Parallelism
Running multiple threads concurrently!
Running multiple threads concurrently!
Up to this point, we’ve only been dealing with programs that run within a single thread of execution. That means that we can follow a single path through the code, all the way from the start of the program when it calls the main() method all the way to the end. Unfortunately, while this allows us to create many useful programs, we aren’t able to take advantage of the power of modern computers with multi-core processors, which can handle multiple tasks simultaneously.
In addition, if our application needs to perform multiple tasks at once, such as computing a complex value while also handling user interactions with a GUI, we need a way to develop a program that can have multiple simultaneous paths executing at the same time. Without this, our GUI will appear to freeze anytime the application needs to compute something, frustrating our users and making it very slow to use.
In this chapter, we’ll introduce the concept of multithreaded computing, which involves creating a single program that can perform multiple simultaneous tasks within threads, itself a subset of the larger concept of parallel computing that involves running multiple processess simultaneously, sometimes spread across large supercomputers.
Some key terms we’ll cover in this chapter:
We’ll also explore a short example multithreaded program to see how it works in each of our programming languages.
First, let’s review how modern computers actually handle running multiple applications at once, and what that means for our own programs.
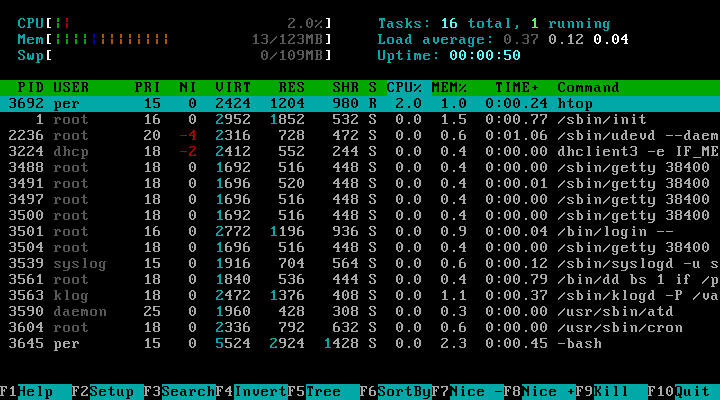
When a program is executed on a computer, the operating system loads its code into memory and creates a process to handle running that program. A process is simply an instance of a computer program that is running, just like an object is an instance of a class. Some programs, such as a web browser, allow us to create multiple processes of the same program, usually represented by multiple windows or tabs. The image above shows the htop command in Linux, which lists all of the processes running on the system. In Codio, we can use the top command in the Terminal to see the running processes - go ahead and try it!
At some point during your experience working with a computer, you may have been told that a computer can only do one thing at a time, and that it appears to run multiple programs at the same time by quickly switching between them. That’s mostly true, though in actuality there is a bit more nuance to it, which we’ll discuss a bit later. For modern computer with multi-core processors, we can typically have one process running per core.
In practice, an operating system may have tens or even hundreds of processes running at any given time. However, the computer it is running on may only have four or eight processor cores available. So, the operating system includes a scheduler that determines which processes should be executed at any given time, and most operating systems will switch between running processes thousands of times per second, making it appear to a user that all running processes are executing at the same time. This process of swapping between running processes is known as context switching.
The diagram above shows the various states a process can be placed in by the scheduler in the operating system. When the process is able to execute, it is in the running state. When the scheduler is ready to pause it, it is placed into the waiting state. However, when it is trying to load a file or waiting on another task, it is instead in the blocked state until that operation has completed.
When a process is waiting or blocked, the operating system could also decide that it needs to reclaim the memory used by this process. In that case, it can be swapped out of the processor’s cache in place of another process. Of course, all of this happens at the microsecond level in modern processors, so a process can be running, waiting, blocked, swapped out of memory, and swapped back in memory, all within a single second.
So, in the simplest version, each program we want to run is loaded into a process by the operating system, which handles scheduling that process to run on one of the cores of our processor. That’s what we need to know for now, as we introduce the next concept, threads.
In most modern operating systems, a process can be further divided into threads, which are individual sequences of instructions that the program can follow. A great way to think of a thread is an individual line of code that you can trace through your program, starting at the beginning and going all the way to the end. Up to this point, we’ve only written programs that contain a single thread, so you should only be able to trace a single line of code all the way through the program.
However, it is possible for our program to create multiple threads, and then have them appear to run simultaneously. Of course, as we said before, they may not actually run simultaneously, especially on a computer with only a single processing core. It is all left up to the scheduler in the operating system to determine how these threads are actually scheduled and executed.
