Hyper-Text Transfer Protocol
Etiquette for Web Servers and Clients
Etiquette for Web Servers and Clients
At the heart of the world wide web is the Hyper-Text Transfer Protocol (HTTP). This is a protocol defining how HTTP servers (which host web pages) interact with HTTP clients (which display web pages).
It starts with a request initiated from the web browser (the client). This request is sent over the Internet using the TCP protocol to a web server. Once the web server receives the request, it must decide the appropriate response - ideally sending the requested resource back to the browser to be displayed. The following diagram displays this typical request-response pattern.
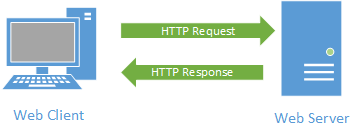
This HTTP request-response pattern is at the core of how all web applications communicate. Even those that use websockets begin with an HTTP request.
The HTTP standard, along with many other web technologies, is maintained by the World-Wide-Web Consortium (abbreviated W3C), stakeholders who create and maintain web standards. The full description of the Hyper-Text Transfer Protocol can be found here w3c’s protocols page.
Before we get too deep in the details of what a request is, and how it works, let’s explore the primary kind of request you’re already used to making - requests originating from a browser. Every time you use a browser to browse the Internet, you are creating a series of HTTP (or HTTPS) requests that travel across the networks between you and a web server, which responds to your requests.
To help illustrate how these requests are made, we’ll once again turn to our developer tools. Open the example page this link. On that tab, open your developer tools with CTRL + SHIFT + i or by right-clicking the page and selecting “Inspect” from the context menu. Then choose the “Network” tab:
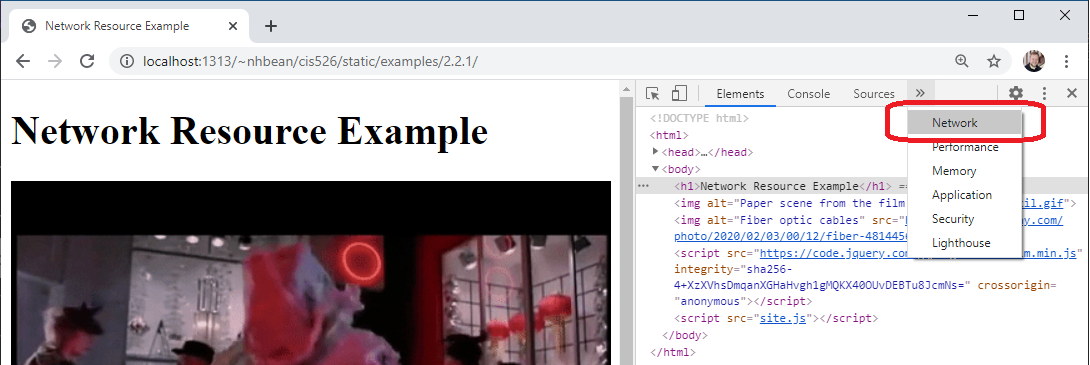
The network tab displays details about each request the browser makes. Initially it will probably be empty, as it does not log requests while not open. Try refreshing the page - you should see it populate with information:
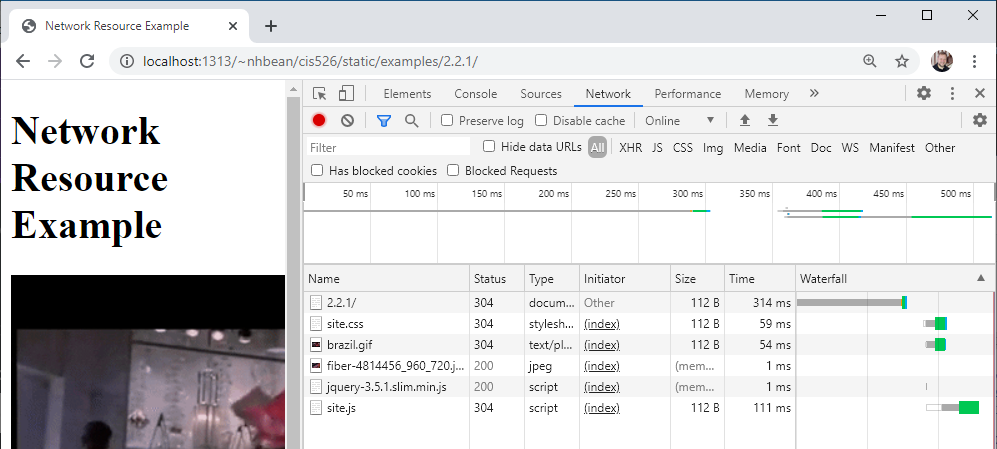
The first entry is the page itself - the HTML file. But then you should see entries for site.css, brazil.gif, fiber-4814456_960_720.jpg, jquery-3.5.1.slim.min.js, and site.js. Each of these entries represents an additional resource the browser fetched from the web in order to display the page.
