Asynchronous JavaScript
Parallel Processing Made Easy
Parallel Processing Made Easy
JavaScript makes extensive use of asynchronous processing to tackle the challenge of concurrency. This includes the events we’ve already talked about (user events, network events and timers), but it has also been expanded to provide even more powerful features. The XMLHTTPRequest object allows JavaScript to request additional resources directly in an asynchronous manner, and the more recent Fetch API updates that approach. Web workers allow parallel JavaScript processes to be run in the browser. And new ES6 syntax and constructs like Promises and the async/await keywords make asynchronous functions easier to reason about and use. In this chapter, we will explore each of these topics.
Concurrency means “doing more than one thing at the same time.” In computer science, concurrency can refer to (1) structuring a program or algorithm so that it can be executed out-of-order or in partial order, or (2) actually executing computations in parallel. In modern-day programming, we’re often talking about both. But to help us develop a stronger understanding, let’s look at the two ideas one-at-a-time, and then bring it together.
One of the earliest concurrency problems computer science dealt with was the efficient use of early computers. Consider a mainframe computer like the PDP-1, once a staple of the university computer science department. In 1963, the base price of a PDP-1 was $120,000. Adjusted for inflation, this would be a price of a bit more than one million dollars in 2020! That’s a pretty big investment! Any institution, be it a university, a corporation, or a government agency that spent that kind of money would want to use their new computer as efficiently as possible.
Consider when you are working on a math assignment and using a calculator. You probably read your problem carefully, write out an equation on paper, and then type a few calculations into your calculator, and copy the results to your paper. You might write a few lines as you progress through solving the problem, then punch a new calculation into your calculator. Between computations, your calculator is sitting idle - not doing anything. Mainframe computers worked much the same way - you loaded a program, it ran, and spat out results. Until you loaded a new program, the mainframe would be idle.
An early solution was the use of batch processing, where programs were prepared ahead of time on punch-card machines or the like, and turned over to an IT department team that would then feed these programs into the computer. In this way, the IT staff could keep the computer working as long as there was batched work to do. While this approach kept the computer busy, it was not ideal for the programmers. Consider the calculator example - it would be as if you had to write out your calculations and give them to another person to enter into the calculator. And they might not get you your results for days!
Can you imagine trying to write a program that way? In the early days that was exactly how CS students wrote programs - they would write an entire program on punch cards, turn it in to the computer staff to be batched, and get the results once it had been run. If they made a mistake, it would require another full round of typing cards, turning them in, and waiting for results!
Batch processing is still used for some kinds of systems - such as the generation of your DARS report at K-State, for sending email campaigns, and for running jobs on Beocat and other supercomputers. However, in mainframe operations it quickly was displaced by time sharing.
Time-sharing is an approach that has much in common with its real-estate equivalent that shares its name. In real estate, a time-share is a vacation property that is owned by multiple people, who take turns using it. In a mainframe computer system, a time sharing approach likewise means that multiple people share a single computer. In this approach, terminals (a monitor and keyboard) are hooked up to the mainframe. But there is one important difference between time-sharing real estate and computers, which is why we can call this approach concurrent.
Let’s return to the example of the calculator. In the moments between your typing an expression and reading the results, another student could type in their expression, and get their results. A time-sharing mainframe does exactly that - it take a few fractions of a second to advance each users’ program, switching between different users at lightning speed. Consider a newspaper where twenty people might we writing stories at a given moment - each terminal would capture key presses, and send them to the mainframe when it gave its attention, which would update the text editor, and send the resulting screen data back to the terminal. To the individual users, it would appear the computer was only working with them. But in actuality it was updating all twenty text editor program instances in real-time (at least to human perception).
Like batch processing, time-sharing is still used in computing today. If you’ve used the thin clients in the DUE 1114 lab, these are the current-day equivalents of those early terminals. They’re basically a video card, monitor, and input device that are hooked up to a server that runs multiple VMs (virtual machines), one for each client, and switches between them constantly updating each.
The microcomputer revolution did not do away with the concept. Rather, modern operating systems still use the basic concept of the approach, though in the context of a single computer it is known as multitasking. When you write a paper now, your operating system is switching between processes in much the same way that time-sharing switched between users. It will switch to your text editor, processing your last keystroke and updating the text on screen. Then it will shift to your music player and stream the next few thousand bytes of the song you’re listening to the sound card. Then it will switch to your email program which checks the email server and it will start to notify you that a new email has come in. Then it will switch back to your text editor.
