Chapter 5
Strings and StringBuilders
Welcome!
This page is the main page for the Strings and StringBuilders Section
This page is the main page for the Strings and StringBuilders Section
This page is the main page for the Strings and StringBuilders chapter
In CC310 we covered various data structures: stacks, sets, lists, queues, and hash tables. When we looked at these structures, we considered how to access elements within the structures, how we would create our own implementation of the structure, and tasks that these structures would be fitting for as well as ill fitting. Throughout this course we will introduce and implement a variety of data structures as we did in CC310.
We begin this course with an often overlooked structure: strings. By the end of this chapter, we will understand how strings are data structures, how we access elements, what types of tasks are appropriate for strings, and how we can improve on strings in our code.
In many data science positions, programmers often work with text-based data. Some examples of text-based data include biology for DNA sequencing, social media for sentiment classification, online libraries for citation networks, and many other types of businesses for data analytics. Currently, strings are often used for word embeddings, which determine how similar or dissimilar words are to one another. An industry leading software for this application is Tensorflow for Python, which generated the image below.
In an immense oversimplification, the process used for word embeddings is to read in a large amount of text and then use machine learning algorithms to determine similarity by using the words around each word. This impacts general users like us in search engines, streaming services, dating applications, and much more! For example, if you were to search Python topics in your search results may appear referring to the coding language, the reptile, the comedy troupe, and many more. When we use machine learning to determine word meanings, it is important that the data is first parsed correctly and stored in efficient ways so that we can access elements as needed. Understanding how to work with strings and problems that can arise with them is important to utilizing text successfully.
Reference: https://projector.tensorflow.org/
Strings are data structures which store an ordered set of characters. Recall that a character can be a: letter, number, symbol, punctuation mark, or white space. Strings can contain any number and any combination of these. As such, strings can be single characters, words, sentences, and even more.
Let’s refresh ourselves on how strings work, starting with the example string: s = "Go Cats!".
| Character | G | o | C | a | t | s | ! | |
| Index | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
As with other data structures, we can access elements within the string itself. Using the example above, s[0] would contain the character ‘G’, s[1] would contain the character ‘o’, s[2] would contain the character ’ ‘, and so on.
We can determine the size of a string by using length functions; in our example, the length of s would be 8. It is also important to note that when dealing with strings, null is not equivalent to “”. For string s = "", the length of s would be 0. However for string s = null, accessing the length of s would return an error that null has no length property.
We can also add to strings or append on a surface level; though it is not that simple behind the scenes. The String class is immutable. This means that changes will not happen directly to the string; when appending or inserting, code will create a new string to hold that value. More concisely, the state of an immutable object cannot change.
We cannot assign elements of the string directly and more broadly for any immutable object. For example, if we wanted the string from our example to be ‘Go Cat!!’, we cannot assign the element through s[6] = '!'. This would result in an item assignment error.
For an example, consider string s = ‘abc’. If we then state in code s = s + ‘123’, this will create a new place in memory for the new definition of s. We can verify this in code by using the id() function.
string s = 'abc'
id(s)
Output: 140240213073680 #may be different on your personal device
string s = s + '123'
id(s)
Output: 140239945470168 While on the surface it appears that we are working with the same variable, our code will actually refer to a different one. There are many other immutable data types as well as mutable data types.
On the topic of immutable, we can also discuss the converse: mutable objects. Being a mutable object means that the state of the object can change. In CC310, we often worked with arrays to implement various data structures. Arrays are mutable, so as we add, change, or remove elements from an array, the array changes its state to accommodate the change rather than creating a new location in memory.
| Data Type | Immutable? |
|---|---|
| Lists | ☐ |
| Sets | ☐ |
| Byte Arrays | ☐ |
| Dictionaries | ☐ |
| Strings | ☑ |
| Ints | ☑ |
| Floats | ☑ |
| Booleans | ☑ |
Reference: http://people.cs.ksu.edu/~rhowell/DataStructures/strings/strings.html
Consider the following block of pseudocode:
1. function APPENDER(NUMBER, BASE)
2. RESULT = ""
3. loop I from 1 to NUMBER
4. RESULT = RESULT + BASE
5. if I MOD 2 = 0
6. RESULT = RESULT + " "
7. else
8. RESULT = RESULT + ", "
9. end loop
10. return RESULT
11. end functionLets step through the function call with APPENDER(4,'abc') and analyze the memory that the code takes.
