Classes and Objects
Getting Object Oriented
Getting Object Oriented
A signature aspect of object-oriented languages is (as you might expect from the name), the existence of objects within the language. In this chapter, we take a deep look at objects, exploring why they were created, what they are at both a theoretical and practical level, and how they are used.
Some key terms to learn in this chapter are:
Encapsulation
Information Hiding
Message Passing
State
Class
Object
Field
Method
Constructor
Parameterless Constructor
Property
Public
Private
Static
To begin, we’ll examine the term encapsulation.
The first criteria that Alan Kay set for an object-oriented language was encapsulation. In computer science, the term encapsulation refers to organizing code into units. This provides a mechanism for organizing complex software.
A second related idea is information hiding, which provides mechanisms for controlling access to encapsulated data and how it can be changed.
Think back to the FORTRAN EPIC model we introduced earlier. All of the variables in that program were declared globally, and there were thousands. How easy was it to find where a variable was declared? Initialized? Used? Are you sure you found all the spots it was used?
Also, how easy was it to determine what part of the system a particular block of code belonged to? If I told you the program involved modeling hydrology (how water moves through the soils), weather, erosion, plant growth, plant residue decomposition, soil chemistry, planting, harvesting, and chemical applications, would you be able to find the code for each of those processes?
Remember from our discussion on the growth of computing the idea that as computers grew more powerful, we wanted to use them in more powerful ways? The EPIC project grew from that desire - what if we could model all the aspects influencing how well a crop grows? Then we could use that model to help us make better decisions in agriculture. Or, what if we could model all the processes involved in weather? If we could do so, we could help save lives by predicting dangerous storms! A century ago, you knew a tornado was coming when you heard its roaring winds approaching your home. Now we have warnings that conditions are favorable to produce one hours in advance. This is all thanks to using computers to model some very complex systems.
But how do we go about writing those complex systems? I don’t know about you, but I wouldn’t want to write a model the way the EPIC programmers did. And neither did most software developers at the time - so computer scientists set out to define better ways to write programs. David Parnas formalized some of the best ideas emerging from those efforts in his 1972 paper “On the Criteria To Be Used in Decomposing Systems into Modules”. 1
A data structure, its internal linkings, accessing procedures and modifying procedures are part of a single module.
Here he suggests organizing code into modules that group related variables and the procedures that operate upon them. For the EPIC module, this might mean all the code related to weather modeling would be moved into its own module. That meant that if we needed to understand how weather was being modeled, we only had to look at the weather module.
They are not shared by many modules as is conventionally done.
Here he is laying the foundations for the concept we now call scope - the idea of where a specific symbol (a variable or function name) is accessible within a program’s code. By limiting access to variables to the scope of a particular module, only code in that module can change the value. That way, we can’t accidentally change a variable declared in the weather module from the soil chemistry module (which would be a very hard error to find, as if the weather module doesn’t seem to be working, that’s what we would probably focus on trying to fix).
Programmers of the time referred to this practice as information hiding, as we ‘hid’ parts of the program from other parts of the program. Parnas and his peers pushed for not just hiding the data, but also how the data was manipulated. By hiding these implementation details, they could prevent programmers who were used to the globally accessible variables of early programming languages from looking into our code and using a variable that we might change in the future.
The sequence of instructions necessary to call a given routine and the routine itself are part of the same module.
As the actual implementation of the code is hidden from other parts of the program, a mechanism for sharing controlled access to some part of that module in order to use it needed to be made. An interface, if you will, that describes how the other parts of the program might trigger some behavior or access some value.
D. L. Parnas, “On the criteria to be used in decomposing systems into modules” Communications of the ACM, Dec. 1972. ↩︎
Let’s start by focusing on encapsulation’s benefits to organizing our code by exploring some examples of encapsulation you may already be familiar with.
The C# libraries are organized into discrete units called namespaces. The primary purpose of this is to separate code units that potentially use the same name, which causes name collisions where the interpreter isn’t sure which of the possibilities you mean in your program. This means you can use the same name to refer to two different things in your program, provided they are in different namespaces.
For example, there are two definitions for a Point Struct in the .NET core libraries: System.Drawing.Point and System.Windows.Point. The two have a very different internal structures (the former uses integers and the latter doubles), and we would not want to mix them up. If we needed to create an instance of both in our program, we would use their fully-quantified name to help the interpreter know which we mean:
System.Drawing.Point pointA = new System.Drawing.Point(500, 500);
System.Windows.Point pointB = new System.Windows.Point(300.0, 200.0);The using directive allows you to reference the type without quantification, i.e.:
using System.Drawing;
Point pointC = new Point(400, 400);You can also create an alias with the using directive, providing an alternative (and usually abbreviated) name for the type:
using WinPoint = System.Windows.Point;
WinPoint pointD = new WinPoint(100.0, 100.0);We can also declare our own namespaces, allowing us to use namespaces to organize our own code just as Microsoft has done with its .NET libraries.
Encapsulating code within a namespace helps ensure that the types defined within are only accessible with a fully qualified name, or when the using directive is employed. In either case, the intended type is clear, and knowing the namespace can help other programmers find the type’s definition.