The thin clients in DUE 1114 (as well as the remote desktops) are therefore both time-sharing between VMs and multitasking within VMs.
The second approach to concurrency involves using multiple computers in parallel. K-State’s Beocat is a good example of this - a supercomputer built of a lot of individual computers. But your laptop or desktop likely is as well; if you have a multi-core CPU, you actually have multiple processors built into your CPU, and each can run separate computational processes. This, it is entirely possible that as you are writing your term paper the text editor is running on one processor, your email application is using a second one, and your music is running on a third.
In fact, modern operating systems use both multitasking and parallel processing in tandem, spreading out the work to do across however many cores are available, and swapping between active processes to on those cores. Some programs also organize their own computation to run on multiple processors - your text editor might actually be handling your input on one core, running a spellcheck on a second, and a grammar check on a third.
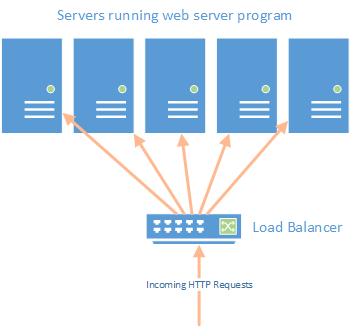
Remember our earlier discussion about scaling web servers? This is also a parallel processing approach. Incoming HTTP requests are directed by a load balancer to a less-busy server, and that server formulates the response.
Individual programs can also be written to execute on multiple cores. We typically call this approach Multithreading, and the individually executing portions of the program code threads.
These aren’t the only ways to approach concurrency, but they are ones we commonly see in practice. Before we turn our attention to how asynchronous processes fit in though, we’ll want to discuss some of the challenges that concurrency brings.
Implementing concurrency in computing systems comes with some specific challenges. Consider the multitasking approach where we have your text editor and your music player running at the same time. As the text editor process yields to the music player, the data and program elements it had loaded up into working memory, needs to be cleared out and replaced with the music player’s data and program. However, the music player’s data and program need to be retained somewhere so that they can be swapped back in when the music player yields.
Modern operating systems handle this challenge by dividing working memory amongst all programs running (which is why the more programs you run, the more RAM you consume). Each running process is assigned a block of memory and only allowed to use that memory. Moreover, data copied into the CPU (the L2 cache, L1 cache, and registers) may also be cached in memory for later restoration. You’ll learn more about the details of this process if you take an Operating Systems course. But it is very important that each running program is only allowed to make changes in its own assigned memory space. If it wasn’t, it could overwrite the data of another task!
In fact, an OS allowing a running program to overwrite another program’s assigned memory is a security vulnerability, as this can involve overwriting part of the other program, changing how it actually works! Viruses, trojans, and worms are often written to exploit this kind of vulnerability.
While operating systems normally manage the challenges of concurrency between running programs, when the program itself is written to be concurrent, the program itself must be built to avoid accidentally overwriting its own memory in unexpected ways. Consider a text editor - it might have its main thread handling user input, and a second thread handling spell checking. Now the user has typed “A quick brow”, and the spell checker is finding that “brow” is misspelled. It might try to underline the line in red, but in the intervening time, the user has deleted “brow”, so the underlining is no longer valid!
Or consider image data. Applying a filter to an image is a computationally costly operation - typically requiring visiting each pixel in the image, and for some filters, visiting each pixel around each pixel as part of the transformation. This would be a good use-case for multi-threading. But now imagine two filters working in parallel. One might be applying a blur, and the other a grayscale transformation. If they were overwriting the old image data with their new filtered version, and were working at the same time, they might both start from the original pixels in the upper-right-hand corner. The blur would take longer, as it needs to visit neighboring pixels. So the grayscale filter writes out the first hundred pixels, and then the blur writes out its first hundred, over-writing the grayed pixels with blurred color pixels. Eventually, the grayscale filter will get so far ahead of the blur filter that the blur filter will be reading in now-greyed out pixels, and blurring them. The result could well be a mishmash of blurred color and gray-and-white splotches.