Take, for example, the two images brazil.gif and fiber-4814456_960_720.jpg. These correspond to <img> tags in the HTML file:
<img alt="Paper scene from the film Brazil" src="brazil.gif"/>
<img alt="Fiber optic cables" src="https://cdn.pixabay.com/photo/2020/02/03/00/12/fiber-4814456_960_720.jpg"/>
The important takeaway here is that the image is requested separately from the HTML file. As the browser reads the page and encounters the <img> tag, it makes an additional request for the resource supplied in its src attribute. When that second request finishes, the downloaded image is added to the web page.
Notice too that while one image was on our webserver, the other is retrieved from Pixabay.com’s server.
Similarly, we have two JavaScript files:
<script src="https://code.jquery.com/jquery-3.5.1.slim.min.js" integrity="sha256-4+XzXVhsDmqanXGHaHvgh1gMQKX40OUvDEBTu8JcmNs=" crossorigin="anonymous"></script>
<script src="site.js"></script>As with the images, one is hosted on our website, site.js, and one is hosted on another server, jquery.com.
Both the Pixabay image and the jQuery library are hosted by a Content Delivery Network- a network of proxy servers that are distributed geographically in such a way that a request for a resource they hold can be processed from a nearby server. Remember that the theoretical maximum speed for internet transmissions is the speed of light (for fiber optics) or electrons in copper wiring. Communication is further slowed at each network switch encountered. Serving files from a nearby server can prove very efficient at speeding up page loads because of the shorter distance and smaller number of switches involved.
A second benefit of using a CDN to request the JQuery library is that if the browser has previously downloaded the library when visiting another site it will have cached it. Using the cached version instead of making a new request is much faster. Your app will benefit by faster page loads that use less bandwidth.
Notice too that the jQuery <script> element also uses the integrity attribute to allow the browser to determine if the library downloaded was tampered with by comparing cryptographic tokens. This is an application of Subresource Integrity, a feature that helps protect your users. As JavaScript can transform the DOM, there are incentives for malicious agents to supplant real libraries with fakes that abuse this power. As a web developer you should be aware of this, and use all the tools at your disposal to keep your users safe.