This description leaves out some of the complexity of how threads and processes work within modern operating systems on modern hardware. In the real world, it is possible for a process to consist of multiple threads, and those threads can be scheduled to run at any time on any processor in any order by the operating system.
In addition, many newer processors support running multiple threads simultaneously on a single core, so threads could be running at the exact same time, maybe even on the same processor core itself.
We won’t worry about any of these details in this course, since much of this is handled for us by our programming language and operating system. However, if you plan to develop truly high-performance applications that use threads, you’ll need to learn how to properly deal with the complexity that comes from using modern computer hardware.
Thankfully, because of this, we can write programs that use multiple threads to perform different tasks at (nearly) the same time. To the user, it appears that our program is doing multiple things at once!
For our use, there are two major reasons why we would want to use multiple threads:
In this chapter, we’re going to learn about both uses, but going forward we’re most concerned about the second use, making our GUI appear to be responsive even while our program is performing other tasks. In a later chapter, we’ll learn about event-driven programming, which relies on splitting a program into multiple threads as well.
Now that we’ve learned about threads, let’s discuss how we can work with them in our programs. Writing a multithreaded program can be significantly more difficult than a single threaded program, but with the extra difficulty comes the ability to write programs that are much more flexible and powerful.
Creating a thread is very simple in many modern programming languages. Both Java and Python include libraries for dealing with threads, and to create a new thread, each one simply requires some sort of function or method to serve as the starting point for the new thread. In a way, this is just like the main() method that is the starting point of most programs - we’re just defining a new method to serve as the starting point for a new thread.
Once we’ve created the thread, it is given to the operating system for scheduling. Our main thread can continue to work, and the newly created thread will also start to run as well. So, the theoretical model might look something like this:

Here, it appears that both threads are running simultaneously. However, as we discussed earlier in this chapter, that isn’t really the case. For example, if the system only has one processor core, and these are the only two threads running on the system, then the threads might be interleaved on that processor like this:

If we expand that to two processor cores, then they might actually run simultaneously, like this:

Of course, this is a very simplified view of this process. In practice, there will be many processes and threads that are competing for access across several cores, so the actual model could look something like this:

As we can see, the processors are always executing some code, but many times they are executing code in a thread from some other application. Our application’s code will be scheduled by the operating system in between the other threads, but we cannot guarantee when it will be scheduled or for how long. Also, while this diagram makes it appear that each thread will only be scheduled on one processor, in fact the thread could be scheduled on ANY processor that is available. On a modern personal computer today, there may be as many as 16 or 32 individual threads available, sometimes multiple threads per CPU core, in the processor!
So, the big takeaways here:
Unfortunately, the big takeaways we saw on the previous page have very important consequences for our multithreaded programs. One of the most common errors, and also one of the notoriously most difficult errors to debug, is a race condition.
A race condition occurs when two threads in a program are trying to update the same value at the same time. If the operating system decides to interrupt one thread at just the wrong time, then a race condition occurs and the value could be given an incorrect value.
Let’s look at the simplest form of a race condition. Consider the case where we’d like to read a value from a variable, and then add 1 to that value. In code, it might look something like this:
y = data.x
data.x = y + 1Here, we have some data object stored in memory, which includes an attribute of x. Notice that we are not just adding 1 to the value of x and immediately updating it. Instead, we read the value of x into y, then use y to increase the value of x by 1. This is a very arbitrary example, but it is reflective of code that we might actually use in our applications. For example, we might read the x coordinate position of a sprite in a video game, perform some calculation on that position, and then update the position. It follows a pattern very similar to this.
So, if we run this code in two separate threads, one way the program could execute is shown below:

In this case, both pieces of code work like we expect. The spawned thread goes first, and reads the value 0 from data.x. Then, it computes the new value 1 and stores that back in data.x. After that, the main thread is scheduled on the other processor, and it reads 1 from data.x, computers the new value 2, and stores it back in place. So far, so good, right?
What if the threads get interrupted during the computation? In that case, the program could instead execute like this:

In this case, the spawned thread reads the value 0 from data.x, then stores it in y. Then, it is interrupted on its CPU, while the main thread is scheduled to execute on the other CPU. So, that main thread will also read the value 0 from data.x and store it in y. After that, the spawned thread will run, updating the value in data.x to 1. Finally, the main thread will execute updating the value in data.x to 1 again, even though it was already 1.