In the discussion of namespaces, we used a struct. A C# struct is what computer scientists refer to as a compound type, a type composed from other types. This too, is a form of encapsulation, as it allows us to collect several values into a single data structure. Consider the concept of a vector from mathematics - if we wanted to store three-dimensional vectors in a program, we could do so in several ways. Perhaps the easiest would be as an array:
double[] vectorA = {3, 4, 5};However, other than the variable name, there is no indication to other programmers that this is intended to be a three-element vector. And, if we were to accept it in a function, say a dot product:
public double DotProduct(double[] a, double[] b) {
if(a.Length < 3 || b.Length < 3) throw new ArgumentException();
return a[0] * b[0] + a[1] * b[1] + a[2] * b[2];
}We would need to check that both arrays were of length three… A struct provides a much cleaner option, by allowing us to define a type that is composed of exactly three doubles:
/// <summary>
/// A 3-element vector
/// </summary>
public struct Vector3 {
public double x;
public double y;
public double z;
public Vector3(double x, double y, double z) {
this.x = x;
this.y = y;
this.z = z;
}
}Then, our DotProduct can take two arguments of the Vector3 struct:
public double DotProduct(Vector3 a, Vector3 b) {
return a.x * b.x + a.y * b.y + a.z * b.z;
}There is no longer any concern about having the wrong number of elements in our vectors - it will always be three. We also get the benefit of having unique names for these fields (in this case, x, y, and z).
Thus, a struct allows us to create structure to represent multiple values in one variable, encapsulating the related values into a single data structure. Variables, and compound data types, represent the state of a program. We’ll examine this concept in detail next.
You might think that the kind of modules that Parnas was describing don’t exist in C#, but they actually do - we just don’t call them ‘modules’. Consider how you would raise a number by a power, say 10 to the 8th power:
Math.Pow(10, 8);The Math class in this example is actually used just like a module! We can’t see the underlying implementation of the Pow() method, it provides to us a well-defined interface (i.e. you call it with the symbol Pow and two doubles for parameters), and this method and other related math functions (Sin(), Abs(), Floor(), etc.) are encapsulated within the Math class.
We can define our own module-like classes by using the static keyword, i.e. we could group our vector math functions into a static VectorMath class:
/// <summary>
/// A library of vector math functions
/// </summary>
public static class VectorMath() {
/// <summary>
/// Computes the dot product of two vectors
/// </summary>
public static double DotProduct(Vector3 a, Vector3 b) {
return a.x * b.x + a.y * b.y + a.z * b.z;
}
/// <summary>
/// Computes the magnitude of a vector
/// </summary>
public static double Magnitude(Vector3 a) {
return Math.Sqrt(Math.Pow(a.x, 2) + Math.Pow(a.y, 2) + Math.Pow(a.z, 2));
}
}To duplicate the module behavior with C#, we must declare both the class and its methods static.
But what most distinguishes C# is that it is an object-oriented language, and as such, its primary form of encapsulation is classes and objects. The key idea behind encapsulation in an object-oriented language is that we encapsulate both state and behavior in the class definition. Let’s explore that idea more deeply in the next section.
The data stored in a program at any given moment (in the form of variables, objects, etc.) is the state of the program. Consider a variable:
int a = 5;The state of the variable a after this line is 5. If we then run:
a = a * 3;The state is now 15. Consider the Vector3 struct we defined in the last section:
public struct Vector3 {
public double x;
public double y;
public double z;
// constructor
public Vector3(double x, double y, double z) {
this.x = x;
this.y = y;
this.z = z;
}
}If we create an instance of that struct in the variable b:
Vector3 b = new Vector3(1.2, 3.7, 5.6);The state of our variable b is $\{1.2, 3.7, 5.6\}$. If we change one of b’s fields:
b.x = 6.0;The state of our variable b is now $\{6.0, 3.7, 5.6\}$.
We can also think about the state of the program, which would be something like: $\{a: 5, b: \{x: 6.0, y: 3.7, z: 5.6\}\}$, or a state vector like: $|5, 6.0, 3.7, 5.6|$. We can therefore think of a program as a state machine. We can in fact, draw our entire program as a state table listing all possible legal states (combinations of variable values) and the transitions between those states. Techniques like this can be used to reason about our programs and even prove them correct!
This way of reasoning about programs is the heart of Automata Theory, a subject you may choose to learn more about if you pursue graduate studies in computer science.
What causes our program to transition between states? If we look at our earlier examples, it is clear that assignment is a strong culprit. Expressions clearly have a role to play, as do control-flow structures decide which transformations take place. In fact, we can say that our program code is what drives state changes - the behavior of the program.
Thus, programs are composed of both state (the values stored in memory at a particular moment in time) and behavior (the instructions to change that state).
Now, can you imagine trying to draw the state table for a large program? Something on the order of EPIC?
On the other hand, with encapsulation we can reason about state and behavior on a much smaller scale. Consider this function working with our Vector3 struct:
/// <summary>
/// Returns the the supplied vector scaled by the provided scalar
/// </summary>
public static Vector3 Scale(Vector3 vec, double scale) {
double x = vec.x * scale;
double y = vec.y * scale;
double z = vec.z * scale;
return new Vector3(x, y, z);
}If this method was invoked with a vector $\langle4.0, 1.0, 3.4\rangle$ and a scalar $2.0$ our state table would look something like:
| step | vec.x | vec.y | vec.z | scale | x | y | z | return.x | return.y | return.z |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.0 | 1.0 | 3.4 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 2.0 | 6.8 | 0.0 | 0.0 | 0.0 |
| 4 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 2.0 | 6.8 | 8.0 | 2.0 | 6.8 |
Because the parameters vec and scale, as well as the variables x, y, z, and the unnamed Vector3 we return are all defined only within the scope of the method, we can reason about them and the associated state changes independently of the rest of the program. Essentially, we have encapsulated a portion of the program state in our Vector3 struct, and encapsulated a portion of the program behavior in the static Vector3 library. This greatly simplifies both writing and debugging programs.