You can use the network tab to help debug issues with resources. Click on one of the requested resources, and it will open up details about the request:
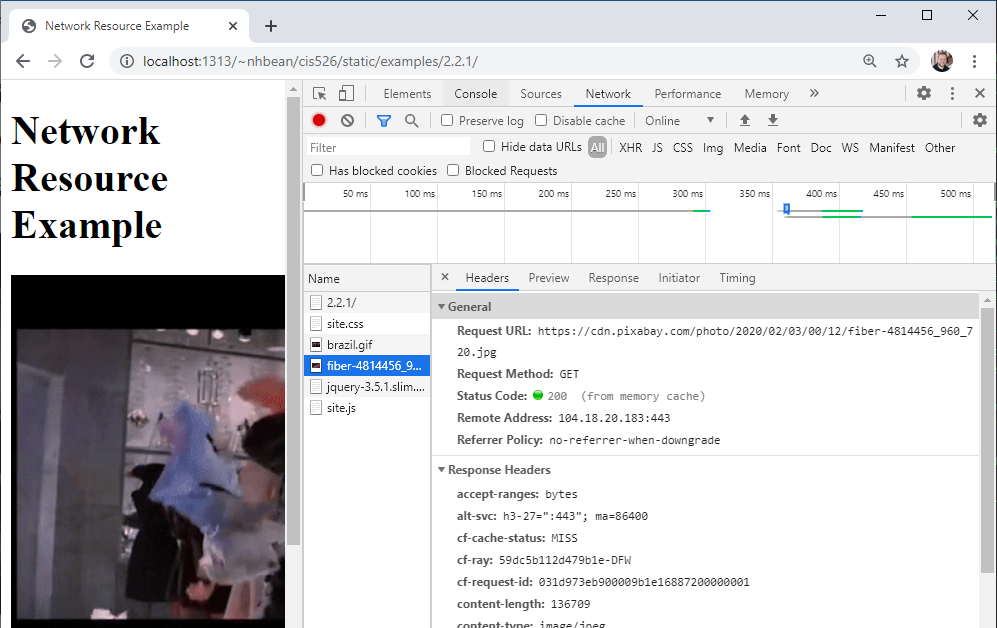
Notice that it reports the status code along with details about the request and response, and provides a preview of the requested resource. We’ll cover what these all are over the remainder of this chapter. As you learn about each topic, you may want to revisit the tab with the example to see how these details correspond to what you are learning.
So now that we’ve seen HTTP Requests in action, let’s examine what they are. A HTTP Request is just a stream of text that follows a specific format and sent from a client to a server.
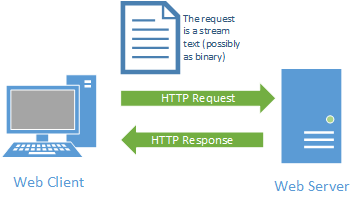
It consists of one or more lines terminated by a CRLF (a carriage return and a line feed character, typically written \r\n in most programming languages).
The request-line follows the format
Request-Line = Method SP Request-URI SP HTTP-Version CRLF
The Method refers to the HTTP Request Method (often GET or POST).
SP refers to the space character.
The Request-URI is a Universal Request Indicator, and is typically a URL or can be the asterisk character (*), which refers to the server instead of a specific resource.
HTTP-Version refers to the version of the HTTP protocol that will be used for the request. Currently three versions of the protocol exist: HTTP/1.0, HTTP/1.1, and HTTP/2.0. Most websites currently use HTTP/1.1 (HTTP/2.0 introduces many changes to make HTTP more efficient, at the cost of human readability. Currently it is primarily used by high-traffic websites).
Finally, the CRLF indicates a carriage return followed by a line feed.
For example, if we were requesting the about.html page of a server, the request-line string would be:
GET /about.html HTTP/1.1\r\n
Header lines consist of key-value pairs, typically in the form
Header = Key: Value CRLF
Headers provide details about the request, for example, if we wanted to specify we can handle the about.html page data compressed with the gzip algorithm, we would add the header:
Accept-Encoding: compress, gzip\r\n
The server would then know it could send us a zipped version of the file, resulting in less data being sent from the server to the client.
If our request includes a body (often form data or a file upload), we need to specify what that upload data is with a Content-Type header and its size with a Content-Length header, i.e.:
Content-Length: 26012 Content-Type: image/gif
The header section is followed by a blank line (a CRLF with no characters before it). This helps separate the request metadata from the request body.
The body of the request can be text (as is the case for most forms) or binary data (as in an image upload). This is why the Content-Type header is so important for requests with a body; it lets the server know how to process the data. Similarly, the Content-Length header lets us know how many bytes to expect the body to consist of.
It is also acceptable to have no body - this is commonly the case with a GET request. If there is no body, then there are also no required headers. A simple get request can therefore consist of only the request-line and blank line, i.e.:
GET /about.html HTTP/1.1\r\n\r\n
The HTTP/1.1 request definition can be found in W3C RFC 2616 Section 5
The first line of the HTTP request includes the request method, which indicates what kind of action the request is making of the web server (these methods are also known as HTTP Verbs). The two most common are GET and POST, as these are supported by most browsers.
