Git and GitHub
Be a Better Version
Be a Better Version
Code version control is a staple of modern software development. So it’s a good idea to learn and practice it now, so it becomes a core element of your software development practice. This appendix covers one of the most popular distributed version control software in use today - Git. It also covers one of the most popular online platforms for hosting remote Git repositories - GitHub. (Hint: Despite the tendency for many programmers to use the names interchangeably, they aren’t the same thing!)
Over the next few sections we’ll take you through the basic concepts of how Git actually works, and then show you the most common workflows you’ll find yourself using with Git.
Some key terms to learn in this chapter are:
Have you ever been working on a paper for a class, and stopped every now and then to save it under a slightly different name, i.e. “Paper draft 1.docx”, “Paper draft 2.docx”, “Paper final draft.docx”, “Paper final draft with Merge suggestions.docx”, and so on?
Effectively what you were doing was version control - keeping old copies of a project around. This can be a lifesaver if your current file gets corrupted and becomes unusable. It can also be helpful to go back and see older versions, perhaps to see what a section looked like before your last set of changes. It might also be handy if that last major revision just isn’t working, and you want to go back to what the paper looked like before you started making changes.
Now think about programming projects, which involve multiple files. You could copy your project directory and rename it… but it’s a lot of effort, and also chews up memory on your computer. And have you ever found those multiple folders/files become difficult to navigate and sort through? Also, what happens if your entire computer gets trashed? Or stolen? Where are you with your multiple copies of files/directories then?
Version control software was invented to help solve these problems, along with one more pressing issue - working with others and sharing those code files between everyone on the team. No doubt you probably have or have heard some horror stories from CIS 115 or other courses were one member of the team accidentally overwrote the content that the rest of the team had painstakingly added to the group’s Wiki page…
Ideal version control software therefore:
Git is one of the many version control programs that has been developed to tackle these challenges, and is currently one of the most popular. In part, this is because it does a very good job at tackling each of those issues we just discussed. Of course, it can only do this if you are using it as it was intended to be used… so it’s a good idea to spend a bit of time learning those details (though, as the authors of xkcd suggest, many people don’t):

First, to use Git you need to install a program known as a Git client on your computer. Most people use the open-source command-line git client available from https://git-scm.com/downloads, but there are other clients that provide GUI experiences and the like. Here we’ll focus on the command-line version.
You can also learn more from the official Git Documentation or the free online Pro Git Book. These are great resources for expanding your Git knowledge, as this appendix is only going to hit the conceptual high points of Git and focus on the workflows you’ll be using for this class.
Git converts an ordinary directory (folder) on our computer into a git repository, allowing you to save different versions of the directory’s contents as you make changes to that directory. Invoking the git init command within the top directory of your project starts this process:
$ git init
The data describing these changes and how to switch to them is stored in a subdirectory the Git client creates in the top project directory named .git. This folder is normally hidden from the user on most operating systems, though you can reveal it by tweaking your OS settings. All the git commands modify the contents of that folder. This approach has one really great benefit - if you copy your project folder into a new location, your repository information goes with it!
If you’re curious about the structure of the .git folder, Pierre DeWulf has a good post discussing it on his blog. 1 Essentially, every time you commit (save your current changes), Git creates a new entry representing the state of your files at that point, including an identifying hash (to identify the commit), the previous (parent) commit’s hash, a comment describing the commit, the date and time of the commit, and the identity of the user making the commit. We can use this information to restore the project directory to any one of the commits we’ve made.
Because Git places all of its repository information in the .git folder, deleting it will make the directory no longer be a repository. All committed changes will be lost, and you will no longer be able to revert your project files to earlier versions.
Pierre DeWulf, “Understanding git for real by exploring the .git directory”, daolf.com, Mar 11, 2019. ↩︎
It is important to understand that Git doesn’t save the changes to every file in the directory when you create a commit - it only saves those files you have staged to be committed. This extra step often confuses new Git users, but it exists to give you full control over what gets committed into your repository.
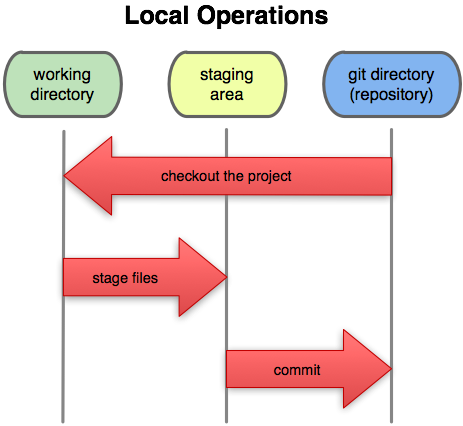
It may help to understand how Git thinks about files. Files in your repository directory fall into one of five categories - untracked, unstaged, staged, committed, and ignored.
Untracked files are those that have never been added to the repository. As far as the repository is concerned, they don’t exist. If you were to delete one, you cannot restore it, as the repository has no saved version of it. Mostly these are files that have recently been created.
Unstaged files are those that are tracked, but have at least some changes that have not been committed. These are either new files that have just been added to the repository’s index with a git add command, or files that have been altered since the last commit.
Staged files are those that will be included in the next commit. They are added to the list of staged files with the git add command, and will be committed with the git commit command.
Committed files are those whose current state has been saved as a commit. In other words, they are “safe” as they can be restored from that commit with a git checkout command.
Ignored files are those whose path matches the pattern in the .gitignore file. We’ll come back to this idea shortly.