So, as we can see, we’ve run the same program, and it has produced two different results, depending on how the threads themselves are scheduled to run on the system. This is the essence of a race condition in our code.
What if both threads are scheduled to run simultaneously on two different processors, as in this example:

In this case, the main thread is trying to read the value of data.x at the exact same instant that the spawned thread is trying to save that value. In that case, what will the main thread think is stored in data.x? As it turns out, we have no way of predicting what it will read. It could read 0, or 1, or maybe even some intermediate value the CPU uses while it stores the data.
Thankfully, there is a way to deal with this situation, as we’ll learn on the next page.
To deal with race conditions, we have to somehow synchronize our threads so that only one is able to update the value of a shared variable at once. There are many ways to do this, and they all fit under the banner of thread synchronization.
The simplest way to do this is via a special programming construct called a lock. A lock can be thought of as a single object in memory that, when a thread has acquired the lock, it can access the shared memory protected by the lock. Once it is done, then it can release the lock, allowing another thread to acquire it.
A great way to think about this passing a ball around a circle of people, but only the person with the ball can speak. So, if you want to speak, you try to acquire the ball. Once you’ve acquired it, you can speak and everyone else must listen. Then, when you are done, you can release the ball and let someone else acquire it.
Of course, if someone decides to hold on to the ball the entire time and not release it, then nobody else is allowed to speak. When that happens, we call that situation deadlock. The same thing can happen with a multithreaded program.
So, let’s update our program to use a lock. In this case, we’ll assume that data includes another attribute lock which contains a lock that is used to control access to data:
data.lock.acquire()
y = data.x
data.x = y + 1
data.lock.release()Now, let’s look at our two possible situations and see how they change when we include a lock in our code. First, we have the situation where the programs are properly interleaved:

In this case, the spawned thread is able to acquire the lock when needed, perform its computation, and then release the lock before the other thread needs it. So, the lock really didn’t change anything here.
However, in the next case, where they are interleaved, we’ll see a difference:

Here, the spawned thread immediately acquires the lock and reads the value of data.x into y, but then it is interrupted. At that same time, the main thread wakes up and starts running, and tries to acquire the lock. When this happens, the operating system will block the main thread until the lock has been released. So, instead of waiting, the main thread will be blocked, and the spawned thread will continue to do its work. However, once the spawned thread releases the lock, the operating system will wake up the main thread and allow it to acquire the lock itself. Then, the main thread can perform its computation and update the value in data.x. As we can see, we now get the same value that we had previously. This is good! This means that we’ve come up with a way to defeat the inherent unpredictability in multithreaded programs.
The same holds for the third example on the previous page, when both threads run simultaneously. If both threads try to acquire the lock at the same time, the operating system will determine which thread gets it, and block any other threads trying to access the lock until it is released.
Of course, this introduces another interesting concept - if our threads must share data in this way, then is this any better than just having a single thread? If we look at this example, it seems that the threads can only run sequentially because of the lock, and that is true here. So, to make our multithreaded programs effective, each thread must be able to perform work that is independent of the other threads and any shared memory. Otherwise, the program will be even more inefficient than if we’d just written it as a single thread!
On the next pages, we’ll explore the basics of creating and using threads in both Java and Python. As always, feel free to skip ahead to the language you are learning, but you may wish to review both languages to see how they compare.
Java includes several methods for creating threads. The simplest and most flexible is to implement the Runnable interface in a class, and then create a new Thread that uses an instance of the class implementing Runnable as it’s target.
It is also possible to create a class that inherits from the Thread class, which itself implements the Runnable interface. However, this is not recommended unless you need to perform more advanced work within the thread.
Here’s a quick example of threads in Java:
import java.lang.Runnable;
import java.lang.Thread;
import java.lang.InterruptedException;
public class MyThread implements Runnable {
private String name;
/**
* Constructor.
*
* @param name the name of the thread
*/
public MyThread(String name) {
this.name = name;
}
/**
* Thread method.
*
* <p>This is called when the thread is started.
*/
@Override
public void run() {
for (int i = 0; i < 3; i++) {
System.out.println(this.name + " : iteration " + i);
try {
// tell the OS to wake this thread up after at least 1 second
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println(this.name + " was interrupted");
}
}
}
/**
* Main Method.
