Chapter 7
Hash Tables
Maps, Hash Tables, and Dictionaries!
Maps, Hash Tables, and Dictionaries!
A hash table is an unordered collection of key-value pairs, where each key is unique. The great thing about hash tables is that they provide efficient insertion, removal and lookup operations that arrays and linked lists cannot match, such as:
A hash table consists of three components:
A user basically stores a key-value pair in the hash table where the key is used to identify the key-value pair as well as compute where it will be stored. For instance, if we consider all the students in a university, we can store student information (name, address, phone, major, GPA, courses, etc.) in the hash table using their name as the key. Storing a key-value pair in a hash table uses the following procedure.

Retrieving a key-value pair from the hash table follows a similar procedure.
Ideally, it would be nice if there was only a single key-value pair stored in each bucket. However, we cannot guarantee this so we use a linked list to allow us to store multiple items whose key produces the same index.
Another data type that is similar to hash tables and is built into many modern programming languages, is the dictionary or an associative array. A dictionary is a collection of key-value pairs that is directly indexed by a key instead of an integer. These keys can be an integer, a string, or other data types. Dictionaries typically support the following operations:
As you can see dictionaries and hash tables are very similar in their basic operation. However, an important difference is that hash tables tend to allow any type of objects as the value in the key-value pairs, while dictionaries typically require a specific type of object to be the value. A dictionary can be implemented using a variety of data structures including linked lists and hash tables.
As stated previously, a hash table has three main components: an array, a hash function, and a set of buckets that store key-value pairs. We discuss the implementation of these below.
We use an array to hold pointers to the buckets where the key-value pairs are stored. While the array itself is a common data type found in almost every language, there are some important aspects to the arrays used in hash tables.
First, the array must be large enough to store our key-value pairs without too many collisions. A collision occurs when two key-value pairs map to the same array index. Although we cannot keep this from happening, the fewer collisions, the faster the hash table. Thus, the larger the array, the lower the chance for collisions. We capture the size of the array as its capacity.
In the example below, both hash tables are storing the same number of key-value pairs. However, the capacity of the array on the right is more than twice as large as the one on the left. To retrieve a random key-value pair from each of these arrays requires a search of one of the linked list buckets. For the array on the left, the average number of nodes searched is $1.8$, while for the array on the right it is only $1.2$. Thus, in this example doubling the capacity of our array provides a $33\%$ reduction in the time required to retrieve a key-value pair. (Note that these statistics were computed based on these particular array capacities and the number of key-value pairs in the example.)

Second, the array should be re-sizable. Since we generally do not know in advance how many key-value pairs we have to store in our hash table, we need to be able to resize our array when the number of key-value pairs reaches a predefined threshold. This threshold is based on the loading factor, which we define next.
As we store more key-value pairs in a hash table, the number of collisions will increase. The more collisions we have, the less efficient our hash table will become. Thus, at some point, it makes sense to increase the capacity of the array and rehash our table, which means we compute new indexes for all key-value pairs and add them into the new array. The question is, when is the appropriate time to do this?
Traditionally, we answer this question using a ratio of the capacity of the hash table array to the number of key-value pairs stored in the table. There are three key properties of hash tables that come into play here:
Typically, when the load factor reaches a specified threshold, we double the capacity of the array and then rehash the table using the new array. The load factor threshold we choose is a tradeoff between space and time. The larger the array, the more memory you use, but with fewer collisions. Obviously, using a smaller array increases the number of collisions as well as the time it takes to retrieve key-value pairs from the table. For our examples below, we use the standard default load factor of $0.75$.
If our array was large enough to ensure our hash function would compute a unique index for each key (i.e., there would be absolutely no collisions), we could store the key-value pairs directly in the array. Unfortunately, this is almost never the case and collisions do occur. Therefore, we store the key-value pairs in buckets associated with each array index. Buckets are the general term we use to describe the mechanism we use to store key-value pairs and handle any collisions that occur. As shown in the figure below, we use linked lists to implement our buckets, which is a fairly standard approach.