You can check for the status of your files in the repository at any time with the git status command:
$ git status This will print the status of all uncommitted files:
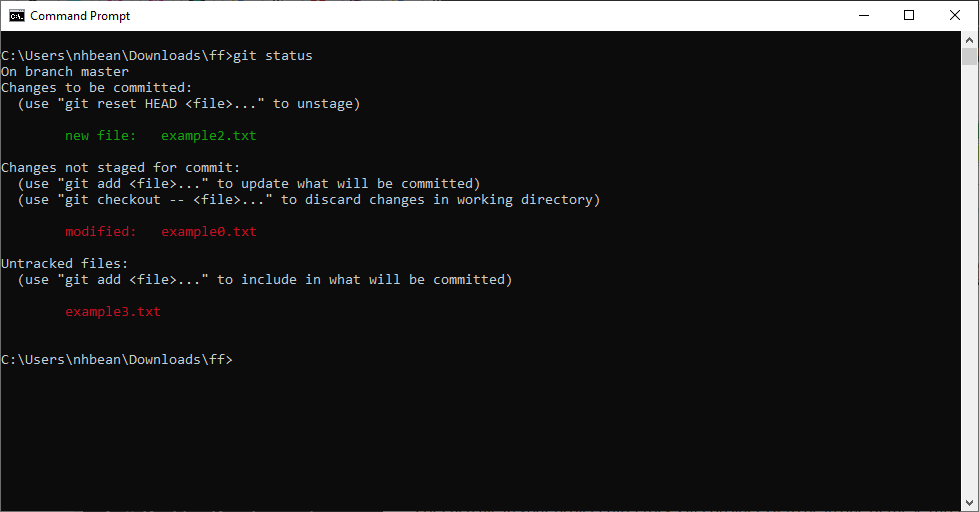
There are four files in the ff directory: example0.txt, example1.txt, example2.txt, and example3.txt. In the output above, we see:
$ git checkout -- example0.txt, or add this file to those staged with $ git add example0.txt.Interestingly, you can still change a staged file. If you do so, Git keeps track of the staged but not committed changes, and the new, unstaged modifications. For example, if we change example2.txt and run git status again, we’ll see:
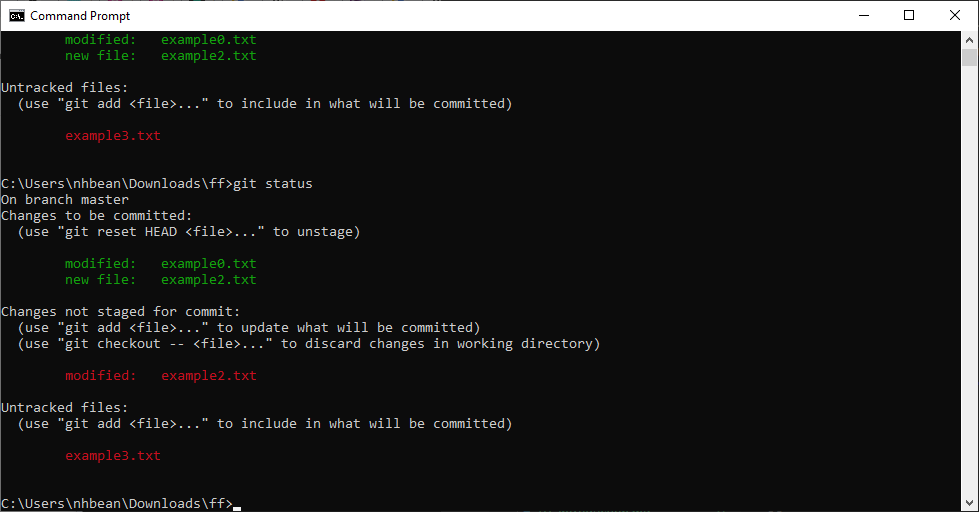
Notice example2.txt now has two statuses - corresponding to the staged and unstaged changes!
With this understanding in mind, the standard way of committing changes is to combine a git add command and a git commit command:
$ git add .
$ git commit -m "<a message about the commit>"The git add . adds all untracked and unstaged files (making them staged), and git commit commits our staged files.
Typically there are some files in a project that we never want to commit. For example, compilers often create temporary or intermediate files during the compilation process, and these will be recreated every time we re-compile. We also usually don’t want to commit the compiled binary files either, as we can always compile our code to get a fresh copy. Not saving these files means our repository takes up less memory, and Git operations are faster.
And if our project involves some configuration files with sensitive information (passwords, shared secrets, etc), we don’t want to commit these to our repository either - especially if it will be publicly visible on GitHub.
We can specify the patterns of files Git should ignore with a special text file named .gitignore. Inside that file, we specify file path patterns. Any file matching one of these patterns is effectively ignored by Git. However, if we have already committed a file to the repository, and then added our .gitignore file, the committed file remains in the repository. For this reason, we always want to add our .gitignore as we create the repository.
While it is technically possible to completely remove a file accidentally committed to a Git repository, the process is not easy to complete correctly, and a mistake often means the file is still accessible to a skilled adversary. In those situations, it may be best to delete the .git folder and create a new repository.
GitHub provides a helpful repository of .gitignore files for specific programming languages and platforms. An easy trick is to find the one for the language you are interested in, open it in its raw form, and copy/paste its text into your .gitignore file. For this class, you’ll want to use the Visual Studio .gitignore.
As we suggested earlier in the chapter, one of the most important uses of a version control system is to allow you to revert to an earlier version of your code. To ask Git to list the available commits, you can use the git log command:
$ git logThis should print a list of the commits and their details, with the newest commit first:
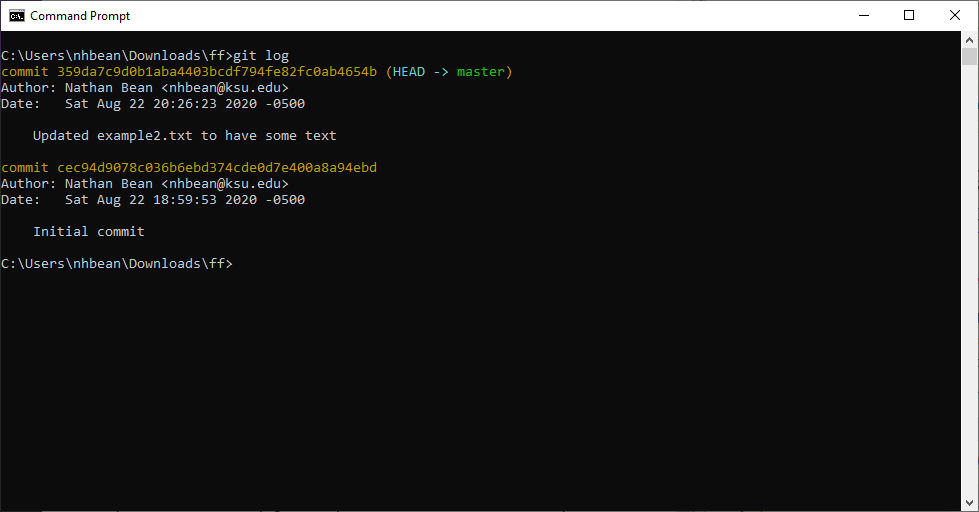
Notice each commit is identified by a hash, date, and commit message. This is why a good commit message is important - it helps to let us know what we changed (and therefore what changes we would be undoing if we reverted to that commit). If we wanted to revert to an earlier version, we would use the git checkout command:
$ git checkout [hash]Where [hash] is the hash of the commit, i.e. cec94d9078c036b6ebd374cde0d7e400a8a94ebd for the initial commit in the example.
