We’ve already learned about arrays, which are perfect examples of lists in programming. In fact, Python uses the data type list in the same way most other programming languages use arrays. Other programming languages, such as Java, provide a list data structure through their standard libraries.
One important way to classify data structures is by the operations they can perform on the data. Since a list is the simplest version of a linear data structure, it has several important operations it can perform:
For example, let’s look at the insert operation. Assume we have the list shown in the following diagram:
Then, we decide we’d like to add the element $4$ at index $3$ in this list. So, we can think of this like trying to place the element in the list as shown below:
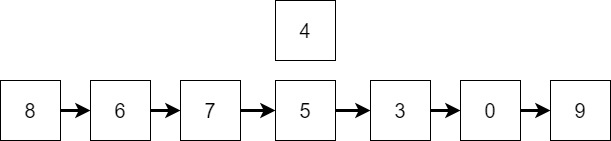
Once we insert that element, we then shift all of the other elements back one position, making the list one element larger. The final version is shown below:

Lists are a very powerful data structure, and one of the most commonly used in a variety of programs. While arrays may seem very flexible, their static size and limited operations can sometimes make them more difficult to use than they are worth. Many programmers choose to use the more flexible list data structure instead.
When deciding which data structure to use, lists are best when we might be adding or removing data from anywhere in the list, but we want to maintain the ordering between elements. As we’ll see on the later pages, we can have more specific types of structures for particular ways we intend to add and remove data from our structure, but lists are a great choice if neither of those are a good fit.
The next two data structures we’ll look at are stacks and queues. They are both very similar to lists in most respects, but each one puts a specific limitation on how the data structure operates that make them very useful in certain situations.
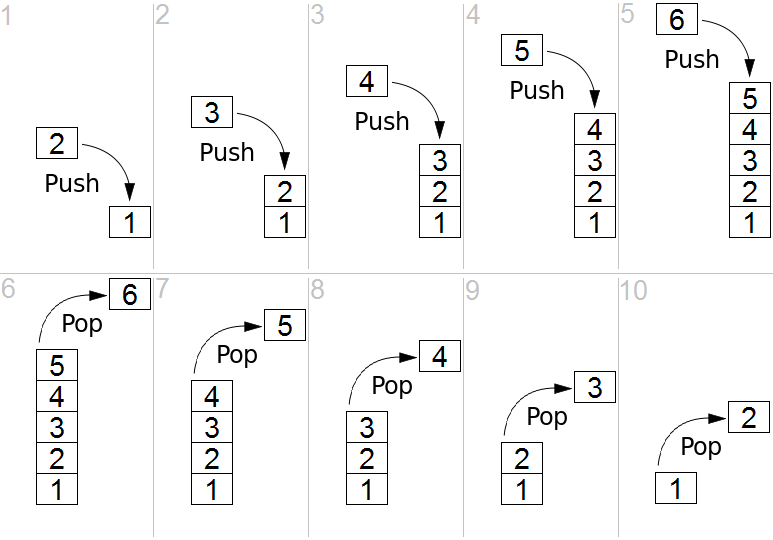
A stack is one special version of a list. Specifically, a stack is a Last In, First Out or LIFO data structure.
So, what does that mean? Basically, we can only add elements to the end, or top of the stack. Then, when we want to get an element from the stack, we can only take the one from the top–the one that was most recently added.
A great way to think of a stack is like a stack of plates, such as the one pictured below:
When we want to add a new plate to the stack, we can just set it on top. Likewise, if we need a plate, we’ll just take the top one off and use it.
A stack supports three major unique operations:
Many stacks also include additional operations such as size and find as well.
A queue is another special version of a list, this time representing a First In, First Out or FIFO data structure.
As seen in the diagram above, new items are added to the back of the queue. But, when we need to take an item from a queue, we’ll take the item that is in the front, which is the one that was added first.
Where have we seen this before? A great example is waiting our turn in line at the train station,
In many parts of the world, the term queueing is commonly used to refer to the act of standing in line. So, it makes perfect sense to use that same word to refer to a data structure.
As we can probably guess, we would definitely want to use a stack if we need our data structure to follow the last in, first out, or LIFO ordering. Similarly, we’d use a queue if we need first in, first out or FIFO ordering.
If we can’t be sure that one or the other of those orderings will work for us, then we can’t really use a stack or a queue in our program.
Of course, one of the biggest questions that comes from this is “why not just use lists for everything?” Indeed, lists can be used as both a queue and a stack, simply by consistently inserting and removing elements from either the beginning or the end of the list as needed. So why do we need to have separate data structures for a queue and a stack?
