Extras
Everything that didn’t fit anywhere else!
Everything that didn’t fit anywhere else!
We’ve covered lots of new topics in this course, but there are always important ideas that get left out or don’t fit anywhere else. So, in this final chapter of the book, we’ll look at some one-off topics and concepts that we feel are important to cover in this course. For many students, this course serves as a capstone programming course, and we want to make sure you are well prepared as a programmer in the future.
Each page in this chapter covers a different topic, with links to additional resources and reading material where possible. More information will continually be added to this chapter as new topics are considered, so if you have a topic in mind that hasn’t been already covered in this course, please contact your course instructor and share your idea. It might just end up in an future version of this book.
One major topic in the Java programming language that we’ve made use of but haven’t really explained is the use of generic types. A generic type is a class or interface that can accept a parameter for the type of object that it stores. A great example is the LinkedList class that we are very familiar with. When working with a class that supports generic types, we provide the type parameter in angle brackets <> as in this example:
LinkedList<Person> personList = new LinkedList<>();So, as we know, this LinkedList object will only allow us to store objects compatible with the Person type. If we try to add anything else to that list, the compiler will raise an error before we even can execute our code. Likewise, when we access an element in the list, it will automatically be given to us as a Person object, without any casting required.
Person person = new Person("Willie", 42);
personList.add(person);
Person personOut = personList.get(0); // no cast required!
Integer intObject = new Integer(5);
personList.add(intObject); // COMPILER ERROR!Compare that with a non-generic version of a List class, such as the one you probably created as part of a data structures course:
public class MyArrayList {
private Object[] array;
private int size;
public MyArrayList() {
this.array = new Object[10];
this.size = 0;
}
public Object get(int i) {
return this.array[i];
}
public void add(Object obj) {
this.array[size++] = obj;
}
}If we wish to use the simple class above, we can instantiate it using this code:
MyArrayList myPersonList = new MyArrayList();This class stores objects using the top-level Object class. So, it can store every possible type of object, but it doesn’t have any way of enforcing types at all. Consider the same code example:
Person person = new Person("Willie", 42);
myPersonList.add(person); // Person is a subtype of Object
Person personOut = myPersonList.get(0); // COMPILER ERROR!
Person personOut = (Person) personList.get(0); // requires a cast
Integer intObject = new Integer(5);
myPersonList.add(intObject); // Integer is a subtype of Object
Person secondOut = (Person) personList.get(1); // EXCEPTION!
// Integer cannot be cast as a PersonHere, we see that we can add any object to the list, and the compiler will allow it. However, when we access those items, we’ll have to cast them back to the type we need to use, and if we make a mistake, we’ll encounter an exception. So, this is definitely not ideal.
Of course, one easy solution would be to rewrite our MyArrayList class to accept only Person objects instead of the base Object type. This isn’t that difficult to do.
public class MyPersonList {
private Person[] array;
private int size;
public MyPersonList() {
this.array = new Person[10];
this.size = 0;
}
public Person get(int i) {
return this.array[i];
}
public void add(Person obj) {
this.array[size++] = obj;
}
}In effect, we can just replace the Object type in the code with the Person type, and it works just fine. If we want to create a list to store a different type, we can just duplicate this class, update a few types, and we are good to go, right?
Hopefully by now we are well trained enough in object-oriented programming that our intuition is telling us that there must be a simpler way to do this. This seems to violate the Don’t Repeat Yourself (DRY) principle, since we are creating a bunch of classes that do the same thing with slightly different types. Thankfully, there is a great solution for this in Java.
To create a class that uses a generic type, we simply can replace each instance of the type with a variable. So, in our class itself, we can update it to handle generic types as shown in this example:
public class MyGenericList<T> {
private T[] array;
private int size;
public MyGenericList() {
this.array = new T[10];
this.size = 0;
}
public T get(int i) {
return this.array[i];
}
public void add(T obj) {
this.array[size++] = obj;
}
}It’s really that simple. We add a generic parameter list to our class declaration, <T> in this example, and then replace all instances of the type with that parameter. Traditionally, we use T for the generic type variable, and most generic classes use single uppercase letters to represent type variables, making it clear which variables are types and which ones are other variables.
Then, when we wish to use this class, we can treat it just like any other generic class:
MyGenericList<Person> genericList = new MyGenericList<>();
Person person = new Person("Willie", 42);
genericList.add(person);
Person personOut = genericList.get(0); // no cast required!