This reverts your files to that point, and reports you are in a ‘detached HEAD’ state, i.e. the commit loaded is not the latest one on this branch. Carlos Schults has an excellent post describing this condition. If you want to start working from this point (leaving your later changes out), best practice is to create a new branch to hold this commit. We’ll look at branches next.
Branches are a powerful mechanisms for working on different versions of your code. The name “branch” is derived from visualizing a repository as a tree structure, with each commit being a node in the tree. For a simple repository, this tree structure is pretty boring - just a straight line as each node has only one child:

This default branch was historically named “master”, though recent practice has shifted to using the term “main”. GitHub provides guidance and support for renaming existing project branches.
At any node in the commit tree, we could create a new branching point with the command git branch [branchname] where we supply the branch name. The branch starts with exactly the same code as the current commit to main (or whatever branch we are branching from). Then we can check out the branch with git checkout [branchname], using the name we supplied. Let’s create and check out a branch named “experiment” in our above example:
$ git branch experiment
$ git checkout experimentWe now have a new branch, experiment, branching from commit 573ed9f:

While “experiment” is the checked out branch, any commits we make are placed on it instead of the main branch. Let’s assume we create two commits on the experiment branch; our tree will now look like:

We can switch back to the main branch at any point with git checkout main. When we do so, our code will be reverted back to how it was in the last commit to the main branch (commit 573ed9f). If it turns out our experiment was a flop, we can forget about the experiment branch and the changes we made to it - we’re back to a clean working build at the point before we started the experiment.
It is important to understand how commits and branches interact. When you check out a branch, the code in the repository is reverted to the last commit on that branch. And any new commits you make are saved to the currently checked out branch.
If you have uncommitted or staged changes in files, git will refuse to check out a branch until these are committed or stashed, as checking out the branch will overwrite those changes and they would be lost forever. In contrast, unstaged and ignored files are fine (as there is no committed version that will overwrite the file). Best practice is to commit your changes before switching branches, unless you want to throw the changes away.
If, on the other hand, we like the changes from the experiment, and want to add them to the main branch, we can merge those changes with the git merge [branchname] command:
$ git merge experimentThis merges the specified branch with the currently checked-out branch. Git accomplishes merging through a recursive strategy, which works very well. However, if both branches have had changes committed since the last shared commit, there is a possibility that some of those changes will overlap, and Git will not be able to determine which to use. This is called a merge conflict and must be resolved by you. See the merge conflict section later for more details.
There are a number of reasons we might want to create a branch; let’s examine some common use cases.
Prototype branches - Let’s say we wanted to try making some changes to our code that we aren’t sure will work - basically, we are creating an experimental prototype. If this experiment doesn’t end up succeeding, we would like to return to our current version of the project. This is exactly the scenario we walked through above.
Feature branches - Let’s assume you have a working program you need to add a new feature to, but you still want to be able to access the working code. In this case, you can create a branch to work on that feature. That way, when your feature is only partially done, you can still switch back to your main branch and fix a bug, etc., without needing to remove or comment out your half-written feature code.
Personal branches - Let’s say you’re working with a team. You want to make sure that the main branch is always clean, ready-to-go code, and you don’t want to have to deal with your teammate’s half-written code (nor they with yours). Each team member can create their own branch to do their work on, and when it is tested and ready, merge that code into the main branch.
Each of these approaches can (and usually is) used in conjunction with remote repositories. We’ll take a look at that next.
Git bills itself as a distributed version control system. This means it has no central server. Instead, we can create copies of the repository we call remote repositories with the git clone command. These copies can be placed anywhere - in another directory on your computer, or on a different computer on your network, or a computer accessed via the internet.
GitHub is a web service that specifically hosts remote git repositories and allows you to access them through both your git client and through a web (HTML/CSS/JS) interface. It was created primarily to provide a place to host publicly-accessible, open-source projects, though you can also use it to create private repositories. It is not the only such service available; BitBucket is a similar website more focused on closed-source projects, and the popular GitLab is an open-source server for hosting Git projects you can install on your own systems. The Computer Science department at Kansas State University runs its own GitLab server to host projects developed as part of our research and extension mission.
At this point in your learning, you will likely be using a repository hosted on GitHub (usually created by GitHub classroom when you accept an assignment) as a remote repository you are cloning to one or more local repositories. For example, you’ll likely clone your project on both your home computer and a lab computer so you can work in both locations.
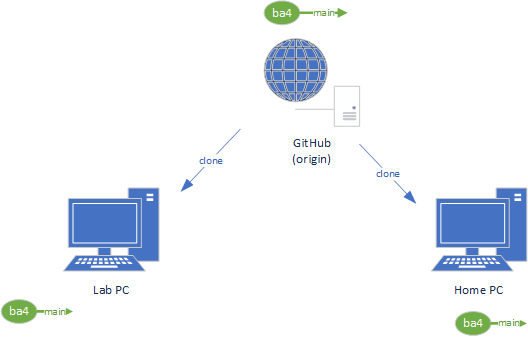
A clone is a copy of the project in its current state, including the hidden .git folder. This means it is also a complete git repository! The code will be in the same state as that of the currently active branch of the repo it was cloned from (for a project cloned from GitHub, this would be the main/master branch).
While the cloned repository is a copy of an existing repository, it will not contain unstaged or ignored files or directories, as these are not tracked by Git.