There are two important reasons. First, if we know that we only need to access the most recently added element, or the element added first, it makes sense to have a special data structure for just that usage. In this way, it is clear to anyone else reading our program that we will only be using the data in that specific way. Behind the scenes, of course, we can just use a list to represent a queue or a stack, but in our design documents and in our code, it might be very helpful to know if we should think of it like a stack or a queue.
The other reason has to do with performance. By knowing exactly how we need to use the data, we can design data structures that are specifically created to perform certain operations very quickly and efficiently. A generic list data structure may not be as fast or memory efficient as a structure specifically designed to be used as a stack, for example.
As we learn about each of these data structures throughout this course, we’ll explore how each data structure works in terms of runtime performance and memory efficiency.
File:Lifo stack.png. (2017, August 7). Wikimedia Commons, the free media repository. Retrieved 23:14, February 7, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Lifo_stack.png&oldid=254596945. ↩︎
File:Tallrik - Ystad-2018.jpg. (2019, December 31). Wikimedia Commons, the free media repository. Retrieved 23:17, February 7, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Tallrik_-_Ystad-2018.jpg&oldid=384552503. ↩︎
File:Data Queue.svg. (2014, August 15). Wikimedia Commons, the free media repository. Retrieved 23:21, February 7, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Data_Queue.svg&oldid=131660203. ↩︎
File:People waiting a train of Line 13 to come 02.JPG. (2016, November 28). Wikimedia Commons, the free media repository. Retrieved 23:23, February 7, 2020 from https://commons.wikimedia.org/w/index.php?title=File:People_waiting_a_train_of_Line_13_to_come_02.JPG&oldid=223382692. ↩︎
Another linear data structure is known as a set. A set is very similar to a list, but with two major differences:
In fact, the term set comes from mathematics. We’ve probably seen sets already in a math class.
Beyond the typical operations to add and remove elements from a set, there are several operations unique to sets:
Again, many of these operations may be familiar from their use in various math classes.
In addition, we can easily think of set operations as boolean logic operators. For example, the set operation union is very similar to the boolean operator or, as seen in the diagram below.
As long as an item is contained in one set or the other, it is included in the union of the sets.
Similarly, the same comparison works for the set operation intersection and the boolean and operator.
Once again, if an item is contained in the first set and the second set, it is contained in the intersection of those sets.
A set is a great choice when we know that our program should prevent duplicate items from being added to a data structure. Likewise, if we know we’ll be using some of the specific operations that are unique to sets, then a set is an excellent choice.
Of course, if we aren’t sure that our data structure will only store unique items, we won’t be able to use a set.
File:Venn0111.svg. (2019, November 15). Wikimedia Commons, the free media repository. Retrieved 02:37, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Venn0111.svg&oldid=375571745. ↩︎
File:Venn0001.svg. (2019, November 15). Wikimedia Commons, the free media repository. Retrieved 02:37, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Venn0001.svg&oldid=375571733. ↩︎
The last of the linear data structures may seem linear from the outside, but inside it can be quite a bit more complex.
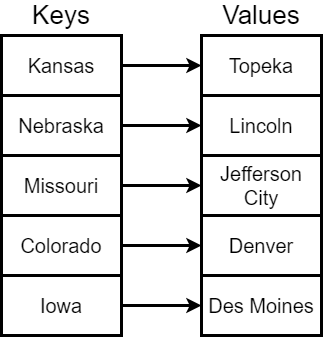
The map data structure is an example of a key-value data structure, also known as a dictionary or associative array. In the simplest case, a map data structure keeps track of a key that uniquely identifies a particular value, and stores that value along with the key in the data structure.
Then, to retrieve that value, the program must simply provide the same key that was used to store it.
In a way, this is very similar to how we use an array, since we provide an array index to store and retrieve items from an array. The only difference is that the key in a map can be any data type! So it is a much more powerful data structure.
In fact, this data structure is one of the key ideas behind modern databases, allowing us to store and retrieve database records based on a unique primary key attached to each row in the database.
A map data structure should support the following operations:
Later in this course, we’ll devote an entire module to learning how to build our own map data structures and explore these operations in more detail.
One of the most common ways to implement the map data structure is through the use of a hash table. A hash table uses an array to store the values in the map, and uses a special function called a hash function to convert the given key to a simple number. This number represents the array index for the value. In that way, the same key will always find the value that was given.
But what if we have two keys that produce the same array index? In that case, we’ll have to add some additional logic to our map to handle that situation.
Maps are great data structures when we need to store and retrieve data using a specific key. Just like we would store data in a database or put items in a numbered box to retrieve later, we can use a map as a general purpose storage and retrieval data structure.
Of course, if our data items don’t have unique keys assigned to them, then using a map may not be the best choice of data structure. Likewise, if each key is a sequential integer, we may be able to use an array just as easily.