*/
public static void main(String[] args) {
// create threads
Thread thread1 = new Thread(new MyThread("Thread 1"));
Thread thread2 = new Thread(new MyThread("Thread 2"));
Thread thread3 = new Thread(new MyThread("Thread 3"));
// start threads
System.out.println("main: starting threads");
thread1.start();
thread2.start();
thread3.start();
// wait until all threads have terminated
System.out.println("main: joining threads");
try {
thread1.join();
thread2.join();
thread3.join();
} catch (InterruptedException e){
System.out.println("main thread was interrupted");
}
System.out.println("main: all threads terminated");
}
}Let’s look at this code piece by piece so we fully understand how it works.
import java.lang.Runnable;
import java.lang.Thread;
import java.lang.InterruptedException;We import both the Runnable interface and the Thread class, as well as the InterruptedException exception class. We have to wrap a few operations in a try-catch block to make sure that the thread isn’t interrupted by the operating system unexpectedly.
public class MyThread implements Runnable {
private String name;
public MyThread(String name) {
this.name = name;
}
// ...
}The class is very simple. It implements the Runnable interface, which allows to wrap it in a Thread as we’ll see later. Inside of the constructor, we are simply setting a name attribute so we can tell our threads apart.
@Override
public void run() {
for (int i = 0; i < 3; i++) {
System.out.println(this.name + " : iteration " + i);
try {
// tell the OS to wake this thread up after at least 1 second
Thread.sleep(1000);
} catch (InterruptedException e) {
System.out.println(this.name + " was interrupted");
}
}
}The run() method is declared in the Runnable interface, so we must override it in our code. This method is pretty short - it simply iterates 3 times and prints the value of the iteration along with the thread’s name, and then it uses the Thread.sleep(1000) method call. This tells the operating system to put this thread into a waiting state, and to not wake it up until at least 1000 milliseconds (1 second) has elapsed. Of course, we can’t guarantee that the operating system won’t make this thread wait even longer than that, but typically it will happen so fast that we won’t be able to tell the difference.
However, many of the methods in the Thread class can throw an InterruptedException if the thread is interrupted while it is performing this operation. In practice, it happens rarely, but it is always recommended to wrap these operations in a try-catch statement.
public static void main(String[] args) {
// create threads
Thread thread1 = new Thread(new MyThread("Thread 1"));
Thread thread2 = new Thread(new MyThread("Thread 2"));
Thread thread3 = new Thread(new MyThread("Thread 3"));
// start threads
System.out.println("main: starting threads");
thread1.start();
thread2.start();
thread3.start();
// wait until all threads have terminated
System.out.println("main: joining threads");
try {
thread1.join();
thread2.join();
thread3.join();
} catch (InterruptedException e){
System.out.println("main thread was interrupted");
}
System.out.println("main: all threads terminated");
}Finally, the main() method will create three instances of the Thread class, and provide an instance of our MyThread class, which implements the Runnable interface, as arguments to the constructor. In effect, we are wrapping our runnable class in a thread.
Then, we call the start() method on the thread, which will actually create the thread through the operating system and start it running. Notice that we do not call the run() method directly - that is called for us once the thread is created in the start() method.
Finally, we call the join() method on each thread. The join() method will block this thread until the thread we called it on has terminated. So, by calling the join() method on each of the three threads, we are making sure that they have all finished their work before the main thread continues. Once again, this could throw an InterruptedException, so we’ll use a try-catch statement to handle that.
That’s all there is to this example!
When we execute this example, we can see many different outputs, depending on how the threads are scheduled with the operating system. Below are a few that were observed when this program was executed during testing.