Thus, in our diagram above, the home, lab, and GitHub copies of our repository all start exactly the same, with commit ba4. But if we make and commit changes to one of those repositories, that repository will be ahead of the other repositories, which will not have that commit. We can see this in the diagram below, where we have added commit a4e to the repository on our Lab PC:
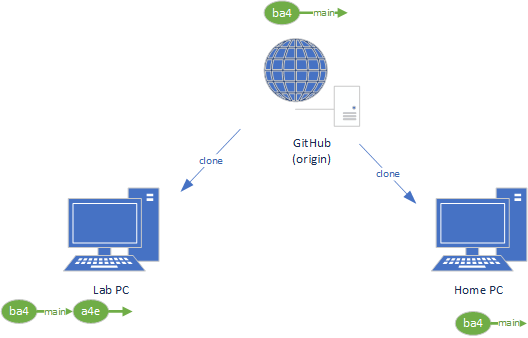
To get this same commit on our other remote repositories, we’ll use push and pull commands.
We can push commits from one repository to another one with a git push command. To use this command, we need to know the location of the remote repository, and what branch we want to push our changes to. When we clone an existing repository, Git automatically saves the location of that repository and gives it the name origin. Thus, we can copy our commit a4e from our Lab PC repository to GitHub with the git push command:
$ git push origin mainThis pushes our new commit to the GitHub repository, so it now also has that commit:
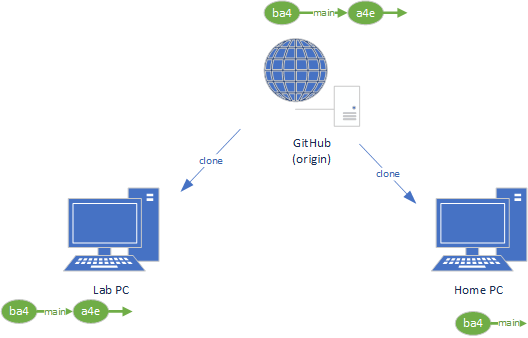
Because GitHub does not have a reference to our Home PC’s repository, we can’t push the commit there. Instead, we’ll need to pull it directly from our home computer.
As the repository on our home PC is also a clone of the GitHub repository, it kept track of the location of it using the name origin as well. So we can pull commits from that location (GitHub) using the git pull command:
$ git pull origin mainThis copies any commits on the GitHub repository into the Home PC repository:
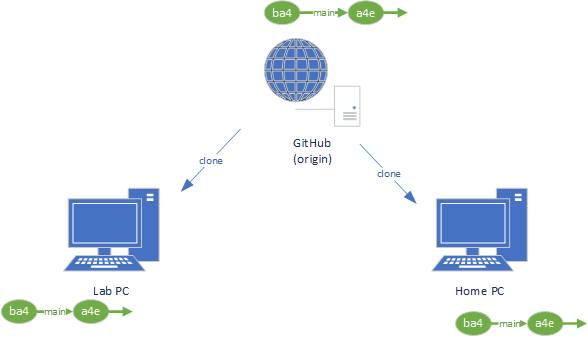
If you push or pull changes to a repository that has extra commits, Git merges the extra commits with the pushed ones (as with the merge command). This can introduce the possibility of merge conflicts when Git is uncertain how to best combine two changes. These must be resolved by you as described in the merge conflict section. For this reason, it is always best practice to pull changes into your local branch, fix any merge conflicts, create a new commit, and only then push it to the remote repository. This ensures that the main branch code is always in good shape.
You can actually set up as many remote repositories as you want. In the diagram above, it would be possible to push or pull from the Lab PC to the Home PC directly, provided you had a publicly accessible URL for both (as we normally don’t have static IP addresses for home networks, this is unlikely). You can add an additional remote repository with git remote add [name] [url].
This can be helpful if you have a project you’ve started on your home machine and want to push to GitHub. Create an empty project on GitHub (it must be completely empty, so don’t create a default readme or license file). Then copy the clone URL and use it in your local Git command:
git remote add origin [remote url]where [remote url] is the GitHub clone url. After you’ve done this, you can push your project to GitHub normally.
You can also list all remote repositories in a repo with:
git remote -vYou probably noticed in our push and pull examples above, we specified the main branch. You can also pull or push from other branches, i.e. if you had an experiment branch on your remote repository origin you could pull it with:
git pull origin experimentThat would merge the experiment branch into the branch you currently have checked out.
Most often, we want to have our remote and local branches correspond to one another. In that case, we can first fetch all remote changes (without merging them into our local repository), which will also fetch any new remote branches. Then, we can create a new local branch that is synchronized to a new remote upstream branch. For example, suppose there is an experiment branch in our remote repository and we wish to create a new local experiment branch to track it. We can do:
git fetch
git checkout -b experiment origin/experimentAfter these commands, we have created the new local experiment branch which is currently synchronized with the remote experiment branch, and have checked out that new branch. As we make changes, we can use the git push and git pull shorthands, which will push and pull between the local experiment and remote experiment branches.
This section summarizes the git commands you will need when creating feature branches for your semester-long project.
When you start a new milestone, you need to create a local branch to hold your work. For example, if you wanted to create a feature branch for Milestone 0, you would do:
$ git branch ms0Next, check out your new branch. For our Milestone 0, we would do:
$ git checkout ms0As you make progress on the current milestone, it is a good idea to add your changes to the remote repository. First, make sure you are on your milestone branch by doing:
$ git branchYou will see a list of all local branches, with a * next to the currently checked out branch. You should see that the branch for the current milestone has a *. Then, add, commit, and push the changes for your branch to the remote repository:
$ git add .
$ git commit -m "description of changes"
$ git pushThe first time you do this, it will automatically create a remote branch with the same name.
Depending on your git configuration, you may get this error when you git push or git pull on a local branch that has no remote counterpart:
fatal: The current branch <branchName> has no upstream branch.
To push the current branch and set the remote as upstream, use
git push --set-upstream origin <branchName>
To have this happen automatically for branches without a tracking
upstream, see 'push.autoSetupRemote' in 'git help config'.If you get this error, you can update your git configuration as follows:
git config --global push.autoSetupRemote trueAt that point you should be able to use git push or git pull and have it go automatically to/from the corresponding remote branch.
(If you still have errors, you will first need to update your version of git to get a version that is at least 2.37 – you can check the version number with git --version.)