File:Hash table 3 1 1 0 1 0 0 SP.svg. (2019, August 21). Wikimedia Commons, the free media repository. Retrieved 02:46, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Hash_table_3_1_1_0_1_0_0_SP.svg&oldid=362787583. ↩︎
The other type of data structure we can use in our programs is the non-linear data structure.
Broadly speaking, non-linear data structures allow us to store data across multiple dimensions, and there may be multiple paths through the data to get from one item to another. In fact, much of the information stored in the data structure has to do with the paths between elements more than the elements themselves.
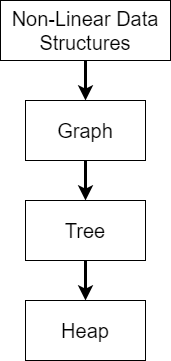
Just like linear data structures, there are several different types of non-linear data structures. In this case, each one is a more specialized version of the previous one, hence the hierarchy shown above. On the next few pages, we’ll explore each one just a bit to see what they look like.
File:6n-graf.svg. (2020, January 12). Wikimedia Commons, the free media repository. Retrieved 02:53, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:6n-graf.svg&oldid=386942400. ↩︎
The most general version of a non-linear data structure is the graph, as shown in the diagram above. A graph is a set of nodes that contain data, as well as a set of edges that link two nodes together. Edges themselves may also contain data.
Graphs are great for storing and visualizing not just data, but also the relationships between data. For example, each node in the graph could represent a city on the map, with the edges representing the travel time between the two cities. Or we could use the nodes in a graph to represent the people in a social network, and the edges represent connections or friendships between two people. There are many possibilities!
Graphs are a great choice when we need to store data and relationships between the data, but we aren’t sure exactly what structures or limitations are present in the data. Since a graph is the most general and flexible non-linear data type, it has the most ability to represent data in a wide variety of ways.
File:Directed acyclic graph 2.svg. (2016, May 3). Wikimedia Commons, the free media repository. Retrieved 03:05, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Directed_acyclic_graph_2.svg&oldid=195167720. ↩︎
 [^1]
[^1]
File:Tree (computer science).svg. (2019, October 20). Wikimedia Commons, the free media repository. Retrieved 03:13, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Tree_(computer_science).svg&oldid=371240902.
A tree is a more constrained version of a graph data structure. Specifically, a tree is a graph that can be shown as a hierarchical structure, where each node in the tree is itself the root of a smaller tree. Each node in the tree can have one or more child nodes and exactly one parent node, except for the topmost node or root node, which has no parent nodes.
A tree is very useful for representing data in a hierarchical or sorted format. For example, one common use of a tree data structure is to represent knowledge and decisions that can be made to find particular items. The popular children’s game 20 Questions can be represented as a tree with 20 levels of nodes. Each node represents a particular question that can be asked, and the children of that node represent the possible answers. If the tree only contains yes and no questions, it can still represent up to $2^{20} = 1,408,576$ items!
Another commonly used tree data structure is the trie, which is a special type of tree used to represent textual data. Ever wonder how a computer can store an entire dictionary and quickly spell-check every single word in the language? It actually uses a trie!
Below is a small example of a trie data structure:
This trie contains the words “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn” and “A” in just a few nodes and edges. Imagine creating a trie that could store the entire English language! While it might be large, we can hopefully see how it would be much more efficient to search and store that data in a trie instead of a linear data structure.
A tree is a great choice for a data structure when there is an inherent hierarchy in our data, such that some nodes or elements are naturally “parents” of other elements. Likewise, if we know that each element may only have one parent but many children, a tree becomes an excellent choice. Trees contain several limitations that graphs do not, but they are also very powerful data structures.
File:Trie example.svg. (2014, March 2). Wikimedia Commons, the free media repository. Retrieved 03:22, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Trie_example.svg&oldid=117843653. ↩︎
The last non-linear data structure we’ll talk about is the heap, which is a specialized version of a tree. In a heap, we try to accomplish a few goals:
If we follow those three guidelines, a heap becomes the most efficient data structure for managing a set of data where we always want to get the maximum or minimum value each time we remove an element. These are typically called priority queues, since we remove items based on their priority instead of the order they entered the queue.
Because of this, heaps are very important in creating efficient algorithms that deal with ordered data.
As discussed above, a heap is an excellent data structure for when we need to store elements and then always be able to quickly retrieve either the smallest or largest element in the data structure. Heaps are a very specific version of a tree that specialize in efficiency over everything else, so they are only really good for a few specific uses.
File:Max-Heap.svg. (2014, December 28). Wikimedia Commons, the free media repository. Retrieved 03:25, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Max-Heap.svg&oldid=144372033. ↩︎
The other major topic covered in this course is the use of algorithms to manipulate the data stored in our data structures.