There are many different approaches that can be used to manage this challenge. One is the use of locks - locking a section of memory so only one thread can access it while it makes changes. In the filter example, the grayscale filter could lock the image data, forcing the blur filter to wait until it finishes. Locks work well, but must be carefully designed to avoid race conditions - where two threads cannot move forward because the other thread has already locked a resource the blocked thread needs to finish its work.
Asynchronous programming is another potential solution, which we’ll look at next.
In asynchronous programming, memory collisions are avoided by not sharing memory between threads. A unit of work that can be done in parallel is split off and handed to another thread, and any data it needs is copied into that threads’ memory space. When the work is complete, the second thread notifies the primary thread if the work was completed successfully or not, and provides the resulting data or error.
In JavaScript, this notification is pushed into the event queue, and the main thread processes it when the event loop pulls the result off the event queue. Thus, the only memory that is shared between the code you’ve written in the Event Loop and the code running in the asynchronous process is the memory invovled in the event queue. Keeping this memory thread-safe is managed by the JavaScript interpreter. Thus, the code you write (which runs in the Event Loop) is essentially single-threaded, even if your JavaScript application is using some form of parallel processing!
Let’s reconsider a topic we’ve already discussed with this new understanding - timers. When we invoke setTimer(), we are creating a timer that is managed asynchronously. When the timer elapses, it creates a timer ’event’ and adds it to the event queue. We can see this in the diagram below.
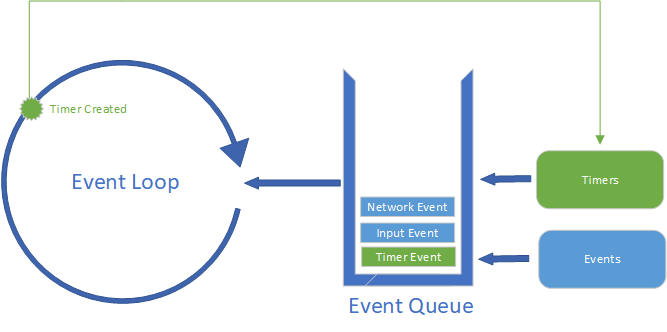
However, the timer is not actually an event, in the same sense that a 'click' or 'keydown' event is… in that those events are provided to the browser from the operating system, and the browser passes them along into the JavaScript interpreter, possibly with some transformation. In contrast, the timer is created from within the JavaScript code, though its triggering is managed asynchronously.
In fact, both timers and events represent this style of asynchronous processing - both are managed by creating messages that are placed on the event queue to be processed by the interpreter. But the timer provides an important example of how asynchronous programming works. Consider this code that creates a timer that triggers after 0 milliseconds:
setTimeout(()=>{
console.log("Timer expired!");
}, 0);
console.log("I just set a timer.");What will be printed first? The “Timer expired!” message or the “I just set a timer.” message?
See for yourself - try running this code in the console (you can click the “console” tab below to open it).
The answer is that “I just set a timer” will always be printed first, because the second message won’t be printed until the event loop pulls the timer message off the queue, and the line printing “I just set a timer” is executed as part of this pass in the event loop. The setTimeout() and setInterval() functions are what we call asynchronous functions, as they trigger an asynchronous process. Once that process is triggered, execution immediately continues within the event loop, while the triggered process runs in parallel. Asynchronous functions typically take a function as an argument, known as a callback function, which will be triggered when the message corresponding to the asynchronous process is pulled off the event queue.
Any code appearing after a call to an asynchronous function will be executed immediately after the asynchronous function is invoked, regardless of how quickly the asynchronous process generates its message and adds it to the event queue.
As JavaScript was expanded to take on new functionality, this asynchronous mechanism was re-used. Next, we’ll take a look at an example of this in the use of web workers.
As JavaScript began to be used to add more and more functionality to web applications, an important limitation began to appear. When the JavaScript interpreter is working on a big task, it stays in the event loop a long time, and does not pull events from the event queue. The result is the browser stops responding to user events… and seems to be frozen. On the other hand - some programs will never end. Consider this one:
while(true) {
console.log("thinking...");
}This loop has no possible exit condition, so if you ran it in the browser, it would run infinitely long… and the page would never respond to user input, because you’d never pull any events of the event queue. One of the important discoveries in computer science, the Halting Problem tackles exactly this issue - and Alan Turing’s proof shows that a program to determine if another program will halt for all possible programs cannot be written.