Suppose you followed the steps above to start a milestone on your home computer (including pushing the latest changes for your milestone branch) and wanted to continue working on a lab computer.
If this was your FIRST time working on this repository on the new computer, you would need to clone the repository to the new local machine. You can do this with Visual Studio’s File->Clone Repository or from the terminal with git clone [repoURL].
If you have already cloned this repository to your current local computer but have not yet created a branch on this computer for the current milestone, you can use the git checkout option to both create a new local branch with the same name as a remote branch and switch to that new branch:
$ git checkout -b ms0 origin/ms0Replacing ms0 with the current milestone branch.
If you have previously worked with the current milestone branch on your local computer, you need to first checkout that branch:
$ git checkout ms0Again, replacing ms0 with the current milestone branch. Then, pull the latest changes for that branch from the remote repository to the local repository. If you do:
$ git pull origin ms0It will fetch updates from the remote ms0 branch and merge them into the local ms0 branch.
Finally, when you have finished the milestone, you’ll want to merge your new changes from the feature branch into the main branch:
$ git checkout main
$ git merge ms0(Again, replacing ms0 with the current milestone branch name). Next, push the newly expanded main branch to GitHub:
$ git push origin mainAfter that, you’ll need to create a release to turn in.
When git merges commits from two different branches or remote repositories, it applies the committed changes from both. In many cases, this works seamlessly, but sometimes it results in merge conflicts. A conflict occurs when the same line(s) in a file were changed in both branches, and git is unsure of which to use.
Git will do several things in this scenario:
It will report as output from that command that caused the conflict which file(s) in the repository contain conflicts, and
It will mark the conflicted sections of those files using a special format that shows the two versions of the code.
An example of such a marking is:
public void PrintSomething() {
<<<<<<< HEAD
if(testValue) {
=======
if(otherTestValue) {
>>>>>>> some_branch
Console.log("Something...");
}Here, we see two conflicting versions of one line: if(testValue) { and if(otherTestValue){. Additionally, we see markers delimiting the conflicting sections: <<<<<<< HEAD, =======, and >>>>>>> some_branch. We need to replace all of the code and delimiters with one final version of the code. This could be the first option, the second option, or a combination of the two:
public void PrintSomething() {
if(testValue && otherTestValue) {
Console.log("Something...");
}We need to do this for all conflicts in all conflicting files. Once they have all been resolved, we need to commit the changes with the commands:
$ git add .
$ git commit -m "Fixed merge conflicts"When you are ready to turn in an assignment, you will need to create a release tag. A tag is nothing more than a specially named commit, and a release is a special tag created on GitHub to mark a specific version of the software.
Since releases are created on GitHub, it is important to make sure you’ve committed your changes and have pushed them to GitHub before you create the release. You can check that all changes have been committed and pushed with the command:
$ git statusIf you see these messages:
Your branch is up to date with 'origin/main'.
nothing to commit, working tree cleanThen you are good to go. On the other hand, if you get the message Your branch is # commits ahead of 'origin/main', then you need to push to master, and if any files are listed as uncommitted, you first need to commit them.
Next, open your repository on Github. Towards the right side of the page you should see a link labeled “Create a new release”. Click it.
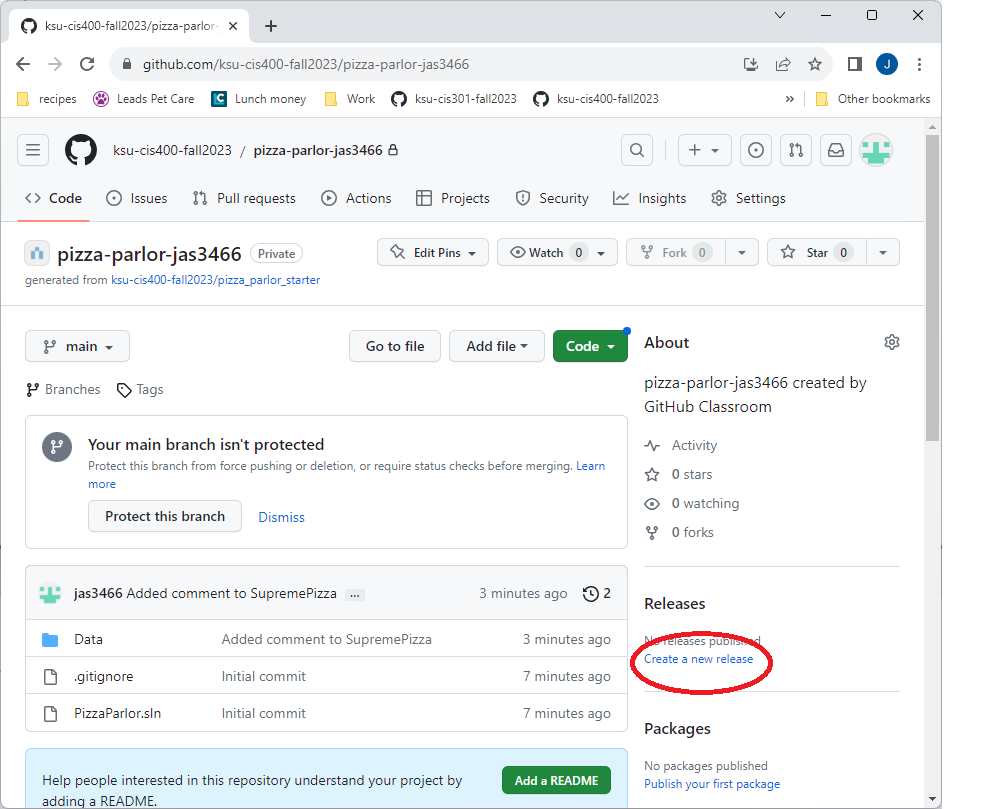
This will load the releases page for your repository.
You will need to fill out the release form, specifically the version and title, and then click the “Publish Release” button.