Recall that strings are reference variables. As such, string variables hold pointers to values and the value is stored in memory. For the following example, the HEAP refers to what is currently stored in memory and VARIABLE shows the current value of the variable RESULT.
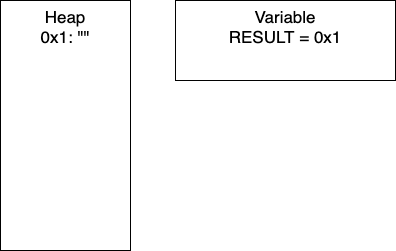
Initialization: In line two, we initialize RESULT as an empty string. In the heap, we have the empty string at memory location 0x1. Thus, RESULT is holding the pointer 0x1.
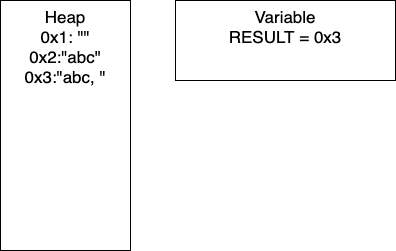
I = 1: Now we have entered the loop and on line 4, we add more characters to our string. At this point, we would have entry 0x2 in our heap and our variable RESULT would have the pointer 0x2. Continuing through the code, line 5 determines if I is divisible by 2. In this iteration I = 1, so we take the else branch. We again add characters to our string, resulting in a new entry in 0x3 and our variable RESULT containing the pointer 0x3. In total, we have written 8 characters. We then increment I and move to the next iteration.
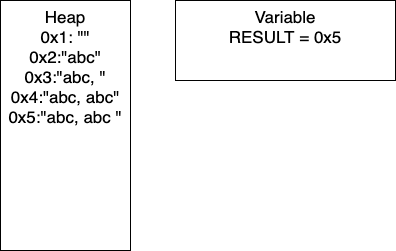
I = 2: We continue the loop and on line 4, we add more characters to our string. At this point, we would have entry 0x4 in our heap and our variable RESULT would have the pointer 0x4. Continuing through the code, line 5 determines if I is divisible by 2. In this iteration I = 2, so we take the if branch. We again add characters to our string, resulting in a new entry in 0x5 and our variable RESULT containing the pointer 0x5. In this iteration, we have written 17 characters. We then increment I and move to the next iteration of the loop.
I = 3: We continue the loop and on line 4, we add more characters to our string. At this point, we would have entry 0x6 in our heap and our variable RESULT would have the pointer 0x6. Continuing through the code, line 5 determines if I is divisible by 2. In this iteration I = 3, so we take the if branch. We again add characters to our string, resulting in a new entry in 0x7 and our variable RESULT containing the pointer 0x7. In this iteration, we have written 26 characters. We then increment I and thus I = 4 breaking out of the loop.

We can do some further analysis of the memory that is required for this particular block.
| Iteration | Memory Entries | Total Character Copies |
|---|---|---|
| 1 | 3 | 8 |
| 2 | 5 | 8 + 17 = 25 |
| 3 | 7 | 25 + 26 = 51 |
| 4 | 9 | 51 + 35 = 86 |
| . | . | . |
| n | 2n + 1 | (9n2 + 7n)/2 |
You need not worry about creating the equations! Based on this generalization, if the user wanted to do 100K iterations, say for gene sequencing, there would be (2x100,000 - 1) = 200,001 memory entries and (9x100,0002 + 7x100,000)/2 = 45 billion character copies. This behavior is not exclusive to strings; this will occur for any immutable type.
While this example is contrived, it is not too far off the mark. Another caveat to this analysis is that, depending on our programming language, there will be a periodic ‘memory collection’; there wont be 200K memory addresses occupied at one time. Writing to memory in this way can be costly in terms of time, which in industry is money.
As a result of being immutable, strings can be cumbersome to work with in certain applications. When long strings or strings that we are continually appending to, such as in the memory example, we end up creating a lot of sizable copies.
Recall from the memory example the block of pseudocode.
1. function APPENDER(NUMBER, BASE)
2. RESULT = ""
3. loop I from 1 to NUMBER
4. RESULT = RESULT + BASE
5. if I MOD 2 = 0
6. RESULT = RESULT + " "
7. else
8. RESULT = RESULT + ", "
9. end loop
10. return RESULT
11. end functionIn this example, what if we changed RESULT to a mutable type, say a list of strings for Python or a StringBuilder in Java. Once the loop is done, we can cast RESULT to a string. By changing just the one aspect of the code, we would make only one copy of RESULT and have far less character copies.