However, we really will only use the Vector3 library in conjunction with Vector3 structures, so it makes a certain amount of sense to define them in the same place. This is where classes and objects come into the picture, which we’ll discuss next.
The module-based encapsulation suggested by Parnas and his contemporaries grouped state and behavior together into smaller, self-contained units. Alan Kay and his co-developers took this concept a step farther. Alan Kay was heavily influenced by ideas from biology, and saw this encapsulation in similar terms to cells.
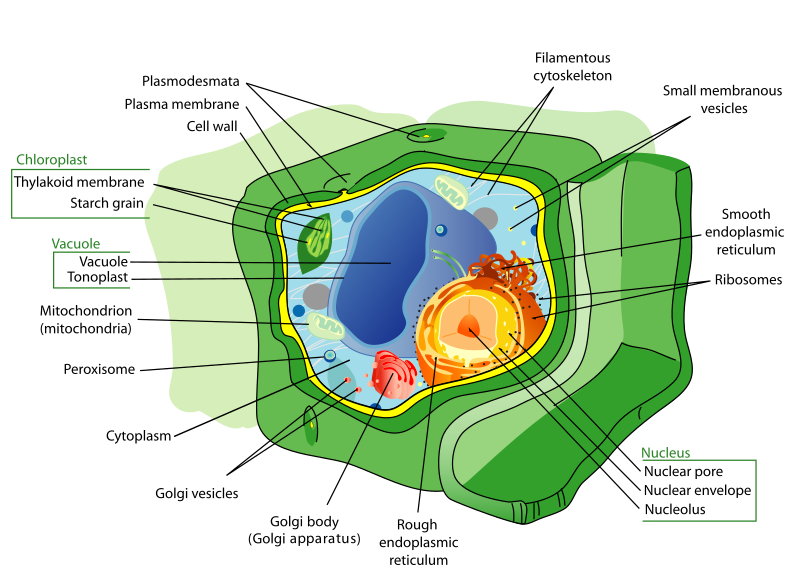
Biological cells are also encapsulated - the complex structures of the cell and the functions they perform are all within a cell wall. This wall is only bridged in carefully-controlled ways, i.e. cellular pumps that move resources into the cell and waste out. While single-celled organisms do exist, far more complex forms of life are made possible by many similar cells working together.
This idea became embodied in object-orientation in the form of classes and objects. An object is like a specific cell. You can create many, very similar objects that all function identically, but each have their own individual and different state. The class is therefore a definition of that type of object’s structure and behavior. It defines the shape of the object’s state, and how that state can change. But each individual instance of the class (an object) has its own current state.
Let’s re-write our Vector3 struct as a class using this concept:
/// <summary>A class representing a 3-element vector</summary>
public class Vector3 {
/// <summary>The X component of the vector</summary>
public double X;
/// <summary>The Y component of the vector</summary>
public double Y;
/// <summary>The Z component of the vector</summary>
public double Z;
/// <summary>Constructs a new vector</summary>
/// <param name="x">The value of the vector's x component</param>
/// <param name="y">The value of the vector's y component</param>
/// <param name="z">The value of the vector's z component</param>
public Vector3(double x, double y, double z) {
X = x;
Y = y;
Z = z;
}
/// <summary>Computes the dot product of this and <paramref name="other"/> vector</summary>
/// <param name="other">The other vector to compute with</param>
/// <returns>The dot product</returns>
public double DotProduct(Vector3 other) {
return X * other.X + Y * other.Y + Z * other.Z;
}
/// <summary>Scales this vector by <paramref name="scalar"/></summary>
/// <paramref name="scalar">The value to scale by</paramref>
public void Scale(double scalar) {
X *= scalar;
Y *= scalar;
Z *= scalar;
}
}Here we have defined:
X, Y, and ZVector3() constructor that takes a value for the object’s initial stateScale() methodWe can create as many objects from this class definition as we might want:
Vector3 one = new Vector3(1.0, 1.0, 1.0);
Vector3 up = new Vector3(0.0, 1.0, 0.0);
Vector3 a = new Vector3(5.4, -21.4, 3.11);Conceptually, what we are doing is not that different from using a compound data type like a struct and a module of functions that work upon that struct. But practically, it means all the code for working with Vectors appears in one place. This arguably makes it much easier to find all the pertinent parts of working with vectors, and makes the resulting code better organized and easier to maintain and add features to.
Classes also provide additional benefits over structs in the form of polymorphism, which we’ll discuss in Chapter 2.
Now let’s return to the concept of information hiding, and how it applies in object-oriented languages.
Unanticipated changes in state are a major source of errors in programs. Again, think back to the EPIC source code we looked at earlier. It may seem unusual now, but it used a common pattern from the early days of programming, where all the variables the program used were declared in one spot, and were global in scope (i.e. any part of the program could reassign any of those variables).