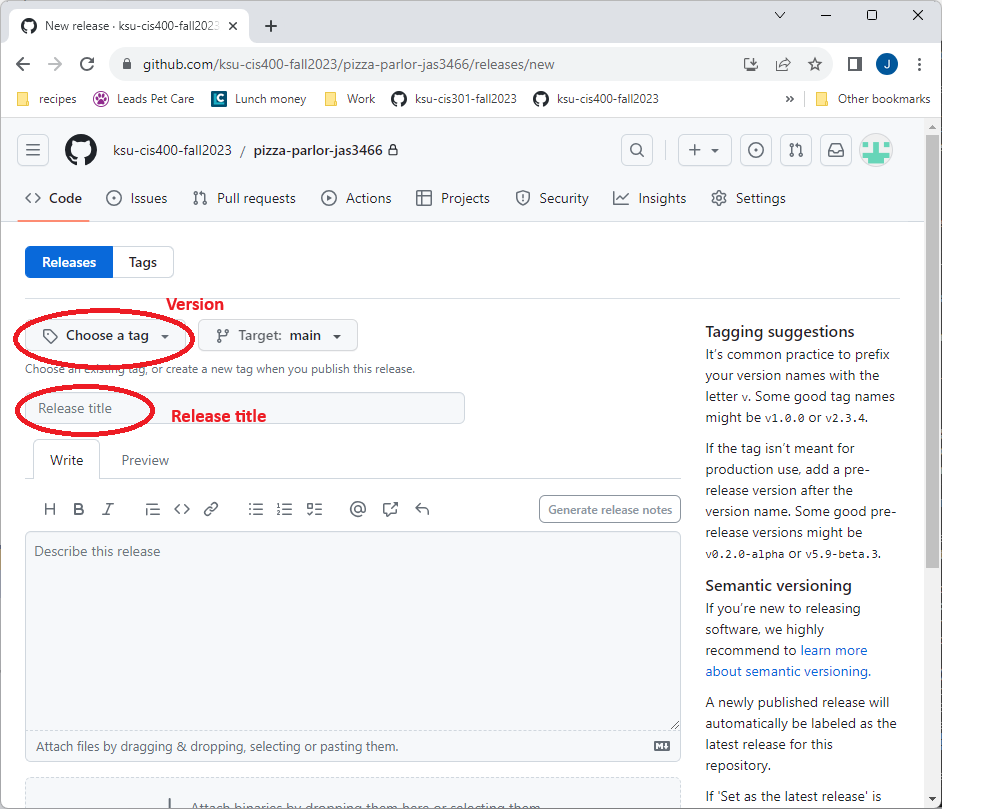
Releases use semantic versioning, a numbering system that uses three numbers separated by periods (i.e. version 3.4.2). The first number is the major version - a change in this number indicates a major change in the associated software, i.e. a redesigned interface, a change in what methods are available, etc. The second number is the minor version. It indicates small feature additions to the software. Finally, the third number is the patch version, and this one indicates a change that is typically a bug fix or security fix. Each number rolls over like the seconds and minutes on a clock when the next version number is increased, i.e. you would go from version 2.7.23 to 3.0.0, or 4.3.12 to 4.4.0. For this project, each milestone should be treated as a minor release, and each new project as a major one.
Releases also get a human-readable name. For this class, you should use the assignment name as the release name, i.e. Milestone 0.
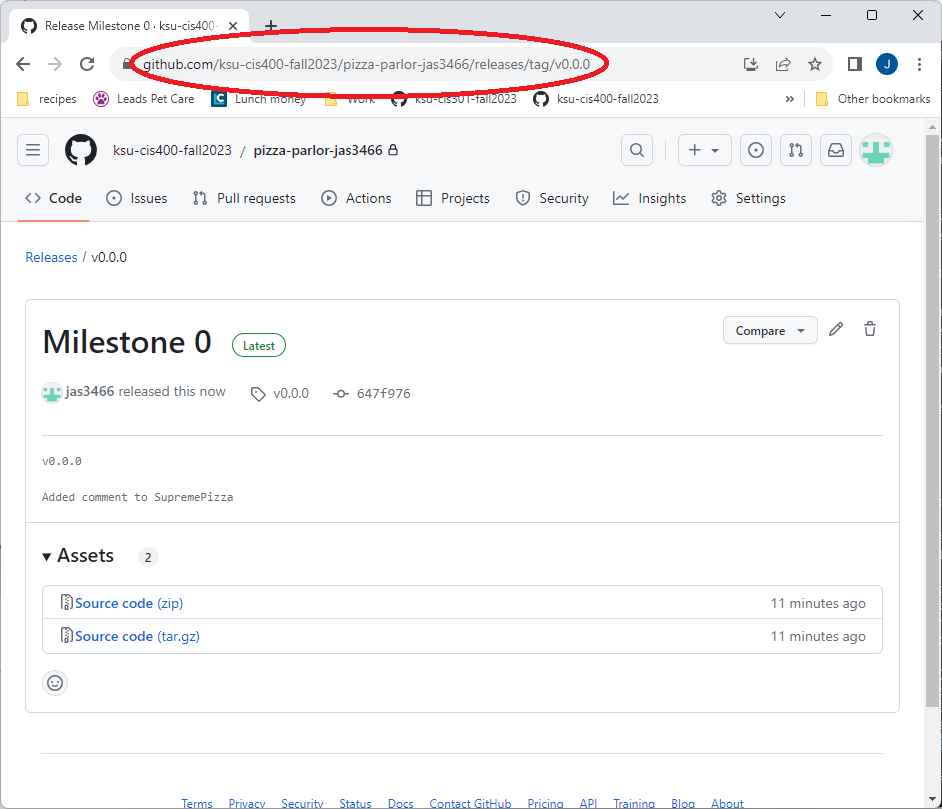
Once you have finished creating the release, GitHub should take you to the release page. You can also navigate there by clicking the specific release under the “Releases” heading on the right-hand side of your repository landing page. Copy the URL of this page; it is what you will submit on Canvas.