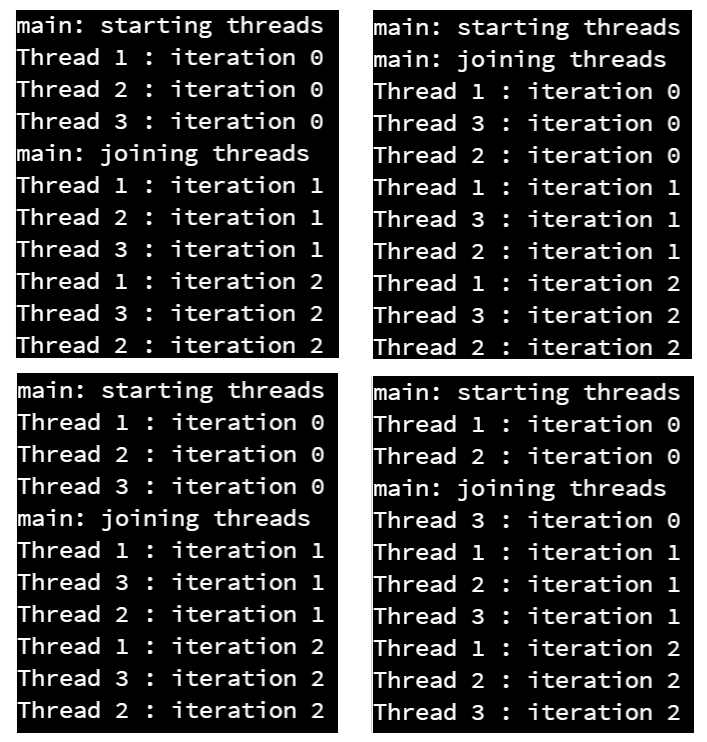
If you look closely at these four lists, no two of them are exactly the same. This is because of how the operating system schedules threads - we cannot predict how it will work, and because of this a multithreaded program could run differently each time it is executed!
Next, let’s look at a quick example of a race condition in Java, just so we can see how it could occur in our code.
First, let’s consider this example:
public class MyData {
public int x;
}import java.lang.Runnable;
import java.lang.Thread;
import java.lang.InterruptedException;
public class MyThread implements Runnable {
private String name;
private static MyData data;
/**
* Constructor.
*
* @param name the name of the thread
*/
public MyThread(String name) {
this.name = name;
}
/**
* Thread method.
*
* <p>This is called when the thread is started.
*/
@Override
public void run() {
for (int i = 0; i < 3; i++) {
int y = data.x;
// tell the OS it is ok to switch to another thread here
Thread.yield();
data.x = y + 1;
System.out.println(this.name + " : data.x = " + data.x);
}
}
/**
* Main Method.
*/
public static void main(String[] args) {
// create data
data = new MyData();
// create threads
Thread thread1 = new Thread(new MyThread("Thread 1"));
Thread thread2 = new Thread(new MyThread("Thread 2"));
Thread thread3 = new Thread(new MyThread("Thread 3"));
// start threads
System.out.println("main: starting threads");
thread1.start();
thread2.start();
thread3.start();
// wait until all threads have terminated
System.out.println("main: joining threads");
try {
thread1.join();
thread2.join();
thread3.join();
} catch (InterruptedException e){
System.out.println("main thread was interrupted");
}
System.out.println("main: all threads terminated");
System.out.println("main: data.x = " + data.x);
}
}In this example, we are creating a static instance of the MyData class, which can act as a shared memory object for this example. Then, in each of the threads, we are performing this three-step process:
int y = data.x;
// tell the OS it is ok to switch to another thread here
Thread.yield();
data.x = y + 1;Just as we saw in the earlier example, we are reading the current value stored in data.x into a variable y. Then, we are using the Thread.yield() method to tell the operating system that it is allowed to switch away from this thread at this point. In practice, we typically wouldn’t use this method at all, but it is helpful for testing. In fact, Thread.yield() is effectively the same as calling Thread.sleep(0) - we are telling the operating system to put this thread to sleep, but then immediately add it back to the list of threads to be scheduled on the processor. Finally, we update the value stored in data.x to be one larger than the value we saved earlier.
In effect, this is essentially the Java code needed to reproduce the example we saw earlier in this class.
So, what happens when we run this code? As it turns out, sometimes we’ll see it get a different result than the one we expect:
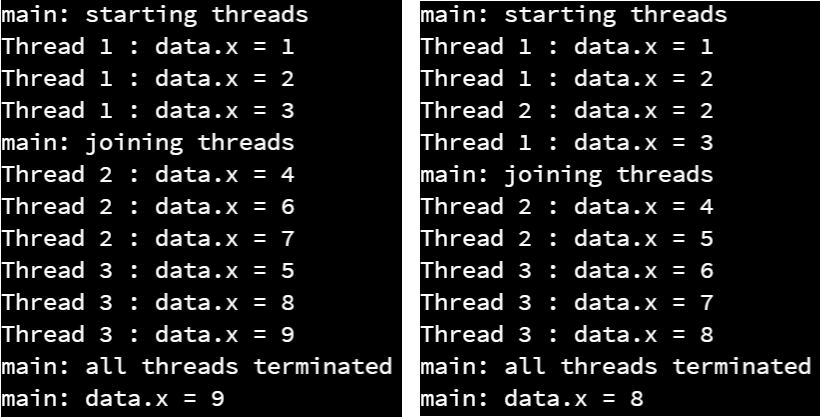
Uh oh! This is exactly what a race condition looks like in practice. In the screenshot on the right, we see that two threads set the same value into data.x, which means that they were running at the same time.
