CS Topics
An overview of some of the most important topics, research areas, and cool ideas in computer science!
An overview of some of the most important topics, research areas, and cool ideas in computer science!

Hey folks, today I’d like to talk to you a little bit about supercomputing. I’m Dr. Dan Andresen. I’m the director of our K-State Supercomputing center, also a professor in computer science. So if you want to see me come by my office or set up a Zoom meeting, happy to talk about this sort of thing. So supercomputing is about two things. It’s about size. And it’s about speed. And compared to your average laptop, the laptop is the teeny mouse, so it’s about two big things. And it’s about size, because many problems just can’t fit into a standard laptop or standard desktop. And see if this issue of Okay, my problem is too big for that, what do I do? You take it to a supercomputer. Or similarly, if you’ve got a big problem that just takes way too long, or you got a little problem, and you get lots and lots of them, then it’s really useful to have something that isn’t likely to go ahead and say, Oh, yeah, by the way, I’m going to restart it every couple weeks, because Microsoft pushed out a patch, or something like that. And so these are the types of problems that we do on a supercomputer because with a supercomputer, we bring the size, we bring the speed so that if you’ve got really big problems, they’re actually manageable.
We had one of our users, for instance, that came to me a year or two ago, and said, I’ve got a problem that’s taking too long to run. Sure. How long have you taking, like calculate is going to take 436 years? Ah, we can handle that. So anyway, we talked about it, set some students on it, we ran it on Beocat, we ran it in parallel, and we knocked down a one week problem down to 36 seconds, which is about an 81 million times speed up. And that’s the sort of thing that a) is a lot of fun. And b) it’s something that we get to do in supercomputing because we have the tools that can really take this on. So supercomputers are awesome for doing the really big problems. We use it for things like simulations and data mining and visualization. The idea is we take really big amounts of data. An average wheat genome is one and a half terabytes, for instance, a little more than your average PC can handle. Especially if you’re doing a denovo genome assembly, where you need all that in memory. Otherwise, it takes forever. So what we do is we take the big data, and we look at it and we say, hey, how can we analyze this? How can we compute with it, and come up with some really life changing stuff?
So for instance, tornadoes: fact of life here in Kansas. And so what happened was years ago, we couldn’t really do things at a high resolution, that’s the kind of this general idea that will maybe there might be a problem somewhere in the area. And on TV, they’d have this thing, look out everybody in this massive cone of space. Now it’s more like, Okay, if you’re in this area move. And if you’re in this area, you’re probably gonna be relatively safe. Because we’ve got more and more powerful computers, we’ve got better and better models. And because we’ve got the supercomputers that can handle it, we can start saying, hey, look, it’s worth spending $20 million on the machine, because we got to avoid evacuating Houston, which would cost billions or evacuating most of Florida, which would also cost billions. And so because we have bigger computers, and we have faster computers, we can actually do some really cool stuff.
So we do simulation, because a lot of times it’s either impossible, or really hard to do things in real life. You know, it’s the like the old joke about defining the universe give two examples. What do I do? I can’t. So you can either use simulation to say, Okay, let’s simulate what a universe would be like if you know, various laws were tweaked. Or there are times where it’s just too expensive. We had a professor, for instance, that was doing air purification systems. And every time she built a sample, micro engineering product, it cost about $10,000. Well, what you would do is you’d use a supercomputer to analyze electronically 10s of thousands of these possibilities, then for the ones that looked really, really promising, you’d have a sample made. Saved her millions of bucks. So the idea behind simulation on supercomputers, we can do things that otherwise we just can’t do, whether it’s for ethical reasons, or for economic reasons. Both are very, very valid. The other thing is supercomputing isn’t just something we do for science. It’s also something that really has a big impact on industry. Airlines, for instance, use supercomputers to figure out how can we optimize logistics saving about 100 million bucks a year, automotive design, again, about a billion dollars per company per year in terms of not having to do all the testing and being able to pull together and do CAD CAM, structural integrity, all this analysis that we don’t have to do physically. But it becomes something we can do digitally in a simulation, and it saves a ton of money despite being kind of expensive. I mean, to get a supercomputer it’s anything over about a million bucks or so up into the possibly hundred million dollars. If you’re a government system that really needs a big system. Semiconductor industry, same sort of things saving about a billion bucks a year. Energy, about building about two new power plants for you and those suckers are expensive, you know, 300 million up to about a billion dollars each.
If you go to work, for instance, for Cerner. They have the equivalent of a supercomputer they use to do virtual drugs studies, Hey, what is this impact on this drug with this drug for male patients in their late 80s, or something like that they do enough, they have enough data, they can do this analysis and say, here, here’s the impact. And it works. And it’s really has a big impact on their bottom line. And on the fact that they didn’t have to go out and do drug testing on a bunch of 80 plus year old men, because like my dad, he’s not in good, good shape for setting up a bunch of drug tests might actually hurt him. So really an important thing, both in the real world, real world, and in academia and in science. So why do we bother? Well, the big news is, you can do bigger and more exciting science. And that’s really one of the drivers today for scientific supercomputing is the fact that you can do things at a massive scale, whether it’s simulating the universe, simulating weather and hurricanes, or simulating genomes and looking for things that oh, you know, might be causing the COVID virus to be so nasty. And so you get very, very useful information out of some very, very big powerful tools. Similarly, if you’re familiar with HPC, or supercomputing, then you know, where normal computing is going.
So 20 years ago, Google was barely a gleam in Sergey’s eye. But on the other hand, for those of us that were in supercomputing at the time, what they were doing is like, Oh, yeah, we understand that. And so you can get ahead of the curve, and know where normal computing is going to be. And that can be a really strategic advantage. If you’re trying to figure out where am I going to go in my job, and what’s my career going to look like? So in the future, the general idea is, particularly if you start combining things like 5G networking, and the cloud and software, you can license pretty easily and the Internet of Things. And you started seeing My computer is really well, I need this sensed I need this computed on. And I need this visualized, and I need to plug in this AI algorithm to do an analysis on it for me. And then I want the output displayed in my virtual reality goggles. That’s what it looked like, we could have a great, here’s my credit card. Well, I still have it all on file already. Here’s my credit card. Here’s my budget. And let’s go ahead and rent the sort of thing. So you won’t necessarily say hey, I need to buy a $5 million computer, although you might, but you might rent one for the time that you need it and then let other people use it when they don’t just like you do today in the cloud.
So it’s collaborative, you work with other people. It’s dynamic, and it is really, really cool. So that’s kind of what we’re looking at for the future in terms of supercomputing, but it’s all at massive scales. So a couple of resources. A lot of these slides I get from Henry Newman, Globus Open Science grid and other things are available. Thanks for the people that let us use your graphics. And I hope this helps. If you have any questions want to talk about it. As you can tell, I like to talk about it. Get in touch
Read Pattern on the Stone, Chapter 7 - Speed: Parallel Computers
In this module, we will spend a lot of time talking about compression and error checking in our computers. We’ve already talked about compression a little bit in the data encoding module earlier this semester. But now we’re going to spend an entire module talking about just these two topics. First, we’re going to talk about in compression. What do you think compression is and why do you think it’s useful? As you might recall, compression is reducing the amount of space a particular piece of data needs to be stored on a computer. And if we think about that, that may not even really make sense, how can we take the piece of data and store it in fewer Bits and Bytes than what it originally was? It turns out, there are a lot of different ways to do that. We can do all sorts of different things by replacing repeated chunks of data or re-encoding the data in such a way that we can interpret it differently in our computer systems. And we’ll take a look at that in this module.
Why do you think we would do that? Well, computer resources are very expensive. For example, think about the storage space in your computer. While you might have a couple of terabytes. If you’ve ever played video games, or downloaded a lot of videos, you’ll find that that space gets eaten up very, very quickly by those large files. And so we can use compression to reduce the amount of space that those files take up and store them in fewer hard drives than it would take to store the raw files. Likewise, we can think about transmission bandwidth across the internet. If we need to send a large file across the internet. If our internet connection is very slow, it might be better to compress the file before we send it and then allow the other user on the other end to decompress that file when they receive it. However, of course, this does create a trade off, we’re spending computation time to compress and decompress the data in hopes of saving transmission time in storage space when we actually store or transmit the file. And so depending on the amount of computational power we have, and the amount of transmission or storage space we have available, it may or may not make sense to compress data. But in general, compression is usually a good thing and helps us save more data in a smaller amount of space, and transmit lots of data very quickly across the internet.
So let’s take a look at one example of compression called run length encoding. In run length encoding, we’re looking for runs or repeated sequences in our data. And then we’re going to going to replace them with a shorter version of that data in our actual store data itself. Usually that shorter version would be the sequence that we’re repeating, and account of how many times it gets repeated. So let’s take a look. Here’s an example of data that we could send via run length encoding, we’re using characters and recall of course, the characters can be stored as binary values using ASCII the American Standard Code for Information Interchange. So while we’re representing this data as text, it would actually be stored and transmitted as binary on our computers.
So in run length encoding, we would look for repeated characters and try and replace them with shorter versions of themselves. For example, if we look at these W’s at the top, we can see that they’re an awful lot of them. So let’s count them, we have 1 2 3 4 5 6 7 8 9 10 11 12, there are 12 W’s. So in our in our data, we would say that we have 12 W, then we have one B, so we just write one B, then we have 12 more W’s. So if you count those out, there will be 12, W’s, and so on. And so with run length encoding, we would be able to count the number of each characters and put a number followed by the character that shows up. So if we encode all of this data with run length encoding, we would get 12 W, 1 B, 12 W, 3 B, 24 W, 1 B, 15 W.
As we talked about earlier, the characters W and B can also be stored as binary. And of course, these numbers can be stored as binary. So it should be pretty easy to figure out how we can convert this particular string of data into a binary string that we would send along with our data.
But there might be a problem. If we think about all of that being one long string of binary numbers, how could we tell which parts of it are the numbers and which parts of it are text. And remember, the text itself is just numbers as well. So maybe we need to come up with some sort of a scheme that allows us to structure that data so that we know where the numbers are and where the text is. So let’s take a look at that.
Here’s that same example again, but how do you think we could write it so that we can easily tell which ones are the text and which ones are the numbers? Take a minute to think about that before you move on. A better way to think about this would be to use escape sequences. So in escape coding, what we would do is we would have a double character representing an escape sequence. For example WW; the WW being a repeated character would reduce down to just a single W. But then afterwards, we would have a number. And so looking at this bottom, we see WW followed by 12. The ww is our escape sequence saying we are going to repeat the letter W. And the next bit of binary data is going to be the number of times we repeat that character. So we see WW 12. Then we see just one B. And because B is not repeated, we just assume that that is text.
Next, we have WW again. And since that’s a repeated character, that will tell us that we’re going to repeat W and the next bit of data is going to be binary, that is the number of times we repeat that character. So then we have WW 12. Now we have three B’s, so we have BB 3. Then we have WW 24, a single B, then WW 15. So if you look at this, that is a little bit longer than the example we saw earlier, because we have to double some of the characters. But this example is much easier to read for our computer. We know that every character is text, except if we see the same character twice. And then we will know that the eight bits after that represent a number that we could use to repeat that character that many times. So now that we’ve seen an example of run length encoding, we’re going to let you give it a try in the next quiz.
Next, let’s take a look at another form of compression called Huffman coding. Huffman coding uses the frequency of the letters in a piece of text to reduce the amount of space that they take up in the encoded data. To do this, we will count the occurrences of each character in our text. And we’ll use that count to make a binary tree with the data. Then the paths of the tree to each character give the codes that we use for the Huffman encoded data. This is a little bit complex.
But let’s take a look at an example and see how this works. Let’s say we’d like to send this particular text using a Huffman tree. This is an example of a Huffman tree. If we count this just as plain ASCII characters, it would take 298 bits, which is 8 times 36 characters to send this data. So now let’s look at how we would encode it into a Huffman tree. The first thing we would do is we would count the number of occurrences of each character.
So let’s look at an example of how we would convert this into a Huffman tree. The first thing we would do is we would count the frequency of each character. So let’s take a look at the spaces we have 1 2 3 4 5 6 7. So we have seven space characters in this particular example, so we can make a list. On this slide, we see the list of some of the most common characters in that text. There are seven spaces, 4 letter A’s, 4 letter E’s, 3 F’s, 2 H’s, 2 I’s, 2 M’s, 2 n’s, and so on.
So with that data, we can then construct a binary tree by using the frequency of the characters to determine where they go in the binary tree. Since the space is the most frequent character, we’re going to put it at the very top of the tree, whereas least frequent characters, for example, a p would go toward the bottom of the tree. So if we follow the Huffman example algorithm, we’ll see that we create a binary tree that looks something like this. And this is pretty complex. And we’re not going to exactly talk about how to build this binary tree. But there is a very unique algorithm that you’ll learn about later on that can allow you to do this.
So now we look at this tree. And we see that the space character is way over here. We mark it for you. So the space characters right here. So to get to that space character, we will make right, here, right here, and right here. So the space character, in terms of directions would be RRR. Likewise, the E, we would go left, left, left. So E is going to be left, left left. This is the space, this is the E. And so in Huffman coding, we would use the direction that we go in the binary tree to become our data. So if we encode this, so that right is ones, we would do 111 for the space, for the E, it would be 000. Pretty cool, isn’t it?
Likewise, if we want to get to the letter A, we would go left, then right, then left, so A would be left, right left to get A. So that would be 010. Pretty cool, isn’t it. So we’ve taken characters that normally need eight binary values to represent them. And we can represent them here with this tree in anywhere from three to five characters. So if we look at this Huffman example, broken up, we’ll see something like this, the letter team becomes 0110, H is 1010. And if we go on, we can eventually find the A, which is going to be this one right here, th, this, space, is, space, A n, space, example, we saw that he was 000. So right here, we’ve got a really big improvement. We’ve gone from 288 bits of data all the way down to 135 bits of data. So we’ve nearly cut it in half a little bit more than half actually, to make this work.
Now, of course, Huffman trees do come with one particular caveat that we have to talk about. If we want to transmit this data encoded using a Huffman tree, we would also have to send a representation of the Huffman tree itself to allow this data to be decoded. And that can add a significant amount of overhead on small texts like this. In fact, the amount of data we would need to send this Huffman tree would be way more data than we needed to encode the original message even completely uncompressed. So while Huffman tree is a very powerful encoding system, It really works well when you’re sending large amounts of text like an entire book, then using a Huffman tree to encode that you can get significant savings in your compression. So once again, we’ve got a little example of the Huffman tree encoding problem that you can try on the next quiz.
Now let’s talk about error checking. What do you think error checking means when we’re talking about sending and retrieving data? And why do you think it would be useful? Well, let’s take a look at an example. When we send data, such as this text, hello there, sometimes the data might get garbled in transmission. When you were a kid, if you played with radios or walkie talkies, or anything like that, you might have had trouble understanding what other people say, Heck, even it happens today, sometimes on cell phone calls. So if there was a way that we could confirm that the data we’re receiving is the data that was actually sent without adding too much overhead to the data, that might be a really powerful tool, a great intuition to think of is squeezing the data into a smaller space, and then using that to check and see if we got the right answer.
So if we start with the text, hello there, and we squeeze the kerning, between the characters really narrow, we get this image shown below, that we can use as a little check to make sure that the data that we received was the same thing. So on the receiving end, if instead of receiving Hello, there we see Hello, ghere. If we squeeze that together the same way, we noticed that the squeezed image does not look the same as the squeezed image above. And so by sending the squeezed image above, we would know that we didn’t get the right data. And that squeezed image doesn’t take up a whole lot of space. That’s really the intuition behind error checking, we’re trying to send a little bit more data along with a larger transmission. And we can use that little bit of extra data to make sure the transmission itself was received without errors. That’s the real intuition behind this.
So let’s take a look at an example. One of the best ways we could do this is simply adding together the numbers. So if we take the sentence Hello there, and we convert it to ASCII, we see that a capital H is 72, e is 101, L is 108, and so on and so forth. So if we take all of those numbers, we could just add them up, and send all of that ASCII text plus the number 1101. Pretty cool, isn’t it, then on the receiving end, if the T got replaced with a G, obviously, the sum we would get would be different. And we would know that somehow that message got corrupted. Of course, this might be a little bit complex, for example, 1101 doesn’t fit in an eight bit binary number, so we may have to truncate it a bit or use modulo, to reduce it down to a number that fits into an eight bit binary value. Now, of course, this is a very simple form of error checking, and it does have some flaws. So let’s talk about some of these different questions. For example, if we only have the sum that came along with that message, could we use that to recover the original? So if I just gave you 1101? Could you tell me what original message produced that sum? Probably not. It would be really, really difficult to do. So we can’t use it to recover the original.