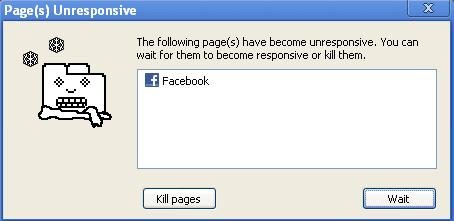
Thus, browsers instead post warning messages after execution has run for a significant amount of time, like this one:
So, if we want to do a long-running computation, and not have the browser freeze up, we needed to be able to run it separately from the thread our event loop is running on. The web worker provides just this functionality.
A web worker is essentially another JavaScript interpreter, running a script separate from the main thread. As an interpreter, it has its own event loop and its own memory space. Workers and the main thread can communicate by passing messages, which are copied onto their respective event queues. Thus, communication between the threads is asynchronous.
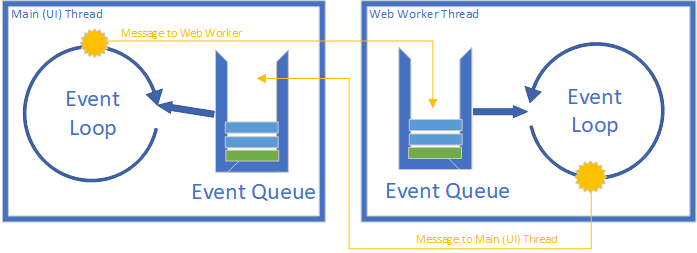
You can see an example of such a web worker by using this link to open another tab in your browser. This example simulates a long-running process of n seconds either in the browser’s main thread or in a web worker. On the page is also three colored squares that when clicked, shift colors. Try changing the colors of the squares while simulating a several-second process in both ways. See how running the process on the main thread freezes the user interface?
Web workers are actually very easy to use. A web worker is created by constructing a Worker object. It takes a single argument - the JavaScript file it will execute (which should be hosted on the same server). In the example, this is done with:
// Set up the web worker
var worker = new Worker('stall.js');The stall.js file contains the script the worker will execute - we’ll take a look at it in a minute.
Once created, you can attach a listener to the Worker. It has two events:
message - a deserialized message sent from the web workermesageerror - a message sent from the web worker that was not serializableYou can use worker.addEventListener() to add these, or you can assign your event listener to the event handler properties. Those properties are:
Worker.onmessage - triggered when the message event happensWorker.onmessageerror - triggered when the messageerror event happensAdditionally, there is an error handler property:
Worker.onerrorWhich triggers when an uncaught error occurs on the web worker.
In our example, we listen for messages using the Worker.onmessage property:
// Set up message listener
worker.onmessage = function(event){
// Signal completion
document.querySelector('#calculation-message').textContent = `Calculation complete!`;
}If the message was successfully deserialized, it’s data property contains the content of the message, which can be any valid JavaScript value (an int, string, array, object, etc). This gives us a great deal of flexibility. If you need to send more than one type of message, a common strategy is to send a JavaScript object with a type property, and additional properties as needed, i.e.:
var messageData1 = {
type: "greeting",
body: "Hello! It's good to see you."
}
var messageData2 = {
type: "set-color",
color: "#ffaacc"
}We can send messages to the web worker with Worker.postMessage(). Again, these messages can be any valid JavaScript value:
worker.postMessage("Foo");
worker.postMessage(5);
worker.postMessage({type: "greetings", body: "Take me to your leader!"});In our example, we send the number of seconds to wait as an integer parsed from the <input> element:
// Get the number to calculate the Fibonacci number for and convert it from a string to a base 10 integer
var n = parseInt(document.querySelector('#n').value, 10);
// Stall for the specified amount of time
worker.postMessage(n);Whatever data we send as the message is copied into the web worker’s memory using the structured clone algorithm. We can also optionally transfer objects to the web worker instead of copying them by providing them as a second argument. This transfers the memory holding them from one thread to the other. This makes them unavailable on the original thread, but is much faster than copying when the object is large. It is used for sending objects like ArrayBuffer, MessagePort, or ImageBitmap. Transferred objects also need to have a reference in the first argument.
For the JavaScript executing in the web worker, the context is a bit different. First, there is no document object model, as the web worker cannot make changes to the user interface. Likewise there is no global window object. However, many of the normal global functions and properties not related to the user interface are available, see functions and classes available to web workers for details.