To fix this, Java includes couple of special methods for dealing with synchronization. First, we can use the synchronized statement, which is simply a wrapper around a block of code that we’d like to be atomic. An atomic block is one that shouldn’t be broken apart and interrupted by other threads accessing the same object. In effect, the synchronized statement will handle acquiring and releasing a lock for us, based on the item used in the statement.
So, in this example, we can update the run() method to use a synchronized statement:
@Override
public void run() {
for (int i = 0; i < 3; i++) {
synchronized(data) {
int y = data.x;
Thread.yield();
data.x = y + 1;
System.out.println(this.name + " : data.x = " + data.x);
}
Thread.yield();
}
}Here, the synchronized statement creates a lock that is associated with the data object in memory. Only one thread can hold that lock at a time, and by associating it with an object, we can easily keep track of which thread is able to access that object.
Now, when we execute that program, we’ll always get the correct answer!
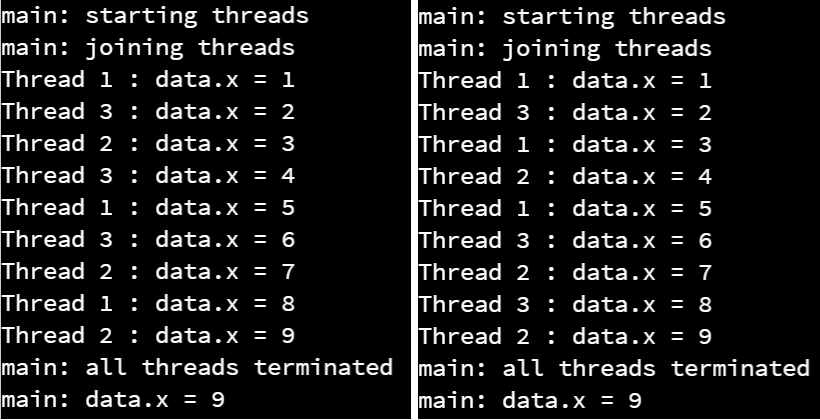
In fact, to get the threads interleaved as shown in this screenshot, we had to add additional Thread.sleep() statements to the code! Otherwise, the program always seemed to schedule the threads in the same order on Codio. We cannot guarantee it will always happen like that, but it is an interesting quirk you can observe in multithreaded code. In practice, sometimes race conditions may only happen once in a million operations, making them extremely difficult to debug when they happen.
Python includes several methods for creating threads. The simplest and most flexible is to create a new Thread object using the threading library. When that object is created, we can give it a function to use as a starting point for the thread.
Here’s a quick example of threads in Python:
import threading
import time
import sys
class MyThread:
def __init__(self, name):
"""Constructor.
Args:
name: the name of the thread
"""
self.__name = name
def run(self):
"""Thread method."""
for i in range(0, 3):
print("{} : iteration {}".format(self.__name, i))
# tell the OS to wake this thread up after at least 1 second
time.sleep(1)
@staticmethod
def main(args):
# create threads
t1_object = MyThread("Thread 1")
thread1 = threading.Thread(target=t1_object.run)
t2_object = MyThread("Thread 2")
thread2 = threading.Thread(target=t2_object.run)
t3_object = MyThread("Thread 3")
thread3 = threading.Thread(target=t3_object.run)
# start threads
print("main: starting threads")
thread1.start()
thread2.start()
thread3.start()
# wait until all threads have terminated
print("main: joining threads")
thread1.join()
thread2.join()
thread3.join()
print("main: all threads terminated")
# main guard
if __name__ == "__main__":
MyThread.main(sys.argv)Let’s look at this code piece by piece so we fully understand how it works.
import threading
import time
import sysWe import both the threading library, which allows us to create threads, as well as the time library to put threads to sleep. We’ll also need the sys library to access command-line arguments, if any are used.
class MyThread:
def __init__(self, name):
self.__name = nameThe class is very simple. Inside of the constructor, we are simply setting a name attribute so we can tell our threads apart.
def run(self):
for i in range(0, 3):
print("{} : iteration {}".format(self.__name, i))
# tell the OS to wake this thread up after at least 1 second
time.sleep(1)The run() method is the method we’ll use to start our threads. This method is pretty short - it simply iterates 3 times and prints the value of the iteration along with the thread’s name, and then it uses the time.sleep(1) method call. This tells the operating system to put this thread into a waiting state, and to not wake it up until at least 1 second has elapsed. Of course, we can’t guarantee that the operating system won’t make this thread wait even longer than that, but typically it will happen so fast that we won’t be able to tell the difference.