How well does it detect errors? Well, if we change the T to a G, we would probably detect that. But what if we replaced an L with an M and another L with the letter right before L? How well does this detect errors? Well, let’s consider the case where one of the L’s in hello gets replaced with an M, and the other L gets replaced with a K. M is one greater than L. But K is one less than L. And so when we sum those together, we would still get the exact same sum. So it is possible for us to create an error that the sum itself does not catch, that’s not really good. So as we can see, are the areas that cannot detect absolutely, we could swap characters, we could rearrange the characters, they would all still sum up to the exact same value. There’s tons of ways that we could do this. And of course, we talked about this a little bit already, but 1101 is larger than eight bits. How should we handle that? Well, we could use modular division where we divide it by 256. And keep the remainder, which would be the modulo operation that you learn about in your programming courses that would allow that number to fit in just eight bits. But of course, the big question we always ask in this class, can we do better. And I would argue that there are ways that we can definitely do better than a simple addition error checking.
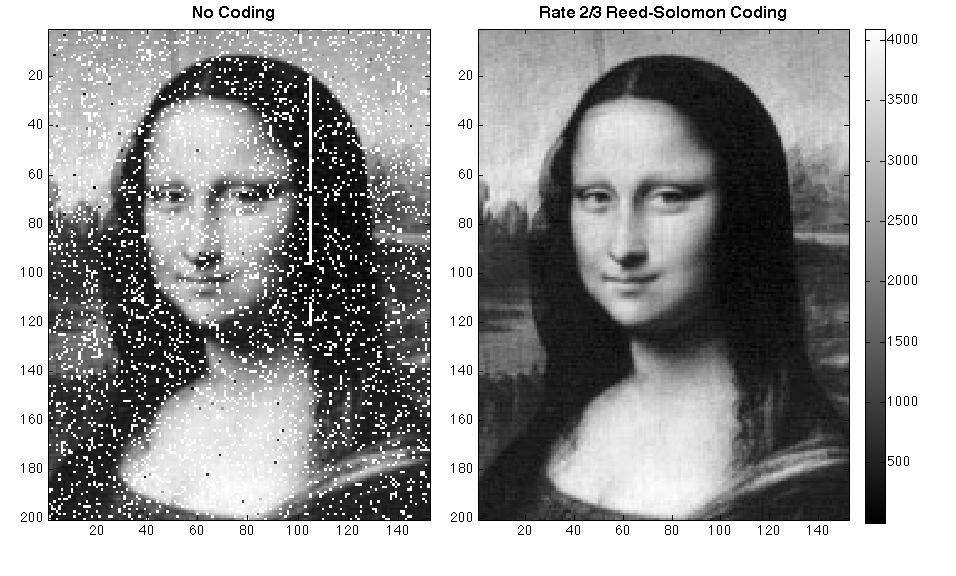
So let’s take a look at another example of error checking. In this case, it’s called pinpoint error checking. Here, we’ve received a number 483754. So very large number, and we’ve taken that number and we’ve arranged it in a four by four grid. And then we’ve added a column in a row to the end of the grid that we can use to calculate what we call our checks up, which is the sum that we’re going to create to make sure that these numbers are correct. To create that checksum, what we will do is we will sum up each row and each column and then we will keep just the ones place of that value in this call. So for exam We have 4 plus 8 is 12, plus 3 is 15 plus 7 is 22. So here we would put 2, here we have 5 + 4 is 9, + 3 is 12, + 3 is 18. So we would keep the 8. Likewise, we could go down, we have 4 + 5 is 9, + 2 is 11, + 3 is 14. So we would keep the 4, here we have 8 + 4 is 12, + 2 is 14, + 9 is 23. So we would keep 3. And we could do this all the way through until we got all of these numbers, which we see right here, we see 4306 along the bottom, and 2858 along the side, then when we send the message, we could simply add those numbers in where they go, we see down here are 4837 of our original number, plus this 2 for our checksum 5436, plus an 82256, plus a 53397, plus an 8. And then we have 4306, which is our bottom checksum. So we have a 16 digit number. And we’ve added 8 more digits to it to provide a checksum. So it’s gotten a little bit bigger, it’s about 50%, bigger than it was.
But what can we do with this checksum that’s very, very powerful. So here, we’ve received a message. And we have in gray, our original checksum. And then in red, we have the checksum that we calculated from the message that we received. So take a look at this and see if you can figure out exactly where the error is in this received message. All right, let’s see if we can find the error. So we look at our checksum for matches up. 3…, uh-oh, this one doesn’t match up. So we’re going to circle this one. Zero matches up, six matches up, two matches up, eight matches up, uh-oh, here, 5 and the 0 don’t match up, and then the 8 matches up. So if we look at the row and the column, we know that this one is incorrect. Now the big question is, can we use this to restore that value to what it originally was, we know here that this value should be eight larger, or should be five larger, and we know that this value should be there, five larger five smaller. So with this number, if we add five to it, and just keep the ones place, we know that this number should probably have been a two. So let’s look at our original. Uh huh. It was a two. So using this pinpoint checksum by adding a little bit more data to the data that we’re transmitting, not only can we detect an error, but we can actually correct an error. And there are some different ways we can measure this. For example, we can detect a lot of different errors, but we may not be able to correct as many errors as we can detect. And that’s one of the important things to remember about checksum such as this. So now that you’ve seen an example, we’ll have a little quiz after this where you can do another example on your own just to see how this works.
The C2 total on the slide at 0:54 - 2:10 is incorrect. The total is 7336 but that value modulo 255 is 196, not 96 as shown in the video.
Let’s look at an even better way to do a checksum to check and see if our data is correct. This is called Fletcher’s checksum. And here we’re giving a quick pseudocode of the algorithm that is used to generate Fletcher’s checksum. Basically, the way it works is you divide the word into a sequence of equally sized blocks. And we’ll just use the individual characters for this. And we’ll start with two checksums, one of them, C1 starts at zero, the other to also starts at zero, then for every block, we’ll add the value of the block to the first check sum. And then we’ll add the new value of that checksum to the second checksum. And then finally, while we’re done, we will calculate the values of the checksum mod 255 to reduce them to an eight bit binary value. And we’ll return those two checksums.
So let’s take a look at an example of how we would do Fletcher’s checksum. We’ll start with our same messages always and divided into blocks where each character is its own block. So the first character, the capital H is a value 72. So we’ll add 72 to the first checksum. And then we will add that checksum value to the second checks up. So after the first character, they’re both the same. The second character, the lowercase E is 101. So we’ll add 101 to the first checksum to get 173. But now we will add this new checksum 173 to the value of 72 and the second checksum to get 245. Likewise, we’ll add 108 to 173 to get 281, then we’ll add 281 to 245 to get 526. And we’ll continue this process until we’ve done all the letters. And then at the end, you’ll see that we still get the same checksum that we found earlier 1101, which becomes 81 when we do mod, and then the second checksum becomes 7336, which is 96 when we do them on. So now we only have to send along two additional numbers along with our text. And that will tell us a lot more about the text in the errors. So let’s take a look at that and see how many errors this can find. Let’s consider the case of just doing these first three characters. So we know that the checksum for 72, 101 ,108. If we look back here should be 281 and 526. So we would have 281 and 526. So let’s look at this first example. We have 72 108 101. Well, that changed the first checksum? No, it’s the exact same value, it will be to 81. However, will it change the 526? Well, we start with 72. And then we will add 72 plus 108, which is going to be eight 180. So the second check sum will be 180. So we’re going to add 180 here, 180 here, which is going to be 252. And then to the 180, we’re going to add 101. So the second checksum is still going to be 281. But if we add 281. Here, we’re going to get 331, we get 533.
So in this example, by switching these two characters, the first checksum did not change, but the second checksum definitely changes. And that’s because the order changed. Likewise, when we look at all of these examples, we see that all of them add up to the same set of characters. So the first checksum will always be 281. But the second checksum will be different every single time. And that’s because we’re adding this first checksum to the second checksum every single time so it captures the ordering of the characters as well as the values that they may change based on those different values. So even by adding a zero in there, we would get a different value for that second checksum. So once again, there will be a quiz after this video where you can try a little bit of Fletcher’s checksum just to see how it works.
Let’s go over a couple other error checking methods that you might run across, we’re not going to go into these in too much detail because they are kind of complex at this level. But we’ll give you an idea of what’s out there, just so you can say you’ve seen it. One interesting example is the cyclic redundancy check or CRC. With CRC will have some sort of binary value. And we’ll use a particular checksum to verify it. So we’ll start with this binary value on a checksum. And we will compute the XOR of the checksum, and that binary value. So we start with 1010. And we XOR that with 1011. So we’ll get 1. And this works a lot like long division, we just keep working down the value until we get left with something that is smaller than our checksum. And so with this input 101000001001, we would send along these three bits 011 as our checksum. And then once we’ve received it, we can do this same division again, and make sure that we get the same checksum to know that the error hasn’t been introduced in our code.
Another method of error checking is hash codes. And hash codes are really complex. But they basically are a one way algorithm to take any piece of data and convert it into a single value. So for example, we would choose some sort of a hash base like 2 or 10, or 37. And then if we have a whole bunch of numbers, we would calculate the hash as the first number times our base to the value in plus the second number times the base to the power n minus one, and so on, and so forth. So if we have the word 456, if our base is 10, obviously, our hash should be 456. If our base is 100, we get 4056. If our bases, just five, it would be 126. But if we choose some interesting other numbers, we would get different hash codes. Later on, if you start taking programming courses, one of the data structures you’ll learn about is a hash table, sometimes known as a dictionary or a hash map. And to do that, what it does is it takes a piece of data and it computes the hash of that data, and then uses that to store the data in a unique way so that it can be quickly retrieved. But we can also use those hashes to verify data.
Another really common use of hashes would be password store. For example, md5 is a commonly used pass password hashing algorithm, or at least it was it’s been cracked since then. But you could take any text and calculate the md5 hash of that text and store that number. Then if anyone tried to input a password, you would simply take their password, re-compute the hash. And if it created the same hash as the actual password, then you know that that user inputed the create the correct password, and you could allow them access. Here’s another quick example of hash codes, just showing what it would look like for some other input data.
Another form of error checking you might run into is called a hamming code. And a hamming code is kind of complex. But what it does is it takes the data bits that you want to send and it calculates what are called parity bits for those data bits. A parity bit is basically a bit that’s designed to make all of those data bits plus the parity bit come up to an even number of ones. So if we want to send the data in bits, 3,5,6, and 7, for example, we want to send 0100, we calculate these three Hamming parity bits. The first one is 3,5,7. So we look at 3,5,7, there’s only a single one there. So that parity bit would be a one, the bits 3, 6, and 7 would be 3,6,7. There’s no one so we put a zero there. And then for 5,6,7, there’s a single one, so we need to add one more one to get to an even number of ones. Then to construct the actual hamming code, we have our first parity bit, our second parity bit, so one, zero, then we have our first data bit zero, then our last parity bit one, and then the last three bits of our data Five, six, and seven. It’s a little complex. But the concept behind Hamming codes is to create data words that are so far apart from each other that a single bit error, you can almost just round it to the closest binary value that makes sense for the hamming code that you’re using, and use that as your way to solve different errors. In this module, we’ve covered a lot of different ways that you can compress and do error checking on data that you send and receive or data that you store in your computer’s while a lot of this can be kind of complex and math heavy.
I’m hoping this opens your eyes a little bit to some of the things that go on behind the scenes on your computer that you might be aware of, but really didn’t understand how they work. We deal with things like zip files and JPEG images all the time. And those are all examples of compression. Error checking is a little bit more behind the scenes, but it’s really the backbone of how we can send and receive data across the internet using these unreliable connections and packets that might be dropped and still be able to recover and understand the data that we receive on the other side.
Nine Algorithms that Changed the Future Ch 1 - Introduction
Nine Algorithms that Changed the Future Ch 5 - Error Correcting Codes
Nine Algorithms that Changed the Future Ch 7 - Data Compression

In this module, we’re going to take a look at one of the most important applications of computer science and modern technology- the field of cryptography. Cryptography is the study of ways to communicate securely and privately in the presence of third parties. If you think about it, cryptography is very important today with the rise of the Internet and modern technology. Any data that’s transmitted over the internet can be intercepted by just about anyone from your internet service provider all the way to the website that you’re communicating with, and anybody in between. Remember, the internet is built upon open standards, and so anybody can understand the packet formats and deconstruct them very quickly. So we need a way that we can encrypt and secure the data inside of those packets. So they can only be opened by the intended recipients, and that’s where the field of cryptography comes in. There were lots of historical Computer Science professionals interested in cryptography. Charles Babbage was very fascinated by it. Alan Turing was especially involved in cryptography, and Claude Shannon, were all involved in the field of cryptography. Also, surprisingly, the author Edgar Allan Poe was one of the people that was really excited about cryptography outside of computer scientists, and in fact, helped popularize cryptography as a word game that you might see in your newspaper.
So let’s take a look at an example of what cryptography might look like. When I used to teach this in a classroom, I would usually start by having strips of paper with this particular message printed out and laid all over the tables, and I would encourage students to see if they could decrypt this particular message. So on the slide here, you see the same text that I have written on the strip of paper, but it can be kind of hard to decrypt this message. So take a look at it and see if you can come up with what this message should say. I’ll give you a hint. If you have a marker nearby, or something that’s about this big and round kind of dowel shaped, that might help. Still need a hint? Well, what happens if I take this piece of paper, and I wrap it around the marker like so. Take it and wrap it. Just like that. So now I’ve taken this message, and I’ve wrapped it around the marker. And you’ll notice that when you do this, the text kind of starts to line up, you can see that there are characters that start to line up. That’s what this is. This message is actually an example of one of the earliest forms of cryptography called a Scytale. A Scytale was round dowel rod, kind of like this marker that you could use to encrypt and send messages. And it was used all the way back in ancient Roman and Greek times. For example, if you wanted to send a message to somebody, you could take a strip of leather and wrap it around the Scytale, and then you would impress the characters of the message across the strip of leather on the Scytale. Then you would unwrap it, and you’d end up with a string of random characters that look something like this on the paper, and you could send that piece of leather out into the field. And of course, the only way to decrypt it would be to know how to decrypt it, and to have a Scytale that was the same size as the one that was used to encode that message. And so if you were very careful, you can use Scytale of different sizes to encode different messages using the same technique. So if we start with this message in the class, you realize that a Scytale is really just an iterative cipher, where we start with about every six letters. So we have this is a Scytale example. That’s what that message would say. Now, of course, you’ll notice I’ve added the letter Q in there a couple of times. And that’s actually very commonly done in the field of cryptography. As long as the message is understandable to the person receiving it when they decrypt it, you can add some random characters in there that don’t make any sense once you have decrypted the message, but it can really help foul up people trying to decrypt the message and use every single character in the message. It’s a neat little trick to make your encryption just that much more unbreakable.
There are lots of examples of early ciphers that have been used throughout history, we looked at one called the Scytale. There are also things such as substitution ciphers. A substitution cipher is where you take the letters in your text and you simply replace them one for the other. For example, all B’s become Q’s. All K’s become G’s, and so on and so forth. If you read the newspaper or do puzzle books, you might have seen a puzzle called a crypto quip. That is actually an example of a substitution cipher, and it’s one that was made popular by Edgar Allan Poe. Of course, putting your crypto equipment in newspaper might lead you to think that it’s easily breakable, and it totally is. One of the best ways that you can break things that are substitution ciphers is by frequency analysis. You look for the most frequent characters, and then you assume that those would be probably the most frequent characters in the English language. For example, in English were helped out a lot by the game show Wheel of Fortune. We know that the letters R S T L N E are some of the most frequently used characters in the English language. So if we find the most frequent substituted letters in our substitution cipher, we can try those characters and see what works. Also things such as short words, two letter words, things like that really helped break a crypto crypt very, very easily.
So then you get to more advanced ciphers called polyalphabetic ciphers. And these are like substitution ciphers, but much, much more advanced. For example, you would substitute letters not only based on the previous letter, but the position and all sorts of other things. Polyalphabetic ciphers were first described all the way back in the ninth century AD by the Islamic mathematician al-Kindi, but they were later explained in a lot more detail by French mathematician Leon Battista Alberti in 1467. So of course, once again, polyalphabetic ciphers can seem very complicated. But once you really discover how many different substitution ciphers there are in a polyalphabetic cipher, then it reduces the problem to simply breaking each of those individual substitution ciphers one at a time. So while they’re still powerful, they’re not nearly unbreakable, like we might think today.
