Serialization
Saving today’s data for tomorrow!
Saving today’s data for tomorrow!
Earlier in this course, we learned that an object-oriented program can be thought of as two different parts, the state of the program, and the behavior in the program. In this chapter, we’re going to discuss ways that we can save the program’s state while it is running. By doing so, we can then resume the program at a later time by simply loading that state back into memory.
This is a process generally known as serialization, though other languages may use other terms. Most notably, the process that Python uses is known as pickling in the Python documentation. Other documents may refer to this process as marshalling.
At its core, this is simply the process of taking either the whole or a part of a program’s state and converting it into a format that can be stored and/or transmitted, and then read back into memory to create a semantically identical state of the program.
Thankfully, we don’t have to worry about the behavior of the program, since that is already present in the program’s source code and any associated files that are created by compiling or executing the code. As long as the code hasn’t changed since the state was saved, we’ll be able to completely reconstruct the program, including both state and behavior.
First, let’s quickly review the state of a program. Recall from an earlier chapter that the state of a program consists of all of the variables and objects stored in memory. So, any time we create a new variable or instantiate a new object in our code, that adds to the overall state of the program.
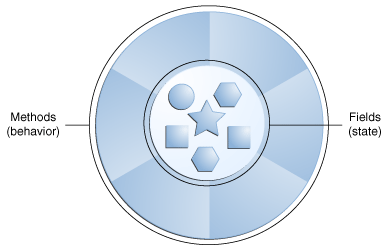
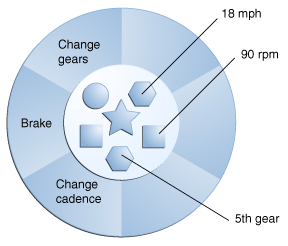
In the diagram above, we can visualize an object in object-oriented programming as the state, with a set of variables in the center, and the behaviors around those variables defining how we can use, interact with, and modify that state. For example, we could represent a bicycle’s state and behavior as shown below:
In this diagram, we see that the bicycle is traveling at 18 miles per hour (MPH) and the wheels are rotating at 90 revolutions per minute (RPM). The bicycle itself is in 5th gear.
However, in most programs, the only things we are really concerned with are the objects stored in memory that represent the core data that the program is using. Consider the example of a word processing program, such as Microsoft Word or Google Docs. In this program, we might consider the document itself as the core part of the program’s state that we are really concerned with saving.
Other items in memory, such as the list of recent changes that can be used to “undo” those changes, and the various view settings such as the current page and the “zoom” of the document, are all still part of the state of the program, but we might choose to not serialize that part of the state when saving the document.
In effect, it is an important design decision to make when developing an application - what parts of the state should be serialized as “persistent state”, and which parts are “ephemeral state” that can be easily reconstructed by the user as needed.
Going back to the bicycle example, perhaps we consider the fact that the bicycle is in 5th gear as persistent state that we need to store, but perhaps we don’t need to store the current speed.
So, now that we understand state, let’s talk about how we can serialize it in a way that is easy to parse and understand. There are really two major options we can choose from: a textual representation of the data, and a binary representation. Let’s look at text formats first.
There are many different ways that we can serialize data into a textual format. In fact, we’ve already covered how to read data from and write data to text files many times throughout this curriculum, and it is probably one of first things most programmers learn how to do.
At its core, the concept of serialization to a text file is pretty much the same as writing any data to a text file. We simply must write all the data stored in the program to a text file in an organized way. Then, when we need to load that file back into our program’s state, we can simply read and parse the data, storing it in objects and variables as needed.
So, let’s look at a simple example and explore the various ways that we could store this data in a textual format. Consider a Person object that has a name and age attribute. In addition, that object stores an instance of Pet, which also has a name, a breed and an age attribute.

With that structure in mind, there are several different formats we could use to store the data.
