Introduction to Databases

Databases are essentially everywhere with modern technology. We live in a digital age, far more connected online than ever, and utilizing a number of smart devices that generate thousands of data points just for a single person. Our digital foot print is always growing…even more so for companies that are able to store far more data than they used to about their operation. Almost every application or smart device we use is connected to some form of database to store information it creates/collects.
The before times… Databases allow us to manipulate and store information significantly faster and in much larger volumes than ever before. But before databases existed, of course we had classic paper filing systems. Though, even when we started to advance technologies and created digital computers, data still was not readily accessible at our fingertips in large amounts. A lot of data was stored in single or multiple files like text files on computers for quite some time. File-based data storage and access is difficult to work with, resulting in a tediously written programs that resulted in a lot of repeated code. Data integrity, retention, and access also presents a major issue, particularly when more than one device/program/person needs to work the with data at the same time.
The main concept behind a database is a centralized data store that manages data integrity and allows fast retrieval and manipulation of data. Initially, when the idea of a data store or database was materialized, they weren’t really that much better than a normal file store. They were typically a static system in the 1960’s, which meant that modifications were tedious and hard to complete. More so, programmers had to know the physical structure of the database in order to utilize the data.
Most modern databases are quite dynamic and typically require only knowledge of the logical structure structure of the data. There are also numerous programming libraries that make interfacing with a database using your favorite language much easier than doing everything by hand!
In 1970, Edgar F. Codd, a researcher at IBM published the paper A Relational Model of Data for Large Shared Data Banks. In this paper, he outlines how database systems could utilize mathematical foundations in set theory, predicate logic, and relational algebra. This work led to the creation of some of the first relational databases as well as the language used to work them called the Structured Query Language (SQL). We will be re-visiting some of Codd’s work throughout this course!
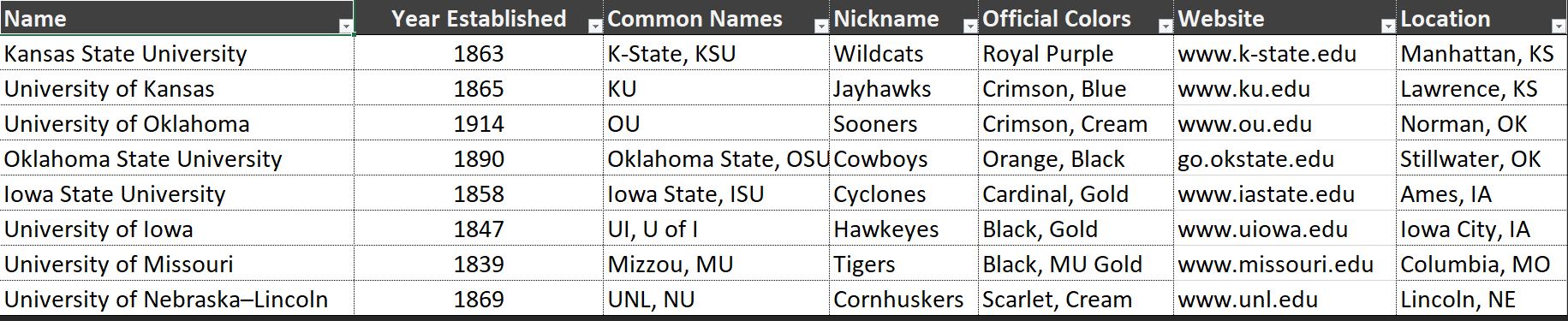
Here we can see some basic information about universities in a table. Much of the data we use in relational databases resemble this format, except the information is typically at a much larger scale. A lot of situations find this data being stored in spreadsheets, comma separated value (csv) files, and alike; however, these formats have limited capability in manipulating and storing data. Spreadsheet applications can do some of this type of work, but there are limits…particularly in terms of scalability, accessibility, and reliability. That is where relational databases come into play!
In mathematics, when we perform operations on numbers, we get numbers as a result. So in databases, when we perform operations on datasets, we can get new datasets as a result. The vast majority of operations we perform on a database will be done in the form of a query. Think of a query as a question that we would like answered about some data or entity. The word entity can be used to describe a single record about something contained in a database, like one single student record. We can extract entities using a query with three primary database operations: selection, projection, and join.
The term entity may be used interchangeably with records and rows in certain scenarios; however, at their core, they don’t always mean the same thing.