Integer intObject = new Integer(5);
genericList.add(intObject); // COMPILER ERROR!With that code, we’ve definitely followed the Don’t Repeat Yourself (DRY) principle, since there will only be one instance of the class in our code, and it can now support any generic type we choose.
One major topic in the Python programming language that we’ve made use of but haven’t really explained is the use of generic types. A generic type is a class or interface that can accept a parameter for the type of object that it stores. A great example is the List class that we are very familiar with. When providing type hints for a list class, we can provide the type that should be stored in the class in square brackets []:
person_list: List[Person] = list()So, as we know, this List object will only allow us to store objects compatible with the Person type. If we try to add anything else to that list, the type checker will raise an error. Of course, since we are working in a dynamically-typed language, there is nothing that will prevent us from doing so in practice, but using a type checker such as Mypy will help us find these errors in our code. Likewise, when we access an element in the list, it will automatically be given to us as a Person object, without any casting or type inference required.
person: Person = Person("Willie", 42)
person_list.append(person)
person_out: Person = person_list[0] # no cast or type check required
person_list.append("Test") # TYPE CHECK ERROR!Compare that with a non-generic version of a List class, such as the one you probably created as part of a data structures course:
from typing import List
class MyArrayList:
def __init__(self) -> None:
self.__array: List[Object] = list()
def append(self, obj: Object) -> None:
self.__array.append(obj)
def get(self, i: int) -> Object:
self.__array[i]If we wish to use the simple class above, we can instantiate it using this code:
my_person_list: MyArrayList = MyArrayList()This class stores objects using the top-level Object class. So, it can store every possible type of object, but it doesn’t have any way of enforcing types at all. Consider the same code example:
person: Person = Person("Willie", 42)
my_person_list.append(person) # Person is a subtype of Object
person_out: Person = my_person_list[0] # TYPE CHECK ERROR
if isinstance(my_person_list[0], Person): # requires a type cast
person_out: Person = my_person_list[0]
my_person_list.append("Test") # str is a subtype of Object
second_out: Person = my_person_list[1] # TYPE CHECK ERROR
# It will be a string, but type checker
# can't tell what type it should beHere, we see that we can add any object to the list, and the type checker will allow it. However, when we access those items, we’ll have to cast them back to the type we need to use, and if we make a mistake, we might run into issues. So, this is definitely not ideal.
Of course, one easy solution would be to rewrite our MyArrayList class to accept only Person objects instead of the base Object type. This isn’t that difficult to do.
from typing import List
class MyPersonList:
def __init__(self) -> None:
self.__array: List[Person] = list()
def append(self, obj: Person) -> None:
self.__array.append(obj)
def get(self, i: int) -> Person:
self.__array[i]In effect, we can just replace the Object type in the code with the Person type, and it works just fine. If we want to create a list to store a different type, we can just duplicate this class, update a few types, and we are good to go, right?
Hopefully by now we are well trained enough in object-oriented programming that our intuition is telling us that there must be a simpler way to do this. This seems to violate the Don’t Repeat Yourself (DRY) principle, since we are creating a bunch of classes that do the same thing with slightly different types. Thankfully, there is a great solution for this in Python.
To create a class that uses a generic type, we simply can replace each instance of the type with a variable. So, in our class itself, we can update it to handle generic types as shown in this example:
from typing import List, TypeVar, Generic
T = TypeVar('T')
class MyGenericList(Generic[T]):
def __init__(self) -> None:
self.__array: List[T] = list()
def append(self, obj: T) -> None:
self.__array.append(obj)
def get(self, i: int) -> T:
self.__array[i]It’s really that simple. We first create a TypeVar to represent our generic type. Traditionally, we use T for the generic type variable, and most generic classes use single uppercase letters to represent type variables, making it clear which variables are types and which ones are other variables. Then, we subclass the Generic[T] base class to show that this is a generic class, and then replace all instances of the type with that parameter.
Then, when we wish to use this class, we can treat it just like any other generic class:
generic_list: MyGenericList[Person] = MyGenericList()
person: Person = Person("Willie", 42)
generic_list.append(person)
person_out: Person = generic_list[0] # Properly Type Checked
my_person_list.append("Test") # TYPE CHECK ERRORWith that code, we’ve definitely followed the Don’t Repeat Yourself (DRY) principle, since there will only be one instance of the class in our code, and it can now support any generic type we choose.