Another example of an early cipher would be the tabula recta. A tabula recta, like you see here is all of the letters of the alphabet are arranged in a grid. And you can see that each grid shifts by one letter. Then with a table such as this, there are a lot of different algorithms you can use to encrypt data. For example, you could use the previous letter in the data to encrypt the next letter that you want to encrypt. So if we want to encrypt the word HELLO, we would start by using H to encrypt H. So we get H, but then the next letter E would be encrypted using the H line and it becomes L, then we use the next L to encrypt L. So we would encrypt L, which would be W, then we use W to encrypt another L, which becomes H. And then we use H to encrypt O, which becomes V. And so by following that process through, we can use the tabula recta to create a very, very hard to break cipher just by following an algorithm. And of course, you can do all sorts of different things with this and it creates a pretty powerful cipher, not one that is completely undecipherable. But it’s a very powerful way to do something using a very simple table such as this. And this is actually the same basis of things like the decoder rings that you might have heard about that were sold in cereal boxes years ago, they use the same basic idea. If you have the table or the decoder ring or whatever the ciphers key is, then it becomes very easy to break but without the key, you have to discover the key in order to break it easily.
In this module, we’re going to take a look at one great example of the use of cryptography in computer science. And to do that we have to go all the way back in history to look at World War Two. This slide right here shows the height of German occupation of Europe during World War Two. And during that time, the Germans were sending encrypted messages to all of their field commanders using a system that was very, very much thought to be uncrackable at that time. So we’re going to take a look at what that system is, how it works, and how the Allies were actually able to crack it by taking advantage of some of the knowledge that they had about such a system. Oh, and of course, some of this information would have been very much top secret, and a lot of it was classified up until just a few decades ago. So it’s really an interesting time to take a look back at what was going on during World War Two, and take a look at how the Germans were able to build a very interesting encryption system that was then later broken by the allies. So let’s start by taking a look at a quick video demonstrating the German’s Enigma machine and how it worked.
Watch through 5:50
I present to you the German Enigma machine. The Enigma machine was used to encode messages during World War Two. And it was a really interesting piece of equipment. It used several different rotors that were rotated to create a key for the encryption, and used a plug board and a keyboard for inputs. And so as we saw in the video with the Enigma machine, you would set the rotors to a particular key. And then when you press the key on the keyboard, and electrical current would go from that key, through the plug board, through the rotors, back out through the rotors, and then light up a lamp above. And so by pressing that key and holding it down, it would show you the letter that that letter should be encrypted to. Then, you would press the next key, another letter would light up, you press another key, another letter would light up. And each time you press a key, the rotors would advance one click changing the way that things were encrypted. And so of course, if you sat there and kept pressing the same key on the keyboard, you would notice that every single time you did that the letters that it would light up would be different every single time making you think that this is a very, very hard to break cipher. And indeed it was.
So as we saw, the Enigma machine consists of several rotors. Each rotor has 26 letters engraved around the outside, and it has 26 pins, each pin representing the input for one letter. And so you’d have a pin on one side, a whole scramble of wires on the inside, and then on the outside, you would have another contact that would go out. And so each pin was paired to one contact, but they were shuffled around randomly, so you really didn’t know how it was set up. And so of course, with just three rotors in the Enigma machine, that means there are over 17,000 possible combinations of three character positions of the Enigma machine rotors. So here’s an exploded view of showing the between the rotors where you have the pins on one side, making contact with the contacts on the other side. And so by sending an electrical current through one of the rotors, it would eventually go through the pins and contacts through each rotor until it would come back out the other side. And then of course, like we talked about, the Enigma machine uses a ratcheting system, very similar to an old analog odometer in an old car. Every single time you press a key, the ratcheting system would advance the outermost rotor, one click. And then of course, once that rotor has made a full cycle, it would advance the second rotor, one click, and then once that outside rotor has made 26 cycles, and the inner rotor has made 26 cycles as well, then the first rotor will be incremented one click. And so like it works just like an odometer, it’s very, very interesting the way they set this up.
But probably the most interesting fact is the way that the reflector works. So for example, let’s say you press the letter A on your keyboard. Then, it would go through the right rotor, the middle rotor the left rotor, and it would hit this special plate on the other end called a reflector, which would take that input on one pin and it would output it on another pin. Then it would go back through the rotors using a different path, and then it would hit the letter G and light up that light. But this right most rotor would then advance one position. So the next time you press the letter A, you would get an entirely different combination. You would have A which would go through this path, hit the reflector, come out this path, and then it would light up the letter C. So this makes decrypting messages really, really impossible. You never know what letter you’re going to get out based on the inputs unless you really know everything about how the position is set up. Finally, on the front of the Enigma machine, they included what’s called a plug board. And so what the plug board could do is you could swap the positions of two letters using these little wires. So for example, this system is set up to swap the letter S with the letter O and the letter J with the letter A. And so with this plug board, you can have up to 13 swaps, which gives you 10 million different combinations of keys that you might have to worry about. Of course, it’s interesting to note that the swaps are reflexive, so if J gets swapped with A, then A also gets swapped with J, so the same happens for both letters.
So all told, you have all sorts of different ways to set the key for the Enigma machine. You have the choice of the rotors and the ordering of the rotors. We saw three rotors, but toward the end of the war, there might have been as many as eight different rotors available that they could use. Then you have the initial position of the rotors. So the initial three letter key that the rotors were set to. You have the ring setting on the rotors, which shows where the rings go on the rotors, that way, it kind of changes the position a little bit more. And then you’d have the plugboard connections on the front, which are swapping different letters around. And so in theory, to understand how an Enigma machine is encrypting data, you would need to know all four of these things for each Enigma machine that you want to try and decrypt. And that’s a lot of information to keep in mind. Now of course, the other thing that they did is they had a specific operational pattern that they use when they were encrypting data using an Enigma machine. So the first thing they would do is they would set the wheels on the Enigma machine to the key from today’s codebook. The Germans carried around these code books that gave the keys for each day. And unfortunately, throughout the entire war, to my knowledge, not a single codebook was lost. In addition to the key settings, there was a particular way that the Enigma machines were operated. To operate an Enigma machine. First, they would set the wheels to the key from today’s codebook, the Germans used a paper codebook that gave different keys for each day of the year. And to my knowledge, those code books were not ever compromised during the war, they would always be burned or destroyed before any German camps were taken over. Secondly, the operator of the Enigma machine would then choose a unique key for the message. So they would choose a different key consisting of three characters for that message. So then they would use the daily key to encode the message key twice to avoid errors. So the first six characters of the message would be the message key encoded twice, then you would set the wheels to the message key, and start en crypting and sending the message. So not only did each day have a different daily key, but then each individual message used its own message key to send the data, so everything was really scrambled.
So if we look at this process, how do you think you’d go about cracking an Enigma machine? Take a minute to think about that. So obviously, the Enigma machine had many strengths. There were many different factors to the encryption, as we saw earlier. There were eight different wheels to choose from by the end of the war. And so depending on how you calculate it, there could be as many as 150 trillion different setups just from the plugboard itself. So altogether, it’s estimated there were 158 quintillion possible keys that you could use to decode an Enigma machine.
However, the Enigma machine came with very, very important weaknesses. The first and most important weakness was a letter would never encrypt to itself, because of the way the reflector worked on the plug boards and on the wheels. If you press the key A, you could press that key 26 times, and never once would the light for a light up because they were on the same circuit. And so with the reflector through the wheels, there was no way the current could come back through the circuit that it was sent out, which means that A would never light up for itself. Secondly, of course, the plug boards were reciprocal. And so by swapping two letters, you’re really just adding a substitution cipher on top of a really complex polyalphabetic cipher so the plug boards really didn’t do a whole lot in terms of making the combinations more complex, it just scrambled the letters a little bit. Another big problem they had was the wheels themselves were not similar enough, the wheels were so different, in fact that using some advanced mathematics, you could determine roughly which wheels were being used, just by the way the letters were distributed in the message that you received. And then of course, there were some poor policies and procedures around the Enigma machine. And one of the worst parts was the fact that they allowed message operators to choose the key. If your message operator in a foxhole during a war, and you’re asked to come up with three random letters all the time, every time you want to send a message, are those letters going to be truly random? Or are you more likely to pick some letters that have specific meaning to you like the initials of your loved one back home or your hometown, and they actually found out that that was a problem. A lot of German message operators were not picking truly random letters for the message keys. And then of course, they were encoding those same letters twice at the beginning of the message. So if you could decrypt the first three letters of the message, you had the message key that you could then use to decrypt the rest of the code. So that was not really that useful. So now let’s take a look at a second part of this video about how to decrypt a message that’s encoded with Enigma machine.
Watch through 2:40
The success for cracking the Enigma machine really comes down to the work of this man, Marian Rejewski. Marian Rejewski was a Polish mathematician who worked on the Enigma machine in the early days of the 1920s and 1930s. The Enigma machine was actually originally available as a corporate machine; you could go out and buy it as a corporation, and use it to encrypt and store data. And so it wasn’t until much later that was taken over by the German Nazi Party and used in their war efforts. And so public Enigma machines were available and could be studied. And so Marian Rejewski was able to study some of the early Enigma machines and try and predict the adaptations that Germany made as they move closer to war in the late 1920s and 30s. So based on his work, he was able to determine what the Germans were doing and was even able to eventually replicate some of the German machines that they had created. But of course, that was just part of the story. So to crack the Enigma machine, it was really first cracked by Marian Rejewski of Poland. He was able to use some of those publicly available Enigma machines to crack some of the earliest things that they did. By 1938, as Germany was getting closer to war, they added two new wheels of their own making it much much harder to crack if you didn’t know the wheels existed. And so Marian Rejewski of Poland contacted folks in England and gave them a lot of his research and ask them for assistance. And so by 1939, Alan Turing, working together with the folks at Bletchley Park, created what he called the Bombe, which was a machine that could decrypt the Enigma machine. And so work on the Bombe progressed pretty much throughout the entire war. And by 1945, almost every single message that the German sent using the Enigma machine, could be deciphered by the allies within two days. So what is the Bombe? The Bombe is a machine developed by Alan Turing to simulate hundreds of Enigma machines side by side. You can see that it has all of these sets of three wheels, simulating the three wheels that might be present in an Enigma machine. And it was designed to explore many of the weaknesses and other facts about the Enigma machine that were known to the Allies based on the work of Marian Rejewski and Alan Turing at that particular time. So let’s take a look at a quick video of a Bombe in action just to see what it looks like.
Of course, the impact of cracking the Enigma machine cannot be understated. It’s probably best put by Sir Harry Hensley, who is a British intelligence historian. And he wrote, “My own conclusion is that it shortened the war by not less than two years and probably by four years … we wouldn’t have in fact been able to do the Normandy landings, even if we had left the Mediterranean aside, until at the earliest 1946, probably a bit later.” So really, the ability of the Allies to decrypt and decode the German messages sent via the Enigma machine was really important toward ending the war effort. And it’s almost unfathomable to imagine how bad World War Two had been, had it gone on for two or even four more years. And, of course, this is just focusing on the work in the European Theater. There was also another program called Ultra. It was based in the Pacific Theater, focused on decrypting some of the Japanese messages that were sent during World War Two. And so later on, we may add some videos to this module discussing that program, as well.
But let’s move into modern days and talk a little bit about Claude Shannon again. We’ve talked about Claude Shannon several times in this class before, but one of his most lasting claims to fame is as The Father of Modern Information Theory. And his work after the war really helped build the modern cryptography systems that we use today. He realized that there was a very mathematical way that you can encrypt data so that it could be very, very difficult to decrypt that data without understanding the keys used to build it. So because of a lot of his work in the 1950s, we refer to Claude Shannon as The Father of Modern Information Theory.
So one of the modern forms of encryption is called symmetric key encryption. And in symmetric key encryption, we take some sort of data such as the plain text hello world, and we encrypt it using a very particular algorithm and a key. And so the algorithm uses the data that we want to encrypt and the key, and it will produce what’s called ciphertext. And so the ciphertext is the encrypted form of the data that we can send and receive and do everything we want. And then to decrypt it, we would use the same key and sometimes a similar algorithm or a slightly different algorithm to get back to the plain text. So symmetric key encryption does have some advantages and disadvantages. One of the biggest things to remember with symmetric key encryption is that it uses a shared secret key. Both the person encrypting the message and decrypting the message need to have a copy of the key. And so that creates this interesting problem of how do we share the key without knowing that someone else got ahold of the key. And likewise, if we encrypt something with a shared key, and the other person has lost that key, then we may not know who has access to that data, making it really kind of complex. However, shared key encryption and symmetric key encryption does still get used from time to time. Most of the time, it’s used for file encryption, things like encrypted zip files, usually use symmetric key encryption. You use the same password to encrypt them as you use to decrypt them.
The other form of modern encryption that we’ll talk about is public key encryption. And public key encryption is a little bit more complex because it uses two different keys. So we start by generating two keys, a public key and a private key. The private key we keep for ourselves; we don’t give that to anybody else. A lot of times the private key is unique to a particular computer itself. Then we would give our public key to anybody; it’s public. We could tattoo it on our forehead. We really don’t care because that’s the public key. Then, anybody that wants to send us encrypted data, could take their data and lock it using the public key that we have made public available. And as soon as they lock it with that public key, the only person that can unlock it is the person with the matching private key. And so if they want to send something that only we can read, they lock it with our public key, and then we can unlock it with our private key. Likewise, we can go the other way, if we want to send something out to the world and have the world know that it came from us, we can lock it with our private key and post it out on the web along with our public key. And so anybody that wants to can look at that data, unlock it with our public key. And as long as they trust that that’s our public key, they know that we are the only person that could have sent that message. This is how things such as email signatures, the actual like signed signatures work. You can also do this on websites. If you look at your websites, they’ll have a lock that usually says it’s encrypted. And part of that is that the data is encrypted, but also part of that is that it’s verified that we know where that data is coming from using a process based on public key encryption. And then of course, we can combine the two. For example, if we’re sending our credit card data back and forth with a website, we can use their public key, and they can use our public key in very unique ways. For example, if we want to send our credit card data, what we could do is we could lock it using their public key so that they are the only person that can read it. But we can also sign it with our private key so that they know that the only person that could have sent that data is us. And so by combining the two, we can get both protected data, and we can get it signed and verified so we know where it came from. So let’s take a look at a quick video on Diffie-Hellman key exchange, which is how we can actually share keys back and forth and make sure that both users have a key that they can use to encrypt data.
In the video, the values of d and e are swapped at one point. Thankfully, this doesn’t matter since they are commutative and can be used in any order, but it is a bit confusing. We’ll correct this video in the future!
Let’s take a look at one modern form of encryption called RSA encryption. RSA was developed in 1977, and it was named for the three creators- Ron Rivest, Adi Shamir, and Leonard Adelman. RSA encryption uses the product of two large prime numbers to generate a key that’s used to encrypt data, and the strength of the key really depends on the difficulty of factoring that large number back into its two prime numbers. So for example, if we say our key number is 1071. Can we factor that into the two prime numbers? We could do it eventually, but we’d have to check a lot of different numbers to see what it was. So now imagine that 1071, instead of being a number with just four digits, was a number that had 64 digits in it. That’s really the size of the prime number products that we’re talking about when we do RSA encryption. And so really, the key to RSA encryption is the fact that it’s very, very difficult to factor a large number like that into the two unique prime numbers that are used to create it. So let’s take a look at how RSA encryption works to see why that’s important and why it can create a system that is easily broken if that rule doesn’t hold.
So for RSA, we start with two numbers, p and q. So I’m going to start out with p is five, and q is 17. So we’ve created two distinct prime numbers five and 17. Next, we will compute their products. So the product is n, which is equal to p times q, which is five times 17, which is 85. The other thing we’ll need to compute is Euler’s totient. And the totient of two prime numbers is actually just the number minus one. So to calculate Euler’s totient t, we would do p minus one times q minus one, which is going to be four times 16, which is 64. So we have p is five, q is 17, n is 85, and our totient t is 64. So let’s write that here. Again, we have p is five, q is 17, n is 85, and t is 64.
Now, here’s the really complicated part. We need to choose the number e less than t that is coprime to t so that they share no common factors. Then, we calculate d as the modular multiplicative inverse of e. So that e times x is equal to one mod t. This is really complex mathematics, but what it really means is we need to pick a multiple that is one more than a multiple of t. So if t is 64, we’re looking at 65 129 193, etc. So we’re finding multiples of t, 64, an adding 1, 65. 64 times two is 28, so 129. 64 times three is 193. 64 times four is 256. So we’d look at 257, etcetera. And then we choose one of these that we can factor. So let’s look at 65. Can we factor 65 into two numbers? It turns out we can. So if we set d equal to five, and e equal to 13, we get 65. And e is less than t, and it’s coprime to t. Specifically, e is prime, which is great. Two number are coprime if they don’t share any common factors other than one. And since 13 is prime, it’s also coprime to any other number, which is what we want.