As we recall, linked lists provide constant time operations for adding key-value pairs to the list and linear time operations for retrieving key-value pairs from the list. While linear time seems slow for adding a key-value pair to the list, we need to remember that we are talking only about the number of key-value pairs in a specific list, not the total number of key-value pairs in the entire hash table. Thus, as shown in the figure above, the maximum number of key-value pairs in any linked list is $2$, even though the size of the entire table is $9$. With a load factor of $0.75$ and a good quality hash function that distributes key-value pairs uniformly across the array, our linked lists generally have a small number of items ($2$ or $3$ maximum) in each list. So, even though retrieving is not technically constant time, because it is very close to it in practice, we say that it is.
A hash function converts a key into a hash code, which is an integer value that can be used to index our hash table array. Obviously, there are some hash functions that are better than others. Specifically, a good hash function is both easy to compute and should uniformly distribute the keys across our hash table array. Both of these are important factors in how fast our hash table operates, since we compute a hash code each time we insert or get a key-value pair from the hash table. If it takes too long to compute the hash code, we lose the benefits of having constant time insertion and retrieval operations. Likewise, if the function does not distribute the keys evenly across the table, we end up with several keys in the same bucket, which causes longer times to retrieve key-value pairs.
A good hash function should have three important properties.
Luckily, many modern programming languages provide native support for hash functions. Both Java and Python provide built-in hashing functions. These functions take any object and produce an integer, which we then use with the modulo operator to reduce it to the appropriate size for our array capacity. An example of how to use the Java hashCode function is shown below. More information on the Java hashCode function can be found here.
public int computeIndex(Object key){
return key.hashCode() % this.getCapacity();
}An example of using Python’s hash function is shown below. More information on hashing in Python and the hash function can be found here.
def compute_index(self, key):
return hash(key) % self.capacityAnother interesting use of hash functions deals with storing and verifying passwords. When we sign up for an account on a website, it asks us for a password that we’d like to use. Obviously, if that website just stored the password directly in their database, it could be a huge security problem if someone was able to gain access to that information. So, how can the website store a password in a way that prevents a hacker from learning our password, but the website can verify that we’ve entered the correct password?