One major topic that this course doesn’t cover is software engineering. Software engineering is all about applying practices from the field of engineering to the development of software. So, while it also includes things such as program architecture, programming paradigms, and design patterns, which we do cover in this course, software engineering also includes many other topics related to the process of developing, operating, testing, and maintaining software.
One of the major topics in software engineering is the Software Development Life Cycle, sometimes abbreviated as SDLC or referred to as the Software Development Process. This is all about how we actually design and build software, going from the initial idea, all the way through design, development, testing, maintenance, updates, and more. There are entire courses and books dedicated to this topic, and it is an area of constant study and improvement for software developers of all skill levels.
On this page, we’ll give a brief overview of the major concepts and how they all fit together.
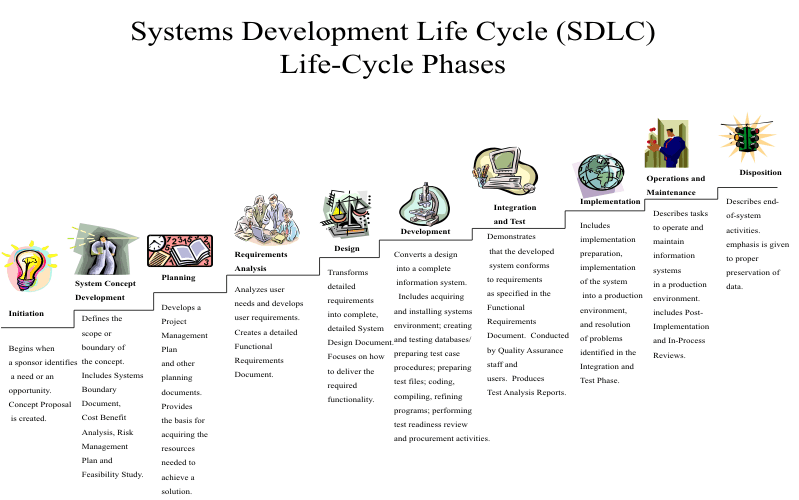 1
Right-click and open image in new tab for larger version
1
Right-click and open image in new tab for larger version
The software development life cycle consists of many steps, and each of the methodologies discussed below may use a slightly different list of steps, adding or omitting them as needed. However, they generally fit into a few major groupings:
The first step is generally to determine the requirements of the piece of software. At this step, a developer might ask questions about who the software is for, what it should do, how it will store and access data, and what type of hardware it will be running on. All of these questions help build the list of requirements for the software. Throughout most of your academic career, this is usually provided to you as the description of the programming project. It clearly states what the finished product should do and how it should work.
Once the requirements are determined, developers will start working on the overall design of the application. This usually involves creating some UML diagrams to help describe the structure of the application itself, and it may also include discussions of external libraries to be used, software design patterns to apply, and more. Again, this is usually given to you as part of the assignment description, though in this class you were tasked to develop your own software design as part of your final project.
This step is the obvious one - it involves actually developing the software! In this step, developers refer back to the design documents and original requirements list to make sure the code being developed meets those needs. In your academic career, this is the step that most classes, up to this point, have focused on teaching you. As a programmer in a large organization, or working on your own personal project, this is really the core step of the process that you’ll work with. However, throughout your career you may find yourself branching out a bit and working more on gathering requirements and designing software that others will help you build.
Once the software is developed, it needs to be tested. In this course, we introduced unit testing, which makes up the bulk of software testing. As we discussed before, this could also include items such as regression tests, integration tests, and more. In fact, the test-driven development paradigm turns this around by requiring tests to be developed before the software itself, effectively combining both the testing and development steps into a single step.
When the software is ready to be released, the last step in its life cycle is to be deployed to the end-users. However, once they have access to the software, they are bound to find bugs to be fixed. So, many software projects also must include some maintenance steps here to fix bugs and provide updates to the program even after it is released.
Another core concept of software engineering are the software development methodologies, which are different ways of moving through the steps of the software development life cycle listed above. Each methodology follows its own unique pattern through those steps, and may add additional constraints or processes as needed. There are many different methodologies in use today, but let’s look at a few of the more common ones that you might come across.