So now we found d and e, which are the keys that we actually need to send and receive our ata. So let’s look at our RSA keys. We have two keys, our public key, which is going to be n and remember and n is 85 and e is five. And then we can encode using this, and we have our private key, which is 85 and 13. So let’s take a look at an example to see how this would work. If we want to encrypt the message 42, what we would do is we would take 42 to the power of five, and then we would do mod 85. So remember, the modulo operation means we divide by 85 and we keep the remainder. So if we actually do this on a calculator, you’ll find that this is equal to 77. And if you have a calculator handy, you can try this yourself. So 77 is the message that we can send as an encoded message. On the receiving end, we would take our encoded message 77, raise it to the power of 13, mod 85. And sure enough, if you calculate 77 to the power of 13, and you might need Wolfram Alpha to do this, then mod 85, you will get back the original message 42. That’s how RSA encryption works. It’s really, really simple. It’s mathematics with a little bit of flavor on top of it to make the keys.
Now, here’s the really tricky part. How do we break RSA encryption? Well, let’s take a look at our keys. Right here in both our public key and our private key, one part of that key is 85. What was 85? Remember that 85 is equal to our two prime numbers, p and q multiplied together. And since p and q are both prime, there is only one way that 85 could be factored. There are no other possible factors. And we know that we use five and 17. So if anybody can factor 85, into five and 17, then they can create t, because t is going to be four times 16, which is 64. And then using t if they have either e or d, they know that e times d would be one more than a multiple of t. And once they have that they could deduce the other half of the key. That’s what’s really important here. So RSA only works if this particular operation is very, very expensive. So to do RSA encryption, we choose numbers p and q, such that they are very, very large. And like I said, we’re talking hundreds of bits, we’re talking multiple digits long, and that’s why there’s so much computing power spent on the search for larger and larger prime numbers. Because for RSA encryption to work, we need those larger and larger prime numbers in order to construct RSA keys that we can use to send and receive data.
This is also really important later on when we talk about concepts such as computability. For example, we’re making an assumption here that the only way to factor a very, very large product of prime numbers is trying all possible prime numbers less than that number. So it’s simply brute force. Now, if we wake up tomorrow, and some mathematician has devised a better algorithm for factoring large products of prime numbers into their two primes, then all of the RSA encryption on the internet isn’t as secure anymore, because now there’s an algorithm that can do that quickly. Another fear would be that quantum computers could do this. And so if a quantum computer discovers a way to factor large products of prime numbers very quickly, it could have the same effect on RSA encryption. Now, of course, this is just one example of one encryption algorithm, but it gives you an idea of the fact that modern encryption is really built upon these ideas that there are very difficult calculations for somebody else to make if they don’t know the original numbers, but those calculations can be made very quickly for us if we know the original numbers that we used to build that key. So I hope this has been really informative. I really encourage you to try RSA encryption for yourself. It is very fun to do the math behind this. And just to see that it works exactly like you’d expect. You can go back and pick any two prime numbers for p and q, and go through this process. The hardest part is finding e and d. But there’s some really great helpers online that you can use, and I’ll link to one of those after this video so you can play around with RSA encryption yourself.
Nine Algorithms that Changed the Future Ch 4 - Public Key Cryptography
Nine Algorithms that Changed the Future Ch 9 - Digital Signatures

In this module, we’re going to discuss a lot of topics related to cyber security. Cyber Security is another important research area in computer science, and it’s one that directly impacts a lot of computer users in their daily lives. So in cybersecurity, we really are asking ourselves one big question, how do we keep our data secure, and that’s really all it comes down to. We’re trying to secure data both on our computers, but also as we transmitted across the Internet, and any other communication technologies we might be using. And so we’re going to talk about some different ways that we can keep our data secure on our computers.
Before we get into that, a word of warning, I’m encouraging each of you to put your white hat on when we talk about this. So in computer science, we talk about different types of hackers. And typically, you have the black hat hackers, which are the ones that do so maliciously. But you can also have white hat hackers, which are hackers that use their skills for benevolent means– to help companies find security holes in their infrastructures and hopefully patch those holes and become a little bit safer. And so some of the things we’re going to talk about today, if used maliciously, could be very illegal, they could be felonies, they’re very, very dangerous things for you to use maliciously. But as a computer scientist, it’s important for you to understand those topics so that you can defend against them and know what they are in case they get used against you. And so I’m encouraging us all to put our white hats on at this point, and come at this topic from the view of doing this for the good of everybody else and trying to help them secure and protect their data. Okay, let’s get started.
First, we need to talk about authentication. Authentication is a very, very important part of anything in cyber security. And authentication mainly deals with a few things, it’s determining if the person is who they say they are. So when you sit down to a computer, and you type in your password, that is a form of authentication. You’re letting your computer authenticate the fact that you are who you say you are. Now, typically, authentication requires three different factors. There are ownership factors, which is something the user has. For example, an ownership factor could be a physical key to a building, it could be a USB drive that has a token on it, or it could be some other symbol or some other device that the user has to authenticate that they are who they say they are. A police badge, for example, is a form of authentication that authenticates who that person is. The second one we can talk about is knowledge factors. A knowledge factor is something the user knows that authenticates themselves. Typically, we think of this as passwords and pin numbers or anything else the user has memorized. But it could be even other facts such as birth dates, and mother’s maiden names, and social security numbers, things that the user would know very quickly. Those are what makes up a knowledge factor. And for most computer systems, we use knowledge factors as the primary form of authentication. The third form of authentication is an inherence factor. And an inherence factor is something the user inherently is. An inherence factor would be things such as a retinal scan, or a fingerprint scan, or DNA test, something that these are really can’t change about themselves.
And so to authenticate a user in a computer system, we typically use one of these factors at a minimum to authenticate them. There is also something called multi factor authentication or two factor authentication, which you’ve probably come across, especially if you do online banking or play certain video games. And that is pretty much exactly what you think it is, it is two different factors of authentication combined to provide greater security. And typically, they combine something the user knows, such as a password or a pin number ,with something the user has, such as a credit card, or in a lot of cases, it’s access to a mobile phone or an email account. And that is something the user has or possesses as the second factor of authentication. So think about some places that you run into two factor authentication, video games, online banking. At K-State, a lot of faculty and staff now use two factor authentication whenever they authenticate at K-State. But a big question to ask yourself is, would you as a student like to have two factor authentication on your K-State account? Why or why not? Do you think it’s worth the extra security to really protect all of your important academic records? Or is it just an extra hassle if you have to get your phone out every single time you want to log in? Currently, for faculty and staff, we log in with our phones, but then we can have it remember our device for up to 10 days before we have to do that two factor authentication again. So it’s a little bit extra hassle, but it’s not super inconvenient if we’re using the same computer day after day. But I could see if you’re using lab computers and have to authenticate every single time, that might be a little extra hassle for you. So it’s something to think about.
So in this lecture, we’re going to hone in on one of the most common authentication factors, which is the use of a password. A password is a very traditional system used to authenticate users on computer systems, on websites, just about anywhere. But I think there’s a lot of misconceptions about how to make secure passwords and how secure passwords really are. And so we’re going to rely on some information to really look at passwords and how they can be made more secure and some of the ways that they may be are less secure than we thought. So this is a comic from XKCD. It’s one of the great comics that he does. And here, he’s talking about how we make a particular password. And we’re going to come back to this comic. But here he shows a pretty common password, we start with an uncommon, but non jibberish word, then we add like a number and a punctuation because almost every website, you need to have at least a number and a punctuation. And we do some common substitutions from leet speak so zeros for O’s and fours for A’s. Usually we have caps and 99% of the time, if you’re going to capitalize the letter, it’s going to be the first letter of your password. So what we have is we have a password here that has a few different bits of entropy. And in fact, if you calculate it out, there’s just about 16 bits of entropy in this box. So that means that there are roughly 65,535 different ways that you could build a password. Based on these rules. You choose a word, you add some numbers, and punctuations, and substitutions and things. And so 16 bits of entropy, that sounds pretty powerful.
But how would we go about cracking this password? What would that look like? So let’s look at some different ways you could possibly crack this password. Obviously, the first thing you could do is you could try brute force. You start with aaaaaa, that didn’t work aaaaab, that didn’t work, and so on. And so brute force hacking does work in certain scenarios, especially for things like combination locks. If you’ve ever done a an escape room, one thing you might realize is they give you those combination locks with four dials on it. And hopefully, you’re smart enough to realize that if you only get three of the four dials, and you can’t quite figure out the fourth one, you could brute force it in about 10 seconds. So you really don’t have to get all of the dials, you can just brute force a little bit. And so with combination locks and things, sometimes it’s very, very easy to brute force them. And in fact was simple passwords like old websites that required your passwords to be eight characters or less, you could actually brute force a password very quickly. For example, here is a six character password, there would be about 308 million different six character all lowercase passwords. It seems like a lot, but if we try it about 1000 a second, which is pretty, pretty common. I mean, even on a bad website, you could try 1000 passwords a second, it would only take us about three and a half days to crack that password. And in the grand scheme of things, three and a half days is not that long.
So let’s look at another way. How about things like rainbow tables. For example, this slide shows the 25 most common passwords used on the internet, according to some research done by Gizmodo a few years ago. And looking at this list, it is pretty disappointing. You’ll see passwords such as 123456, or 123456789. But you’ll see things like sunshine, qwerty, iloveyou, admin, abc123, certain profanity words. And so these passwords are really not all that great. And in fact, it’s really easy to go online and find some of the most common passwords that are available. Another thing that we can look at is what’s called rainbow tables. And so a rainbow table is actually a password lookup table that is calculated all of the protected versions of these passwords. For example, on older versions of Windows, when you set your windows password would actually be stored in the Windows registry using a hash. And so a hash, if you remember from our previous module is an algorithm that takes a piece of text and converts it to a number using a one way algorithm. And so the theory is if you type in the same password and go through the same hash algorithm, if you get the same output, you know, they put in the right password. But of course, what you could do is put in all possible passwords and store all of the possible hashes and create a table that matches them up. And so that’s what a rainbow table is, it basically creates a rainbow of all the different possible password combinations and the hashes that those create. And so if you have a Windows computer, an older Windows computer and can get the password hash out of the registry, you can go online to these websites that have rainbow tables and just put in that hash, and they will look up the password for you or at least a password that creates that hash. And so for a lot of really bad algorithms such as the early windows algorithm, there are some algorithms such as MD5 that rainbow tables are created for, you could just go out and look up a password based on a hash.
So between brute forcing common passwords and rainbow tables, there are a lot of different ways that you can crack really easy passwords. So let’s go back and look at that password example we saw earlier and talk about entropy. So he calculates that there would be about 28 bits of entropy in a common password there and 2 the 28 to get about three days at 1000 guesses a second. It’s really similar to what we saw with brute forcing, even though it’s a much longer more complex password, but it’s actually pretty easy to break a password like that. Now, here’s the hard part. Can you remember what that password was on that slide a few minutes ago? Don’t Look, don’t rewind the video and look, but see if you can write down that password that we saw earlier. Did you get it? Now you can go look and see if you got it. And so it turns out that we’re creating passwords that are really easy to actually crack if we understand the structure of the password. But it’s very hard for us to remember is it’s troubadour with an & and a three, but I don’t remember exactly what order so it’s hard to remember.
And so what he’s arguing here is we’re creating passwords that are basically easy to crack and hard to remember, what we really should focus on is creating passwords that are hard to crack, but easy to remember. How do you suppose we would do that? It turns out that to make more complex passwords, there is exactly one rule that you need to follow. And that is make them longer. That’s it. No special characters, no capitalization, punctuation, lowercase, uppercase, numbers, symbols, foreign words, does not matter. The only thing that matters to make your password more secure, is making it longer. So here we have four random common words, you start with 1000 common words in the English language. So that means you have about 10, or 11 bits of entropy per word. And you pick four of them correct horse battery staple. purple monkey umbrella dishwasher. very, very simple. All you have to remember is those four words, and I can even go out there and say, here’s a list of 1000 words. And my password is four words separated by spaces. And that right there would have 44 bits of entropy. So even if I gave you the list of words and told you exactly how my password was set up, it could take you 550 years to try all possible combinations of that password at 1000 guesses a second. That is much, much harder to do. But it’s very easy to remember, you probably already remember that password correct horse battery staple. It’s very easy to remember.
And so the whole idea behind making secure passwords, we see a lot of websites today that tell you you have to have a number and a symbol and special characters and whatnot, doesn’t matter. The only thing they should do is set a minimum password requirement of 20 or 30 characters and just tell you to make a long password. That right there will make your password more secure with a big asterisk on it. Understand that when we talk about security here, we’re only talking about security based on cracking the password using some sort of brute force method or some sort of dictionary based method. We are not saying that that password is secure against all attacks, for example, correct horse battery staple, if you write that down on a post it note and stick it under your keyboard, it would only take somebody about two seconds to read that password off of the post a note and remember it instantly. There’s nothing special about it. And so just because it’s easy for you to remember doesn’t mean that wouldn’t also be easy for someone else to remember. Likewise, if you don’t pick four random words, if you pick four words like your four grandparents or something like that, like their names, that could be much easier for people to crack. And so while it’s uncrackable from a computer standpoint, there are other parts of cybersecurity that we’ll get into a little bit later that make this password maybe less secure than what you want.
So finally, let’s talk about storing passwords securely in your applications. And there are a lot of different ways you can store passwords so that users could use them to authenticate. Let’s take a look at that. First, obviously, we could store the password itself. The user types in a password, we store that password in the database. Great, right? They type that password in again, we check it to make sure they typed in the same password. If they did, they let them in. That sounds like a really great system, doesn’t it? Hopefully, you’re cringing a little bit thinking about this. Because obviously, websites that have databases on them get hacked all the time. And if a hacker gets access to this database, they have your password. Simple as that. There’s nothing that they have to do, there’s no decryption they have to worry about, they get your password. And of course, one of the weaknesses of people on the internet is we tend to use the same password over and over again. Raise your hand, if you do that. I do. I use the same password a lot of places on the internet, it’s something I probably shouldn’t do. But I do. And so if somebody gets one of my passwords, they might be able to use that password to log into other websites that I use that same password on. So this is obviously not very secure. And the only thing that they need to compromise this is database access. As soon as they access the database, they have all the passwords, and it’s really simple so we probably shouldn’t do this.
What if we store the passwords by encrypting them using a key? Well, that makes them a little bit more secure, which means now if you get the database, you also need to have a key to decrypt the passwords, or of course, some sort of a lookup table or a rainbow table to decrypt the passwords. And so you know, as soon as they get the database in the key, it would compromise all the accounts. So this is better than storing the raw passwords. But it’s still not great. And it’s not that hard.
The really best way to store passwords is using what’s called a password salt. And this is because users are generally bad at creating good passwords. And so what we can do is take their short, crappy passwords and add a long string of random characters to it before we encrypt it. And so that will make the encrypted password much much stronger, it will feel like a longer password, even if the user’s portion of that password is very short. So it protects against all sorts of things like dictionary or rainbow table attacks, Rainbow table attacks assume that passwords are pretty short. Most rainbow tables only work on passwords that are 10 characters or less. So if we add a salt of 25 characters to the end of a password, we’re guaranteed to get something that’s pretty long and hard to break using just standard encryption attacks. So if we store with a global salt, which means that we use the global salt value, the same salt value for all passwords, then a hacker would have to get the database, the encryption key we used, and that global salt value. And the nice thing is those are typically stored in three different places. The database is stored, obviously, as the database. The encryption key is probably stored somewhere in the software, and the salt value is probably stored somewhere in the software’s configuration. And so you need to get all three of those parts to break these passwords. If you didn’t have the encryption key or the salt value, you could try and brute force it, but it would take a long time. The downside is once you brute force a password, you could get the key and the salt and use that to compromise all the other accounts. So if you get one, you still get all the accounts compromised, but it is a little bit harder to do. The other thing you can do, of course, is you can encrypt all the passwords with a unique salt value. So every single user, every single account gets its own salt value. And if you do that, you need the database encryption key and the salt value for each user account in order to crack it. And that makes it even much harder. That means you can only compromise one account at a time, because every single time you need to get that salt value for that account. And so that makes cracking these passwords really, really hard to do.