An algorithm is best defined as a finite list of specific instructions for performing a task. In the real world, we see algorithms all the time. A recipe for cooking your favorite dish, instructions for how to fix a broken car, or a method for solving a complex mathematical equation can all be considered examples of an algorithm. The flowchart above shows Euclid’s Algorithm for finding the greatest common divisor of two numbers.
In this course, however, we’re going to look specifically at the algorithms and algorithmic techniques that are most commonly used with data structures in computer programming.
An algorithmic technique, sometimes referred to as a methodology or paradigm, is a particular way to design an algorithm. While there are a few commonly used algorithms across different data structures, many times each program may need a unique algorithm, or at least an adaptation of an existing algorithm. to perform its work.
To make these numerous algorithms easier to understand, we can loosely categorize them based on the techniques they use to solve the problem. On the next few pages, we’ll introduce some of the more commonly used algorithmic techniques in this course. Throughout this course, we will learn how to apply many of these techniques when designing algorithms that work with various data structures to accomplish a goal.
File:Euclid flowchart.svg. (2019, January 8). Wikimedia Commons, the free media repository. Retrieved 21:43, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Euclid_flowchart.svg&oldid=334007111. ↩︎
The first algorithmic technique we’ll use is the brute force technique. This is the algorithmic technique that most of us are most familiar with, even if we don’t realize it.
Simply put, a brute force algorithm will try all possible solutions to the problem, only stopping when it finds one that is the actual solution. A great example of a brute force algorithm in action is plugging in a USB cable. Many times, we will try one way, and if that doesn’t work, flip it over and try the other. Likewise, if we have a large number of keys but are unsure which one fits in a particular lock, we can just try each key until one works. That’s the essence of the brute force approach to algorithmic design.
A great example of a brute force algorithm is finding the closest pair of points in a multidimensional space. This could be as simple as finding the two closest cities on a map, or the two closest stars in a galaxy.
To find the answer, a brute force approach would be to simply calculate the distance between each individual pair of points, and then keep track of the minimum distance found. A pseudocode version of this algorithm would be similar to the following.
MINIMUM = infinity
POINT1 = none
POINT2 = none
loop each POINTA in POINTS
loop each POINTB in POINTS
if POINTA != POINTB
DISTANCE = COMPUTE_DISTANCE(POINTA, POINTB)
if DISTANCE < MINIMUM
MINIMUM = DISTANCE
POINT1 = POINTA
POINT2 = POINTB
end if
end if
end loop
end loopLooking at this code, if we have $N$ points, it would take $N^2$ steps to solve the problem! That’s not very efficient, event for a small data set. However, the code itself is really simple, and it is guaranteed to find exactly the best answer, provided we have enough time and a powerful enough computer to run the program.
In the project for this module, we’ll implement a few different brute-force algorithms to solve simple problems. This will help us gain more experience with this particular technique.
File:Closest pair of points.svg. (2018, October 20). Wikimedia Commons, the free media repository. Retrieved 22:29, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Closest_pair_of_points.svg&oldid=324759130. ↩︎
The next most common algorithmic technique is divide and conquer. A divide and conquer algorithm works just like it sounds. First, it will divide the problem into at least two or more smaller problems, and then it will try to solve each of those problems individually. It might even try to subdivide those smaller problems again and again to finally get to a small enough problem that it is easy to solve.
A great real-world example of using a divide and conquer approach to solving a problem is when we need to look for something that we’ve lost around the house. Instead of trying to search the entire house, we can subdivide the problem into smaller parts by looking in each room separately. Then, within each room, we can even further subdivide the problem by looking at each piece of furniture individually. By reducing the problem’s size and complexity, it becomes easier to search through each individual piece of furniture in the house, either finding our lost object or eliminating that area as the likely location it will be found.

One great example of a divide and conquer algorithm is the binary search algorithm. If we have a list of data that has already been sorted, as seen in the figure above, we can easily find any item in the list using a divide and conquer process.
For example, let’s say we want to find the value $19$ in that list. First, we can look at the item in the middle of the list, which is $23$. Is it our desired number? Unfortunately, it is not. So, we need to figure out how we can use it to divide our input into a smaller problem. Thankfully, we know the list is sorted, so we can use that to our advantage. If our desired number is less than the middle number, we know that it must exist in the first half of the list. Likewise, if it is greater than the middle number, it must be in the second half. In this case, since $19$ is less than $23$, we must only look at the first half of the list.

Now we can just repeat that process, this time using only the first half of the original list. This is the powerful feature of a divide and conquer algorithm. Once we’ve figured out how to divide our data, we can usually follow the same steps again to solve the smaller problems as well.