The web worker has its own unique global scope, so any variables declared in your main thread won’t exist here. Likewise, varibles declared in the worker will not exist in the main scope either. The global scope of the worker has mirror events and properties to the Worker - we can listen for messages from the main thread using the onmessage and onmessageerror properties, and send messages back to the main thread with postMessage().
The complete web worker script from the example is:
/** @function stall
* Synchronously stalls for the specified amount of time
* to simulate a long-running calculation
* @param {int} seconds - the number of seconds to stall
*/
function stall(seconds) {
var startTime = Date.now();
var endTime = seconds * 1000 + startTime;
while(true) {
if(Date.now() > endTime) break;
}
}
/**
* Message handler for messages from the main thread
*/
onmessage = function(event) {
// stall for the specified amount of time
stall(event.data);
// Send an answer back to the main thread
postMessage(`Stalled for ${event.data} seconds`);
// Close the worker since we create a
// new worker with each stall request.
// Alternatively, we could re-use the same
// worker.
close();
};Workers can also send AJAX requests, and spawn additional web workers! In the case of spawning additional workers, the web worker that creates the child worker is treated as the main thread.
The web workers we’ve discussed up to this point are basic dedicated workers. There are also several other kinds of specialized web workers:
<iframe> elements. These are more complex than a dedicated worker and communicate via ports. See MDN’s SharedWorker article for information.JavaScript implements its asynchronous nature through callbacks - functions that are invoked when an asynchronous process completes. We see this in our discussion of timers like setTimeout() and with our web workers with the onmessage event handler. These demonstrate two possible ways of setting a callback. With setTimeout() we pass the callback as a function parameter, i.e.:
function timeElapsed() {
console.log("Time has elapsed!");
}
// Set a timer for 1 second, and trigger timeElapsed() when the timer expires
setTimeout(timeElapsed, 1000);With webworkers, we assign a function to a property of the worker (the onmessage variable):
function messageReceived(message) {
console.log("Received " + message);
}
// Set the event listener
onmessage = messageReceived;Remember, a callback is a function, and in JavaScript, functions are first-order: we can assign them as a variable or pass them as an argument to a function! We can also define a callback asynchronously as part of the argument, as we do here:
setTimeout(function() {
console.log("time elapsed")
}, 1000);Or using lambda syntax:
setTimeout(() => {
console.log("time elapsed")
}, 1000);These are roughly equivalent to passing timeElapsed() in the first example - and you’ll likely see all three approaches when you read others’ code.
Callbacks are a powerful mechanism for expressing asynchronicity, but overuse can lead to difficult to read code - a situation JavaScript programmers refer to as “callback hell”. This problem became especially pronounced once programmers began using Node to build server-side code, as Node adopted the event-based callback asynchronous model of JavaScript for interactions with the file system,databases, etc. (we’ll cover Node in the next chapter).
Consider this example, which logs a user into a website:
webapp.get('/login', (req, res) => {
parseFormData(req, res, (form) => {
var username = form.username;
var password = form.password;
findUserInDatabase(username, (user) => {
encryptPassword(password, user.salt, (hash) => {
if(hash === user.passwordHash)
res.setCookie({user: user});
res.end(200, "Logged in successfully!");
else
res.end(403, "Unknown username/password combo");
});
});
});
});Don’t work about the exact details of the code, but count the number of nested callbacks. There are four! And reasoning about this deeply nested code starts getting pretty challenging even for an experienced programmer. Also, handling errors in this nested structure requires thinking through the nested structure.
There are strategies to mitigate this challenge in writing your code, including:
The site callbackhell.com offers a detailed discussion of these strategies.
As JavaScript matured, additional options were developed for handling this complexity - Promises and the async and await keywords. We’ll talk about them next.
Promises replace the callback mechanism with a JavaScript object, a Promise. In many ways, this is similar to the XMLHttpRequest object that is at the heart of AJAX. You can think of it as a state machine that is in one of three states: pending, fulfilled, or rejected.
A promise can be created by wrapping an asynchronous call within a new Promise object. For example, we can turn a setTimeout() into a promise with:
var threeSecondPromise = new Promise((resolve, reject) => {
setTimeout(() => {
resolve("Timer elapsed");
}, 300);
});We can also create a promise that immediately resolves using Promise.resolve(), i.e.:
var fifteenPromise = Promise.resolve(15);This promise is never in the pending state - it starts as resolved. Similarly, you can create a promise that starts in the rejected state with Promise.reject():
var failedPromise = Promise.reject("I am a failure...");You can also pass an error object to Promise.reject().