So lastly, let’s take a look at one of the instances where people have really broken passwords very, very quickly. And this is from the Adobe hack from several years ago. And again, this is an XKCD comic. But what happened is Adobe misused an algorithm called block mode ds. And what that does is every block of your password gets chunked up. So every eight characters or so it gets broken, and it gets encrypted separately. And because they did that incorrectly, if the user had the same password in that first eight characters, it would encrypt to the same thing. And so what you end up with is basically the world’s largest crossword puzzle. So for example here you would have weathervanessword and then you have name one. If you’re a fan of redwall, you might understand that weathervanessword might have something to do with Matthias from redwall and so this might be Mateus1. Here you have favorite of the 12 people apostles - Matthais, and then you have all these other ones like alphaobviousmichaeljackson. I’m guessing this is ABC123- the famous Michael Jackson hit from when he was in the Jackson5. It’s an obvious password, and it’s alphabetical. So there are lots of different examples of bad passwords, being stored improperly not correctly salting and hashing them like you should and this is one that Adobe definitely got called out for back in the day. So finally, if you want to take a look at your own passwords and see how secure they are, there’s this website howsecureismypassword.net. You can go online you can type in your passwords and it will give you an idea of how long it would take to crack that password.
Another area of cybersecurity that we should discuss is social engineering. Social engineering is all about using techniques to compromise the system by exploiting the users directly instead of the system security itself. And this is a really important concept. There’s an old saying, in computer science that a system is only as secure as the users that use that system. It’s kind of a play off the idea of a system is only as secure as its weakest link. And in most cases, the weakest link is the user itself. And so on the next few slides, we’re going to take a look at some different ways that you can use social engineering, to maybe break into a computer system and what those things look like so that we can defend against those. So a great example of social engineering is trying to get some information from somebody that they don’t want to give. And a great example of that would be a bank account number. So if I wanted to get someone’s bank account number, how do you think I could go about that using social engineering? Take a minute to think about it. So while this example may not work that well in today’s world, because not many people carry around checkbooks. If you have a checkbook, look at your checkbook at the bottom of your checks, and see what’s printed there. Hopefully, you should realize that printed at the bottom of your checks are two numbers. One of them is the routing number that identifies your bank, and the other number is your bank account number. And so I think one of the best ways to do this was actually discovered by Gru in the movie Despicable Me selling cookies. He had his girls sell Girl Scout cookies, and as long as he said, “Oh, I can only accept checks.” A lot of people might not think twice about writing a check for a Girl Scout troop, but that check includes your bank account information. And so with a little bit more work, you could probably use that information very nefariously against the people that wrote those checks. So even though it’s something that we don’t really think about giving out very often, it’s right there out in the open if we know how to get it.
So let’s take a look at some examples of social engineering and see what those look like. First and foremost is the idea of pretexting. Pretexting is calling or going somewhere and pretending to be someone else. And you see this a lot of times done in movies where the bad guys will come in and pretend to be exterminators so that they can gain access to the back room of a bank. But you could do it just as easily by calling someone and pretending to be their insurance agent. This happens at K-State all the time. Department offices get calls asking for information, like who’s in charge?, who’s the department head?, who buys your supplies? And then they will call back later and say, Oh, yeah, so and so said that you should buy the supplies from our company. We’re just checking the follow up on the order. Even though no order was made. they now know who’s in charge, who makes the decisions, and they’re hoping that they get somebody else that is like, oh, yeah, that sounds reasonable. And they’ll just approve it. So by pretexting a little bit, you can gain access to systems that may not work very well, otherwise. Of course, pretexting is very closely related to impersonation. Impersonation is calling is simply pretending to be somebody else. So with impersonating, I could impersonate one of my students, I can impersonate somebody else and try and get access to their systems. And this also happens every once in a while. For example, there were a couple of instances in the news where somebody got a call from somebody pretending to be their boss’s secretary, and giving them new instructions for how to transfer money. And as soon as they transferred the money, of course, they were transferring it to the attackers, and the money was gone before they even realized what was going on. And of course, that person immediately realized their mistake called their boss directly to double check on the transfer. And obviously, the boss had no idea what was going on, and the money was already gone. And so impersonation is another really strong attack vector in social engineering.
There’s also something called the human buffer overflow. So take a minute and try and read every single word on this page using the color that the word is written in. So it would start with green, red, blue, yellow, blue, black. You have to think about it. And in fact, if you try and go really, really fast, you’ll probably find that you start reading the words instead of saying the colors. This is an example of the human buffer overflow. And so what you can do is by desensitizing people by getting them thinking about other things, you can trick them into saying something or revealing something they wouldn’t normally do. A great way to do this is to have people do a few math problems, such as asking them what’s two plus two? What’s four plus four? What’s eight plus eight? What’s 16 plus 16? And then ask them to name a vegetable. And for a lot of humans, they will immediately answer carrot. Likewise, if you ask them to name a tool, it will probably be a hammer. If you ask them to name a number between five and 12. It will be seven. Seriously try this get some people to do some math problems and get them thinking logically and then ask them some of those random questions. And I think you’ll be really surprised if they don’t take a minute to think about it. Their knee jerk reactions are probably carrots, hammer, seven. It’s worth trying. So that’s one thing you can do.
Another one is definitely quid pro quo. This is a ransom attack. Very famously here in Kansas City, the company, Garmin, was recently attacked by ransomware. And so that’s a quid pro quo attack, they took something they encrypted all of their systems, and then basically held it for ransom and said, if you don’t give us money, we will not decrypt the systems. And so quid pro quo is a very, very powerful attack that is gaining a lot of popularity out there. You’ve seen it done to governments, to hospitals, to large companies. It can be really devastating if they don’t have the proper techniques in place to deal with such an attack.
But there’s a lot more mundane ways that social engineering can happen to. You can have phishing attacks. This is a phishing attack that I got a few years ago from K-State, or at least it looked like it’s from K state, asking us to send some information. So let’s take a look at this email and see what we think. So first, we see that we got this email from accountupgrade@ksu.edu. It looks pretty legit. It comes from the Kansas State University webmail team. Yeah, that looks right. But then we start reading “due to the congestion in all ksu.edu users and removal of all ksu.edu capital accounts copyright Kansas State University be shutting down”. If you start reading this email, it doesn’t really quite jive. It doesn’t have really good English in it. And then of course, at the bottom, the obvious thing is to ask you for your first name, last name, email address, your username, your password, your password again, just to make sure you got it right, and your eID. And this is kind of interesting. Most people outside of case they don’t even know what an ID is something that’s unique to K-State, but they at least knew to ask for that particular question here. Although the ID, the username, and your email address are all going to be the same thing. So while this is a pretty good phishing attempt, it’s not a great one. But every year these phishing attempts, they can compromise hundreds of casing email accounts every single year.
Likewise, you get these scams, these are known as 419 scams, but you get these all the time. Usually, it’s something where they say that you have won some large amount of money, and they need some information from you to send it to you. And a lot of times they only ask for a few thousand dollars. They’re called 419 scams, because that’s the section of the Nigerian criminal code that makes these illegal. And a lot of these are at least said to originate from Nigeria. This one is from Ivory Coast. And this also is a real one that I received a few years ago when I put on these slides. And so this is a form of what’s called advance fee fraud. They claim to have a large amount of money that they want to send to you, but they can’t quite do it. And so they need you to send just a little bit of money to them so that they can get your money and send it back. Obviously, all of these are fake. But there are many stories online that you can find people that have been scammed for several thousands of dollars or 10s of thousands of dollars by scams, such as this.
Another form of social engineering you might run into is baiting. Baiting is leaving something out there and hoping somebody goes for it. And a great example of this is flash drives. Let’s say you’re walking across campus and you find a flash drive like this laying by the sidewalk. What’s your first instinct? Do you pick it up and take it to the nearest computer and plug it in and see if you can figure out whose it is? Well, if you did that, you might have just infected that computer with a virus that was put on this flash drive. And this is actually a really common form of social engineering. In fact, this has been used as a white hat technique to protect a lot of companies and companies routinely fail this. They put a few flash drives out in the parking lot. A person finds a flash drive. “Oh, I should be a good person and see who this is.” And they immediately infect their company with a virus. And so when you find flash drives like this, especially flash drives that you don’t know where they came from, the best thing you should do is give them to an IT professional and let them deal with it. A lot of times they have systems specifically set up so that they can plug in unknown data devices and make sure that they’re done securely, and won’t infect the system.
And then of course, it’s also important to mention that social engineering does include threats, this XKCD comic once again, does a really good job of describing this. Crypto nerd might think, oh, we’ve got a computer encrypted with a password, let’s build a million dollar cluster to crack it. But in actuality, let’s go get a $5 wrench and just beat this guy over the head with it until he gives us his password. And so you really have to understand tha while there are a lot of very sophisticated systems to protect our computer systems. Sometimes direct threats are something that you have to think about. And that’s something that is really kind of uncomfortable to even think about in the field of cybersecurity. But it’s something to bear in mind that sometimes a direct threat like that is enough to crack a system.
So now that we’ve talked about all these different ways that social engineering can happen, let’s talk about some ways that we can combat social engineering. First and foremost is user training. We need to do a really good job of training our users how to spot these scams. And this happens all the time. You have to train them how to watch for phishing scams and email scams. You have to train people to talk on the phone to listen for phone calls that are trying to solicit more information or trying to fake something out. You have to ask them to be questioning if somebody walks in and claims to be an exterminator. Who called them? Do they have an invoice? Do they have an appointment? Are we expecting you? things like that. All of those fall under user training, we also need to have really good security protocols and audits. We need to make sure that if there is something secure, that we keep it secure. And a security protocol could be as simple as if you’re in a building where you have to swipe your key card to walk in the door, you don’t hold the door open for somebody else. That’s a great form of social engineering is standing outside smoking, and then being like, oh, I forgot my badge can you let me in? And if they’re not thinking about the protocol, they’re just like, sure, I’ll let you in, and you’ve just gained access to a secure building. So having those protocols and audits in place is also really important. As we mentioned earlier, as a user, you should always be a little skeptical, you should always be questioning everything. If you get an email that looks weird, a phone call that looks weird, somebody comes in and is acting suspicious, that little bit of questioning and being on guard can really protect you against a lot of social engineering. You can also perform penetration testing, a lot of companies do this where they will send out fake scam emails, and then anybody that responds to that email has to go through a security training. They can hire companies to try to come in as white hats, and try and break into the building, or talk their way in, or do all sorts of these cool things. And so by penetration testing, you can find those weaknesses in your protocols and make sure that you secure those. Finally, you can also work on properly disposing your garbage. Obviously a lot of social engineering can involve dumpster diving. You pull papers and invoices and things out of the trash. And so if you’re not thinking about that, that can be one way that people can gain a lot of information about your company. And so if you’re even at home, you should be shredding your bank statements or credit card statements cutting up your own credit cards, just in case because there’s a lot of information that can be gotten just from a trash bag that’s left outside.
So finally, let’s talk a little bit about social engineering in practice. Every year there is a DEF CON cybersecurity convention that’s held every year in Las Vegas. And several years they have done what they call a capture the flag style contest. And the whole idea is contestants at that contest try and gain information about companies via the internet first. And then using that information, they will just call the company headquarters and attempt to gain more information or flags for points. And those five could be as simple as what web browser do you use? What version of Windows do you use to who’s your exterminator company? who’s your catering company? All of these pieces of information can be used to construct a really in depth social engineering attack on a company. And so the report is actually quite staggering how a lot of different companies did really, really poorly at this. Obviously part of DEF CON is they went out and asked these companies for permission. Nobody gave them permission to do this. They did it anyway. That’s kind of how DEF CON works. So if you’re interested, I encourage you to read the report. We will link it after this video. It’s really quite fascinating to see what they were able to learn by doing social engineering.

Welcome back everyone. In this video, we’re going to be taking a look at artificial intelligence. But before we get to the artificial part, what is actually intelligence? So what does it mean to be intelligent? This is a question I ask all of my students from the kindergarteners that I do outreach with all the way up into college classes like this, and I get a very wide range of responses here. And usually the default answer that I get is intelligent means someone is smart, right? But it’s not necessarily always the case, right? A person who’s smart or has an high IQ is capable of doing math, really good at remembering information, and creation of information. But it’s not necessarily intelligent behavior. So intelligence involves a lot of different things, including reasoning and problem solving, which of course, smart people are able to do those things as well. Our ability to reason to a certain degree and problem solved to a certain degree is definitely an intelligent behavior. When you encounter a situation in you’re environment, and you reason and solve that particular problem to get around that particular obstacle. And we see these types of behaviors and all sorts of beings, right? Not just humans, but it is documented quite frequently in the animal kingdom as well. Intelligent behavior also involves our ability to construct knowledge, right? So as we learn from our environment, right? Learning is also another intelligent behavior. But as we start to interact from our environment, we’re going to gather data, information, things that we see, taste, hear, touch, all of those things, our ability to perceive from our environment, which is also an intelligent behavior, our senses, but that information needs to go somewhere, right? An intelligent being like an animal or human is going to be able to take that information and construct knowledge to a certain degree.
Now the level of intelligence can impact what kind of knowledge that can be constructed, probably some of the most basic ones, right? Even my kid right now we have those buckets, right, that have little different shape holes on top, and you have a bunch of different blocks. So the square block goes into the square hole, and the star block goes into the star hole. And it takes a little while, right? That is information that you can kind of get from trial and error, trying to put the square block in a triangle hole isn’t going to work out very well, but eventually you’ll figure out that, hey, the square goes into the square hole, and so on. Right? So that is one of our base forms of being able to construct knowledge and learn from our environment. Our ability to perceive also impacts our ability to learn and construct that knowledge. So the first time that you ever touched a hot stove by accident or a hot pan, right, that pain is something that we remember and is ingrained in us. So before that ever happens, we don’t really truly learn what it means to touch something that’s very hot. And we don’t sense that as a true thing of danger until that is actually touched. And then we get that pain reception. And we hopefully learn to not touch that hot pan again, even though we do that probably by accident. And hopefully we don’t do that on purpose again. So intelligent behavior, right? Not necessarily someone who’s smart, although smart people are definitely intelligent and exhibit intelligent behavior, but intelligent behavior isn’t necessarily connected to how smart someone is. But if that is intelligence, what does it mean to have artificial intelligence? Well, on a very basic level, right, is a non-biological thing that has or exhibits forms of intelligence, right, a machine right or robot or computer or phone, whatever it may be something that is not living a does exhibit some form of intelligence. Now, it may not be total human intelligence, but it may be partial human intelligence.
So a lot of this came from a man by the name of John McCarthy, who really was the creator or really helped start the field of AI. So in 1956, john McCarthy, who worked at Dartmouth College at the time, helped to organize a conference to discuss the idea of artificial intelligence. And so the 50s, this is really after world war two was over, and everyone was home and the big computers that we had created for the war, are now no longer being used for military purposes, but are starting to be transformed into industrial purposes. John McCarthy also had a lot of other things credited to him, including the Lisp programming language, but primarily he is credited for helping organize the idea of artificial intelligence and so on. During that summer of 1956, several leading minds in the world of AI at the time, although AI really wasn’t solidified at that point, but many of the people who had interest in this type of idea gathered for a very several long week brainstorming session, essentially, little mini conference. Attendees included john McCarthy, of course, Alan Newell, Herbert Simon, Claude Shannon, who we’ve talked about before Marvin Minsky, and quite a few others. I’ll talk about a lot of those folks here later on and the following videos. But pictured here are some of the surviving members of the conference from at least in 2006, when they’re celebrating their 50th anniversary. But at this conference, overall, a lot of the groundwork and the ideas of artificial intelligence were first introduced. And it really helped to shape the field for many years to come.
So we had this discussion already of what is intelligence and what is artificial intelligence. According to john McCarthy, it is the science and engineering of making intelligent machines, especially intelligent computer programs. It is related similar to the task of using computers to understand human intelligence. But AI does not have to confine itself to methods that are biologically observable. I really like that particular part there that is not biologically observable, right? There’s a lot of things in the world that are intelligent behaviors, right? Especially a lot of animals, cells, all sorts of things. But there’s a lot of things that machines can do that biological processes can’t as well. What does that mean for the definition of intelligence? Well, John McCarthy continued here to say that intelligence is the computational part of the ability to achieve goals in the world. Varying kinds of degrees of intelligence occur in many people, animals, and even some machines, as we talked about with artificial intelligence. But there’s really no true solid definition of intelligence, and particularly when it doesn’t depend on human intelligence, because a lot of times, of course, we as humans are defining intelligence. And most of the time, we’re defining intelligence in terms of our intelligence. So the problem is that we cannot yet characterize in general what kinds of computational procedures we want to call intelligent. We understand some mechanisms of intelligence and not others. So we don’t really truly fully understand the human brain yet and a lot of the nuances of our own human intelligence. So it’s kind of hard to quantify intelligence as a whole, especially artificial intelligence when we’re trying to transition into human-like AI.