The following requests are those most commonly used in web development. As noted before GET and POST requests are the most commonly used by web browsers, while GET, PUT, PATCH, and DELETE are used by RESTful APIs. Finally, HEAD can be used to optimize web communications by minimizing unnecessary data transfers.
A GET request seeks to retrieve a specific resource from the web server - often an HTML document or binary file. GET requests typically have no body and are simply used to retrieve data. If the request is successful, the response will typically provide the requested resource in its body.
A HEAD request is similar to a GET request, except the response is not expected to provide a body. This can be used to verify the type of content of the resource, the size of the resource, or other metadata provided in the response header, without downloading the full data of the resource.
The POST request submits an entity to the resource, i.e. uploading a file or form data. It typically will have a body, which is the upload or form.
The PUT request is similar to a POST request, in that it submits an entity as its body. It has a more strict semantic meaning though; a PUT request is intended to replace the specified resource in its entirety.
The PATCH request is also similar to POST and PUT requests - it submits an entity as its body. However, its semantic meaning is to only apply partial modifications to the specified entity.
As you might expect, the DELETE method is used to delete the specified resource from the server.
Additional methods include CONNECT, which establishes a tunnel to a server; OPTIONS, which identifies communications options with a resource, and TRACE, which performs a message loop-back test to the target resource. HTTP Methods are defined in W3C’s RFC2616.
Before a web request can be made, the browser needs to know where the resource requested can be found. This is the role that a Universal Resource Locator (a URL) plays. A URL is a specific kind of Universal Resource Indicator (URI) that specifies how a specific resource can be retrieved.
URLs and URIs The terms URL and URI are often used interchangeably in practice. However, a URL is a specific subset of URIs that indicate how to retrieve a resource over a network; while a URI identifies a unique resource, it does not necessarily indicate how to retrieve it. For example, a book’s ISBN can be represented as a URI in the form urn:isbn:0130224189. But this URI cannot be put into a browser’s Location to retrieve the associated book.
A URI consists of several parts, according to the definition (elements in brackets are optional):
URI = scheme:[//[userinfo@]host[:port]]path[?query][#fragment]
Let’s break this down into individual parts:
scheme: The scheme refers to the resource is identified and (potentially) accessed. For web development, the primary schemes we deal with are http (hyper-text transfer protocol), https (secure hyper-text transfer protocol), and file (indicating a file opened from the local computer).
userinfo: The userinfo is used to identify a specific user. It consists of a username optionally followed by a colon (:) and password. We will discuss its use in the section on HTTP authentication, but note that this approach is rarely used today, and carries potential security risks.
host: The host consists of either a fully quantified domain name (i.e. google.com, cs.ksu.edu, or gdc.ksu.edu) or an ip address (i.e. 172.217.1.142 or [2607:f8b0:4004:803::200e]). IPv4 addresses must be separated by periods, and IPv6 addresses must be closed in brackets. Additionally, web developers will often use the loopback host, localhost, which refers to the local machine rather than a location on the network.
port: The port refers to the port number on the host machine. If it is not specified (which is typical), the default port for the scheme is assumed: port 80 for HTTP, and port 443 for HTTPS.
path: The path refers to the path to the desired resource on the server. It consists of segments separated by forward slashes (/).
query: The query consists of optional collection of key-value pairs (expressed as key:value), separated by ampersands (&), and preceded by a question mark (?). The query string is used to supply modifiers to the requested resource (for example, applying a filter or searching for a term).
fragment: The fragment is an optional string proceeded by a hashtag (#). It identifies a portion of the resource to retrieve. It is most often used to auto-scroll to a section of an HTML document, and also for navigation in some single-page web applications.
Thus, the URL https://google.com indicates we want to use the secure HTTP scheme to access the server at google.com using its port 443. This should retrieve Google’s main page.
Similarly, the url https://google.com/search?q=HTML will open a Google search result page for the term HTML (Google uses the key q to identify search terms).