In many cases, we can use a hash function to do just that. When we first enter our password, the website calculates the hash code for the password and then stores the result in the database.
Then, when we try to log in to the website in the future, we provide the same password, and the website is able to calculate the hash again and verify that they match. As long as the hash function is properly designed, it is very unlikely for two passwords to result in the same hash, even if they are very similar.
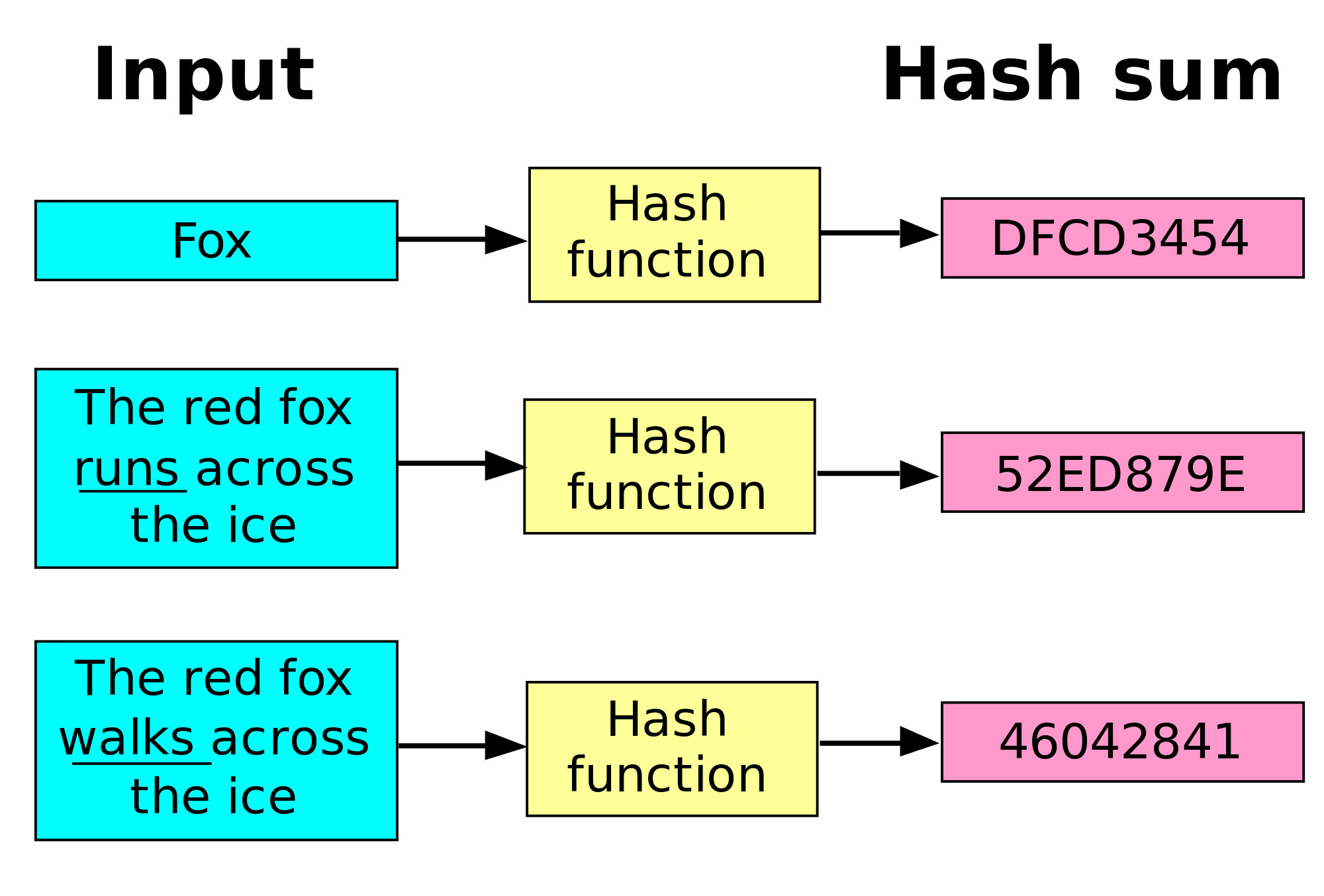
In practice, most websites add additional random data to the password before hashing it, just to decrease the chances of two passwords hashing to the same value. This is referred to as “salting” the password.
Keys allow us to easily differentiate between data items that have different values. For example, if we wanted to store student data such as first name, last name, date of birth, and identification number, it would be convenient to have one piece of data that could differentiate between all the students. However, some data are better suited to be keys than others. In general, the student’s last name tends to be more selective than the first name. However, the student identification number is even better since it is guaranteed to be unique. When a key is guaranteed to be unique, we call them primary keys. The efficiency of a key is also important. Numeric keys are more efficient than alphanumeric keys since computing hash codes with numbers is faster than computing them with characters.
Before we can start describing the basic hash table functions, we first need to create a way to handle key-value pairs. We generally refer to any piece of data that has two parts as a tuple. In the case of key-value pairs, our tuple would look like (key, value). Some languages, such as Python, provide built-in support for creating tuples, while others such as Java and C# require us to create our own tuple class, which is easy to do. All we really need our tuple class to do is to allow us to:
The pseudocode for the Tuple class is given below. Each of the operations is simple and thus we do not discuss them individually. However, notice that the class has two attributes, key and value, that are created in the constructor. The getKey and getValue operations are used often in the code below to provide access to the internals of the tuples.
class Tuple
object key = null
object value = null
function Tuple(object k, object v)
key = k
value = v
end function
function getKey() returns string
return key
end function
function getValue() returns object
return value
end function
function toString() returns string
return "(" + key.toString() + "," + value.toString() + ")"
end function
function equals(Object o) returns boolean
if o is not an instance of Tuple:
return false
end if
Tuple t = (Tuple)o
return (o.key == key) AND (o.value == value)
end functionYou won’t be asked to implement any of these operations since we will just use the built-in class in our chosen language. However, we want you to se behind the scenes and understand how a hash table is implemented directly in code.