If we consider the program as a state machine, that means that any part of the program code could change any part of the program state. Provided those changes were intended, everything works fine. But if the wrong part of the state was changed problems would ensue.
For example, if you were to make a typo in the part of the program dealing with water run-off in a field which ends up assigning a new value to a variable that was supposed to be used for crop growth, you’ve just introduced a very subtle and difficult-to-find error. When the crop growth modeling functionality fails to work properly, we’ll probably spend serious time and effort looking for a problem in the crop growth portion of the code… but the problem doesn’t lie there at all!
There are several techniques involved in data hiding in an object-oriented language. One of these is access modifiers, which determine what parts of the program code can access a particular class, field, property, or method. Consider a class representing a student:
public class Student {
private string _first;
private string _last;
private uint _wid;
public Student(string first, string last, uint wid) {
this._first = first;
this._last = last;
this._wid = wid;
}
}By using the access modifier private, we have indicated that our fields _first, _last, and _wid cannot be accessed (seen or assigned to) outside of the code that makes up the Student class. If we were to create a specific student:
Student willie = new Student("Willie", "Wildcat", 888888888);We would not be able to change his name, i.e. willie._first = "Bob" would fail, because the field _first is private. In fact, we cannot even see his name, so Console.WriteLine(willie._first); would also fail.
If we want to allow a field or method to be accessible outside of the object, we must declare it public. While we can declare fields public, this violates the core principles of encapsulation, as any outside code can modify our object’s state in uncontrolled ways.
Instead, in a true object-oriented approach we would write public accessor methods, a.k.a. getters and setters (so called because they get or set the value of a field). These methods allow us to see and change field values in a controlled way. Adding accessors to our Student class might look like:
/// <summary>A class representing a K-State student</summary>
public class Student
{
private string _first;
private string _last;
private uint _wid;
/// <summary>Constructs a new student object</summary>
/// <param name="first">The new student's first name</param>
/// <param name="last">The new student's last name</param>
/// <param wid="wid">The new student's Wildcat ID number</param>
public Student(string first, string last, uint wid)
{
_first = first;
_last = last;
_wid = wid;
}
/// <summary>Gets the first name of the student</summary>
/// <returns>The student's first name</returns>
public string GetFirst()
{
return _first;
}
/// <summary>Sets the first name of the student</summary>
public void SetFirst(string value)
{
if (value.Length > 0) _first = value;
}
/// <summary>Gets the last name of the student</summary>
/// <returns>The student's last name</returns>
public string GetLast()
{
return _last;
}
/// <summary>Sets the last name of the student</summary>
/// <param name="value">The new name</summary>
/// <remarks>The <paramref name="value"/> must be a non-empty string</remarks>
public void SetLast(string value)
{
if (value.Length > 0) _last = value;
}
/// <summary>Gets the student's Wildcat ID Number</summary>
/// <returns>The student's Wildcat ID Number</returns>
public uint GetWid()
{
return _wid;
}
/// <summary>Gets the full name of the student</summary>
/// <returns>The first and last name of the student as a string</returns>
public string GetFullName()
{
return $"{_first} {_last}"
}
}Notice how the SetFirst() and SetLast() method check that the provided name has at least one character? We can use setters to make sure that we never allow the object state to be set to something that makes no sense.
Also, notice that the _wid field only has a getter. This effectively means once a student’s Wid is set by the constructor, it cannot be changed. This allows us to share data without allowing it to be changed outside of the class.
Finally, the GetFullName() is also a getter method, but it does not have its own private backing field. Instead it derives its value from the class state. We sometimes call this a derived getter for that reason.
While accessor methods provide a powerful control mechanism in object-oriented languages, they also require a lot of typing the same code syntax over and over (we often call this boilerplate). Many languages therefore introduce a mechanism for quickly defining basic accessors. In C#, we have Properties. Let’s rewrite our Student class with Properties:
public class Student {
private string _first;
/// <summary>The student's first name</summary>
public string First {
get { return _first; }
set { if(value.Length > 0) _first = value;}
}
private string _last;
/// <summary>The student's last name</summary>
public string Last {
get { return _last; }
set { if(value.Length > 0) _last = value; }
}
private uint _wid;
/// <summary>The student's Wildcat ID number</summary>
public uint Wid {
get { return this._wid; }
}
/// <summary>The student's full name</summary>
public string FullName
{
get
{
return $"{First} {Last}";
}
}
/// <summary>The student's nickname</summary>
public string Nickname { get; set; }
/// <summary>Constructs a new student object</summary>
/// <param name="first">The new student's first name</param>
/// <param name="last">The new student's last name</param>
/// <param name="nick">The new student's nickname</param>
/// <param wid="wid">The new student's Wildcat ID number</param>
public Student(string first, string last, string nick, uint wid) {
_first = first;
_last = last;
Nickname = nick;
_wid = wid;
}
}If you compare this example to the previous one, you will note that the code contained in bodies of the get and set are identical to the corresponding getter and setter methods. Essentially, C# properties are shorthand for writing out the accessor methods. In fact, when you compile a C# program it transforms the get and set back into methods, i.e. the get in first is used to generate a method named get_First().