@staticmethod
def main(args):
# create threads
t1_object = MyThread("Thread 1")
thread1 = threading.Thread(target=t1_object.run)
t2_object = MyThread("Thread 2")
thread2 = threading.Thread(target=t2_object.run)
t3_object = MyThread("Thread 3")
thread3 = threading.Thread(target=t3_object.run)
# start threads
print("main: starting threads")
thread1.start()
thread2.start()
thread3.start()
# wait until all threads have terminated
print("main: joining threads")
thread1.join()
thread2.join()
thread3.join()
print("main: all threads terminated")Finally, the main() method will create three instances of the threading.Thread class, and provide an instance of our MyThread class as the target argument to the constructor. In effect, we are wrapping our runnable class in a thread.
Then, we call the start() method on the thread, which will actually create the thread through the operating system and start it running. Notice that we do not call the run() method directly - that is called for us once the thread is created in the start() method.
Finally, we call the join() method on each thread. The join() method will block this thread until the thread we called it on has terminated. So, by calling the join() method on each of the three threads, we are making sure that they have all finished their work before the main thread continues.
That’s all there is to this example!
When we execute this example, we can see many different outputs, depending on how the threads are scheduled with the operating system. Below are a few that were observed when this program was executed during testing.
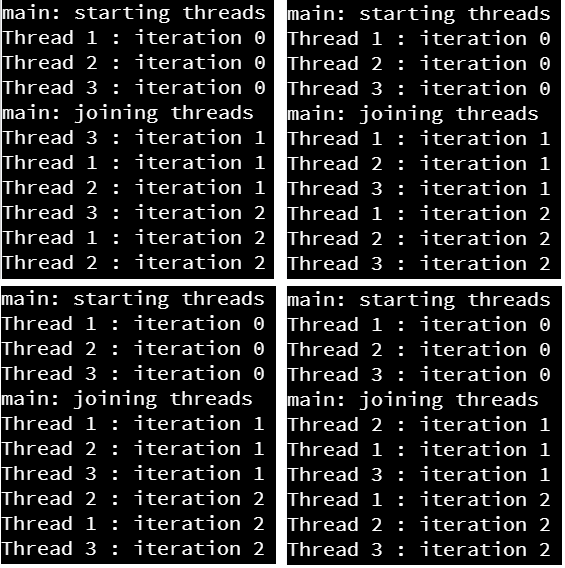
If you look closely at these four lists, no two of them are exactly the same. This is because of how the operating system schedules threads - we cannot predict how it will work, and because of this a multithreaded program could run differently each time it is executed!
Next, let’s look at a quick example of a race condition in Python, just so we can see how it could occur in our code.
First, let’s consider this example:
import threading
import time
import sys
class MyData:
def __init__(self):
self.x = 0
class MyThread:
data = MyData()
def __init__(self, name):
"""Constructor.
Args:
name: the name of the thread
"""
self.__name = name
def run(self):
"""Thread method."""
for i in range(0, 3):
y = MyThread.data.x
# tell the OS it is ok to switch to another thread here
time.sleep(0)
MyThread.data.x = y + 1
print("{} : data.x = {}".format(self.__name, MyThread.data.x))
@staticmethod
def main(args):
# create threads
t1_object = MyThread("Thread 1")
thread1 = threading.Thread(target=t1_object.run)
t2_object = MyThread("Thread 2")
thread2 = threading.Thread(target=t2_object.run)
t3_object = MyThread("Thread 3")
thread3 = threading.Thread(target=t3_object.run)
# start threads
print("main: starting threads")
thread1.start()
thread2.start()
thread3.start()
# wait until all threads have terminated
print("main: joining threads")
thread1.join()
thread2.join()
thread3.join()
print("main: all threads terminated")
print("main: data.x = {}".format(MyThread.data.x))
# main guard
if __name__ == "__main__":
MyThread.main(sys.argv)In this example, we are creating a static instance of the MyData class, attached directly to the MyThread class and not a particular object, which can act as a shared memory object for this example. Then, in each of the threads, we are performing this three-step process:
y = MyThread.data.x
# tell the OS it is ok to switch to another thread here
time.sleep(0)
MyThread.data.x = y + 1Just as we saw in the earlier example, we are reading the current value stored in data.x into a variable y. Then, we are using the time.sleep(0) method to tell the operating system to put this thread to sleep, but then immediately add it back to the list of threads to be scheduled on the processor. Finally, we update the value stored in data.x to be one larger than the value we saved earlier.