Java specifically has a StringBuilder class which was created for this precise reason.
Consider the following, and note the slight changes on lines 2, 4, 6, 8 and the additional line 10.
1. function APPENDER_LIST(NUMBER, BASE)
2. RESULT = []
3. loop I from 1 to NUMBER
4. RESULT.APPEND(BASE)
5. if I MOD 2 = 0
6. RESULT.APPEND(" ")
7. else
8. RESULT.APPEND(", ")
9. end loop
10. RESULT = "".JOIN(RESULT)
11. return RESULT
12. end functionNow consider APPENDER_LIST(4,‘abc’)
Initialization: We start by initializing the empty array. RESULT will hold the pointer 0x1.

I = 1: Now we have entered the loop and on line 4, we add more characters to our array. At this point, we would have only entry 0x1 in our heap and our variable RESULT would have the pointer 0x1. Continuing through the code, line 5 determines if I is divisible by 2. In this iteration I = 1, so we take the else branch. We again add characters to our array. In total, we have written 5 characters. We then increment I and move to the next iteration.

I = 2: We continue the loop and on line 4, we add more characters to our array. We still have just one entry in memory and our pointer is still 0x1. In this iteration, we have written 4 characters. We then increment I and move to the next iteration of the loop.

I = 3: We continue the loop and on line 4, we add more characters to our array. In this iteration, we have written 5 characters. We then increment I and thus I = 4 breaking out of the loop.
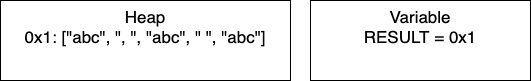
Post-Loop: Once the loop breaks, we join the array to create the final string. This creates a new place in memory and changes RESULT to contain the pointer 0x2.
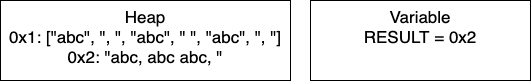
We can do some further analysis of the memory that is required for this particular block.
| Iteration | Memory Entries | Character Copies |
|---|---|---|
| 1 | 2 | 8 |
| 2 | 2 | 17 |
| 3 | 2 | 26 |
| 4 | 2 | 35 |
| . | . | . |
| n | 2 | 9n - 1 |
Again, you need not worry about creating these equations for this course. To illustrate the improvement even more explicitly, let’s consider our previous example with 100K iterations. For APPENDER there were (2x100,000 - 1) = 200,001 memory entries and (9x100,0002 + 7x100,000)/2 = 45 billion character copies. For APPENDER_LIST we now have just 2 memory entries and (9x100,000 - 1) = 899,999 character copies. This dramatic improvement was a result of changing our data structure ever so slightly.
Reference: http://people.cs.ksu.edu/~rhowell/DataStructures/strings/stringbuilders.html
As a result of being immutable, strings can be cumbersome to work with in certain applications. When working with long strings or strings that we are continually appending to, such as in the memory example, we end up creating a lot of sizable copies.
Recall from the memory example the block of pseudocode.
1. function APPENDER(NUMBER, BASE)
2. RESULT = ""
3. loop I from 1 to NUMBER
4. RESULT = RESULT + BASE
5. if I MOD 2 = 0
6. RESULT = RESULT + " "
7. else
8. RESULT = RESULT + ", "
9. end loop
10. return RESULT
11. end functionIn this example, what if we changed RESULT to a mutable type, such as a StringBuilder in Java. Once the loop is done, we can cast RESULT to a string. By changing just the one aspect of the code, we would make only one copy of RESULT and have far less character copies.
Java specifically has a StringBuilder class which was created for this precise reason.
Consider the following, and note the slight changes on lines 2, 4, 6, 8 and the additional line 10.
1. function APPENDER_LIST(NUMBER, BASE)
2. RESULT = []
3. loop I from 1 to NUMBER
4. RESULT.APPEND(BASE)
5. if I MOD 2 = 0
6. RESULT.APPEND(" ")
7. else
8. RESULT.APPEND(", ")
9. end loop
10. RESULT = "".JOIN(RESULT)
11. return RESULT
12. end functionNow consider APPENDER_LIST(4,‘abc’)
Initialization: We start by initializing the empty array. RESULT will hold the pointer 0x1.
I = 1: Now we have entered the loop and on line 4, we add more characters to our array. At this point, we would have only entry 0x1 in our heap and our variable RESULT would have the pointer 0x1. Continuing through the code, line 5 determines if I is divisible by 2. In this iteration I = 1, so we take the else branch. We again add characters to our array. In total, we have written 5 characters. We then increment I and move to the next iteration.