Once again, we ask ourselves if $12$, the centermost number in the list, is the one we are looking for. Once again, it is not, but we know that $19$ is greater than $12$, so we’ll need to look in the second half of the list.

Finally, we have reduced our problem to the simplest, or base case of the problem. Here, we simply need to determine if the single item in the list is the number we are looking for. In this case, it is! So, we can return that our original list did indeed include the number $19$.
We’ll explore many ways of using divide and conquer algorithms in this course, especially when we learn to sort and search through lists of values.
Another algorithmic technique that we’ll learn about is the greedy technique. In a greedy algorithm, the program tries to build a solution one piece at a time. At each step, it will act “greedy” by choosing the piece that it thinks is the best choice for the solution based on the available information. Instead of trying every possible solution like a brute force algorithm or dividing the problem into smaller parts like the divide and conquer approach, a greedy algorithm will just try to construct the one best answer it can.
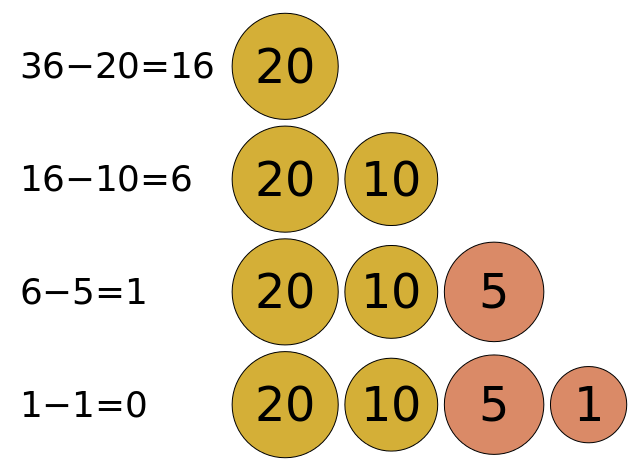
For example, we can use a greedy algorithm to determine the fewest number of coins needed to give change, as shown in the example above. If the customer is owed $36$ cents, and we have coins worth $20$ cents, $10$ cents, $5$ cents and $1$ cent, how many coins are needed to reach $36$ cents?
In a greedy solution, we could choose the coin with the highest value that is less than the change required, give that to the customer, and subtract its value from the remaining change. In this case, it will indeed produce the optimal solution.
In fact, both the United States dollar and the European euro have a system of coins that will always produce the minimum number of coins with a greedy algorithm. So that’s very helpful!
However, does it always work? What if we have a system that has coins worth $30$ cents, $18$ cents $4$ cents, and $1$ cent. Would a greedy algorithm produce the result with the minimum number of coins when making change for $36$ cents?
Let’s try it and see. First, we see that we can use a $30$ cent coin, leaving us with $6$ cents left. Then, we can use a single $4$ cent coin, as well as two $1$ cent coins for a total of $4$ coins: $30 + 4 + 1 + 1 = 36$.
Is that the minimum number of coins?
It turns out that this system includes a coin worth $18$ cents. So, to make $36$ cents, we really only need $2$ coins: $18 + 18 = 36$!
This is the biggest weakness of the greedy approach to algorithm design. A greedy algorithm will find a possible solution, but it is not guaranteed to be the best possible solution. Sometimes it will work just fine, but other times it may produce solutions that are not very good at all. So we always must consider that when creating an algorithm using a greedy technique.
File:Greedy algorithm 36 cents.svg. (2019, April 27). Wikimedia Commons, the free media repository. Retrieved 23:19, February 8, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Greedy_algorithm_36_cents.svg&oldid=347456702. ↩︎
The next algorithmic technique we’ll discuss is recursion. Recursion is closely related to the divide and conquer method we discussed earlier. However, recursion itself is a very complicated term to understand. It usually presents one of the most difficult challenges for a novice programmer to overcome when learning to write more advanced programs. Don’t worry! We’ll spend an entire module on recursion later in this course.
There are many different ways to define recursion. In one sense, recursion is a problem solving technique where the solution to a problem depends on solutions to smaller versions of the problem, very similar to the divide and conquer approach.
However, to most programmers, the term recursion is used to describe a function or method that calls itself inside of its own code. It may seem strange at first, but there are many instances in programming where a method can actually call itself again to help solve a difficult problem. However, writing recursive programs can be tricky at first, since there are many ways to make simple errors using recursion that cause our programs to break.
Mastering recursion takes quite a bit of time and practice, and nearly every programmer has a strong memory of the first time recursion made sense in their minds. So, it is important to make sure we understand it! In fact, it is so notable, that when we search for “recursion” on Google, it helpfully prompts us if we want to search for “recursion” instead, as seen at the top of this page.