The HashTable class has three attributes that provide the basic data structure and parameters we need to efficiently manage our table.
size - captures the number of tuples stored in the table. It is initialized to 0 in line 11 of the constructor.loadFactor - is the load factor used to determine when to increase the capacity of the array. It is initialized to 0.75 in line 12 of the constructor.hashTable - is an array of doubly linked lists. The array is actually created in line 7 of the constructor and the doubly linked lists for each location in the array are created in the loop in lines 8 and 9 of the constructor. 1class HashTable
2 int size
3 double loadFactor = 0.75
4 doubleLinkedList[] hashTable
5
6 function HashTable()
7 hashTable = new doubleLinkedList[16]
8 for i = 0 to hashTable.length
9 hashTable[i] = new doubleLinkedList()
10 end for
11 size = 0
12 loadFactor = 0.75
13 end functionWe assume we are using the language-specific hash code function to actually generate our hash code. However, we need to convert that number (typically a very large integer) to an index for our array, which has a limited capacity. Therefore, we use the modulo function in line 2 to convert the hash code into the range of 0 to the capacity of the array. The computeIndex operation runs in constant time.
1function computeIndex(object key) returns integer
2 return hashCode(key) % getCapacity()
3end functionThe put operation is an important hash table operation, whose goal is to place a key-value pair into the right linked list. We start by calling computeIndex to find which linked list we should store the key-value pair in, which we can access using hashTable[index]. Next, we check to see if the key has already been stored in the table by iterating through the list found at that location in the table. If the key has already been stored, we should update the value in that tuple to be the new value in line 9 and return on line 10. If the key isn’t found, then we actually store the key-value pair in the table by calling the append operation for the hashTable[index] linked list on line 15. Notice, we create a new Tuple using the key and value input parameters before we call append. Since we successfully added the new tuple, we increment the size attribute to keep track of the number of tuples stored in the table.
1function put(object key, object value)
2 index = computeIndex(key)
3
4 hashTable[index].reset()
5 current = hashTable[index].getNext()
6
7 while current != null
8 if current.key == key
9 current.value = value
10 return
11 end if
12 current = hashTable[index].getNext()
13 end while
14
15 hashTable[index].append(new Tuple(key, value))
16 size = size + 1
17
18 if size/capacity > loadFactor
19 doubleCapacity()
20 end if
21end functionSince we have added a new tuple to the table, we need to check to see if the size of the table exceeds our load factor. Therefore, in line 18, we check to see if the value of size/capacity exceeds our loadFactor. If it does, we call the doubleCapacity operation to double the capacity of our array and rehash the table. The doubleCapacity operation is defined below.
Since we are looping through a list of elements in the hash table, it can be difficult to analyze the running time of this method. So, we have to look at both the best case and worst case scenario. In the best case, the linked list is empty, so the entire operation runs in constant time. As long as we have a good hash function and the keys are equally distributed across the hash table, this should be the case.
However, if the hash function is poor, it could cause all of the elements in the hash table to be placed in the same list. In that case, the operation would run on the order of $N$ time, since it would have to iterate across all elements in the list.
The get operation is another important hash table operation, whose goal is to retrieve (without deleting) a key-value pair from the table. Like the put operation, the first thing we need to do is to compute the index of the key we are looking for in line 2. Once we know the index, we call the reset operation on the hashTable[index] linked list so we can call the getNext iterator function in line 4. Lines 6 - 8 are a loop that walks through each key-value pair in the linked list. If we find the key we are looking for in line 7, we return true and the operation ends. If we do not find the key, we call the getNext function to get the next element in the linked list. If we end up going through the entire loop until current != null becomes false, we fall out of the loop and return null in line 13, indicating that we did not find key in the table.