Watch through 5:38
YouTube VideoBut let’s continue our talk here a little bit more about intelligent behavior and what that means with human behavior as well, and when we’re trying to actually make AI that seems human. And so one of the problems with AI is that it forces the computer to mimic all human behavior, not just intelligence. And so when we start to create an AI for it to truly be human like, right, it has to do all of our own behavior. And so things like slow response times, typos, commonly misheld conceptions that aren’t true, connecting words like I’m doing right now. All of these things are human behavior that may not be considered intelligent, or clean, or you know “perfect”, but it’s something that a successful AI agent must be able to do in order to pass what we call the Turing test. And we’ll talk about that here in a second. But likewise, an AI must also act, sometimes really, as if it can’t solve some problems that are perfectly well within its abilities to actually be able to solve, but simply because those problems are unsolvable by human intelligence or unsolvable in the amount of time it could take the AI or computer to actually solve. So if you’re trying to make an AI that is trained to behave and act like a human, it needs to do as humans do, and it can’t be perfect.
So that is where Alan Turing comes into play. And we’ve already talked about Alan Turing to some degree, especially with the Bombe and his work with the Enigma machine, as well as the Turing machine. But he also wrote in a paper, “I propose to consider the question can machines think?” This is a quote from a 1950 paper that he wrote, called “Computing Machinery and Intelligence”, which he opened with that statement and tried to open up some discussion, right? He was deeply interested in the field of artificial intelligence, but unfortunately, there really was no good way to determine if a system was truly intelligent at the time. And so in that paper, he describes one way to test machine’s intelligence, which is now known as the Turing test. The basic idea of a Turing test is as follows. You have one person in a room with a computer capable of simple text-based chat, so they’re sitting on a terminal at a computer, and they’re trying to talk in this chat room or to someone else, and that someone else will be a computer or could be a computer that will try to pass itself off as a human by responding to the prompts from the tester. The tester then must determine whether or not he or she is conversing with a computer or a real person. And now there really hasn’t been someone who has truly passed the Turing test completely with flying colors. And the Turing test as a whole is biased, and there’s some problems with it. And so it’s not perfect either. There have been some algorithms that have passed the Turing test to a certain degree, but there are some problems here.
So can you think of any of those problems that a Turing test may actually have? Some of those problems are actually exhibited from a variant of the Turing test called the Chinese room. So the Chinese room experiment was proposed by John Seely in 1980, in his paper, “Minds, Brains and Programs”. In this setup, an English speaking person is placed in a room with sufficient supplies and a set of instructions completely written in English, that directs them to accept Chinese language characters as input and output a result or response of Chinese characters. On the other side of the wall as a native Chinese speaker, performing what we refer to as a Turing test. And in this case, the person is convinced that the person on the other side of the wall is indeed a human. However, the computer being a human that only speaks English is completely unaware of the conversation that is taking place in Chinese. So in this case, is the machine, right or the person intelligent, or merely just so advanced at following instructions that it appears to be intelligent? So this is a trick right? Are we just good at giving the computer instructions to mimic human behavior or is it just someone who’s good at following instructions? Now, following instructions, there’s some intelligent behavior involved with that, although not a whole lot, but it’s not exhibiting the full intelligent range, right? So there’s some of the fundamental issues with the Turing test and things like that of trying to truly quantify whether or not an AI is a human or not. But this leads to an endless debate right between strong AI and weak AI.
When you think of an AI in movies, this is usually or typically a strong AI, which is designed to completely mimic or surpass human intelligence. Now, this is most movies, right? And most movies that you watch, they’re going to be AI that can converse perfectly in English and answer all questions, and even look up things that instantaneously that at the moment no machine is actually possible. Iron Man is a perfect example with his AI Jarvis or Friday later on and some of the later movies. And so unfortunately, really at this time, strong AI is just not a reality. And there’s even some debate of whether or not it’s actually possible. Most of the AI that we deal with today is in the form of a weak AI. This is also called narrow AI, which is designed to perform only a subset of intelligent actions. Now, just because something is a weak AI doesn’t mean that it’s not possible of good quality intelligent actions. A lot of times weak AI is extremely good at one particular kind of behavior, but not so great at others.
Differentiation here between strong and weak AI starts to lead to the idea of intelligent agents. Intelligent agents are entities that can perceive things about its environment through sensors and act upon that environment with effectors, hopefully in a way that can be perceived by the actual agent. And so what do you think are some examples of these intelligent agents that you’ve seen in your lives recently? I know for me, I have things like Amazon Alexa or smartwatches. Basically, anything that has a sensor and acts upon its own and its environment is going to be in some form of intelligent agent. Now a lot of these are going to be categorized as weak AI, right? So it’s very good at one thing. A simple example is a thermostat, or even a Roomba. Roombas are really good at vacuuming your floor, but not so great at opening your door for you, or cooking your food or telling you what temperature it is in your house.
Each robotic agent or intelligent agent is going to have four primary functions. The ability to perceive things from its environment. So what it can sense, although granted, an agent isn’t going to be able to sense everything about its environment. Sensors are really what it can understand. So what it can sense, what it can understand, right, or what it can understand is only what it senses it knows about. Actions- so what it can do on its environment. And really, an agent is only going to be able to know a subset of all possible actions, it’s not going to be able to know all the things that are possible, right? Depending on the kind of AI and use of that particular agent. Some of those actions or environments become extremely complex, even in the game, something like checkers. A simple game overall, but it becomes extremely complex if you’re trying to go through all possible board configurations. The last major function of an agent are its effectors. So how it can do things. Really, and sometimes it may not be capable of doing enough in its environment, but these are the things that it’s actually able to do in its environment, or how it can do those things in its environment.
Now, this also brings us into discussion of how an AI should act, right? A weak AI, strong AI, whatever you’re trying to talk about here. But this brings us into a discussion on how an agent or an AI agent should be able to act. Now a rational agent, which is what we perceive as intelligent is concerned with doing the right thing, given what it believes, from what it perceives. Given the information that it can gather from its environment, and all of the information that previously knows, it should be concerned about doing the right thing with that information, the act upon that information. But as you can guess it may not know everything, but it will try to do the best it can. Now, we can also measure the utility of an agent by measuring its maximum success. So how good is that? That is what is the right thing? And how do we figure out how well it did that thing? So to understand the effectiveness of artificial agents or intelligence, we have to ask ourselves questions about our beliefs, the uncertainty of knowledge, and how its represented and how we can reason and learn from it. And by studying our own rational behaviors, that is why we as humans do the things that we do, and we can hopefully better understand what goes on into the decision making process and how we can build better rational agents. But in that sense as well, right? If we’re trying to build perfect AI, our human bias gets into the AI that we build. And so one AI, this is why different robotic vacuums behave in sometimes entirely differently, because different humans are building different models of vacuums, or thermostats, or whatever kind of AI you’re looking at. And that is based off of that particular person’s experiences, research and knowledge. And that bias is going to lead into different kinds of utility, different measurements of success, different actions, and different rational behavior.
A couple of very simple examples here of categories of agents that we may see in weak AI, something like a simple reflex agent, which just simply does an action based off of the things that collects or senses from its environment. This is something as simple as a automatic door so you walk into Walmart, and the door opens for you. Right, awesome magic door that opens for you. There is no one that has to open the door for you. But that is a basic AI right? It is something that can perceive from its environment and act upon it. Now it doesn’t really know what its action does. It does know that the door is open, but it doesn’t know what that actually means for the environment. It doesn’t know that it’s letting humans into the room, and it doesn’t know that it’s, you know, letting energy out, for example, as a basic automatic door. And we could do something a little bit more advanced like a learning agent, which is going to be able to learn from its actions and do better the next time, some form of critic or utility is going to be involved here. Something like a smart thermostat in your home. So a Nest thermostat or Ecobee whatever smart thermostat you may be aware of, but those smart thermostats are going to try to learn your behaviors- when are you out of your house?, the temperature of the environment outside of your house, how comfortable you like to have your house, whether like it colder or warmer, what room you’re in, in the house. So it can make that room more comfortable than the rest of the house. So you save on energy. And those sorts of things are going to start learning your behavior or other types of behavior so it can better its particular results, right? It’s so a lot of these AI are basing their decision based off of the utility. The utility, the measurement of success, that it’s actually been programmed to to look at.
So let’s take a look at some early attempts of artificial intelligence. So Alan Newell and Herbert Simon were a couple of early researchers in AI. In 1955, they wrote a program designed to mimic the problem solving skills of a human being, and called it the logic theorist. This program is now widely considered to be the first AI program, it was used to prove theorems in the book of Principia Mathematica, and actually created a much more elegant proof for some of the theorems than the author wrote for the book. At the time, interest was swirling around the growing idea of AI, and the experts decided to come together and discuss that topic at length. This is a conference that John McCarthy had wanted and successfully organized. There’s a lot of different types of AI that have been developed over the years. And there’s a lot of different methodologies behind them to make them artificially intelligent. But a lot of this deals with how we represent knowledge and information for the AI. So there’s a ton of information in the world, even something as simple as a smartwatch that’s detecting your heart rate and oxygen levels and things like that. It ends up being a lot of information over the course of a small period. And so how do we represent that knowledge in order for our AI to actually be able to consume it and make good rational decisions from it.
That also includes a search of that information, so how do we find and dig our way through all of that data, which includes expert systems. So a really good example of an expert system is Amazon. So it learns your shopping habits and recommends items to you. And that recommender system is really what tries to learn your likes, and dislikes, and what you might need to buy, or want to buy next. The ability to plan right? To set out a course between information between two points. Reasoning, machine learning, which we’ll talk about here in a little bit with neural networks, special topics like a natural language processing, so AI that can understand human speech, which for us is not as difficult, but for a machine and for a computer understanding human like speech, and producing human like speech is an incredibly difficult problem.
So to dive a bit deeper into the topic of AI, we’re going to look at the last tool mentioned called neural networks. In 1969, Marvin Minsky, one of the founders of MIT’s AI lab, wrote a book called perceptrons that laid the groundwork for this idea of a neural network. Now, what are neural networks? So the idea behind a neural network lies behind the power of individual neurons, and the connections between them. Each neuron is capable of doing a certain task, and then its output is passed on to other neurons. The strength of a neural network comes in the form of the connections between neurons. If one of them tends to give correct answers to a problem, other neurons will be more likely to use its output based on the strength of the connection between them. And the process of strengthening good connections and weakening bad ones is how neural networks are able to learn how to do particular tasks. And this is really kind of how we’re trying to simulate the human brain, right? We have in our brain, we have lots of neurons and synapses and those synapses, those connections are a representation of the knowledge and things that we actually learned throughout our life. And so how do we actually get a computer to imitate that particular idea? Now, neural networks have been out for quite some time. But more recently, this has been the idea behind deep learning. Deep learning works at a very basic level, expanding the network to have numerous different layers to actually learn from. Deep learning is very much like an artificial neural network, but lots and lots of different layers. And each layer may actually be a different learning algorithm that is producing that particular output.
An example of neural network is here about classifying camouflage tanks. So in this experiment, the researchers wanted to create a neural network that would classify pictures of tanks hiding in trees from pictures of just trees. So we have pictures of trees and pictures of tanks in trees. This was a really interesting problem for the government at the time, and it worked pretty well for the original photos. But when the researchers brought in a new set of photos to test it on, the results were no better than random. The reason behind this behavior is that the original photos that the AI were trained on, were taken all on sunny days for the tanks, all the pictures trees were taken on cloudy days. And so what they really built here was a machine that determined whether or not it was sunny or cloudy. And so this is really kind of a funny ending result here about an AI that did a really good job, right? It was given information and without information, it classified these pictures. And based off of the pictures themselves, the classification of sunny or not sunny became a lot easier or more prevalent than tank or no tank. And so this is a really good example of how AI is really only as smart as, currently, as smart as how we program it or what we tell it to do. And sometimes it ends up finding things out or doing things that we totally didn’t expect. And sometimes it turns out for the better.
So let’s take a better look at some other AI that is a little bit more modern, or a little bit more recent. So in 1997, so this is still pretty old, a little over 20 years old now, Deep Blue, a AI that was developed by IBM beat Garry Kasparov at chess. So Garry Kasparov was a world class chess player. This is a very big achievement at the time because chess again, like many other games can end up being far more complex than what you actually think. So IBM’s next AI venture was IBM’s Watson. Watson was a research project that started out in 2006. And its goal was to be able to learn from the internet. So basically be able to answer lots of questions based off of the information that it can actually scrape from the internet. So basically, Wikipedia type information, things that you search on Google, that sort of thing. A really huge achievement of IBM’s Watson was in 2011, beat Ken Jennings in Jeopardy, which Ken Jennings at the time, if you never watched Jeopardy, or haven’t watched Jeopardy for a while, Ken Jennings was one of the best players in jeopardy at the time. So after IBM’s Watson beat Jeopardy, IBM kind of repurposed the AI to start targeting things like the medical field. So being a computer that is able to answer or intelligently answer medical questions, also things like industrial questions. So it’s basically been in a continuous innovation project where it is basically an AI that is essentially better than your Google search. So not only does searching the internet for information, but actually coming up with this specific answer for the question.
Now even more impressive, Google’s DeepMind project had this AI called AlphaGo. And in 2015, this was the first AI to ever beat a professional human player in Go. Go is a really ancient game that originated in China with a board with a bunch of squares on it, and the task here is to end up with the most colored stones on the board. So there’s white and black stones, and it’s kind of like reverse if you’ve ever played Reversi, but a lot more complex. AlphaGo continued its winning streak by defeating the world champion at Go in 2016. So this is a huge achievement, because again, right, this is the first AI to ever beat a human player in Go. But the real achievement here is that Go is an extremely complex game. It has 10 to the power of 170 possible board configurations. And so an AI that can actually play a game better than a human player at this, or professional at this, is really quite an achievement, because computationally wise it’s practically impossible to look at all board configurations instantaneously at any time for all the moves. So AlphaGo really started to train itself. How it works is it played variations of itself, millions upon millions upon millions of times, to start to learn different techniques and strategies to actually play Go. And AlphaGo was later expanded into an algorithm called alphaZero, which played games like chess and checkers. This is a little bit different than most algorithms or AI’s that play chess and checkers, where those just generates the possible game trees and choose the best move. But alpha zero is deep learning base, so it plays with a little bit more strategy instead of just looking five or six minutes ahead.
Now we could talk on and on and on about the uses of AI and machine learning because it’s pretty much ubiquitous in our current life. But things like Microsoft Connect was a huge innovation that is able to track and map out a human skeleton so you can move and interact, right? This is kind of a big portion or big push into things like AI virtual or augmented reality. Things like Apple Siri or Amazon, Alexa or Cortana all are natural language processing AI applications. So AI that is able to understand and answer human speech questions which are really impressive and improve on it on a daily basis. Things like Wolfram Alpha. AI is pretty much everywhere right has so many interesting capabilities and applications and really have started to become integrated and ingrained in our daily life. ASIMO A S I M O Honda is another example of an attempt at artificial intelligence in this time in a very human like form, this has so many interesting capabilities. And they hope that one day can be used to assist humans in everyday life. Just like a lot of the smart home devices and things like that have started to integrate into our daily routines. The hope here is that we have robotic agents and AI that is able to further assist us in our daily tasks.
So in review, we’ve talked about Alan Turing and the Turing test, along with John Cirillo in Chinese room with the problems and issues that the Turing test actually has. Then, we talked about Newell and Simon’s logic theorist, one of the first AI programs ever to be put out there. Then, we talked a lot about the Dartmouth research projects where organizing the conference to start to kind of build out the idea of AI, and the vast amount of different subtopics, and tools, and projects, and applications of AI, along with things like neural networks with Marvin Minsky, and a bit about the current state of AI. So a lot of things like Deep Blue, AlphaGo, AI in the medical field. So there’s a vast range of different possibilities and applications that we’re currently experiencing, including things like self driving cars. So what’s missing from this discussion, because we could talk for a very long time about AI, and just purely just the applications of AI.
So things like philosophical implications of AI, ethical implications. So this is a really big one right now with self driving cars. So if you’ve ever heard of the moral machine, this is a project out there, I would encourage you to go check this out. But it’s for a self driving car. If you’re presented with a situation where, regardless of the decision you make, you’re going to kill something. What do you kill? Do you swerve to miss grandma crossing the streets? But when you swerve, you’re going to hit the little girl playing hopscotch on the sidewalk? Or do you swerve the other way and hit the dog walker walking down the street with a pack of cute little puppies? Or do you just speed on through the intersection and hit grandma? There’s a lot of moral implications here. Because, you know, when it’s a human making that decision, generally speaking, the human is going to be at fault, but when an AI makes that kind of decision, which involves human life, or other forms of life, who’s at fault? Is it the programmer who told the AI to do that type of behavior? Do we put the car in jail? Right? There’s a lot of ethical implications there around AI and the choice of life or death.