For many novice programmers, the first choice might be to simply create a custom text format to store the data. Here is one possible approach:
Person
Name = Willie Wildcat
Age = 42
Pet
Name = Reggie
Age = 4
Breed = ShorkieThis format definitely stores all of the data in the program’s state, and it looks like it can easily be read and parsed back into the program without too much work. However, such a custom text format has several disadvantages:
Of course, all of these concerns can be addressed by adding either additional rules to the structure or additional complexity to the code for reading and writing these files. However, let’s look at some other widely used formats that already address some of these concerns and see how they compare. Many of them also already have pre-written libraries we can use in our code as well.
The Extensible Markup Language, or XML, is a great choice for data serialization. XML uses a format very similar to HTML, and handles all sorts of data structures and formats very easily. Here’s an example of the same state translated into an XML document:
<state>
<person>
<name>Willie Wildcat</name>
<age>42</age>
<pet>
<name>Reggie</name>
<age>4</age>
<breed>Shorkie</breed>
</pet>
</person>
</state>As we can see, each object and attribute becomes its own tag in XML. We can even place the Pet object directly inside of the Person object, showing the hierarchical structure of the data.
XML also supports the use of a document type definition, or DTD, which provide rules about the structure of the XML document itself. So, using XML along with a DTD will make sure that the document is structured exactly like it should be, and it will be very easy to parse and understand.
In fact, most programming languages include libraries to easily create and parse XML documents, making them a great choice for data serialization. XML is also defined as a standard by the World Wide Web Consortium, or W3C, making it widely used on the internet. Many websites make use of AJAX, short for asynchronous JavaScript and XML, to send and receive data between a web application and a web server.
Another option that is very popular today is JavaScript Object Notation, or JSON. JSON originally started as a way to easily represent the state of objects in the JavaScript programming language, but it has since been adapted to a variety of different uses. Similar to XML, JSON is widely used on the internet today to share data between web applications and web servers, most notably as part of RESTful APIs.
A JSON representation of the state shown earlier is shown below:
{
"Person": {
"Name": "Willie Wildcat",
"Age": 42,
"Pet": {
"Name": "Reggie",
"Age": 4,
"Breed": "Shorkie"
}
}
}JSON and XML share many structural similarities, and in many cases it is very straightforward to convert data between XML and JSON representations. However, JSON tends to require less storage space than similar XML data, making it a good choice if storage space is limited or fast data transfer is required. Finally, JSON can be natively parsed by many programming languages such as JavaScript and Python, and libraries exist for most other languages such as Java.
Another choice that is commonly used is YAML, a recursive acronym for “YAML Ain’t Markup Language.” YAML is very similar to JSON in many ways, and in fact JSON files can be considered valid YAML files themselves.
Here is a YAML representation of the same state:
Person:
Name: Willie Wildcat
Age: 42
Pet:
Name: Reggie
Age: 4
Breed: ShorkieYAML uses indentation to denote the hierarchical structure of the document, very similar to Python code. As we can see, the structure of a YAML document is very similar to the custom text format we saw earlier.
However, while this YAML document seems very simple, the YAML specification includes many features that are omitted in JSON, such as the ability to include comments in the data. Unfortunately, YAML also suffers from many of the same problems as Python code, such as the difficulty of keeping track of the indentation when manually editing a file, and the fact that truncated files may be interpreted as complete since there are no termination markers.
We already know that all the data stored by a computer is in a binary format. So, it of course makes sense to also look at ways we can store a program’s state using a binary file format.
Many programming languages, including Java and Python, include libraries that can be used to generate binary files containing the state of an object in memory. Each language, and indeed each version of the language, may use a different format for storing the binary data in the file.
In this course, we won’t dig into the actual format of the binary file itself, since that can quickly become very complex. However, we will discuss some of the pros and cons related to using a binary file format for serialization compared to a text format.
One major advantage to the binary file format is that they are typically smaller in size than a comparable textual representation. This depends a bit on the language itself, but in general the binary structure doesn’t need to store the name of each object and attribute in the file, just values they contain.
Likewise, reading and writing binary files is often very efficient, since the data doesn’t have to be parsed to and from strings, which is an especially costly process for numeric data.