1function get(object key) returns object
2 index = computeIndex(key)
3 hashTable[index].reset()
4 current = hashTable[index].getNext()
5
6 while current != null
7 if current.key == key
8 return current.value
9 end if
10 current = hashTable[index].getNext()
11 end while
12
13 return null
14end functionAs discussed above, although we do end up looping through one of the linked lists in the hash table, these lists are much, much smaller than the overall size of the hash table under most normal circumstances. Thus, we say that the get operation runs in constant time in the best case.
The remove operation is much like the get operation above, except that when we find the key we are searching for, we remove the key-value pair from the appropriate linked-list and return the value to the calling function. The only real difference in the operations lies in the loop intervals in lines 8 and 9. Here, when we find the key in the list, we call the removeCurrent operation to remove the key-value pair from the linked list and then decrement size by 1. Line 10 then returns current.value.
1function remove(object key) returns object
2 index = computeIndex(key)
3 hashTable[index].reset()
4 current = hashTable[index].getNext()
5
6 while current != null
7 if current.key == key
8 hashTable[index].removeCurrent()
9 size = size – 1
10 return current.value
11 end if
12 current = hashTable[index].getNext()
13 end while
14
15 return null
16end functionLike the get operation above, we loop through one of the linked lists in the hash table. However, given the relatively small size of the list, we assume the remove operation runs in constant time in the best case.
The containsKey operation returns a Boolean value based on whether we find the requested key in the table. Since the get operation already finds the key-value pair associated with a given key, we simply call get and then compute whether the key-value pair returned from get exists to compute the containsKey return value. The containsKey operation runs in constant time in the best case.
1function containsKey(object key) returns boolean
2 return get(key) != null
3end functionThe containsValue operation is not as simple as containsKey since we don’t already have an operation to use to search for a value in our hash table. Since we are not given a key to search for, we cannot use the computeIndex to tell us which linked list to search for our value. Therefore, we need to start at the beginning of our array and loop through each element, searching each of the linked lists stored there for our value.
Line 1 is our outside loop that walks through each linked list stored in our array. Within that loop, we follow the same search process we used in the get operation to search through hashTable[i]. We set up the iterator in lines 3 and 4 and then walk through the linked list in the loop in lines 6 - 9. The only difference in this search process is what we are searching for. In line 7, instead of checking if the keys are equal, we check to see if the values are equal. If they are, we return true. However, if we do not find the value somewhere in the table, we must search through every key-value pair in the table, thus the time complexity for containsValue is order $N$.
1function containsValue(object value) returns boolean
2 for i = 0 to getCapacity()
3 hashTable[i].reset()
4 current = hashTable[i].getNext()
5
6 while current != null
7 if current.value == value
8 return true
9 current = hashTable[i].getNext()
10 end while
11 end for
12
13 return false
14end functionThe getSize function is very simple. It simply returns the HashTable class’ size attribute.
1function getSize() returns integer
2 return size
3end functionLike the getSize function, getCapacity simply returns the length of the hashTable array.
1function getCapacity() returns integer
2 return length of the hashTable array
3end functionThe isEmpty operation simply returns the Boolean value of whether or not the size attribute is 0.
1function isEmpty() returns boolean
2 return size == 0
3end functionThe copy operation is similar to the containsValue operation in that it must walk through the entire hash table to get all the key-value pairs in the table and put them into the new hash table. Line 2 creates the new empty hash table, which we call copy.
The for loop in line 4 walks through the hashTable array, allowing us to access each linked list using hashTable[i]. Within the loop we use the linked list iterator functions (lines 5, 6, and 10) to walk through each key-value pair in the linked lists. For each key-value pair, we call copy.put to insert that key-value pair into the copy hash table. Once we have completed both loops, we return the copy in line 14. Like the containsValue operation, since we walk through each key-value pair in the hash table, the copy operation runs in order $N$ time.