Solvability, right, are there things that a human can do, but the AI can’t, or vice versa? Singularity, the idea that we will reach a point where technology is growing faster than what we can actually do. So it basically grows out of control. And this is kind of like the robot overlords situation. If you’ve ever watched the movie I, Robot with Will Smith. That’s a really kind of good example of singularity and human-like intelligence and robotics. Like robots that have or AI has emotion and things like that. It kind of relates to consciousness as well, right? So we relate to humans being conscious. How to make an AI that has a conscience, or that human-like emotion and human level decision? But again, these are some really deep topics that we could talk a lot about. But these are just some points to kind of remember, as you’re kind of going about learning about AI watching the videos that we have for this particular module and moving forward into a world where AI is as ubiquitous and ingrained into our daily routines, and it’s going to continue that way even more so as as we go farther into the future.
Nine Algorithms that Changed the Future Ch 6 - Pattern Recognition

Welcome back everyone. In this video, we’re going to be taking a look at information retrieval. But before we get to that point, we need to start talking about databases and how data is actually stored. So for this example, we’re going to be working on our own social network called K-Stater. Specifically, we’ve been asked to help design a way to keep track of all the data on a site, like a social network, like K-Stater should have. So if you take a few minutes and brainstorm what kind of data or imagine what kind of information we may need, for example, of course, we’ll need to have some sort of way to track our users like maybe your eID, name, birthday, major, and maybe even just your phone number. And, you know, of course, we’ll need a lot of other information to make a full website like this work. But we can start off with the basics right, just keeping track of our users. But since we want to keep track of all that information, we need some way to actually store it. And so there’s tons of different ways that we could actually store that on our computers, right, of how our computer systems are designed to store information in that way.
But thankfully, there was a huge change in how the data on our computers are actually stored, or at least how we even look at data stored on our computer. And that’s mostly thanks to this man here, Edgar F. Codd. While working for IBM in the late 1960s and early 70s, Codd began working on the ideas of relating to the storage and arrangement of data in computer systems. And in 1970, he published a paper called a relational model of data for large shared data banks that laid out this grand idea for a better way of storing data. That idea led to the creation of what we call a relational database. This is a form of database that is by far the most common in the world today. And if you’ve ever used things like Microsoft Access, or MySQL, or something like that, Microsoft Access is a simple type of relational database. That is pretty easy to use for most people just like what you would open up and use with Microsoft Word or even Excel, and Excel to some extent, depending on how you have your sheet set up is like a relational database, or at least relational data in some sense.
The idea behind a relational database revolves around three different terms, a relation, a tuple, and an attribute. A row in a table is called a tuple. It represents a single item that is stored in the database. In a simple example each person stored in our database could be a just a single tuple. Right, or if we are storing addresses for our users, so that address itself would be one tuple, or one row in our database. Each row or tuple has many attributes represented by columns in the table. An attribute could be something like a name, address, or like a street, zip code, phone number, one single piece of information that is associated with that one particular row or record in. The table itself is called a relation because it relates different attributes together uniquely, in order to describe objects as tuples. So our relation as a whole, right, a relational database. So each attribute strung together in a single tuple is like information related information, right? So we have we have a user, our user may have a name, a username, an email, and all sorts of different types of information. Each of those attributes are related to each other, or in an ideal situation of how we design our database. But relating those different attributes together is really kind of what we are, what we benefit, or what we get out of something like relational database, because it makes our data much easier to store because we store like information with like information, right, so all of those records that have similar information, like all of the user information, and it makes it a lot easier to store and search. Especially in a modern age where we have such large amounts of information, having this highly structured data makes it significantly easier to work with and use as you utilize apps like Facebook and Twitter.
But let’s do some hands on work with a relational database. So since we’re creating a social networking site, probably one of the first relations we’ll need to create is for the user. Right, because a social network is pretty much useless without some people to actually use it. So here’s one potential way that we could set that up. The data here is all nicely arranged into rows and columns, and in theory, right should be easy to look things up. Maybe not. Right? At least the way that I have it currently. So what if you wanted to find all of the students here in our in our user database, or our user relation here that are majoring in computer science? How would I go about doing that? Take a moment here to pause the video and take a look at a table here and see if you can find all of the users or come up with a way to find all of the users who majored in computer science. Hopefully you found all of the users there’s that do did majored in computer science is pretty straightforward, right? But for us humans, and for the small number of users, but for a computer to search our table here to find all of the computer science majors, it becomes a little bit more complicated. Obvious, my name is in there, Josh, first row there. My major is comp. sci, which is short for computer science. And we don’t need the information science or Information Systems majors there.
But we have another computer science major there, gameguy down there, his major is computersci, all one word. And so while both of those users are computer science majors, the listing or how can the computer science major is actually listed as entirely different. That makes the solution for a computer much more difficult to actually write because now we have to take into account in this situation, all of the different spellings and arrangements of the computer science major. So this particular relational table or this particular relation, we would refer to as not normalized so the data isn’t normalized, the data isn’t uniform. And so why do we want to normalize the data? Well, big obvious reason that we just experienced is normalized data makes it a lot easier to actually work with. So those data anomalies, right, the differentiation between compsci, CS, computersci, computer science, all of those differentiations, they’ll mean the same thing. But it becomes a lot harder and more difficult to use, and it makes it more prone to error as well. It also makes redesigning your information a lot easier. More often than not, when you’re actually working with an application or designing an application that’s working with a database, you’ll end up finding that your use cases change over time. And so more often than not, you have to go back in and redesign your database or redesign your tables in order to add new columns or attributes or entirely new relationships.
And so having normalized data to begin with makes that task significantly easier because you don’t have any data anomalies in an ideal world that can throw a wrench into your plan. But one of the other things that normalizing our data can actually accomplish is mirroring real world concepts. So we don’t want to store information into our relation in a random computerized way. Because that’s not the real goal that we’re trying to accomplish with these databases. The goal here is to store information that is significantly easier not just for the computer to actually search through, but also humans as well. And so we want to be able to store our relations in a way that mimic what we would normally store that information in real life. For example, addresses and things like that we don’t have need to come up with these crazy elaborate ways to actually store an address. But we want to make sure that it’s stored in a way that makes sense. Of course, and lastly, this also simplifies the search queries that we actually do on our relations or our data. So those that question that I asked of find all the users that majored in computer science is a lot easier if all of the computer science majors have the exact same spelling of the computer science major. And so having normalized information and normalized data also makes our search tasks significantly easier. So let’s take a look at a way that we can actually start to fix our unnormalized relation.
So first off, let’s take a look at the major column because that’s what we encountered first, and that’s what we tried to search first. So what can we do to make sure that the data in that column is easy to search through or easy to query? Now, if you pause to kind of think of a few ideas here, one potential way that I have listed here is to add an ID for each major. And so essentially, what we end up having here is a second relation. So we split the major off into a second table or a second relation, that acts as a lookup table. Okay, so if you imagine using your basic form online, when you’re signing up for stuff, a lot of times you’ll encounter drop down boxes, right? Those act like simple lookup tables, right, you are given a specific set of things to choose from, instead of typing in free text. Free text, when we’re talking about storing things inside of a table, if we want that free text to be uniform, we can’t rely on our users to enter that for us, we have to suggest and complete that and give them the options to actually select from. But since we have a separate table, here, we need something that’s called a primary key that identifies each record uniquely so we can include it in the other table. It also makes it easier to search.
Each relation in your relational database should have a primary key. And that primary key uniquely identifies each record. So each record in a table or an in relation should be able to be uniquely identified by any number of attributes. So a primary key does not have to be one single attribute. But it can be multiple attributes combined together that are unique. And without that uniqueness, there’s no possible way for us to uniquely retrieve any single record from our database. So that particular part is extremely important as far as relational database goes. What we have here in our new table is our major ID. And you can actually use that to look up the actual abbreviation or the actual major itself. So major ID in this table, this is our major table now. This column is going to be the primary key. And over here, we can just assume that our user ID is our primary key, because everyone at K-State has a unique eID. So we can safely assume that that is our primary key that uniquely identifies each user. But instead of having the major column here in our user table, we now have major ID. And so when a user actually selects their major, you can imagine they would be selecting this through a drop down box. But that is replaced not with the actual major, but the ID of that major.
So if we wanted to see what major John was, we take the major ID 3, look that up in our major table. And that tells us that John is an Information Systems major. And that information systems major has an abbreviation of IS. But this makes it significantly easier for us to look up all of the computer science majors because all we need to do is look up find computer science in our major table, what is that ID and then search that ID in our user table. And so that process is made significantly easier now. But let’s also talk about the birthday column, if we can think of different ideas to how to represent that. Because if you look over here, on our birthday column, we have a whole bunch of different variety of ways that we have for our birthday. So June 13th, June 1, February 2nd, Dec 26, Dec. 18th with a period 18th. So we have abbreviations for the months, days, with the th, nd. So there’s lots of different variations here, we and we don’t even have just the pure numbers yet, which you assume that people would add as well. So there is no uniform way of representing the birthday now. But what we could do is add that to our interface, right, we don’t have to necessarily purely rely on our database, although we could enforce a specific format for our column on the database side. But we can also enforce that when the date is actually entered. So we can have like a little calendar picker or something like that, or an algorithm actually checks the text before it’s actually saved. So just something to watch out for when you’re working with information.
It is a very good practice to keep our data normalized, to keep everything not just unique but evenly distributed or even format street same format for everything because if a human’s going through here and reading this, of course, we could also we can all see what the birthday is and understand what each of these mean. But when we’re querying our database or if our algorithm or computers looking at these records, it becomes significantly more difficult to actually understand. But let’s look at another example. What happens if we try to add a phone number to our user table? Now I’ve stripped off some of the other columns here just to make this example a little bit easier to see and fit onto one slide.
But let’s try to add our phone number. So but how many phone numbers does the typical person have these days? Well, landlines really aren’t that that common anymore, but people still have them. I have one in my office. But I also have, you know, my cell phone, I have a digital telephone number as well, and a couple others, right. So someone might have multiple, just even multiple wireless or cell phone numbers without even considering a landline. And so adding multiple phone numbers for a particular user can become a little bit difficult to actually do. And so if we try to just simply add, say, phone number one, phone number two, things get complicated really quickly, because if someone has more than one phone number, we had to add another column for their second one and another one for their third and so on. And so that doesn’t really become a very good practice. Because, in reality, we don’t want to have to add another call to our database or to our table every time we need to add a an extra phone number for a particular user. So like what we did before, let’s try to put that into a another table, its own table. So one of the ways that we could do this is just have a phone number table. and in this situation, Our phone number is going to be the unique or primary key. And then we have the users that connect the relationships together. So we have a we have many users, right to one phone number.
And this works, but still really doesn’t solve our problems, does it? We still have the same issue before, instead of having having to add multiple phone numbers, multiple phone columns, we now have to add multiple user columns, because right, what if an entire family signs up for our social network? That family might share a phone number, so each person in that family is going to have the same phone number. So every time another person from that family signs up, we’re going to have to add another user to that phone number. So we end up with pretty much the same problem that we did before. So if we flipped it again, right, we can still have our phone number table. But let’s flip that. What if we use the user ID for the primary key in both situations, so primary key over here is our user, right? But we’re going to connect that to a user in our phone table. But now instead of just having only the user ID as our primary key, we have the user ID and the phone number as our primary key.
So if we use both of those to uniquely identify a phone record, that becomes a little bit more easier to do, because we don’t duplicate any information here. Although, of course, we do duplicate the user ID down here, which is perfectly fine. But this makes it more easy to search, right. So this is a one to many type relationship, where we have one user too many phone numbers. So we have one user here, but many phone numbers here. And so that describes the relationship between these two tables. And so we can see it over here. Since the user ID and the phone number are unique together, we can have the same phone number for multiple users. So we have phone number 5134. So gameguy has two phone numbers, but Sharpie also shares the same number as gameguy here. Now this is just a simple example of how we might store a large amount of information or related information into a database that is easily retrievable by a computer.
So in this video, we’re going to reiterate a little bit what we talked about with our relational database, right? Because the whole point of the relational database is that we can store lots of information in a very structured way that is easily searchable. That’s really important in today’s world, because we have the World Wide Web, right, the internet, it’s huge. Now that we know how to store data in a reasonable fashion, we have to talk about where most of the data in the world is actually stored. And for that, really is just the internet. So at the highest level, right, we can think of the internet as a very big, very big, completely unstructured database of all of the information in the world, right, because pretty much almost everything is connected to the internet anymore. Not everything, but pretty much. Some parts of it are very structured, and very well formed and easily searchable. But generally, it will never be as well structured as we’d like. And one structure might be entirely different than another. And so it’s not going to be very uniform across the entire internet. However, we are pretty much constantly using tools like Google to find information and the vast amount of data that is out there on the web, and it does a pretty good job, doesn’t it? When you do a Google search most of the time you find what you’re looking for. So how do we go about finding information in a big giant unstructured pile of data that really is pretty much like finding a needle in a haystack, as far as Internet is concerned. So that task is the job of information retrieval specialist, and the algorithms and research they do. In a base form, right, let’s say we want to find some information on a very simple Internet, maybe this is back in the early early, early days, where there was pretty much nothing out there.
So our internet has three pages, only three pages, and those three pages have very little amount of information. And so we want to find out some information about all this data that is on the web. So we want to run these search queries. And you can kind of imagine these being just put into a Google search box. Okay, so we want to find all the pages that have cats, dogs, dog sat, “dog stood”, cat or mat, and cat and mat. But how could we do that? How could we find all of the pages that match these queries? Well, the most basic or straightforward way to do it is just to read through all the pages and find all the occurrences right. But in reality, the internet is huge, this approach works perfectly fine for what we currently have, right? We only have three pages, I can read this in like under five seconds and find all the results right. But doing that process on the actual internet is a really bad idea, because it’s huge and would take forever so your searches would just never complete. And so we need a better way of looking at data in order to answer all of our questions very quickly and accurately to that.
So the first step here, then is to try to simplify the data. So instead of scanning each character, each word, every single time we tried to run a search or query, we can actually do what we call indexing. For each word, we could create a list that a list that contains which document that word is actually listed in. This indexed collection becomes a little bit easier to search because now we don’t have to look at all of the words in all of the web pages, we’re just looking at this index list. So which queries that we had before? Which of these queries can be actually answered with this information? Well, we can find cat right because cat is one of the words that we have sat there. index. And if we look at cat here, you can see that cat occurs in our document 1, and then cat also occurs and document 3. But in order to find cat, we didn’t have to read the entirety of one we didn’t have to read two. And we didn’t have to read the entirety of three that is already done for us. We just find the word in our list, and then we know already which pages that actually occurs in. But most of these can work just fine, right? Even dog sat, dog space sat, so we’re trying to find any of any occurrences of dog and any occurrences of sat here so quickly. Number 3 here would return to 3. And then it would also return 1-3. So, so one, two and three would be returned entirety for that query there. But cat or matt also works. Cat and mat. So pages that have both cat and mat.
Overall, we can answer all these queries, right? Except for “dog stood”. So “dog stood” doesn’t work. Why? If you ever ran a Google search before, so if you type in just a two word search query is looking for any occurrences in any position on any page. So if I search for just dog space sat, it’s looking for any occurrences of dog and any occurrences of sat on that webpage. But if I use quotation marks, it’s looking for position, it’s looking for position, right, it’s looking for the word dog, immediately followed by a space, followed by the word stood. So now we’re dealing with the position of the words in the webpage. We can’t answer information like that with what we have. Because all we are actually storing here is the word itself, and then if it occurs on and what page it actually occurs on on the in the web, and not the position of where that word occurs on in that page. So in order to do that, we need to modify our index algorithm a little bit. So to improve our indexing algorithm, we could store the location of the word within the document, along with the document number in our index.
So using this information, we can answer all of our queries now, right? How would we actually do that? Well, let’s skip all the rest of them, because we already know we can answer everything else. But let’s look at dog stood. So first we’re looking for for dog, right, so imagine what our algorithm is looking for here, we’re looking for dog stood dog, followed by the word stood. So we can look at dog; dog occurs at two, two. So document two, position two, and document three, position six. So that’s well and good. And so we also need to find stood. So we find stood at document two, three, and document three, three. So dog and stood occur both in both two, documents two and three. So let’s look at the position of those words. So stood obviously is the second position and dog is the first position, so we need to have dog followed by stood. So if we look at the second number here, which is the position of the word, so we have dog that occurs at position two here, and stood that occurs at position three here. So since dog is immediately followed by stood, document two would be a valid page that matches that query. But if we look at document three, dog occurs at position six, and stood occurs at position three. And so since stood does not come after dog in document three, that is not a valid page that matches our search results, or our search query. So in a very, very basic way, this is what your Google search query is actually doing on the internet, it’s trying to, or what Google is doing is trying to basically index the entire internet, so that when you run a search query, it knows where that text is actually occurring in the web, and you can run more intelligent queries like this to find a little bit more accurate information and narrow down your search results.