While properties are methods, the syntax for working with them in code is identical to that of fields, i.e. if we were to create and then print a Student’s identifying information, we’d do something like:
Student willie = new Student("Willie", "Wildcat", "WillieCat", 99999999);
Console.Write("Hello, ")
Console.WriteLine(willie.FullName);
Console.Write("Your WID is:");
Console.WriteLine(willie.Wid);Note too that we can declare properties with only a get or a set body, and that properties can be derived from other state rather than having a private backing field.
While C# properties are used like fields, i.e. Console.WriteLine(willie.Wid) or willie.First = "William", they are actually methods. As such, they do not add structure to hold state, hence the need for a backing variable.
The Nickname property in the example above is special syntax for an implicit backing field - the C# compiler creates the necessary space to hold the value. But we can only access the value stored through that property. If you need direct access to it, you must create a backing variable.
However, we don’t always need a backing variable for a Property getter if the value of a property can be calculated from the current state of the class, e.g., consider our FullName property in our Student class:
public string FullName
{
get
{
return $"{First} {Last}"
}
}Here we’re effectively generating the value of the FullName property from the First and Last properties every time the FullName property is requested. This does cause a bit more computation, but we also know that it will always reflect the current state of the first and last names.
Not all properties need to do extra logic in the get or set body. Consider our Vector3 class we discussed earlier. We used public fields to represent the X, Y, and Z components, i.e.:
public double X = 0;If we wanted to switch to using properties, the X property would end up like this:
private double _x = 0;
public double X
{
get
{
return _x;
}
set
{
_x = value;
}
}Which seems like a lot more work for the same effect. To counter this perception and encourage programmers to use properties even in cases like this, C# also supports auto-property syntax. An auto-property is written like:
public double X {get; set;} = 0;Note the addition of the {get; set;} - this is what tells the compiler we want a property and not a field. When compiled, this code is transformed into a full getter and setter whose bodies match the basic get and set in the example above. The compiler even creates a private backing field (but we cannot access it in our code, because it is only created at compile time). Any time you don’t need to do any additional logic in a get or set, you can use this syntax.
Note that in the example above, we set a default value of 0. You can omit setting a default value. You can also define a get-only autoproperty that always returns the default value (remember, you cannot access the compiler-generated backing field, so it can never be changed):
public double Pi {get;} = 3.14;In practice, this is effectively a constant field, so consider carefully if it is more appropriate to use that instead:
public const PI = 3.14;While it is possible to create a set-only auto-property, you will not be able access its value, so it is of limited use.
Later versions of C# introduced a concise way of writing functions common to functional languages known as lambda syntax, which C# calls Expression-Bodied Members.
Properties can be written using this concise syntax. For example, our FullName get-only derived property in the Student written as an expression-bodied read-only property would be:
public FullName => $"{FirstName} {LastName}"Note the use of the arrow formed by an equals and greater than symbol =>. Properties with both a getter and setter can also be written as expression-bodied properties. For example, our FirstName property could be rewritten:
public FirstName
{
get => _first;
set => if(value.Length > 0) _first = value;
}This syntax works well if your property bodies are a single expression. However, if you need multiple lines, you should use the regular property syntax instead (you can also mix and match, i.e. use an expression-bodied get with a regular set).
It is possible to declare your property as public and give a different access level to one of the accessors, i.e. if we wanted to add a GPA property to our student:
public double GPA { get; private set; } = 4.0;In this case, we can access the value of the GPA outside of the student class, but we can only set it from code inside the class. This approach works with all ways of defining a property.
C# 9.0 introduced a third accessor, init. This also sets the value of the property, but can only be used when the class is being initialized, and it can only be used once. This allows us to have some properties that are immutable (unable to be changed).
Our student example treats the Wid as immutable, but we can use the init keyword with an auto-property for a more concise representation:
public uint Wid {get; init;}And in the constructor, replace setting the backing field (_wid = wid) with setting the property (Wid = wid). This approach is similar to the public property/private setter, but won’t allow the property to ever change once declared.
The above video and below textbook content cover the same ideas (but are not identical). Feel free to pick one or the other.
Before we move on to our next concept, it is helpful to explore how programs use memory. Remember that modern computers are stored program computers, which means the program as well as the data are stored in the computer’s memory. A Universal Turing Machine, the standard example of a stored program computer, reads the program from the same paper tape that it reads its inputs to and writes its output to. In contrast, to load a program in the ENIAC, the first electronic computer in the United States, programmers had to physically rewire the computer (it was later modified to be a stored-program computer).
When a program is run, the operating system allocates part of the computer’s memory (RAM) for the program to use. This memory is divided into three parts - the static memory, the stack, and the heap.

The program code itself is copied into the static section of that memory, along with any literals (1, "Foo"). Additionally, the space to hold any variables that are declared static is allocated here. The reason this memory space is called static is that it is allocated when the program begins, and remains allocated for as long as the program is running. It does not grow or shrink (though the value of static variables may change).
The stack is where the space for scoped variables is allocated. We often call it the stack because functionally it is used like the stack data structure. The space for global variables is allocated first, at the “bottom” of the stack. Then, every time the program enters a new scope (i.e. a new function, a new loop body, etc.) the variables declared there are allocated on the stack. When the program exits that scope (i.e. the function returns, the loop ends), the memory that had been reserved for those values is released (like the stack pop operation).
Thus, the stack grows and shrinks over the life of the program. The base of the stack is against the static memory section, and it grows towards the heap. If it grows too much, it runs out of space. This is the root cause of the nefarious stack overflow exception. The stack has run out of memory, most often because an infinite recursion or infinite loop.