The Waterfall Model is a software development methodology that basically works through the software development lifecycle one step at a time. So, in the waterfall model, developers cannot start working on code until both the requirements and design steps are fully complete. And, at any time, if the developers realize that the design is not feasible, development must be paused while the design is reconsidered.
The waterfall model is seen as a more traditional model, since it has its roots in the early days of software development in the 1950s and 1960s. Many large corporations and government projects still follow this model today. However, there are many drawbacks to this model, such as the fact that it can be very rigid and inflexible, especially as the requirements and design of a software project may change over time.
The Iterative and Incremental Development model builds upon the waterfall model by using the same basic steps, but repeated over and over again. Instead of developing the project all at once, this model focuses on building a small part of the project first, and then slowly adding to it (incremental). That process is repeated multiple times (iterative), until the full project is complete. Through this model, it is much easier to build small prototypes of the software, get feedback, and continually adapt the design and requirements as more information is acquired.
This model has been used successfully in a variety of contexts, including as part of the Mercury and Space Shuttle programs at NASA.4
Closely related to the iterative and incremental development model, the Spiral Model also focuses on a repeated set of steps that start with a small concept and prototype, working outwards toward a final project. In a spiral model, however, developers and teams analyze the “risk” that comes with any change to the software or new concept to be added, and aims to minimize that risk as much as possible. For example, if the team decides to add a new feature to a project, but they are worried that it may not be well received by users, they may decide to only spend a little bit of time working on that feature before getting feedback from the users. If it is well received, the next cycle may devote more time to that feature. If the users don’t like it, they will have saved themselves lots of wasted time by not spending too much time on it in the first place.
Agile Software Development is one of the newer and most popular software development methodologies today. Agile software development actually comes in many forms, but they all focus on rapid prototyping, continual improvement, and quickly responding to changes in requirements and design. It all started with the publication of the Manifesto for Agile Software Development, which contains the statements:
… we have come to value: Individuals and interactions over processes and tools Working software over comprehensive documentation Customer collaboration over contract negotiation Responding to change over following a plan
Therefore, most implementations of the agile software development methodology involve very short development cycles, commonly measured by days or even hours instead of weeks or months. In addition, there is a large focus on automation at all levels, such as continuous integration and automated unit testing, and many developers are encouraged to use standard structures and techniques such as software design patterns and clean code to make their code easy to understand and maintain.
There are lots of great resources for learning more about agile software development on line, including many free courses. For developers considering working in the industry, we highly recommend learning more about agile due to its popularity in all levels of the industry today.
https://commons.wikimedia.org/w/index.php?title=File:Systems_Development_Life_Cycle.gif&oldid=534019806 ↩︎
https://commons.wikimedia.org/w/index.php?title=File:Waterfall_model.svg&oldid=453496509 ↩︎
https://commons.wikimedia.org/w/index.php?title=File:Iterative_development_model.svg&oldid=484829875] ↩︎
https://www.computer.org/csdl/magazine/co/2003/06/r6047/13rRUxBJhpL ↩︎
https://commons.wikimedia.org/w/index.php?title=File:Spiral_model_(Boehm,_1988).svg&oldid=480509142] ↩︎
On the previous page, we discussed the software development life cycle. One of the most important, and often overlooked, steps in those processes is requirements elicitation. Requirements elicitation is all about determining what the users or customers want from a piece of software that is being developed. While this might sound simple, it can actually be one of the most difficult steps in the whole process. In addition, since it is generally the first step in any new software development task, getting this step right can make everything work smoothly, whereas even a small problem at this step can cause the entire project to fail.
One of the major issues with gathering requirements is that many times the users or customers themselves are not well trained in technology or programming themselves, and therefore they don’t have a good idea of what is possible, impossible, or even impractical, when developing a new piece of software. Likewise, they may not be able to fully articulate exactly what they want from a new piece of software, or they might ask for something that they think is achievable without discussing the actual problem they’d like to solve.
This problem is well summed up by the following XKCD comic:
Here, we see a user asking for two things that seem similar - when the user takes a picture using a mobile application, can we determine where it was taken and what is in the picture? Sounds simple, right?
However, to a programmer, those two questions are actually asking for vastly different things. On the one hand, most phones today support GPS, so the mobile app can simply capture the user’s current GPS coordinates when the picture is taken, and then check to see if those GPS coordinates lie within a defined national part boundary. So, this can be easily done with just a little bit of work.