What makes promises especially useful is their then() method. This method is invoked when the promise finishes, and is passed whatever the promise resolved to, i.e. the string "Timer elapsed" in the example above. Say we want to log that result to the console:
threeSecondPromise.then(result => {console.log(result)});This is a rather trivial example, but we can use the same approach to define a new method for creating timers that might seem more comfortable for object-oriented programmers:
function createTimer(milliseconds) {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve();
}, milliseconds);
});
}With this method, we can create a timer to do any arbitrary action, i.e.:
// Say "Hello Delayed World" after five seconds
createTimer(5000).then(() => console.log("Hello delayed World!"));In addition to the then() method, promises also provide a catch() method. This method handles any errors that were thrown by the promise. Consider this function that returns a promise to compute an average:
function computeAverage(numbers)
{
return new Promise((resolve, reject) => {
// Sum the numbers
var sum = numbers.reduce((acc, value) => acc + value);
// Compute the average
var average = sum / numbers.length;
resolve(average);
});
}Try copying this code into the console, and then run some examples, i.e.:
computeAverage([1, 3, 5]).then(average => console.log("The average is", average));computeAverage([0.3, 8, 20.5]).then(average => console.log("The average is", average));But what if we use the empty array?
computeAverage([]).then(average => console.log("The average is", average));Because the length of the empty array is 0, we are dividing by 0, and an error will be thrown. Notice the error message reads “Uncaught (in promise)”… we can use the catch() method to capture this error, i.e.:
computeAverage([])
.then(average => console.log("The average is", average))
.catch(err => console.error("Encountered an error:", err));Note when chaining JavaScript method calls, our dot . can be separated from the object it belongs to by whitespace. This can help keep our code readable by putting it on multiple lines.
Now when we run this code, the error is handled by our catch(). We’re still printing it to the console as an error - but notice the message now reads "Encountered an error" ..., i.e. it’s our error message!
Let’s try one more - an array that cannot be averaged, i.e.:
computeAverage(['A', 'banana', true])
.then(average => console.log("The average is", average))
.catch(err => console.error("Encountered an error:", err));Here we see the promise resolves successfully, but the result is NaN (not a number). This is because that is the normal result of this operation in JavaScript. But what if we want that to be treated as an error? That’s where the reject() callback provided to the promise comes in - it is used to indicate the promise should fail. We’ll need to rewrite our computeAverage() method to use this:
function computeAverage(numbers)
{
return new Promise((resolve, reject) => {
// Sum the numbers
var sum = numbers.reduce((acc, value) => acc + value);
// Compute the average
var average = sum / numbers.length;
if(isNaN(average)) reject("Average cannot be computed.");
else resolve(average);
});
}Rejected promises are also handled by the catch() method, so if we rerun the last example:
computeAverage(['A', 'bannana', true])
.then(average => console.log("The average is", average))
.catch(err => console.error("Encountered an error:", err));Notice we now see our error message!
Where Promise.prototype.then() and Promise.prototype.catch() really shine is when we chain a series of promises together. Remember our callback hell example?
webapp.get('/login', (req, res) => {
parseFormData(req, res, (form) => {
var username = form.username;
var password = form.password;
findUserInDatabase(username, (user) => {
encryptPassword(password, user.salt, (hash) => {
if(hash === user.passwordHash)
res.setCookie({user: user});
res.end(200, "Logged in successfully!");
else
res.end(403, "Unknown username/password combo");
});
});
});
});If each of our methods returned a promise, we could re-write this as:
webapp.get('/login', (req, res))
.then(parseFormData)
.then(formData => {
var username = formData.username;
var password = formData.password;
return username;
})
.then(findUserInDatabase)
.then(user => {
return encryptPassword(password, user.salt);
})
.then(hash => {
if(hash === user.passwordHash)
res.setCookie({user: user});
res.end(200, "Logged in successfully");
else
res.end(403, "Unknown username/password combo");
})
.catch(err => {
res.end(500, "A server error occurred");
});The Promise.prototype.catch() method catches any error or promise rejection that occurs before it in the chain - basically as soon as an error or rejection occurs, further .then() calls are skipped until a .catch() is encountered. You can also chain additional .then() calls after a .catch(), and they will be processed until another error or rejection occurs!