Finally, since the binary files are generally not readable or editable by humans, they could prevent a user from intentionally or accidentally editing the data. Of course, this should not be thought of as any sort of a security mechanism, since any technically adept user could easily reverse-engineer the file format.
A major downside of using binary files to store state is the fact that those files are only readable by the programming language they were created by, and in many cases they are locked to a particular version of the language. In some instances, even small changes to the source code of an object itself may invalidate any previously stored state when stored in a binary format.
Compare this to a textual format such as JSON, which can be easily read by any programming language. In fact, many times the JSON produced by a web server is created by a language other than JavaScript, and then the JavaScript running in the web application can easily parse and use it, no matter which language originally constructed it.
Another major downside is the fact that the files cannot be easily read or edited by a human. In some instances, the ability to manually edit a text file, such as a configuration file for a large application, is a very handy skill. We’ve already looked at several different configuration files for the applications we’ve built in this course, and the ability to edit them quickly helps us make major changes to the structure of our application.
The choice of textual or binary files for storing state is a tricky one. There are many reasons to choose either type, and it really comes down to how the data will be used. Many applications recently have moved from a proprietary, binary format to a more open format. For example, Microsoft Office documents are now stored in an XML format (docx, xlsx, pptx), making it easy for other tools to read and edit those documents. On the other hand, many computer games still prefer to store state and assets in binary, both to make them load quickly but also to prevent users from easily cheating by modifying the files.
On the next few pages, we’ll quickly look at how to generate and read some of these file formats in both Java and Python. As always, feel free to read the page for the language you are studying, but each page might contain useful information.
There are many different methods for serializing data in Java. We’ll quickly look at three of them.
Java includes a special API known as the Java Architecture for XML Binding, or JAXB, for mapping Java objects to XML.
To use it, we can add a few annotations to our objects:
import javax.xml.bind.annotation.*;
@XmlRootElement
public class Person {
// other code omitted
}In the simplest form, we simply add the @XmlRootElement annotation above the class to denote that it can be treated as a root element. If the class contains any lists or other collections, there are a few annotations that are needed for those element as well. The Pet class is similar.
With these annotations in place, reading and writing the XML file is very simple:
import java.io.*;
import javax.xml.bind.*;
public class SaveXml {
public static void main(String[] args) throws Exception {
Person person = new Person("Willie Wildcat", 42, new Pet("Reggie", 4, "Shorkie"));
System.out.println("Saving person:");
System.out.println(person);
File file = new File("person.xml");
JAXBContext jaxbContext = JAXBContext.newInstance(Person.class);
Marshaller jaxbMarshaller = jaxbContext.createMarshaller();
jaxbMarshaller.setProperty(Marshaller.JAXB_FORMATTED_OUTPUT, true);
jaxbMarshaller.marshal(person, file);
}
}To write an XML file, we create a JAXBContext based on the Person class, and then create a Marshaller that actually handles converting the Java data to XML. We can then simply write it’s output to a file.
import java.io.*;
import javax.xml.bind.*;
public class LoadXml {
public static void main(String[] args) throws Exception {
File file = new File("person.xml");
JAXBContext jaxbContext = JAXBContext.newInstance(Person.class);
Unmarshaller jaxbUnmarshaller = jaxbContext.createUnmarshaller();
Person person = (Person) jaxbUnmarshaller.unmarshal(file);
System.out.println("Loading person:");
System.out.println(person);
}
}Reading an XML file is very similar. The only major difference is that we use an Unmarshaller in place of the Marshaller.