When adding existing documentation files (i.e. UML documents) to your project, you may think adding them through Visual Studio’s Solution Explorer would be the way to go. However, this can lead to an unexpected issue. Look closely at the example below:
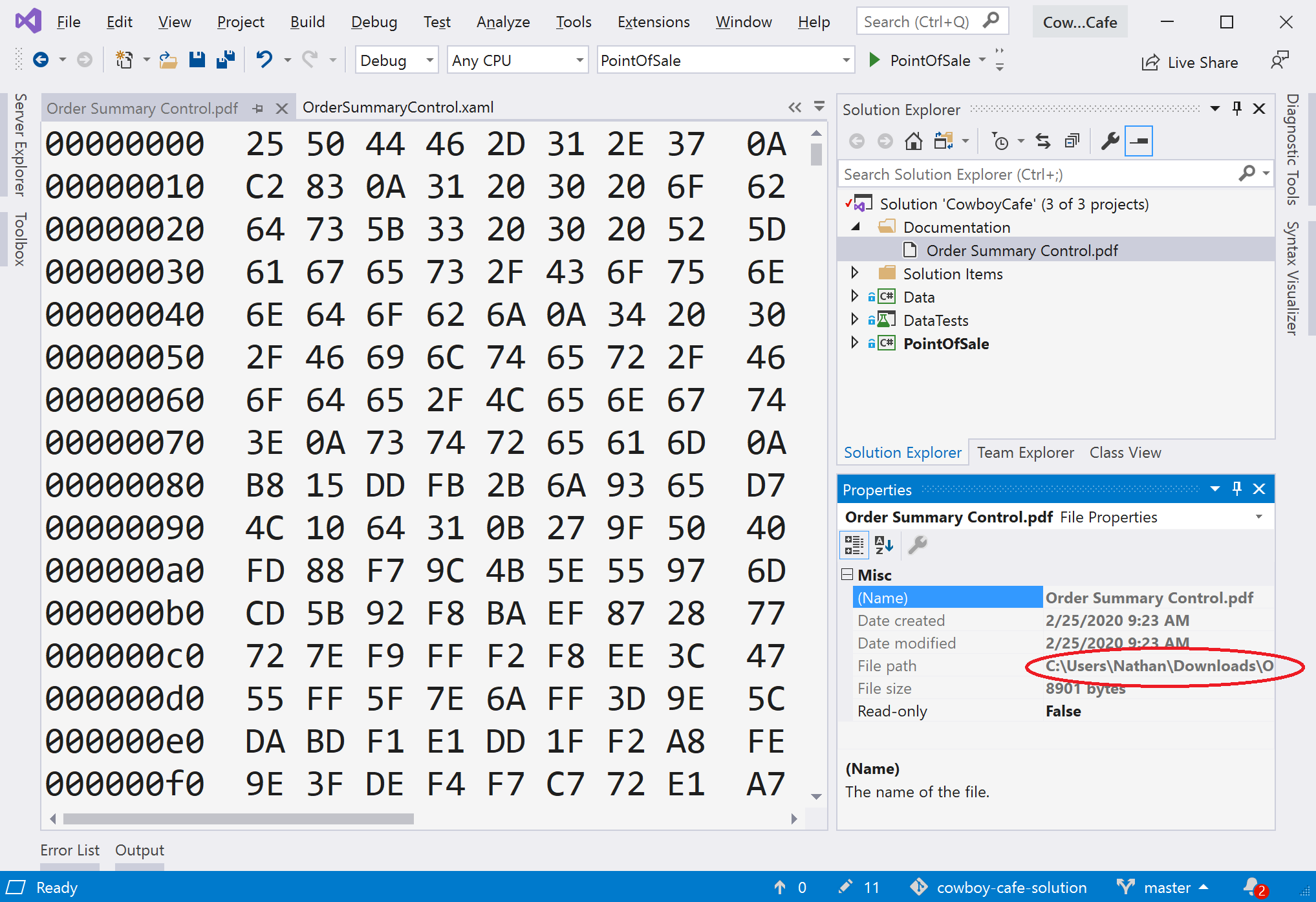
We can see the PDF has been added to the solution file in the Solution Explorer, and we can see its raw data open in the editing pane. But take a close look at the Properties. The file is located in the Downloads folder! Since the file is not present in a folder managed by Git, IT WILL NOT BE COMMITTED!
The ONLY way to get Git to track a file is to PUT IT INTO A DIRECTORY TRACKED BY GIT. Visual Studio’s Solution Explorer does NOT copy existing PDF files, it simply creates a virtual representation of the file within the solution that points to where that file exists on your filesystem.