I = 2: We continue the loop and on line 4, we add more characters to our array. We still have just one entry in memory and our pointer is still 0x1. In this iteration, we have written 4 characters. We then increment I and move to the next iteration of the loop.
I = 3: We continue the loop and on line 4, we add more characters to our array. In this iteration, we have written 5 characters. We then increment I and thus I = 4 breaking out of the loop.
Post-Loop: Once the loop breaks, we join the array to create the final string. This creates a new place in memory and changes RESULT to contain the pointer 0x2.
We can do some further analysis of the memory that is required for this particular block.
| Iteration | Memory Entries | Character Copies |
|---|---|---|
| 1 | 2 | 8 |
| 2 | 2 | 17 |
| 3 | 2 | 26 |
| 4 | 2 | 35 |
| . | . | . |
| n | 2 | 9n - 1 |
Again, you need not worry about creating these equations for this course. To illustrate the improvement even more explicitly, let’s consider our previous example with 100K iterations. For APPENDER there were (2x100,000 - 1) = 200,001 memory entries and (9x100,0002 + 7x100,000)/2 = 45 billion character copies. For APPENDER_LIST we now have just 2 memory entries and (9x100,000 - 1) = 899,999 character copies. This dramatic improvement was a result of changing our data structure ever so slightly.
Reference: http://people.cs.ksu.edu/~rhowell/DataStructures/strings/stringbuilders.html
To start this course, we have looked into strings. They are a very natural way to represent data, especially in real world applications. Often though, the datapoints can be very large and require multiple modifications. We also examined how strings work: element access, retrieving the size, and modifying them. We looked into some alternatives which included StringBuilders for Java and character arrays for Python.
To really understand this point, we have included a comparison. We have implemented the APPENDER and APPENDER_LIST functions in both Python and Java. For the Java implementation, we utilized StringBuilders.
1. function APPENDER(NUMBER, BASE)
2. RESULT = ""
3. loop I from 1 to NUMBER
4. RESULT = RESULT + BASE
5. if I MOD 2 = 0
6. RESULT = RESULT + " "
7. else
8. RESULT = RESULT + ", "
9. end loop
10. return RESULT
11. end function1. function APPENDER_LIST(NUMBER, BASE)
2. RESULT = []
3. loop I from 1 to NUMBER
4. RESULT.APPEND(BASE)
5. if I MOD 2 = 0
6. RESULT.APPEND(" ")
7. else
8. RESULT.APPEND(", ")
9. end loop
10. RESULT = "".JOIN(RESULT)
11. return RESULT
12. end functionFor the tests of 108 and 109 in Java, the string implementation took over 24 hours and the StringBuilder implementation ran out of memory. For these reasons, they are omitted from the figure.
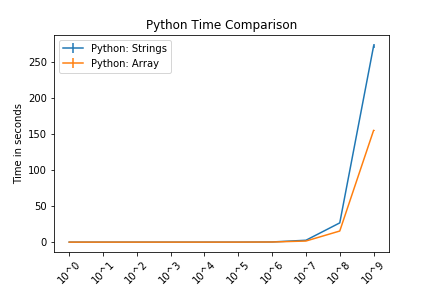
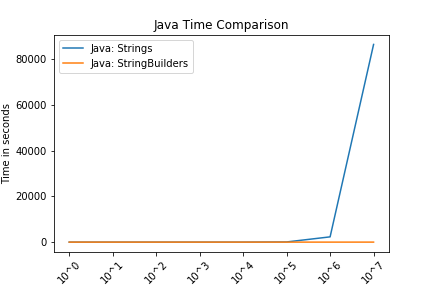
These figures compare Strings and lists for Python and Strings and StringBuilders for Java. The intention of these is not to compare Python and Java.
In both languages, we see that the string function and the respective alternative performed comparably until approximately 106 (1,000,000 characters). Again, these are somewhat contrived examples with the intention of understanding side effects of using strings.
As we have discussed, modern coding languages will have clean up protocols and memory management strategies. With the intention of this class in mind, we will not discuss the memory analysis in practice.
When modifying strings we need to be cognizant of how often we will be making changes and how large those changes will be. If we are just accessing particular elements or only doing a few modifications then using plain strings is a reasonable solution. However, if we are looking to build our own DNA sequence this is not a good way to go as strings are immutable.