On the other hand, how can we determine if there is a bird in a picture? This is a computer vision problem, and is definitely still an unsolved problem as of 2021. There are some very advanced algorithms available today that can perform facial recognition on people, but they require massive amounts of data for training and testing, and even then they aren’t perfect. Our ability to recognize other objects is even more limited, but it is slowly getting better. Projects such as Google Lens demonstrate what can be done currently in this field. So, expecting a mobile app to perform this task is not really feasible at the current time, but perhaps in the future it could be done.
There are many ways to approach the process of gathering requirements for a project. This could involve brainstorming ideas, holding focus groups, collecting surveys and user feedback, producing prototypes and allowing users to interact with them, and more. Once again, the topic of requirements elicitation is large enough for an entire course in itself.
So, if you do find yourself in a position where you need to gather requirements from users or customers, it is worth doing a bit of reading to discover the various approaches and methods that you may be able to put to use. Below are a few resources you may find helpful.
Another major concept to be aware of as a programmer is security. Computer systems today store large amounts of sensitive data, and hackers are always trying to access data and resources they should not have access to. Many times, their ability to access that data is due to a mistake or oversight on the part of a programmer, sometimes made months or even years prior. It could even have been due to some completely new situation that wasn’t at all a concern when the program was originally written.
Therefore, programmers should also have a basic understanding of some of the concerns related to computer security and how they can do their best to avoid them.
A major area of study is Defensive Programming. In effect, defensive programming involves writing programs that will behave in expected ways, even if it receives unexpected or malicious inputs from the user. By learning to write programs in a defensive way, developers can limit the number of vulnerabilities a program has, while easily detecting or preventing malicious input from actually causing a problem.
In some programming languages, such as C and C++, the memory for storing data is handled directly by the user, and misuse of this can lead to all sorts of vulnerabilities in the code. We won’t cover those here, but if you do decide to learn to program in those languages, it is definitely recommended to also build a strong understanding of how to properly manage memory and avoid these problems. This is known as secure coding.
Thankfully, both Java and Python generally handle memory for us, and are much less susceptible to these issues. That doesn’t mean that they are immune, and there are situations where a developer can inadvertently expose data, but generally it is difficult to do so.
As we already learned throughout this course, we can write code to carefully handle errors as they arise. For example, if the input to this function should be a string that must be at least 1 character and no longer than 10 characters, we could do something like this in our code:
public void getString(String input) {
if (input == null) {
throw new NullPointerException();
}
if (input.length < 1 || input.length > 10) {
throw new IllegalArgumentException();
}
// more code here
}def get_string(self, input: str) -> None:
if input is None or not isinstance(input, str):
raise TypeError()
if len(input) < 1 or len(input) > 10:
raise ValueError()
# more code hereIn both of these examples, we carefully check the input variable to make sure that it is properly instantiated and that it meets the criteria we expect, before ever actually using it in our code. We are raising exceptions here, but we could also include some logging code to track these errors. In addition, we should write unit tests that test each of these checks and make sure they are working properly, and these tests will help us make sure we don’t accidentally remove this code in a later version.
Another important concept in security is writing programs and designing systems that will fail in a safe manner. This can be especially important for software that controls parts of our physical environment, such as medical device software.
For example, if we are writing software that is used to lock a safe, what should happen when the software fails to recognize the input? Should it allow the door to be opened? In this case, probably not, since we want the items in the safe to be protected even if the software fails.
On the other hand, if the software is used to lock the doors on a car, it should probably be programmed to unlock the doors in certain situations, such as when an accident occurs. In that case, it could be more important to allow emergency responders to open the door than protecting the occupants of the car.
There are many more techniques and concepts related to security and defensive programming. See the resources listed below for more information.
Now that you have some programming knowledge and skill, you might consider looking for a job that makes use of those skills. So, let’s take a look at some related information that might be useful to you in that path.