A great example of a recursive method is calculating the factorial of a number. We may recall from mathematics that the factorial of a number is the product of each integer from 1 up to and including that number. For example, the factorial of $5$, written as $5!$, is calculated as $5 * 4 * 3 * 2 * 1 = 120$
We can easily write a traditional method to calculate the factorial of a number as follows.
function ITERATIVE_FACTORIAL(N)
RESULT = 1
loop I from 1 to N:
RESULT = RESULT * I
end loop
return RESULT
end functionHowever, we may also realize that the value of $5!$ is the same as $4! * 5$. If we already know how to find the factorial of $4$, we can just multiply that result by $5$ to find the factorial of $5$. As it turns out, there are many problems in the real world that work just like this, and, in fact, many of the data structures we’ll learn about are built in a similar way.
We can rewrite this iterative function to be a recursive function instead.
function RECURSIVE_FACTORIAL(N)
if N == 1
return 1
else
return N * RECURSIVE_FACTORIAL(N - 1)
end if
end functionAs we can see, a recursive function includes two important elements, the base case and a recursive case. We need to include the base case so we can stop calling our recursive function over and over again, and actually reach a solution. This is similar to the termination condition of a for loop or while loop. If we forget to include the base case, our program will recurse infinitely!
The second part, the recursive case, is used to reduce the problem to a smaller version of the same problem. In this case, we reduce $N!$ to $N * (N - 1)!$. Then, we can just call our function again to solve the problem $(N - 1)!$, and multiply the result by $N$ to find the solution to $N!$.
So, if we have a problem that can be reduced to a smaller instance of itself, we may be able to use recursion to solve it!
Beyond the algorithmic techniques we’ve introduced so far, there are a number of techniques that deal specifically with data stored in non-linear data structures based on graphs. Generally speaking, we can group all of these algorithms under the heading graph traversal algorithms.
A graph traversal algorithm constructs an answer to a problem by moving between nodes in a graph using the graph’s edges, thereby traversing the graph. For example, a graph traversal algorithm could be used by a mapping program to construct a route from one city to another on a map, or to determine friends in common on a social networking website.
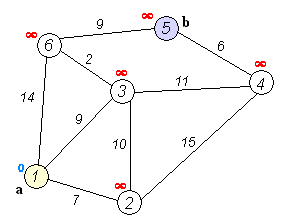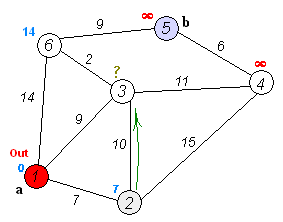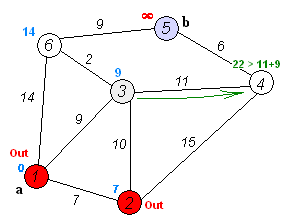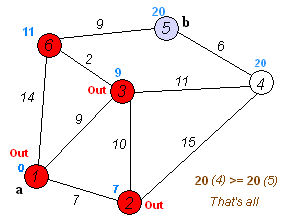
A great example of a graph traversal algorithm is Dijkstra’s Algorithm, which can be used to find the shortest path between two selected nodes in a graph. In the image above, we can see the process of running Dijkstra’s Algorithm on a graph that contains just a few nodes.
Of course, we can use the same approach on any open space, as seen in this animation. Starting at the lower left corner, the algorithm slowly works toward the goal node, but it eventually runs into an obstacle. So, it must find a way around the obstacle while still finding the shortest path to the goal.
Algorithms such as Dijkstra’s Algorithm, and a more refined version called the A* Algorithm are used in many different computer programs to help find a path between two points, especially in video games.
File:Dijkstra Animation.gif. (2018, November 24). Wikimedia Commons, the free media repository. Retrieved 01:45, February 9, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Dijkstra_Animation.gif&oldid=329177321. ↩︎ ↩︎
In this course, we will learn how to develop several different data structures, and then use those data structures in programs that implement several different types of algorithms. However, one of the most difficult parts of programming is clearly explaining what a program should do and how it should perform.
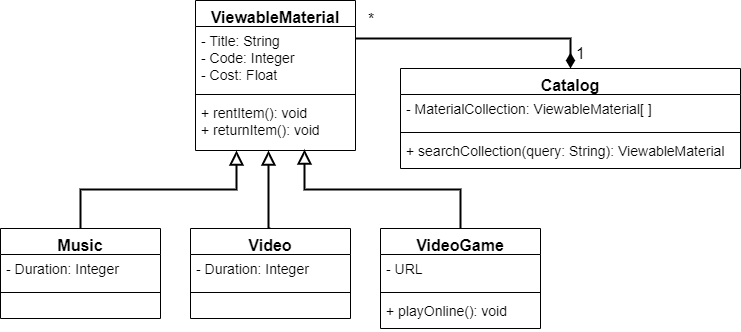
So far, we’ve used UML class diagrams to discuss the structure of a program. It can give us information about the classes, attributes, and methods that our program will contain, as well as the overall relationships between the classes. We can even learn if attributes and methods are private or public, and more.