1function copy() returns HashTable
2 HashTable copy = new HashTable()
3
4 for i = 0 to getCapacity()
5 hashTable[i].reset()
6 current = hashTable[i].getNext()
7
8 while current != null
9 copy.put(current.key, current.value)
10 current = hashTable[i].getNext()
11 end while
12 end for
13
14 return copy
15end functionThe toString operation is almost identical to the copy operation above, except that instead of inserting each key-value pair into a second hash table, we append the string representation of each key-value pair to an output string. In fact, the only differences to the pseudocode come in lines 2, 9, and 10. Line 2 creates a new empty string and line 13 returns that string after walking through the hash table. Finally, line 9 is where we append the current key-value pair’s string representation to the output string. We also append a comma to separate the key-value pairs in output. Like the copy operation, the toString operation runs in order $N$ time.
1function toString() returns string
2 string output = null
3
4 for i = 0 to getCapacity()
5 hashTable[i].reset()
6 current = hashTable[i].getNext()
7
8 while current != null
9 output += current.toString() + ", "
10 current = hashTable[i].getNext()
11 end while
12 end for
13 return output
14end functionThe doubleCapacity operation is similar to the same operations for the array-based stack and queue implementations that we covered earlier. First, we create a new array with twice the capacity of the existing hashTable. Next, we “rehash” each of the key-value pairs in hashTable into the new table. Finally, we point the hashTable attribute at the new table.
The implementation of this process is captured in the following pseudocode. In line 2, we double the size of capacity. It is important to update capacity first so we can use the new value when creating the new hash table array. It is especially important to use this new capacity when calculating the indexes for key-value pairs in the new table.
1function doubleCapacity()
2 capacity = capacity * 2
3 doubleLinkedList[] newTable = new doubleLinkedList[getCapacity()]
4
5 for i = 0 to getCapacity()
6 newTable[i] = new doubleLinkedList()
7 end for
8
9 for i = 0 to getCapacity() / 2
10 hashTable[i].reset()
11 current = hashTable[i].getNext()
12
13 while current != null
14 index = computeIndex(current.key)
15 newTable[index].append(current)
16 current = hashTable[i].getNext()
17 end while
18 end for
19
20 hashTable = newTable
21end functionLine 2 creates a new array called newTable with twice the capacity of the existing table. In lines 5 and 6, we create a new doubly linked list for each element of newTable. Then, in lines 9 - 16 we employ the same looping structure used above in copy and toString to walk through each key-value pair in hashTable. Then for each key-value pair, we compute its new index and then append the key-value pair to the linked list at hashTable[index]. Once we have completed the copying process, we fall out of the loop. Our final action is to point the hashTable attribute at newTable. Like the copy and toString operations, the run time of doubleCapacity is order $N$.
While we do not present the iterator operations here, they are useful operations for hash tables. They are implemented similarly to the other iterator functions we have studied, except that in order to walk through the entire hash table we need to use nested loops where the outside loop walks through the array and the internal loop walks through each linked list. This is very similar to the looping structure in doubleCapacity above.
In this section, we walk through the pseudocode for some basic set operations built on our hash table class above. In this new version of the set class, we declare mySet as a hash table and use that throughout our operations.
mySet = new HashTable()When using a hash table to implement sets, one of the most important choices we must make is what to use for a key. This is really difficult in the case of sets since we do not know exactly what types of objects may be put into the set. Our only real option at this point is just to use the entire object as our key. Our choice to use a default hash function in our hash table turns out to be a good one (at least in modern languages such as Python, Java, and C#), since most default hash functions work on any type of objects.
Next, we discuss the implementation of the important set operations using hash tables.