Request headers take the form of key-value pairs, separated by colons : and terminated with a CRLF (a carriage return and line feed character). For example:
Accept-Encoding: gzipIndicates that the browser knows how to accept content compressed in the Gzip format.
Note that request headers are a subset of message headers that apply specifically to requests. There are also message headers that apply only to HTTP responses, and some that apply to both.
As HTTP is intended as an extensible protocol, there are a lot of potential headers. IANA maintains the official list of message headers as well as a list of proposed message headers. You can also find a categorized list in the MDN Documentation
While there are many possible request headers, some of the more commonly used are:
Accept Specifies the types a server can send back, its value is a MIME type.
Accept-Charset Specifies the character set a browser understands.
Accept-Encoding Informs the server about encoding algorithms the client can process (most typically compression types)
Accept-Language Hints to the server what language content should be sent in.
Authorization Supplies credentials to authenticate the user to the server. Will be covered in the authentication chapter.
Content-Length The length of the request body sent, in octets
Content-Type The MIME type of the request body
Content-Encoding The encoding method of the request body
Cookie Sends a site cookie - see the section on cookies later
User-Agent A string identifying the agent making the request (typically a browser name and version)
After the request headers and an extra CRLF (carriage return and line feed) is the request body.
For GET and DELETE requests, there is no body. For POST, PUT, and PATCH, however, this section should contain the data being sent to the server. If there is a body, the headers should include Content-Type and Content-Length. The Content-Length is always provided as a count of octets (a set of eight bits). Thus, binary data is sent as an octet stream. Text data is typically sent in UTF-8 encoding.
Two body formats bear special mention: application/x-www-form-urlencoded and multipart/form-data. These encodings are commonly used for submitting HTML forms, and will be covered in more detail in the Form Data chapter.
Similar to an HTTP Request, an HTTP response is typically a stream of text and possibly data:
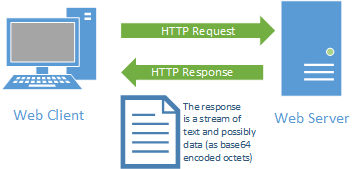
It consists of one or more lines of text, terminated by a CRLF (sequential carriage return and line feed characters):
The status-line follows the format
Status-Line = HTTP-Version SP Status-Code SP Reason-Phrase CRLF
The HTTP-Version indicates the version of the HTTP protocol that is being used (HTTP/1.0, HTTP/1.1, or HTTP/2.0).
SP refers to a space character.
The Status-Code is a three-digit numeric representation of the response status. Common codes include 200 (OK), 404 (Not Found), and 500 (Server Error).
The Reason-Phrase is a plain-text explanation of the status code.
Just like HTTP Requests, a HTTP response can contain headers describing the response. If the response has a body, a Content-Type and Content-Length header would be expected.
The header section is followed by a blank line (a CRLF with no characters before it). This helps separate the response metadata from the response body.
The response body contains the data of the response. it might be text (as is typically the case with HTML, CSS, or JavaScript), or a binary file (an image, video, or executable). Additionally, it might only be a sequence of bytes, as is the case for streaming media.
The full HTTP/1.1 response definition can be found in W3C RFC 2616 Section 6.
The status-line consists of a numeric code, followed by a space, and then a human-readable status message that goes with the code. The codes themselves are 3-digit numbers, with the first number indicating a general category the response status falls into. Essentially, the status code indicates that the request is being fulfilled, or the reason it cannot be.
Codes falling in the 100’s provide some kind of information, often in response to a HEAD or upgrade request. See the MDN Documentation for a full list.
Codes in the 200’s indicate success in some form. These include:
200 OK A status of 200 indicates the request was successful. This is by far the most common response.
201 Created Issued in response to a successful POST request, indicates the resource POSTed to the server has been created.
202 Accepted Indicates the request was received but not yet acted upon. This is used for batch-style processes. An example you may be familiar with is submitting a DARS report request - the DARS server, upon receiving one, adds it to a list of reports to process and then sends a 202 response indicating it was added to the list, and should be available at some future point.