In addition to processing promises in serial (one after another) by chaining .then() methods, sometimes we want to do them in parallel (all at the same time). For example, say we have several independent processes (perhaps each running on a webworker or separate Node thread) that when finished, we want to average together.
The Promise.All() method is the answer; it returns a promise to execute an arbitrary number of promises, and when all have finished, it itself resolves to an array of their results.
Let’s do a quick example using this method. We’ll start by declaring a function to wrap a fake asynchronous process - basically creating a random number (between 1 and 100) after a random number of seconds (between 0 and 3):
function mockTask() {
return new Promise((resolve, reject) => {
setTimeout(() => {
var value = Math.ceil(Math.random()*100);
console.log("Computed value", value);
resolve(value);
}, Math.random() * 3000)
});
}Now let’s say we want to compute an average of the results once they’ve finished. As Promise.All() returns a Promise that resolves to a an array of the results, we can invoke our computeAverage() (which we declared previously) in a chained .then():
Promise.all([
mockTask(),
mockTask(),
mockTask(),
mockTask()
])
.then(computeAverage)
.then(console.log);Note that because computeAverage takes as a parameter an array, and console.log takes as its parameter a value, and those are what the previous promises resolve to, we don’t have to define anonymous functions to pass into .then() - we can pass the function name instead.
Many JavaScript programmers found this format more comfortable to write and read than a series of nested callbacks. However, the async and await syntax offers a third option, which we’ll look at next.
The async and await keywords are probably more familiar to you from languages like C#. JavaScript introduced them to play much the same role - a function declared async is asynchronous, and returns a Promise object.
With this in mind, we can redeclare our createTimer() method using the async keyword:
async function createTimer(milliseconds) {
return new Promise((resolve, reject) => {
setTimeout(() => {
resolve();
}, milliseconds);
});
}Now, instead of using the promise directly, we can use the await keyword in other code to wait on the promise to resolve, i.e.:
await createTimer(4000);
console.log("Moving on...");Try running this in the console. Notice that the second line is not executed until the timer has elapsed after 4 seconds!
Similarly, if we need to use a value computed as part of an asynchronous process, we can place the await within the assignment. I.e. to reproduce the Promise.All() example in the previous section, we could re-write our mockTask() and computeAverage() as async functions:
async function mockTask() {
return new Promise((resolve, reject) => {
setTimeout(() => {
var value = Math.ceil(Math.random()*100);
console.log("Computed value", value);
resolve(value);
}, Math.random() * 3000)
});
}
async function computeAverage(numbers)
{
return new Promise((resolve, reject) => {
// Sum the numbers
var sum = numbers.reduce((acc, value) => acc + value);
// Compute the average
var average = sum / numbers.length;
if(isNaN(average)) reject("Average cannot be computed.");
else resolve(average);
});
}And then the code to perform the averaging could be written:
var numbers = [];
numbers.push(await mockTask());
numbers.push(await mockTask());
numbers.push(await mockTask());
numbers.push(await mockTask());
var average = await computeAverage(numbers);
console.log(average);Many imperative programmers prefer the async and await syntax, because execution of the code pauses at each await, so code statements are executed in the order they appear in the code. However, the actual execution model it is still the event-based concurrency that we introduced with callbacks. Thus, when awaiting a result, the JavaScript interpreter is free to process other incoming events pulled off the event loop.
In this chapter we learned about many of the approaches and challenges involved in concurrent programming, including asynchronous programming. JavaScript adopts the asynchronous approach through its use of the event loop and queue, allowing asynchronous processes to be invoked, processed on separate threads, and posting their results as new messages on the event queue to be processed when the main thread gets to them.
We saw how this approach allows for multi-threaded programs in the browser through the use of web workers, each of which runs a separate JavaScript interpreter with its own event loop and queue. We also saw how communication between web workers and the main thread are handled through message passing, and how very large data buffers can be transferred instead of copied between these threads for efficiency.
Finally, we examined the callback mechanism used for asynchronous processing in JavaScript, and explored two common abstractions used to make it more programmer-friendly: promises and the async/await keywords.
In the next chapter, we’ll explore Node.js, a server-side implementation of the JavaScript engine that makes heavy use of the JavaScript asynchronous model.