In effect, this is essentially the Python code needed to reproduce the example we saw earlier in this class.
So, what happens when we run this code? As it turns out, sometimes we’ll see it get a different result than the one we expect:
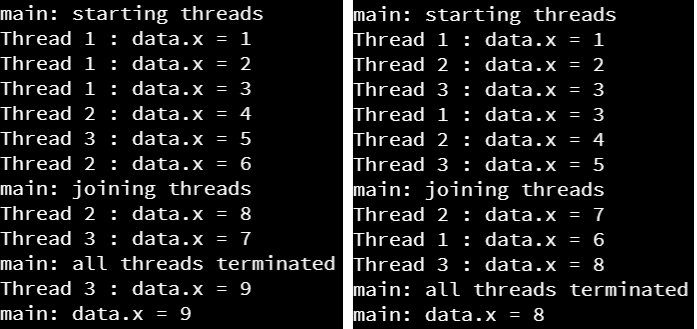
Uh oh! This is exactly what a race condition looks like in practice. In the screenshot on the right, we see that two threads set the same value into data.x, which means that they were running at the same time.
To fix this, Python includes a lock that we can use as part of a with statement, which is simply a wrapper around a block of code that we’d like to be atomic. An atomic block is one that shouldn’t be broken apart and interrupted by other threads accessing the same object. In effect, using a with statement along with a lock will handle acquiring and releasing the lock for us.
So, in this example, we can update the MyThread class to have a lock:
class MyThread:
data = MyData()
lock = threading.Lock()When, we can update the run() method to use a with statement:
def run(self):
for i in range(0, 3):
with MyThread.lock:
y = MyThread.data.x
# tell the OS it is ok to switch to another thread here
time.sleep(0)
MyThread.data.x = y + 1
print("{} : data.x = {}".format(self.__name, MyThread.data.x))
time.sleep(0)Here, the with statement acquires the lock that is associated with the data object in the MyThread class. Only one thread can hold that lock at a time, and by associating it with an object, we can easily keep track of which thread is able to access that object.
Now, when we execute that program, we’ll always get the correct answer!
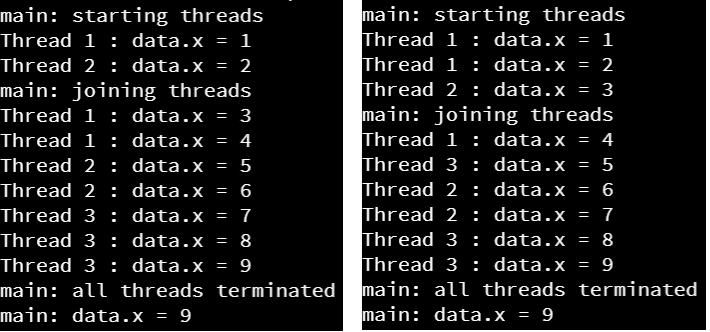
In fact, to get the threads interleaved as shown in this screenshot, we had to add additional time.sleep(0) statements to the code! Otherwise, the program always seemed to schedule the threads in the same order on Codio. We cannot guarantee it will always happen like that, but it is an interesting quirk you can observe in multithreaded code. In practice, sometimes race conditions may only happen once in a million operations, making them extremely difficult to debug when they happen.
In this chapter, we learned about processes and threads. A process is an instance of an application running on our computer, and it can be broken up into multiple threads of execution.
Creating threads is very simple - in most cases, we just need to define a function that is used as the starting point for the thread. However, in multithreaded programs, dealing with shared memory can be tricky, and if done incorrectly we can run into race conditions which cause our programs to possibly lose data.
To combat this, programming languages and our operating system provide methods for thread synchronization, namely locks that prevent multiple threads from running at the same time.
Then, we saw some quick examples for how to create threads in both Java and Python, and how to handle basic race conditions through the use of locks in each language.
In the next chapter, we’ll introduce event-driven programming, which depends on multiple threads to make our GUI responsive to the user even while our application is doing work in the background.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.