However, to describe what each method does, we have simply relied on descriptions in plain language up to this point, with no specific format at all. In this module, we’ll introduce the concept of programming by contract to help us provide more specific information about what each method should do and the expectations we can count on based on the inputs and outputs of the method.
Specifically, we’ll learn about the preconditions that are applied to the parameters of a method to make sure they are valid, the postconditions that the method will guarantee if the preconditions are met, and the invariants that a loop or data structure will maintain.
Finally, we can put all of that information together to discuss how to prove that an algorithm correctly performs the task it was meant to, and how to make sure that it works correctly in all possible cases.
First, let’s discuss preconditions. A precondition is an expectation applied to any parameters and existing variables when a method or function is called. Phrased a different way, the preconditions should all be true before the method is called. If all of the preconditions are met, the function can proceed and is expected to function properly. However, if any one of the preconditions are not met, the function may either reach an exception, prompt the user to correct the issue, or produce invalid output, depending on how it is written.
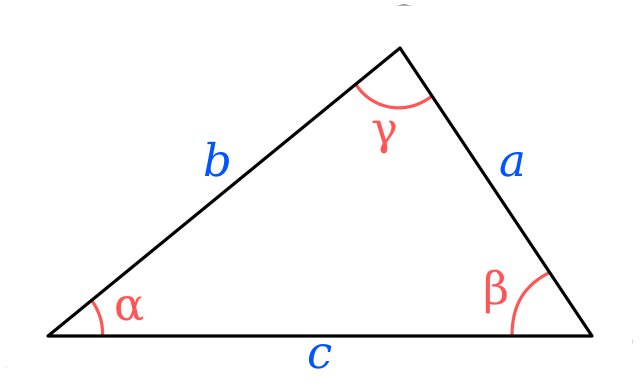
Let’s consider an example method to see how we can define the preconditions applied to that method. In this example, we’re going to write a method triangleArea(side1, side2, side3) that will calculate the area of a triangle, given the lengths of the sides of the triangle.
So, to determine what the preconditions of that method should be, we must think about what we know about a triangle and what sort of data we expect to receive.
For example, we know that the length of each side should be a number. In addition, those lengths should all be positive, so each one must be strictly greater than $0$.
We can also determine if we expect the length to be whole numbers or floating-point numbers. To make this example simpler, let’s just work with whole numbers.
When looking at preconditions, determining the types and expected range of values of each parameter is a major first step. However, sometimes we must also look at the relationship between the parameters to find additional preconditions that we must consider.
For example, the triangle inequality states that the longest side of a triangle must be strictly shorter than the sum of the other two sides. Otherwise, those sides will not create a triangle. So, another precondition must state that the sides satisfy the triangle inequality.
All together, we’ve found the following preconditions for our method triangleArea(side1, side2, side3):
side1, side2 and side3 each must each be an integer that is strictly greater than $0$side1, side2 and side3 must satisfy the triangle inequalityWhat if our method is called and provided a set of parameters that do not meet the preconditions described above? As a programmer, there are several actions we can take in our code to deal with the situation.
One of the most common ways to handle precondition failures is to simply throw or raise exceptions from our method as soon as it determines that the preconditions are not met. In this way, we can quickly indicate that the program is unable to perform the requested operation, and leave it up to the code that called that method to either handle the exception or ignore it and allow the program to crash.
This method is best used within the model portions of a program written using the Model-View-Controller or MVC architecture. By doing so, this allows our controller to react to problems quickly, usually by requesting additional input from the user using the view portion of the program.
In simpler programs, it is common for the code to simply handle the precondition failure by asking the user for new input. This is commonly done in programs that are small enough to fit in a single class, instead of being developed using MVC architecture.
Of course, we could choose to simply ignore these precondition failures and allow our code to continue running. IN that case, if the preconditions are not met, then the answer we receive may be completely invalid. On the next page, we’ll discuss how failed preconditions affect whether we can trust our method’s output.
File:TriangleInequality.svg. (2015, July 10). Wikimedia Commons, the free media repository. Retrieved 23:22, January 21, 2020 from https://commons.wikimedia.org/w/index.php?title=File:TriangleInequality.svg&oldid=165448754. ↩︎
Next, we can discuss postconditions. A postcondition is a statement that is guaranteed to be true after a method is executed, provided all of the preconditions were met. If any one of the preconditions were not met, then we can’t count on the postcondition being true either. This is the most important concept surrounding preconditions and postconditions.