There are additional 200 status codes. See the MDN Documentation for a full list.
Codes in the 300’s indicate redirects. These should be used in conjunction with a Location response header to notify the user-agent where to redirect. The three most common are:
301 Moved Permanently Indicates the requested resource is now permanently available at a different URI. The new URI should be provided in the response, and the user-agent may want to update bookmarks and caches.
302 Found Also redirects the user to a different URI, but this redirect should be considered temporary and the original URI used for further requests.
304 Not Modified Indicates the requested resource has not changed, and therefore the user-agent can use its cached version. By sending a 304, the server does not need to send a potentially large resource and consume unnecessary bandwidth.
There are additional 300 status codes. See the MDN Documentation for a full list.
Codes in the 400’s indicate client errors. These center around badly formatted requests and authentication status.
400 Bad Request is a request that is poorly formatted and cannot be understood.
401 Unauthorized means the user has not been authenticated, and needs to log in.
403 Forbidden means the user does not have permissions to access the requested resource.
404 Not Found means the requested resource is not found on the server.
There are many additional 400 status codes. See the MDN Documentation for a full list.
Status codes in the 500’s indicate server errors.
500 Server Error is a generic code for “something went wrong in the server.”
501 Not Implemented indicates the server does not know how to handle the request method.
503 Service Unavailable indicates the server is not able to handle the request at the moment due to being down, overloaded, or some other temporary condition.
There are additional 500 status codes. See the MDN Documentation for a full list.
Response headers take the form of key-value pairs, separated by colons : and terminated with a CRLF (a carriage return and line feed character), just like Request Headers (both are types of Message Headers). For example, this header:
Expires: Wed, 12 Jun 2019 08:00:00 CSTindicates to the browser that this content will expire June 12, 2019 at 8AM Central Standard Time. The browser can use this value when populating its cache, allowing it to use the cached version until the expiration time, reducing the need to make requests.
Note that response headers are a subset of message headers that apply specifically to requests. As we’ve seen there are also message headers that apply only to HTTP requests, and some that apply to both.
As HTTP is intended as an extensible protocol, there are a lot of potential headers. IANA maintains the official list of message headers as well as a list of proposed message headers. You can also find a categorized list in the MDN Documentation
While there are many possible response headers, some of the more commonly used are:
Allow Lists the HTTP Methods that can be used with the server
Content-Length The length of the response body sent, in octets
Content-Type The MIME type of the response body
Content-Encoding The encoding method of the response body
Location Used in conjunction with redirects (a 301 or 302 status code) to indicate where the user-agent should be redirected to.
Server Contains information about the server handling the request.
Set-Cookie Sets a cookie for this server on the client. The client will send back the cookie on subsequent requests using the Cookie header.
We’ll make use of these headers as we start writing web servers.
After the response headers and an extra CRLF (carriage return and line feed) is the response body.
The body is typically text (for HTML, CSS, JavaScript, and other text files) or binary data (for images, video, and other file types).
Setting the Content-Type and Content-Length headers lets the web client know what kind of data, and how much of it, should be expected. If these headers are not supplied in the response, the browser may treat the body as a blob of binary data, and only offer to save it.
You may have noticed that the earlier parts of this chapter focused on HTTP version 1.1, while mentioning version 2.0. You might wonder why we didn’t instead look at version 2.0 - and it’s a valid question.
In short, HTTP 2.0 was created to make the request-response pattern of the web more efficient. One method it uses to do so is switching from text-based representations of requests and responses to binary-based representations. As you probably remember from working with File I/O, binary files are much smaller than the equivalent text file. The same is true of HTTP requests and responses. But the structure of HTTP 2.0 Requests and Responses are identical to HTTP 1.1 - they are simply binary (an hence, harder to read).