For more information on using JAXB, refer to these resources. The full source code can be found on GitHub:
To handle JSON data in Java, we can use the Jackson library. It can be installed in Gradle by adding a few items to build.gradle:
// Required to match Jackson versions in Spring
ext['jackson.version'] = '2.12.2'
dependencies {
// other sections omitted
implementation 'com.fasterxml.jackson.core:jackson-databind:2.12.2'
}Then, the process for saving and loading JSON data is very similar to working with XML:
import java.io.*;
import com.fasterxml.jackson.databind.ObjectMapper;
public class SaveJson {
public static void main(String[] args) throws Exception {
Person person = new Person("Willie Wildcat", 42, new Pet("Reggie", 4, "Shorkie"));
System.out.println("Saving person:");
System.out.println(person);
File file = new File("person.json");
ObjectMapper mapper = new ObjectMapper();
mapper.writeValue(file, person);
}
}import java.io.*;
import com.fasterxml.jackson.core.type.TypeReference;
import com.fasterxml.jackson.databind.ObjectMapper;
public class LoadJson {
public static void main(String[] args) throws Exception {
File file = new File("person.json");
ObjectMapper mapper = new ObjectMapper();
Person person = mapper.readValue(file, new TypeReference<Person>(){});
System.out.println("Loading person:");
System.out.println(person);
}
}In both cases, we simply create an ObjectMapper class from Jackson, and then use it to read and write the JSON data. It’s that simple.
For more information on using Jackson, refer to these resources. The full source code can be found on GitHub:
Java also includes a built-in mechanism for serialization. All that is really required is to implement the Serializable interface on any objects to be serialized.
import java.io.*;
public class Person implements Serializable {
// other code omitted
}The Pet class is similarly updated. Once that is done, we can use the built-in ObjectInputStream and ObjectOutputStream to read and write objects just like we do any other data types in Java.
import java.io.*;
public class SaveBinary {
public static void main(String[] args) throws Exception {
Person person = new Person("Willie Wildcat", 42, new Pet("Reggie", 4, "Shorkie"));
System.out.println("Saving person:");
System.out.println(person);
File file = new File("person.ser");
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(file));
out.writeObject(person);
}
}import java.io.*;
public class LoadBinary {
public static void main(String[] args) throws Exception {
File file = new File("person.ser");
ObjectInputStream in = new ObjectInputStream(new FileInputStream(file));
Person person = (Person) in.readObject();
System.out.println("Loading person:");
System.out.println(person);
}
}By convention, we use the .ser file extension for serialized data from Java.
For more information on Java serialization, refer to these resources. The full source code can be found on GitHub:
There are many different methods for serializing data in Python. We’ll quickly look at three of them.
Python includes the ElementTree library for processing XML. Unfortunately, due to the way that Python handles objects, we have to write some of the processing ourselves. There are some external libraries that will automatically explore Python objects and build the XML based on its attributes.
To write an XML file in Python, we can use code similar to this:
import xml.etree.ElementTree as ET
person = Person("Willie Wildcat", 42, Pet("Reggie", 4, "Shorkie"))
print("Saving person:")
print(person)
person_elem = ET.Element("person")
ET.SubElement(person_elem, "name").text = person.name
ET.SubElement(person_elem, "age").text = str(person.age)
pet_elem = ET.SubElement(person_elem, "pet")
ET.SubElement(pet_elem, "name").text = person.pet.name
ET.SubElement(pet_elem, "age").text = str(person.pet.age)
ET.SubElement(pet_elem, "breed").text = person.pet.breed
with open("person.xml", "w") as file:
file.write(ET.tostring(person_elem, encoding="unicode"))To construct an XML document, we simply must construct each element and set the parent element, tag, and data of each element, as shown in the example above.
import xml.etree.ElementTree as ET
xml_tree = ET.parse("person.xml")
person_elem = xml_tree.getroot()
for child in person_elem:
if child.tag == "name":
name = child.text
if child.tag == "age":
age = child.text
if child.tag == "pet":
for subchild in child:
if subchild.tag == "name":
pet_name = subchild.text
if subchild.tag == "age":
pet_age = subchild.text
if subchild.tag == "breed":
pet_breed =subchild.text
person = Person(name, age, Pet(pet_name, pet_age, pet_breed))
print("Loading person:")
print(person)Then, to parse that data, we can simply iterate through the tree structure and find each tag, loading the text data into a variable and using those variables to reconstruct our objects.
For more information on using UML, refer to these resources. The full source code can be found on GitHub:
To handle JSON data in Python, we can use the json library.
