Introduction
YouTube VideoIn CC310 we covered various data structures: stacks, sets, lists, queues, and hash tables. When we looked at these structures, we considered how to access elements within the structures, how we would create our own implementation of the structure, and tasks that these structures would be fitting for as well as ill fitting. Throughout this course we will introduce and implement a variety of data structures as we did in CC310.
We begin this course with an often overlooked structure: strings. By the end of this chapter, we will understand how strings are data structures, how we access elements, what types of tasks are appropriate for strings, and how we can improve on strings in our code.
Motivation
In many data science positions, programmers often work with text-based data. Some examples of text-based data include biology for DNA sequencing, social media for sentiment classification, online libraries for citation networks, and many other types of businesses for data analytics. Currently, strings are often used for word embeddings, which determine how similar or dissimilar words are to one another. An industry leading software for this application is Tensorflow for Python, which generated the image below.
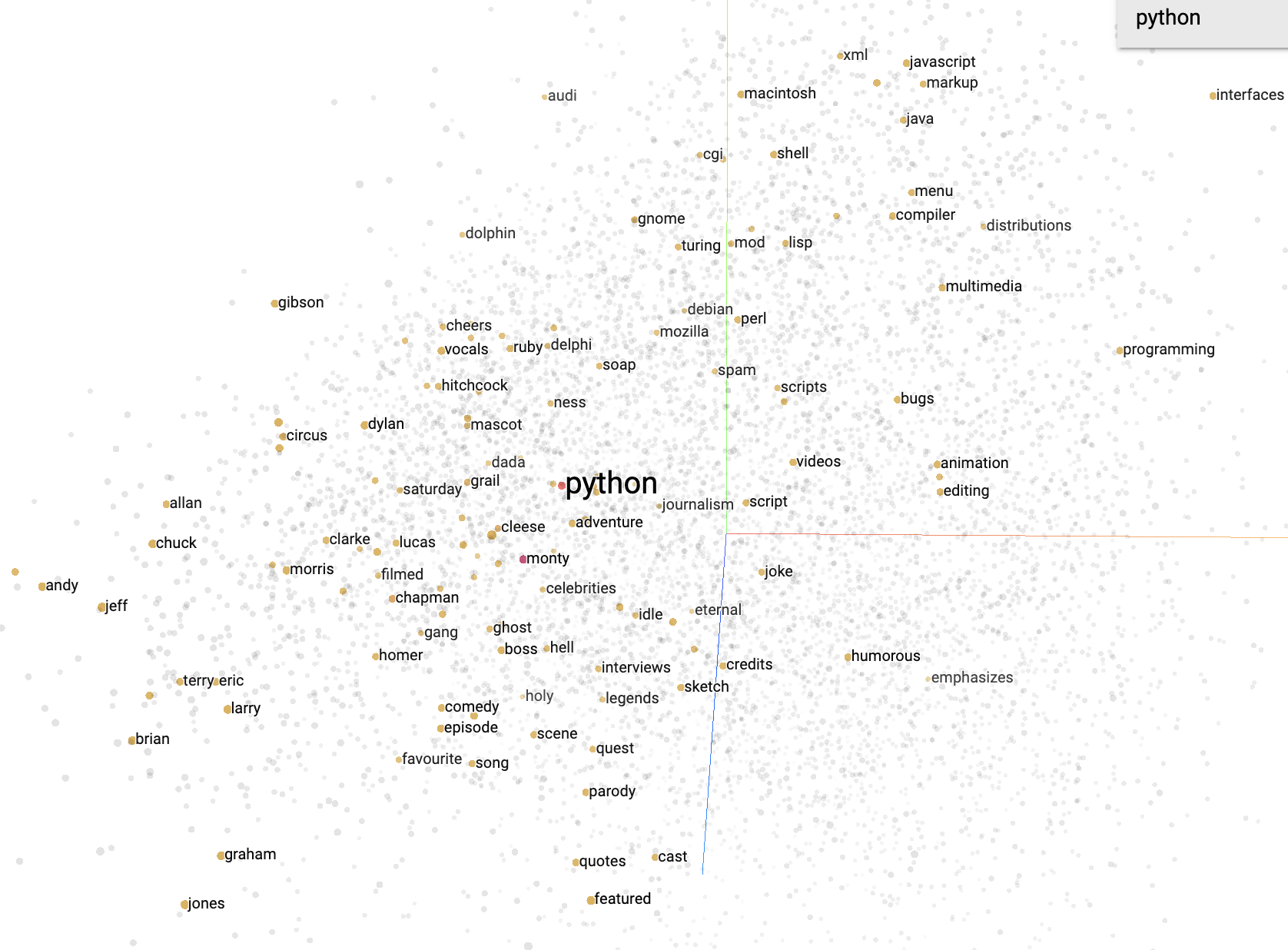
In an immense oversimplification, the process used for word embeddings is to read in a large amount of text and then use machine learning algorithms to determine similarity by using the words around each word. This impacts general users like us in search engines, streaming services, dating applications, and much more! For example, if you were to search Python topics in your search results may appear referring to the coding language, the reptile, the comedy troupe, and many more. When we use machine learning to determine word meanings, it is important that the data is first parsed correctly and stored in efficient ways so that we can access elements as needed. Understanding how to work with strings and problems that can arise with them is important to utilizing text successfully.
Reference: https://projector.tensorflow.org/