To summarize, you must move or copy the file you want to share into the solution directory using your operating system’s file system, NOT VISUAL STUDIO. Visual Studio typically places your projects in the directory C:/Users/%username%/source/repos/%solutionname%/ where %username% is your Windows username and %solutionname% is your solution’s name. If you asked Visual Studio to save your files in another location, you need to look there.
However, there is a quick way to open the exact solution folder from within Visual Studio. Right-click the solution in the Solution Explorer and choose Open Folder in File Explorer from the context menu:
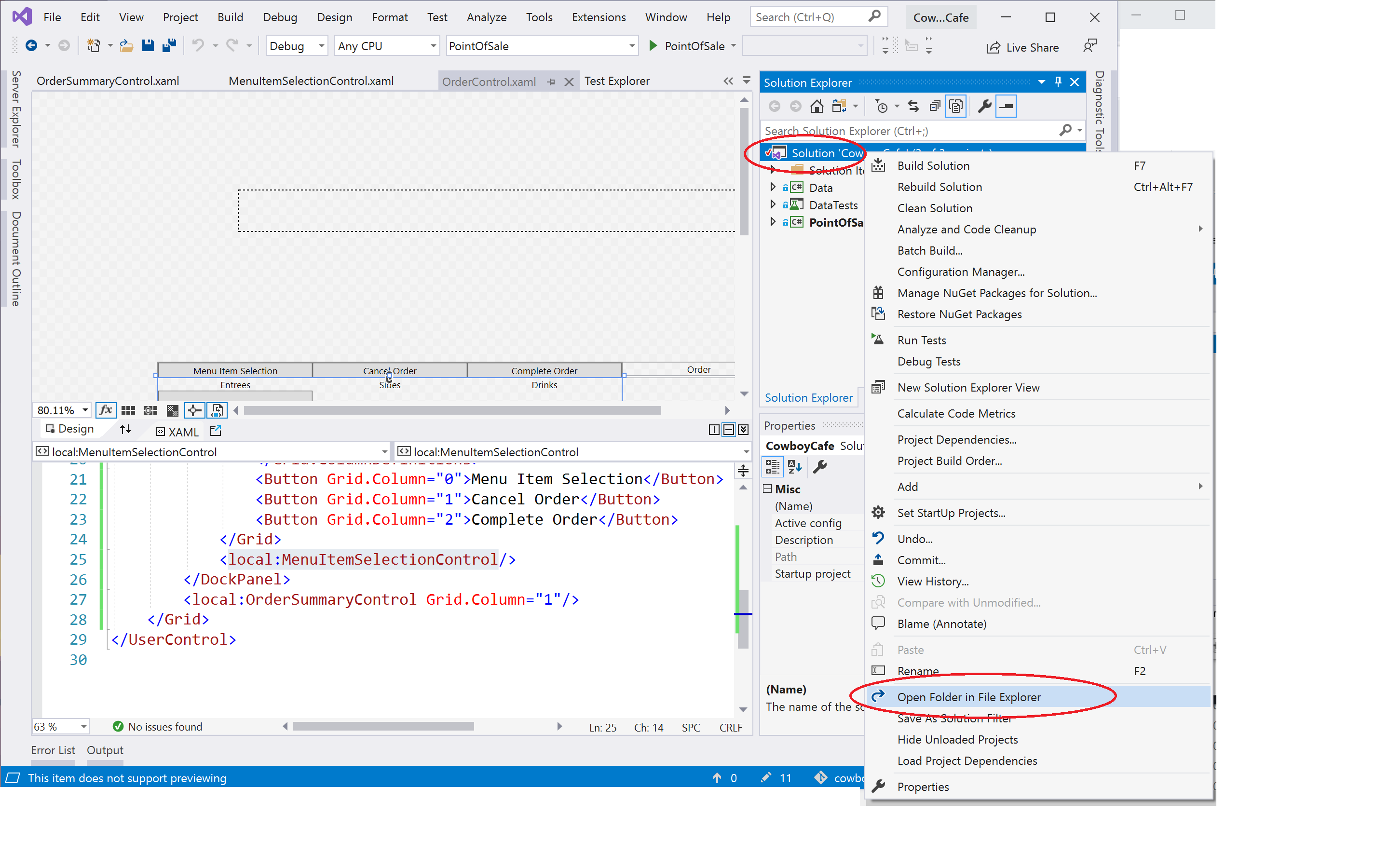
Then you can use File Explorer to create your Documentation folder and place your documents:
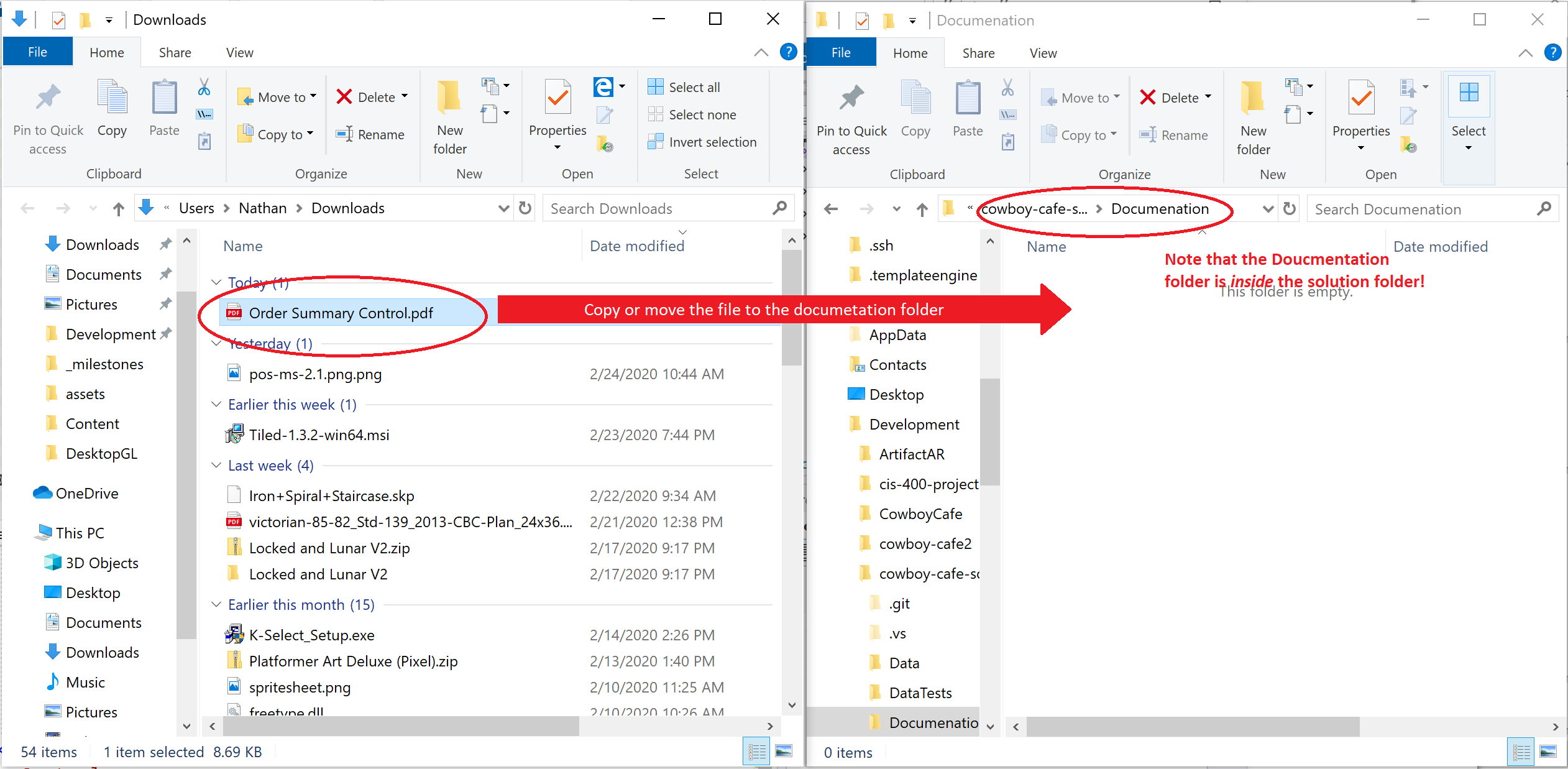
Once the document is in place, you will need to commit your changes and push them to GitHub