Then, the process for saving and loading JSON data is very similar to working with XML:
import json
person = Person("Willie Wildcat", 42, Pet("Reggie", 4, "Shorkie"))
print("Saving person:")
print(person)
person_dict = dict()
person_dict['name'] = person.name
person_dict['age'] = person.age
person_dict['pet'] = dict()
person_dict['pet']['name'] = person.pet.name
person_dict['pet']['age'] = person.pet.age
person_dict['pet']['breed'] = person.pet.breed
with open("person.json", "w") as file:
json.dump(person_dict, file)For JSON, it is easiest to construct a dictionary containing the structure and data to be serialized. This could easily be done as a method within the class itself, but this example shows it outside the class just to demonstrate how it works.
To read the serialized data, we can do the reverse:
import json
with open("person.json") as file:
person_dict = json.load(file)
person = Person(
person_dict['name'],
person_dict['age'],
Pet(
person_dict['pet']['name'],
person_dict['pet']['age'],
person_dict['pet']['breed']))
print("Loading person:")
print(person)For more information on using JSON in Python, refer to these resources. The full source code can be found on GitHub:
Python also includes a built-in mechanism for serialization. All that is required is the Pickle library.
person = Person("Willie Wildcat", 42, Pet("Reggie", 4, "Shorkie"))
print("Saving person:")
print(person)
with open("person.p", "wb") as file:
pickle.dump(person, file)with open("person.p", "rb") as file:
person = pickle.load(file)
print("Loading person:")
print(person)All we have to do is open the file in a binary format by adding b to the open command.
For more information on Java serialization, refer to these resources. The full source code can be found on GitHub:
Another important concept to keep in mind when serializing data is that there are some items that don’t serialize very well, and others that can be omitted. Let’s review a few of those now.
One example of things that don’t serialize well are objects provided by the operating system itself. This includes things such as open files, input and output streams, and threads. In each case, these objects rely on data provided by the operating system, making it difficult to serialize the object directly.
Instead, we can externally save the state, such as the current position we are reading from in the file, or the current object the thread is manipulating, and then use that to recreate the object later on.
The other type of data that you may not wish to serialize is data that is dependent on other data. For example, a program might contain multiple copies of the same class, or have a class where one attribute is computed from other attributes. In order to save space, you may choose to only serialize the data that is required to reconstruct the rest, and perform the reconstruction when loading the data from the file. This will save storage space, but may cost additional computation time. So, we must evaluate the tradeoff and determine which option fits our use case the best.
Finally, we really cannot talk about data serialization without briefly mentioning what might be the penultimate example of serialization - databases.
A database is a specialized piece of software that is designed to store and retrieve large amounts of data. For many applications, especially web applications, a database is the primary method for storing data long-term, and takes the place of any data serialization to a file.
While most database systems are thought of as stand-alone applications that we connect to from our application, there are also smaller databases that can be stored and accessed from a single file, such as SQLite, which is supported directly in Python
Many databases can also store text or binary values directly, so it is possible to use the serialization methods we’ve already discussed to transform objects in memory and store them in a database.
Finally, there are many object-relational mapping, or ORM, tools available that will easily map data from a database into objects that can be used in an object-oriented manner. These can help bridge the gap between the data structures most commonly used in a database and the object-oriented data structures we are familiar with.
We won’t work with databases in this class, as that is well outside of the scope of what we can cover quickly. There are later courses in the Computational Core program that cover both databases and web development in much greater detail. We simply felt that it was worth mentioning the fact that, in practice, a large amount of data serialization is actually done with databases instead of files on a file system.
In this chapter, we learned about how to serialize the state of our applications into a file for storage, and then how to read that state back into memory.
We explored different formats we can use, including JSON, XML, and a binary format. Each of those comes with various pros and cons, so we have to choose wisely.
Then, we saw some examples of how to work with each format in our chosen programming language. In each case, it isn’t too difficult to do.
Finally, we discussed some of the things we might not want to serialize, and the fact that, in practice, we might want to use a database instead of a text file for storing large amounts of data, especially in a web application.
Thankfully, we’ll be able to put this skill to use as we wrap up our semester project.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.