But this is not the only improvement in HTTP 2.0. Consider the request-response pattern we discussed earlier in the chapter:
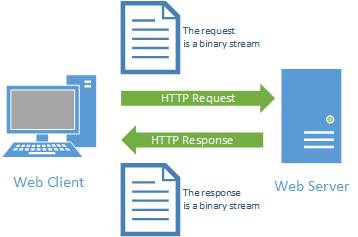
To display a webpage, the browser must first request the page’s HTML data. As it processes the returned HTML, it will likely encounter HTML <img>, <link>, and <src> tags that refer to other resources on the server. To get these resources, it will need to make additional requests. For a modern webpage, this can add up quickly! Consider a page with 20 images, 3 CSS files, and 2 JavaScript files. That’s 25 separate requests!
One of the big improvements between HTTP/1.0 and HTTP/1.1 was that HTTP/1.1 does not close its connection to the server immediately - it leaves a channel open for a few seconds. This allows it to request these additional files without needing to re-open the connection between the browser and the server.
HTTP/2.0 takes this thought a step farther, by trying to anticipate the browser’s additional requests. In the HTTP/2.0 protocol, when a browser requests an HTML page, the server can push the additional, linked files as part of the response. Thus, the entire page content can be retrieved with a single request instead of multiple, separate requests. This minimizes network traffic, allowing the server to handle more requests, and speeds up the process of rendering pages on a client’s machine.
One final point to make about Hyper-Text Transfer Protocol. It is a stateless protocol. What this means is that the server does not need to keep track of previous requests - each request is treated as though it was the first time a request has been made.
This approach is important for several reasons. One, if a server must keep track of previous requests, the amount of memory required would grow quickly, especially for popular web sites. We could very quickly grow past the memory capacity of the server hardware, causing the webserver to crash.
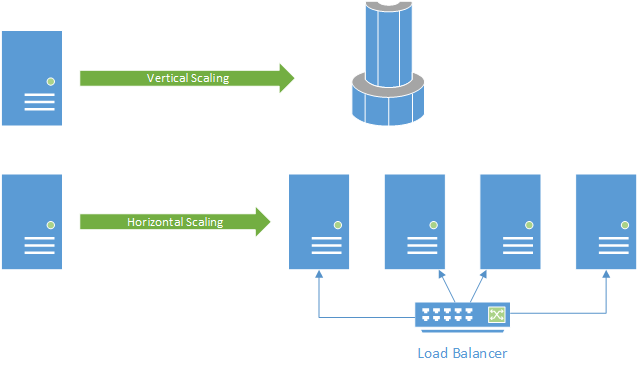
A second important reason is how we scale web applications to handle more visitors. We can do vertical scaling - increasing the power of the server hardware - or horizontal scaling - adding additional servers to handle incoming requests. Not surprisingly, the second option is the most cost-effective. But for it to work, requests need to be handed quickly to the first available server - there is no room for making sure a subsequent request is routed to the same server.
Thus, HTTP was designed as a stateless protocol, in that each new HTTP request is treated as being completely independent from all previous requests from the same client. This means that when using horizontal scaling, if the first request from client BOB is processed by server NANCY, and the second request from BOB is processed by server MARGE, there is no need for MARGE to know how NANCY responded. This stateless property was critical to making the world-wide-web even possible with the earliest internet technologies.
Of course, you probably have experience with websites that do seem to keep track of state - i.e. online stores, Canvas, etc. One of the challenges of the modern web was building state on top of a stateless protocol; we’ll discuss the strategies used to do so in later chapters.
In this chapter, we explored the Hyper-Text Transfer Protocol (HTTP), the technology used to exchange data across the web. We saw how requests and responses are simply well-structured streams of text or data exchanged across a packet-switched network. We examined the structure of these requests, and saw how they all use a similar pattern of a request or response line, a series of headers carrying metadata about the request or response, and an optional body.
We also discussed HTTP request methods like GET and POST, and HTTP response codes like a 404 and what these terms mean. We explored how HTTP has evolved from HTTP 1.0 to 1.1 to 2.0. And we discussed how HTTP is a stateless protocol, and how that statelessness is key to making websites that can serve thousands if not millions of users.
We’ll continue to reference the content of this chapter as we move forward, as HTTP is one of the core web technologies along with HTML, CSS, and JavaScript.