Finally, the heap is where dynamically allocated memory comes from - memory the programmer specifically reserved for a purpose. In C programming, you use the calloc(), malloc(), or realloc() to allocate space manually. In Object-Oriented languages, the data for individual objects are stored here. Calling a constructor with the new keyword allocates memory on the heap, the constructor then initializes that memory, and then the address of that memory is returned. We’ll explore this process in more depth shortly.
This is also where the difference between a value type and a reference type comes into play. Value types include numeric objects like integers, floating point numbers, and also booleans. Reference types include strings and classes. When you create a variable that represents a value type, the memory to hold its value is created in the stack. When you create a variable to hold a reference type, it also has memory in the stack - but this memory holds a pointer to where the object’s actual data is allocated in the heap. Hence the term reference type, as the variable doesn’t hold the object’s data directly - instead it holds a reference to where that object exists in the heap!
This is also where null comes from - a value of null means that a reference variable is not pointing at anything.
The objects in the heap are not limited to a scope like the variables stored in the stack. Some may exist for the entire running time of the program. Others may be released almost immediately. Accordingly, as this memory is released, it leaves “holes” that can be re-used for other objects (provided they fit). Many modern programming languages use a garbage collector to monitor how fragmented the heap is becoming, and will occasionally reorganize the data in the heap to make more contiguous space available.
We often talk about the class as a blueprint for an object. This is because classes define what properties and methods an object should have, in the form of the class definition. An object is created from this blueprint by invoking the class’ constructor. Consider this class representing a planet:
/// <summary>
/// A class representing a planet
// </summary>
public class Planet {
/// <summary>
/// The planet's mass in Earth Mass units (~5.9722 x 10^24kg)
/// </summary>
private double mass;
public double Mass
{
get { return mass; }
}
/// <summary>
/// The planet's radius in Earth Radius units (~6.738 x 10^6m)
/// </summary>
private double radius;
public double Radius
{
get { return radius; }
}
/// <summary>
/// Constructs a new planet
/// <param name="mass">The planet's mass</param>
/// <param name="radius">The planet's radius</param>
public Planet(double mass, double radius)
{
this.mass = mass;
this.radius = radius;
}
}It describes a planet as having a mass and a radius. But a class does more than just labeling the properties and fields and providing methods to mutate the state they contain. It also specifies how memory needs to be allocated to hold those values as the program runs. In memory, we would need to hold both the mass and radius values. These are stored side-by-side, as a series of bits that are on or off. You probably remember from CIS 115 that a double is stored as a sign bit, mantissa and exponent. This is also the case here - a C# double requires 64 bits to hold these three parts, and we can represent it with a memory diagram:

We can create a specific planet by invoking its constructor, i.e.:
new Planet(1, 1);This allocates (sets aside) the memory to hold the planet, and populates the mass and radius with the supplied values. We can represent this with a memory diagram:

With memory diagrams, we typically write the values of variables in their human-readable form. Technically the values we are storing are in binary, and would each be 0000000000010000000000000000000000000000000000000000000000000001, so our overall object would be the bits: 00000000000100000000000000000000000000000000000000000000000000010000000000010000000000000000000000000000000000000000000000000001.
And this is exactly how it is stored in memory! The nice boxes we drew in our memory diagram are a tool for us to reason about the memory, not something that actually exists in memory. Instead, the compiler determines the starting point for each double by looking at the structure defined in our class, i.e. the first field defined is mass, so it will be the first 64 bits of the object in memory. The second field is radius, so it starts 65 bits into the object and consists of the next (and final) 64 bits.
If we assign the created Planet object to a variable, we allocate memory for that variable:
Planet earth = new Planet(1, 1);Unlike our double and other primitive values, this allocated memory holds a reference (a starting address of the memory where the object was allocated). We indicate this with a box and arrow connecting the variable and object in our memory diagram:
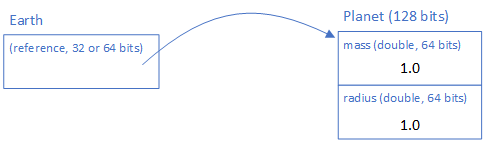
A reference is either 32 bits (on a computer with a 32-bit CPU) or 64 bits (on a computer with a 64-bit CPU), and essentially is an offset from the memory address $0$ indicating where the object will be located in memory (in the computer’s RAM). You’ll see this in far more detail in CIS 450 - Computer Architecture and Operations, but the important idea for now is the variable stores where the object is located in memory not the object’s data itself. This is also why if we define a class variable but don’t assign it an object, i.e.:
Planet mars;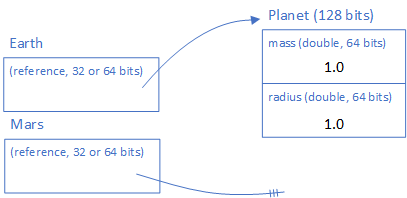
The value of this variable will be null. It’s because it doesn’t point anywhere!
Returning to our Earth example, earth is an instance of the class Planet. We can create other instances, i.e.