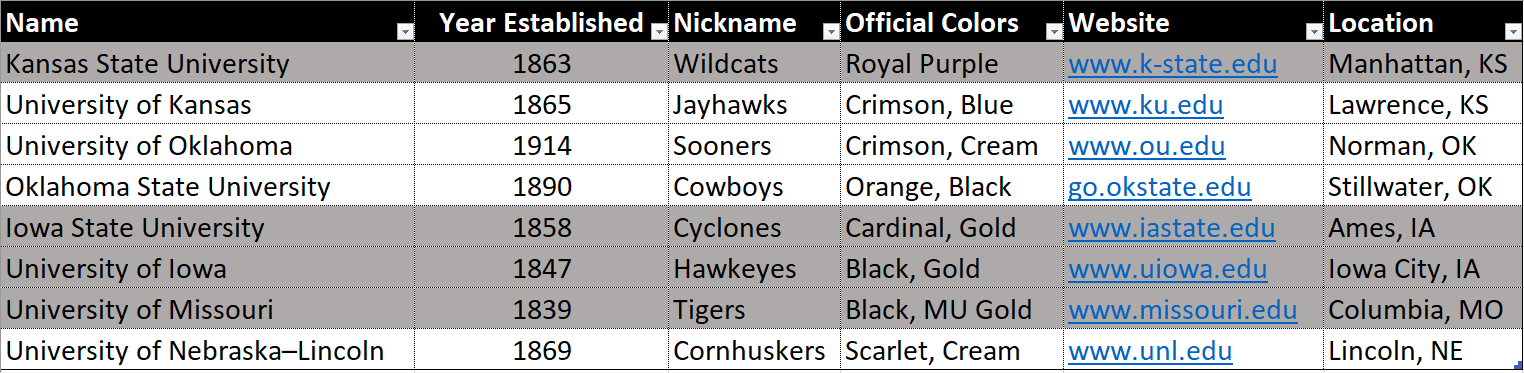
Selection is used to extract a specific subset of rows that match a certain predicate (condition). This operation acts like a filter for querying data. The highlighted rows below are from selecting universities where the ‘Year Established’ is on or before 1863.
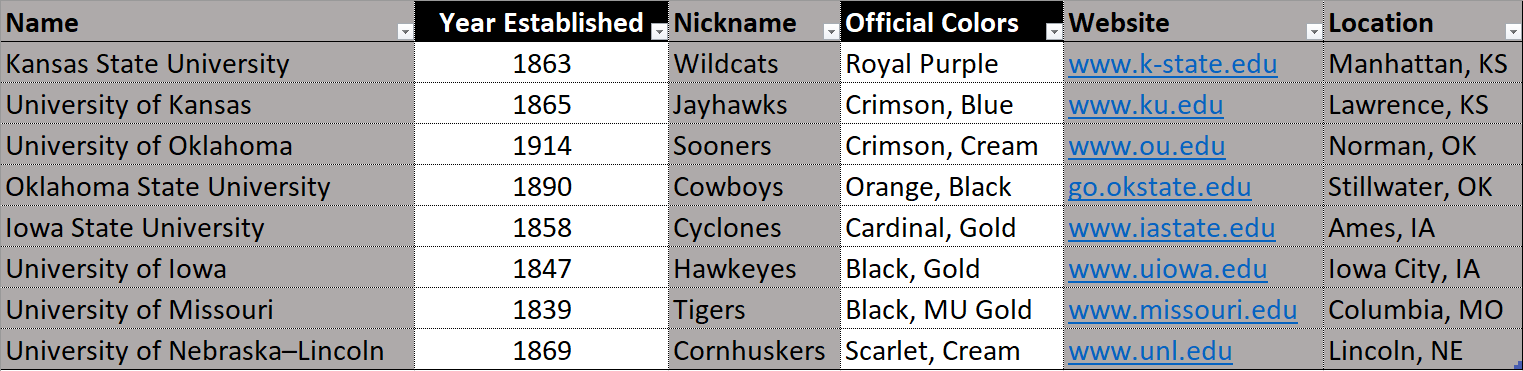
Projection is used to extract a specific subset of columns. This operation chooses which parts of the data are used. The columns that are chosen based off of the provided column names. The highlighted columns in the table below represent the projection of the columns ‘Name’, ‘Nickname’, ‘Website’, and ‘Location’. Note that when projection is used without selection, all rows of data are included.