The contains operation is straightforward since we are using the entire object as the key. We simply return the value from the hash table containsKey operation, which performs the exact function we need.
function contains(object o) returns boolean
return mySet.containsKey(o)
end functionThe add operation maps almost exactly to the hash table put operation except that the put operation does not return a boolean value. So, we first check to see if the key is already contained in the hash table. If so, we just return false, since we don’t need to add the value to the set. Otherwise, we add a new tuple to the hash table, and then return true.
function add(object o) returns boolean
if mySet.containsKey(o)
return false
end if
mySet.put(o, o)
return true
end functionThe set remove operation maps almost exactly to the hash table remove operation, so we just call it and then check to see if the result is not null. If it is null, we will return false since the element was not in the set; otherwise we return true.
function remove(object o) returns boolean
return mySet.remove(o) != null
end functionThe intersection operation creates a new set that has only elements which exist in both sets under consideration. In code, we basically accomplish this by looping through the elements in one set and then checking to see if they exist in the other set. If they do, then we include them in the intersection.
The pseudocode follows that basic algorithm using the hash table iterator to loop through and look at each element in set1. We start by creating a new set, result, to hold the intersection of set1 and set2 in line 2. Then we get the first element pair from set1 by calling the hash table reset operation in line 2 and the getNext operation in line 3.
1function intersection(set1, set2) returns set
2 result = new Set()
3
4 set1.reset()
5 current = set1.getNext()
6 while current != null
7 if set2.contains(current.getKey())
8 result.add(current.getKey())
9 end if
10 current = set1.getNext()
11 end while
12
13 return result
14end functionLines 6 - 10 implement the loop that walks through each element in set1. If the current element is contained in set2 (line 7), the operation calls the add operation to insert the key of the current element into the result set. Line 10 gets the next element from set1 and loops back to the top.
Eventually, we look at each element in set1 and fall out of the loop. When that happens, the intersection operation is complete, and it returns the result set in line 13.
The union operation is similar to the intersection operation in that we need to use the hash table iterator operations to walk through our sets. The difference lies in what we include in the new result set. While we only walked through set1 in the intersection operation, picking only those objects that existed in set2, here we start by copying all elements from set2 into the result set and then walk through set1 adding each of its elements to the result set as well. (Here we don’t need to worry about adding duplicates since the add operation takes care of that for us.)
The code starts in line 2 by making a copy of set2 and assigning it to our new result set. Then, lines 4 and 5 reset the set1 iterator and get the first item from set1. Lines 6 - 8 form the while loop that we use to walk through each element in set1. This time, however, we simply add every element we find in line 7 before getting the next object in line 8. Once the loop exists we are done and we return the result set in line 11.
1function union(set1, set2) returns set
2 result = set2.copy()
3
4 set1.reset()
5 current = set1.getNext()
6 while current != null
7 result.add(current.getKey())
8 current = set1.getNext()
9 end while
10
11 return result
12end functionThe isSubset operation below is very much like the intersection operation above as we have a loop in lines 4 - 8 that checks each element of set1 and checks to see if it is in set2. The difference between the two operations is that in the isSubset operation, we do not build a third result set. Instead, if any element in set1 is not found in set2, then we return false since not all elements of set1 are contained in set2. If we get all the way through the loop, we have checked that each element in set1 was found in set2 and we can return true; set1 is a subset of set2.
1function isSubset (set1, set2) returns boolean
2 set1.reset()
3 current = set1.getNext()
4 while current != null
5 if set2.contains(current.getKey())
6 return false
7 end if
8 current = set1.getNext()
9 end while
10
11 return true
12end functionIn this module, we introduced the concept of a hash table, which is a data structure that provides efficient insertion and retrieval operations. We introduced the three essential elements of hash tables:
We then discussed how to implement a hash table class. In our implementation, we chose to use built-in, language-specific hash code functions to generate the indexes into our array. We also used doubly linked lists to implement our buckets as linked lists are very flexible and provide constant time insertion operations. To demonstrate the effectiveness of hash tables, we re-implemented our set class using hash tables instead of linked lists. In many ways, the re-implementation was almost identical to the linked list implementation since many of the operations found in hash tables are almost identical to those found in linked lists. We also noted that the biggest advantage of implementing sets with hash tables is the (almost!) constant time retrieval operations provided by hash tables.