Planet mars = new Planet(0.107, 0.53);
We can even create a Planet instance to represent one of the exoplanets discovered by NASA’s TESS:
Planet hd21749b = new Planet(23.20, 2.836);
Let’s think more deeply about the idea of a class as a blueprint. A blueprint for what, exactly? For one thing, it serves to describe the state of the object, and helps us label that state. If we were to check our variable mars’ radius, we do so based on the property Radius defined in our class:
mars.RadiusThis would follow the mars reference to the Planet object it represents, and access the second group of 64 bits stored there, interpreting them as a double (basically it adds 64 to the reference address and then reads the next 64 bits)
Incidentally, this is why we start counting at 0 in computer science. The mass bits start at the start of our Planet object, referenced by mars i.e. if mars holds the reference address $5234$, then the bits of mass also begin at $5234$, or $5234+0$. And the radius bits start at $5234 + 64$.
State and memory are clearly related - the current state is what data is stored in memory. It is possible to take that memory’s current state, write it to persistent storage (like the hard drive), and then read it back out at a later point in time and restore the program to exactly the state we left it with. This is actually what Windows does when you put it into hibernation mode.
The process of writing out the state is known as serialization, and it’s a topic we’ll revisit later.
You might have wondered how the static modifier plays into objects. Essentially, the static keyword indicates the field or method it modifies exists in only one memory location. I.e. a static field references the same memory location for all objects that possess it. Hence, if we had a simple class like:
public class Simple {
public static int A;
public int B;
public Simple(int a, int b) {
this.A = a;
this.B = b;
}
}And created a couple of instances:
Simple first = new Simple(10, 12);
Simple second = new Simple(8, 5);The value of first.A would be 8 - because first.A and second.A reference the same memory location, and second.A was set after first.A. If we changed it again:
first.A = 3;Then both first.A and second.A would have the value 3, as they share the same memory. first.B would still be 12, and second.B would be 5.
Another way to think about static is that it means the field or method we are modifying belongs to the class and not the individual object. Hence, each object shares a static variable, because it belongs to their class. Used on a method, static indicates that the method belongs to the class definition, not the object instance. Hence, we must invoke it from the class, not an object instance: i.e. Math.Pow(), not Math m = new Math(); m.Pow();.
Finally, when used with a class, static indicates we can’t create objects from the class - the class definition exists on its own. Hence, the Math m = new Math(); is actually an error, as the Math class is declared static.
With our broader understanding of objects in memory, let’s re-examine something you’ve been working with already, how the values in that memory are initialized (set to their initial values). In C#, there are four primary ways a value is initialized:
This also happens to be the order in which these operations occur - i.e. the default value can be overridden by code in the constructor. Only after all of these steps are completed is the initialized object returned from the constructor.
This step is actually done for you - it is a feature of the C# language. Remember, allocated memory is simply a series of bits. Those bits have likely been used previously to represent something else, so they will already be set to 0s or 1s. Once you treat it as a variable, it will have a specific meaning. Consider this statement:
int foo;That statement allocates the space to hold the value of foo. But what is that value? In many older languages, it would be whatever is specified by how the bits were set previously - i.e. it could be any integer within the available range. And each time you ran the program, it would probably be a different value! This is why it is always a good idea to assign a value to a variable immediately after you declare it.
The creators of C# wanted to avoid this potential problem, so in C# any memory that is allocated by a variable declaration is also zeroed (all bits are set to 0). Exactly what this means depends on the variable’s type. Essentially, for numerics (integers, floating points, etc) the value would be 0, for booleans it would be false. And for reference types, the value would be null.
A second way a field’s value can be set is by assigning a default value after it is declared. Thus, if we have a private backing _count in our CardDeck class, we could set it to have a default value of 52:
public class CardDeck
{
private int _count = 52;
public int Count
{
get
{
return _count;
}
set
{
_count = value;
}
}
}This ensures that _count starts with a value of 52, instead of 0.
We can also set a default value when using auto-property syntax:
public class CardDeck
{
public int Count {get; set;} = 52;
}It is important to understand that the default value is assigned as the memory is allocated, which means the object doesn’t exist yet. Basically, we cannot use methods, fields, or properties of the class to set a default value. For example:
public class CardDeck
{
public int Count {get; set;} = 52;
public int PricePerCard {get;} = 5m / Count;
}Won’t compile, because we don’t have access to the Count property when setting the default for PricePerCard.
This brings us to the constructor, the standard way for an object-oriented program to initialize the state of the object as it is created. In C#, the constructor always has the same name as the class it constructs and has no return type. For example, if we defined a class Square, we might type:
public class Square {
public float length;
public Square(float length) {
this.length = length;
}
public float Area() {
return length * length;
}
}Note that unlike the regular method, Area(), our constructor Square() does not have a return type. In the constructor, we set the length field of the newly constructed object to the value supplied as the parameter length. Note too that we use the this keyword to distinguish between the field length and the parameter length. Since both have the same name, the C# compiler assumes we mean the parameter, unless we use this.length to indicate the field that belongs to this - i.e. this object.
A parameterless constructor is one that does not have any parameters. For example:
public class Ball {
private int x;
private int y;
public Ball() {
x = 50;
y = 10;
}
}Notice how no parameters are defined for Ball() - the parentheses are empty.
If we don’t provide a constructor for a class the C# compiler automatically creates a parameterless constructor for us, i.e. the class Bat:
public class Bat {
private bool wood = true;
}Can be created by invoking new Bat(), even though we did not define a constructor for the class. If we define any constructors, parameterless or otherwise, then the C# compiler will not create an automatic parameterless constructor.