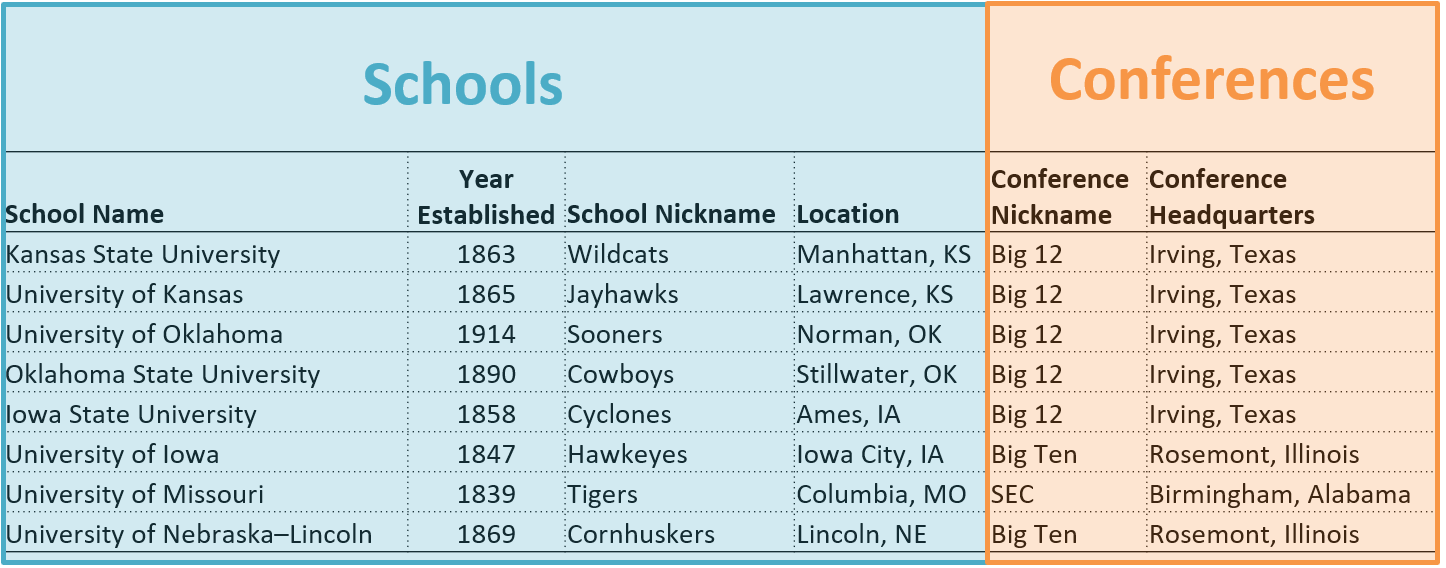
Join is used to combine data from multiple datasets. There are different types of joins that we will talk about…but when tables are joined, not all data has to be included in the operation. In the example below, you can see how the ‘School’ dataset can be joined with parts of the ‘Conferences’ dataset to create a new dataset all together.
The operations selection and projection can be a bit confusing at first…but not in what the operations actually do. The confusion comes from the SQL language syntax. The SELECT statement in SQL is actually the projection operation and the WHERE statement is one of multiple ways to do a selection operation in SQL.
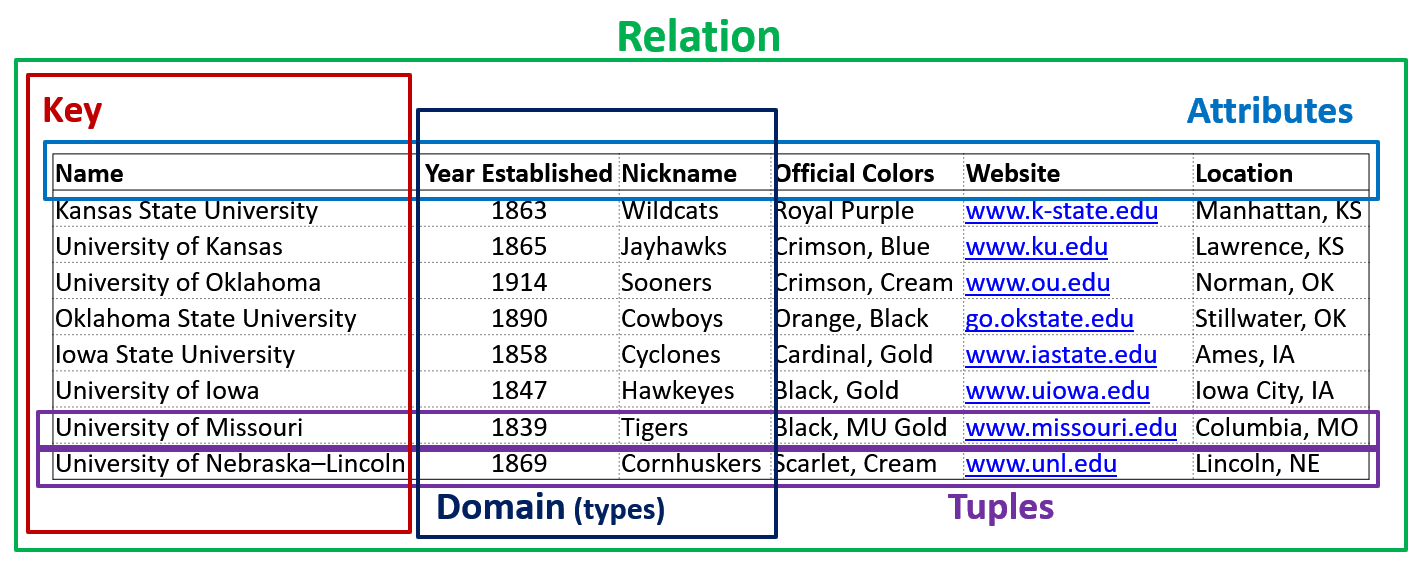
There are a lot of terms that are used when working with databases. Some words can be used interchangeably.
Relations: Two-dimensional tables, each with rows and columns.
Attributes: The columns of the relation. The attributes are a set, not a list.
Tuples: The rows in the relation. The tuples are a set, not a list.
Domain: An elementary type for each attribute. A value must not be a set, list, array, etc.
Keys: A set of attributes that prevent two tuples in the relation to have the same values in all the key attributes.
Combining the above concepts into a complete database design is the database schema.