A résumé for a technical career field such as programming can be quite a bit different from résumés in other fields. This is mainly because a technical résumé should cover more than just work experience, including projects, programming skills, technical knowledge, and more. While there are many guides online for building a technical résumé, here are a few things that you might want to consider including:
Either as part of your work experience, a separate section, or sometimes both, you’ll want to talk about any programming projects you have worked on, even in your own time. For example, you could definitely include the restaurant project from this semester as a guided project, as well as your final project as an example of your own independent work. When discussing your projects, be clear about what programming language and technologies you used to build the project, as well as your contribution if you were working as part of a team. This gives the reader a clear understanding of the types of projects you’ve worked on, the languages and technologies you are likely to be familiar with, and your level of contribution to the project itself.
This résumé section is somewhat unique to programmers, but it is one of the most important sections to include. In this section, you’ll want to list all of the programming languages, technologies, frameworks, platforms, and more than you are familiar with. This can sometimes read like a “buzzword-compliant” list of items, but for a recruiter it can hold valuable information. Many times, an organization is looking for a programmer with experience or familiarity with a particular set of languages and technologies, and if you can quickly show that you’ve worked with them, you’ll become a top contender for the job.
For example, consider all of the tools you’ve worked with just in this course. Here’s a short list of things that you could list on your résumé, depending on what you used in this course:
Of course, you may know some of these more than others, and it is definitely recommended to be honest about your level of skill with each of these, but you already have quite an impressive list of skills and technologies you are familiar with.
Another possible path would be to earn some certifications. A certification is usually given by some organization based on earning a passing score on an exam, and can serve as further proof of your knowledge as a programmer.
Within the field of programming, certifications are viewed with somewhat mixed feelings. For programmers with little experience, earning a certification can help demonstrate proficiency with a language or technology that would be otherwise difficult to prove, but many jobs either don’t look for certifications from new hires, or there are simply too many certifications to know which one would be useful, if any.
In general, we don’t direct students toward earning a certification as a next step after this course, but we don’t discourage it either. Depending on your chosen career path, there may be certifications available that could help you.
We recommend doing some research, either by talking to companies and others in the field you are interested in, or meeting with an advisor or career counselor to explore your options. There are definitely some good certifications out there covering both the Java and Python programming languages that would be easily achievable after completing this course (with a bit more study).
We’ve been using Codio as our development environment throughout this program, mainly because it is purposely designed to provide a great educational experience for novice programmers, while allowing instructors easy access to help students when they get stuck. We have also made use of the automated grading features available in Codio throughout this program.
However, outside of these courses, you won’t have access to Codio and will instead need to find another tool to help you develop your programs. These tools are collectively called Integrated Development Environments, or IDEs, and are the primary tool in a programmer’s toolbox. Let’s look at a few options you might want to consider using in the future.
Visual Studio Code is a free IDE from Microsoft, and uses many of the same concepts and features present in their Visual Studio IDE for professionals. It supports many languages, including both Java and Python, and is also available for Windows, Mac and Linux.
To develop Java on your own computer, you’ll first need to install a Java Development Kit. There are many different IDEs available for Java, but the three most popular are:
Python can be easily installed on just about any system. The Python Website contains download-able installers for many different versions of Python.
For Python, one of the most well known IDEs is PyCharm. Also developed by JetBrains and available in both paid and “Community” versions, PyCharm fits the bill as one of the more feature-rich IDEs for working with Python.
On many platforms the IDLE “Integrated Learning and Development Environment” is installed by default along with Python, and is a great choice for working with smaller Python projects.
Many Python developers also prefer to write code in a simple text editor, so tools such as Atom from GitHub are also popular.
There are many other tools that programmers can use to do their work. Here are just a few of them that we are familiar with and have used in the past.
Finally, it is very important for programmers to always stay on top of new developments and technologies, and it can seem like a daunting task to even know where to look. Let’s review some of the resources that are commonly used by programmers to keep up with the latest news and learn about technologies that they may want to use.
There are many news sites on the web that focus specifically on news related to technology and programming. We encourage you to search around and find sites that are relevant to you and your interest, but here are a few of the more well-known sites:
Likewise, there are many sites that focus on social media and discussion, including some great places to ask questions and get answers to even the most difficult technical questions:
Finally, each many resources are language-specific as well. Here are a few worth noting for each language:
If there are other resources that you’ve found useful, please feel free to share them! Contact the course instructor and share your sites, and you can earn some extra-credit points for a bug bounty!
This chapter covers many helpful topics in programming that don’t fit neatly anywhere else in the book. We hope that a few of these items will be useful to you as you continue to build your programming skill.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.