If the preconditions of a method are all true when a method is called, then we may assume the postconditions are true after the method is complete, provided it is written correctly.
On the last page, we discussed the preconditions for a method triangleArea(side1, side2, side3) that will calculate the area of a triangle given the lengths of its sides. Those preconditions are:
side1, side2 and side3 each must each be an integer that is strictly greater than $0$side1, side2 and side3 must satisfy the triangle inequalitySo, once the method completes, what should our postcondition be? In this case, we want to find a statement that would be always true if all of the preconditions are met.
Since the method will be calculating the area of the triangle, the strongest postcondition we can use is the most obvious one:
side1, side2 and side3That’s really it!
Of course, there are a few other postconditions that we could consider, especially when we start working with data structures and objects. For example, one of the most powerful postconditions is the statement:
When we call a method that accepts an array or object as a parameter, we know that we can modify the values stored in that array or object because the parameter is handled in a call-by-reference fashion in most languages. So, if we don’t state that this postcondition applies, we can’t guarantee that the method did not change the values in the array or object we provided as a parameter.
So, what if the preconditions are not met? Then what happens?
As we discussed on the previous page, if the preconditions are not met, then we cannot guarantee that the postcondition will be true once the method executes. In fact, it may be decidedly incorrect, depending on how we implement the method.
For example, the simplest way to find the area of a triangle given the lengths of all three sides is Heron’s formula, which can be written mathematically as:
$$ A = 1/4 \sqrt{(a + b + c)(-a + b + c)(a - b + c)(a + b - c)} $$Since this is a mathematical formula, it is always possible to get a result from it, even if all of the preconditions are not met. For example, the inputs could be floating-point values instead of integers, or they may not satisfy the triangle inequality. In that case, the function may still produce a result, but it will not represent the actual area of the triangle described, mainly because the parameters provided describe a triangle that cannot exist in the real world. So, we must always be careful not to assume that a method will always provide the correct output unless we provide parameters that make all of its preconditions true.
File:Triangle with notations 2 without points.svg. (2018, December 5). Wikimedia Commons, the free media repository. Retrieved 00:03, January 22, 2020 from https://commons.wikimedia.org/w/index.php?title=File:Triangle_with_notations_2_without_points.svg&oldid=330397605. ↩︎
Once we’ve written a program, how can we verify that it works correctly? There are many ways to do this, but one of the most common is unit testing.
Unit testing a program involves writing code that actually runs the program and verifies that it works correctly. In addition, many unit tests will also check that the program produces appropriate errors when given bad input, or even that it won’t crash when given invalid input.
For example, a simple unit test for the maximum() method would be:
function MAXIMUMTEST()
ARRAY = new array[5]
ARRAY[0] = 5
ARRAY[1] = 25
ARRAY[2] = 10
ARRAY[3] = 15
ARRAY[4] = 0
RESULT = MAXIMUM(ARRAY)
if RESULT == 25:
print "Test Passed"
end if
end functionThis code will simply create an array that we know the maximum value of, and then confirm that our own maximum() method will find the correct result.
Of course, this is a very simplistic unit test, and it would take several more unit tests to fully confirm that the maximum() method works completely correctly.
However, it is important to understand how this test relates to the preconditions and postconditions that were established on previous pages. Here, the unit tests creates a variable ARRAY which is an array of at least one numerical value. Therefore, it has met the preconditions for the maximum() method, so we can assume that if maximum() is written correctly, then the postconditions will be true once it is has executed. This is the key assumption behind unit tests.
In this course, you will be asked to build several data structures and implement algorithms that use those data structures. In the assignment descriptions, we may describe these methods using the preconditions and postconditions applied to them. Similarly, we’ll learn about structural invariants of data structures, which help us ensure that your data structures are always valid.
Then, to grade your work, we use an autograder that contains several unit tests. Those unit tests are used to confirm that you code works correctly, and they do so by providing input that either satisfies the preconditions, meaning that the test expects that the postconditions will be true, or by providing invalid input and testing how your code reacts to those situations.
You’ll see these concepts throughout this course, so it is important to be familiar with them now.
In this chapter, we introduced a number of different data structures that we can use in our programs. In addition, we explored several algorithmic techniques we can use to develop algorithms that manipulate these data structures to allow us to solve complex problems in our code.
Throughout the rest of this course, as well as a subsequent course, we’ll explore many of these data structures and techniques in detail. We hope that introducing them all at the same time here will allow us to compare and contrast each one as we learn more about it, while still keeping in mind that there are many different structures and techniques that will be available to us in the future.