Finally, C# introduces some special syntax for setting initial values after the constructor code has run, but before initialization is completed - Object initializers. For example, if we have a class representing a rectangle:
public class Rectangle
{
public int Width {get; set;}
public int Height {get; set;}
}We could initialize it with:
Rectangle r = new Rectangle() {
Width = 20,
Height = 10
};The resulting rectangle would have its width and height set to 20 and 10 respectively before it was assigned to the variable r.
In addition to the get and set accessor, C# has an init operator that works like the set operator but can only be used during object initialization.
The second criterion Alan Kay set for object-oriented languages was message passing. Message passing is a way to request that a unit of code engage in a behavior, i.e. changing its state, or sharing some aspect of its state.
Consider the real-world analogue of a letter sent via the postal service. Such a message consists of: an address the message needs to be sent to, a return address, the message itself (the letter), and any data that needs to accompany the letter (the enclosures). A specific letter might be a wedding invitation. The message includes the details of the wedding (the host, the location, the time), an enclosure might be a refrigerator magnet with these details duplicated. The recipient should (per custom) send a response to the host addressed to the return address letting them know if they will be attending.
In an object-oriented language, message passing primarily takes the form of methods. Let’s revisit our example Vector3 class:
public class Vector3 {
public double X {get; set;}
public double Y {get; set;}
public double Z {get; set;}
/// <summary>
/// Creates a new Vector3 object
/// </summary>
public Vector3(double x, double y, double z) {
this.X = x;
this.Y = y;
this.Z = z;
}
/// <summary>
/// Computes the dot product of this vector and another one
/// </summary>
/// <param name="other">The other vector</param>
public double DotProduct(Vector3 other) {
return this.X * other.X + this.Y * other.Y + this.Z * other.Z;
}
}And let’s use its DotProduct() method:
Vector3 a = new Vector3(1, 1, 2);
Vector3 b = new Vector3(4, 2, 1);
double c = a.DotProduct(b);Consider the invocation of a.DotProduct(b) above. The method name, DotProduct provides the details of what the message is intended to accomplish (the letter). Invoking it on a specific variable, i.e. a, tells us who the message is being sent to (the recipient address). The return type indicates what we need to send back to the recipient (the invoking code), and the parameters provide any data needed by the class to address the task (the enclosures).
Let’s define a new method for our Vector3 class that emphasizes the role message passing plays in mutating object state:
public class Vector3 {
public double X {get; set;}
public double Y {get; set;}
public double Z {get; set;}
/// <summary>
/// Creates a new Vector3 object
/// </summary>
public Vector3(double x, double y, double z) {
this.X = x;
this.Y = y;
this.Z = z;
}
public void Normalize() {
var magnitude = Math.Sqrt(Math.pow(this.X, 2) + Math.Pow(this.Y, 2) + Math.Pow(this.Z, 2));
this.X /= magnitude;
this.Y /= magnitude;
this.Z /= magnitude;
}
}We can now invoke the Normalize() method on a Vector3 to mutate its state, shortening the magnitude of the vector to length 1.
Vector3 f = new Vector3(9.0, 3.0, 2.0);
f.Normalize();Note how here, f is the object receiving the message Normalize. There is no additional data needed, so there are no parameters being passed in. Our earlier DotProduct() method took a second vector as its argument, and used that vector’s values to mutate its state.
Message passing therefore acts like those special molecular pumps and other gate mechanisms of a cell that control what crosses the cell wall. The methods defined on a class determine how outside code can interact with the object. An extra benefit of this approach is that a method becomes an abstraction for the behavior of the code, and the associated state changes it embodies. As a programmer using the method, we don’t need to know the exact implementation of that behavior - just what data we need to provide, and what it should return or how it will alter the program state. This makes it far easier to reason about our program, and also means we can change the internal details of a class (perhaps to make it run faster) without impacting the other aspects of the program.
This is also the reason we want to use getters and setters (or properties in C#) instead of public fields in an object-oriented language. Getters, setters, and C# properties are all methods, and therefore are a form of message passing, and they ensure that outside code is not modifying the state of the object (rather, the outside code is requesting the object to change its state). It is a fine distinction, but one that can be very important.
You probably have noticed that in many programming languages we speak of functions, but in C# and other object-oriented languages, we’ll often speak of methods. You might be wondering just what is the difference?
Both are forms of message passing, and share many of the same characteristics. Broadly speaking though, methods are functions defined as part of an object. Therefore, their bodies can access the state of the object. In fact, that’s what the this keyword in C# means - it refers to this object, i.e. the instance of the class that the method is currently executing for. For non-object-oriented languages, there is no concept of this (or self as it appears in some other languages).
In this chapter, we looked at how Object-Orientation adopted the concept of encapsulation to combine related state and behavior within a single unit of code, known as a class. We also discussed the three key features found in the implementation of classes and objects in Object-Oriented languages:
We explored how objects are instances of a class created through invoking a constructor method, and how each object has its own independent state but shares behavior definitions with other objects constructed from the same class. We discussed several different ways of looking at and reasoning about objects - as a state machine, and as structured data stored in memory. We saw how the constructor creates the memory to hold the object state and initializes its values. We saw how access modifiers and accessor methods can be used to limit and control access to the internal state of an object through message passing.
Finally, we explored how all of these concepts are implemented in the C# language.