So if we made an algorithm to actually do execute what we just did with dog stood, it would look something like this in a very formal sense. We haven’t shown you any formal algorithms in this structure yet. A formal definition of an algorithm will look like this, where we have input, output and the algorithm steps itself. So this is kind of like pseudocode here. So the input or in other words, called the precondition describes what the input will actually be to this algorithm or the expected input. So in this case, we’re expecting a two word phrase in the form of word one followed by word two, and this is in a quoted string. And the output or the post condition describes the expected or produced output from the algorithm. So given this this input, we’re going to produce this output, and our output is going to be an answer list of all of the numbers of the webpages that contain the phrase. And then the steps that we have here are exactly what I did just before, where we are going to index the web here. So the page number position number pairs for word one, so find all the matches for word one in our index and find all the matches for word two in our index. And then we’re going to go through each of those page number position pairs to see if we have a word that happens right after it. So for each pair in list one, see if there is a pair in list two such that the page number is the same as the one in list one. And the position number is immediately after the position number in the first page position pair. Looks a little bit more complicated than what I actually did before.
So that is a big step that we’re kind of making here and formalizing our algorithm definition. But you’ll see this a lot in computer science, especially as you move forward in our courses. But we can’t answer all of our search queries using this particular algorithm. This particular algorithm is expecting our word one word to our two word phrase here. And so it works perfectly fine for when we’re trying to look up the phrase cat sat, using our indexing list or our indexed list. But cat space stood doesn’t match our precondition, because it doesn’t have the quotation marks around it. We could answer cat stood, but we couldn’t answer cat or stood.
So how could we modify our algorithm in order to handle the other different types of queries? And so there’s a lot of things that we would have to think about when we did that, we would have to make sure we’re modifying our precondition for it to accept different types of search queries. And then we’re going to also have to modify our algorithm itself in order to handle those different types of search queries. So this is just some more complexities of actually formalizing an algorithm definition to make sure and one of the reasons why we would actually do that is to make sure our to make sure to verify that our input and output is correct. So making sure our algorithm does what we want it to actually do.
Welcome back. In this video, we’re going to be taking a deeper look into what kind of queries we can actually ask of Google or searching the web. So we’ve already looked at simple queries like cat, dog, or cat and dog, or cat or dog. But that’s really not as interesting of a question to ask of the internet, right? When we’re wanting to find all of the webpages that are about cats, not just have the occurrences of the word cat, but are about cats. And so how do you know which web pages are more likely to be about cats and webpages that are more likely to be about dogs? And how could you tell the difference? And how would you modify our search algorithm that we had talked about earlier to account for that. So this ranking of the internet becomes a little bit more complicated than our simple straight up text queries.
But as we learned in the HTML lectures, pages in the world wide web have structure to them in the form of HTML tags. And so we could add more information about those tags called metawords to our indexing algorithm. And so now we could could re query the index to find specific words in. for example, the title. So in theory, right at a very simple explanation is a article that contained the word cat in the title is probably more likely to be about cats than it is dogs, even though dog was found on that webpage somewhere in the text. But again, this is a very simple approach, right? The metawords help our algorithm, help our searching, but it’s not going to be a pure ranking system, right? Because basing our questions and answers off of just the text, and these tags won’t yield very efficient results. And it won’t yield a very good collection or a very good curated, top 10 list of dogs? And how do we rank them in priority from our search? Because obviously, there’s a lot of cats and dogs on the internet. So how does one webpage about cats come first, early web search engines dealt with. So as the web got larger and larger, it was more and more difficult to find good pages in all of the bad or useless ones.
One of the early search engines was actually called AltaVista, it grew very quickly at first. So in 1996, it had five servers, 210 gigs of search engine that was constantly indexing the web, late 90s. So having 500 gigs of storage, and 130 gigs of RAM was big, right? This was a huge, huge set of servers, and very powerful machine in order to index web. And it was able to handle 13 million queries daily. So considering this the late 90s, Internet was still relatively new, but this was also getting very close to the .com era. But as we mature into the .com era, Alta Vista was eclipsed by another. So Yahoo, came in and bought them out in 2003, and then eventually shut them down in 2011. But Alta Vista was one of the first major successful search engines that we had for the internet.
We’ll transition into technology that was developed and published in a paper called the Anatomy of a Large-Scale Hypertextual Web Search Engine that provided the answer to our question of how do we rank the internet. They created a new algorithm called PageRank, named after Page himself, that could rank search engine results based off of their authority of the page that was actually found But let’s see how this actually works.
So, as you know, the worldwide web is interconnected ith hyperlinks. So if we had two hypothetical web pages here, Ernie’s scrambled egg recipe and Bert’s scrambled egg recipe. And we could analyze those links that are going o and from that page to learn more about it. With our previous indexing algorithm, if we found eggs on both of these pages, so they’re technically about eggs, but which one should come first. Should Ernie’s come first in our search results, or Bert’s? Which one of these do you think would be the top result for a scrambled egg recipe and why? So in theory, right, Ernie’s scrambled recipe, even if it is better than Bert’s, Ernie s recipe only has one other web page that links to it. So this could be a comment, it could be another blogger, whatever it may be, maybe a Facebook post. But there’s only one person that has a link to that webpage. But Bert’s recipe is obviously more popular, or at least more well known, because it has three pages that link to it. So according to the page rank, here, Bert’s recipe has more authority about scrambled eggs, then Ernie as on scrambled eggs. So Bert’s would come first in our search result and Ernie’s would come next, if these were only two web pages about scrambled eggs. But unfortunately, the World Wide Web is not as nicely structured as we like. So it is highly dependent on the actual websites themselves and other things that become a lot more difficult to actually search through.
But what about this particular example, which page would be ranked higher? Well, we still have Ernie’s and Bert’s scrambled egg recipe, we have John and Alice here. John’s web page points to Ernie’s and Alice’s points to Bert’s. Ernie’s recipe only tried it once it’s not too bad. Alice is clearly a lot more excited about Bert’s recipe. Bert’s recipe is clearly one of the best recipes. So if we are just basing this off of the text, Alice has more authority or would have more authority than John, if we’re looking at the sentiment or the excitement here. But this becomes a problem if we’re just looking at links, though. Right? One link here, one link here. Which one comes first? How do we break that tie? Well, let’s take a look at it as far as the authority of the pages that actually link to it. So John and Alice both have a link to Ernie and Bert’s scrambled egg recipe.
So that’s one and one for both Ernie and Bert. But John is a new blogger; John doesn’t have very many followers so John does not have very much authority. So John has only two links pointing to his web page. But Alice is a really popular blogger. And so she has a lot of different pages, maybe she has 100 different pages that are pointing to that page. And so Alice ends up having more authority. And since Alice has more authority, a link from Alice to Bert’s scrambled egg recipe has far more weight than John linking to Ernie’s scrambled egg recipe. And so in that sense, Bert’s recipe would still come first in our page ranking algorithm over Ernie’s scrambled egg recipe because Alice has more weight, more importance, more authority than John’s page, even though Ernie and Bert have the same number of links to their websites.
But sadly, again, right the internet is not a nice tree structure like that either. Sometimes it’s full of these cyclic connections like this. So if we follow for example, A to B to E to A to B, E A to B to E, we get stuck in these cycles. And these cycles are what we call syncs. Okay, so they suck up all of the authority of the internet. Because our algorithm gets stuck So if our indexer is just sitting there out there on the eb following links, it’ll just et stuck in this cycle. It’ll follow that link over that cycle over and over and over and ver and over and over again. And so all of the authority gets consumed by that cycle. So we can’t just simply follow links on the web because we’ll get stuck in those an all other web pages will have no authority whatsoever.
So one of the ways that actually Page and Brin suggested is called this random surfer model. So imagining that you are simulating the random surfer, you’re going to start on some web page, totally at random on the internet, and then just start clicking on random links. And you’ll continue on that pattern until at some random point in the future, you teleport to a new page and start surfing again. So start on a page, start clicking links on that web page, and then, and then you’ll eventually get ported off into another web page. And then you’ll start this process over again. And so instead of just selecting each link, in a specific order on a web page, you’re going to randomly select links to actually follow, this will cause you to break out of those cycles. And if you do this enough time, keeping track of the percentage of visits that you made onto a particular web page, you can use those values as the rank of the page. So the randomness here, the more links that you have to a page, theoretically speaking, you are more likely to be randomly surfed to others.
So let’s take a look at a example of the random surfer w th PageRank. So here is our sample web that we’re actually crawling here. So we have site A goes to home has an about page, product page, and more on the product page, links to another we site. So site A has these four pages, and then the product page on site a links to site B. Now, let’s say we are just rolling a set of dice, and each of these web pages has a link and that die, the probability the number on that die will would have you either follow that link, or stay on that webpage, right. If multiple links on were, the number that was rolled on the die, depends on which link you actually follow. If you keep on randomly rolling the die, and following links here, which page actually has more authority in this particular example? So if we kept on doing our random page search, so let’s see, if we started at S te A, and we went to home, we could have, we have three different options here. So three outgoing links, and three incoming links. And same thing for about has one, two, three outgoing and three incoming, and so does the more web page. So it has three outgoing and three incoming.
A couple differences here: home has four incoming links, and product has four outgoing links. And so if we keep on randomly rolling our dice here, this is what the authority would actually look like. So if we went long enough, the about and more page would be identical in authority because due to probability, they’re equally as probable to be visited as the other because they bo h have three outgoing links, and three incoming links. The product page has a little bit more authority than the about and more page because there are three or four outgoing links, and only three incoming links. So they have a few extra inks on here that it can actually follow even though it causes the product page to go to site B. Site B only has one possible way of actually being visited, and so that has the smallest authority. But the homepage has the highest authority among all of the pages on site a because it has four incoming links and three outgoing links. So probability wise, it is more likely to be visited than all of the other pages here. And that’s the idea of the random surfer model, even though we have a cycle here. So from home, the more the product about home more product about. Even though we have cycles, the random surfer model is going to narrow down that cycle regardless of the cycle and narrow down which web page is actually more likely to be visited based off of the links that actually finds.
Another way you can do this is by simply generating all possible paths that can be found on the internet. And you can calculate the length of those paths and the percentage of the times that those particular pages show up in those paths. So if we calculate all the different paths that we can actually find here that are less than five, so five sites deep, we actually find that site a occurs more frequently in those past than all others. So this is a little bit different than the random surfer model. So this is a little bit more discreet, meaning that we have a little bit more of an order to things instead of everything being completely random. It does help solve the random surfer model, although we do have to limit the length of our path. So there is some downsides to this technique.
But of course, there’s a lot of different problems out there that could get in our way of actually searching data, right? Instead of just those cycles, right? We have a lot of other issues like spam. How do we take into account our all those ads that are on the internet that are just basically plugging the internet, although that’s, you know, how a lot of people make their money online. But how do you avoid spam? How do you avoid ads that you don’t want to search? How do you avoid malicious websites? You don’t want a malicious website to be the number one hit on Google. How do you take into account the size of the internet and reduce computation time? How do you search non textual information? Right? We have a lot of images and videos on the internet now. And audio, how do you take that into account? Structured versus unstructured data and a lot of lots of different other things. And that brings us really into the difference between what we had with web 1.0 to web 2.0. This has a such a major impact on how the world wide web works. And so after the .com bubble burst, no one really knew where the internet was headed. And a lot of different talks were being had about what the internet could be, or what it could be different, right?
Because at the time, the internet was a place where companies just push content to their users. But now the internet is a place where users can communicate and share their own content quickly and easily. And eventually, that led to this idea of web 2.0, which we’ve talked about before. But the reason that we bring this back up is that the web is a dynamic place now or the web is a more complicated place now. We have web 1.0. We had static web pages that didn’t change very often. And so that led to search algorithms that were significant easier to do because we were dependent mostly on text. And now we have dynamic web pages where the web page that I visit is entirely different than the webpage you visit even if it’s the same URL, because it depends on who’s logged in. It depends on your browsing history. Now we’re also looking at user generated content. So if you look at a Reddit post, right, Reddit trying to search Reddit, how does that show up in Google? Because new Reddit posts are made every single second. So how do you take that into account? How do you take into account multimedia pages, so things like YouTube videos, audio, songs, images, pictures of cats versus pictures of dogs when you’re trying to search that versus text. And this is an entirely different web that we live in now versus what we had in the 90s when early search engines were about. And so this is something that is going to be a continuous problem as we kind of move forward and as the web grows, but it’s just kind of highlighting the importance of this sophistication of the search engines that we are currently able to use.
Nine Algorithms that Changed the Future Ch 3 - Page Rank
Nine Algorithms that Changed the Future Ch 8 - Databases

Welcome back everyone. In this video series, we’re going to be taking a look at big data. So exactly how big is big data? So here’s a slide of the metric prefixes. And so which ones do you think constitute as big data? or big data? Today, we’re talking about data anywhere from gigabytes to petabytes and beyond. And the future, we may even be dealing with exabytes of data. I said, gigabytes, right. But I can have a single video or even in these lecture series, that might be a gigabytes worth of data. And in the grand scheme of things, right, that’s just one video. But if you break down that gigabyte worth of data, you can actually start to chunk that up into lots of different lots of different parts, right? If we’re recording in 4k, for example, as a significant number of frames per second in the video, along with a significant number of pixels. And if you tack on the sound information with that as well. It is a significant amount of information that can be packed into a single gigabyte, big data is going to deal with or one, how do we actually store all of this information? How do we use this information? And how do we get information out of it, right, because we can have lots of information. But without any algorithms or way or ways of actually presenting that information becomes pretty much useless at the end of the day.
So where is all of this data coming from? Right? A lot of what we actually come across in the current age is web 2.0 stuff, right? Social media, and video streaming services as well. So if we look at 2017 versus 2018, we can actually see a lot of different changes here. Specifically, right, we have 4.1 million videos and YouTube, versus 4.3 million videos watching YouTube and within the second year, so not a huge jump. But if we take a look at Netflix, the popularity of Netflix is has drastically increased from 2017 to 2018, from 70,000 hours, to 266,000 hours of video watched every single minute on the internet. And likewise with things like Snapchat, Twitter, Facebook, emails, all sorts of different things. And so this slowly evolves over time, as we even get to some of the older stuff, right from 2016 to 2019, which is previous year. So we went from 2.7 8 million views on YouTube to four and a half million on YouTube, and 700,000 pages on or 700,000 logins on Facebook to 1 million, the number of Google searches has drastically increased. So 2.4 million to 3.8 million Netflix, right, we’re up to almost 700,000 hours of Netflix wash per minute. And things like online shopping have also drastically increase sharing of pictures, things like Instagram, Snapchat, and music, right? Especially smart home devices as well. And even things like twitch are starting to gain significant in popularity as a mainstream streaming service as well. You kind of imagine the sheer amount of information that streams online every 60 seconds is quite mind boggling.
How do we actually make infrastructure that can support the scale of streaming of that information, live and in High Definition? Or in a quick manner, right? Because we don’t want to have to sit here and wait five hours in order to download a YouTube video like what we’d had to do in the late 90s, early 2000s things of that nature. So how do we create an infrastructure that can support this type of information? And how do we create software that allows a normal user to interact with that data in a meaningful way.
And that’s really where the Big Data stack comes into play. We can use all this all these tools and techniques not only to store information, but also also to view that information. This technique creates somewhat of a stacked approach here and management of the data where the bottom layer is going to represent all the providers of that information. And if we look here, we have things like MySQL, Postgres, Hadoop, all of these sorts of things, our databases, database technology, and some of them things like Hadoop are specialized in big data. So doing performing operations on very large amounts of information very quickly, and so We have speed on one access and scale on the other. So how fast is that particular technology at working with information? And how much information can it work with per second. So we have megabytes to petabytes, and batch processing, meaning we can process stuff on demand, but it takes a little bit of time for us to actually do it. And then real time, meaning that when we ask for our data, our data is there instantaneously. And we do not and we don’t have to actually wait for it to be produced.
In the middle here on our stack, this is going to be where all the analysis of that information is, at the bottom is where the data is actually being stored and provided into the analysis layer, where we use packages, like things like SciPy, and NumPy, which are Python, Python packages for scientific analysis, also things like mo hoot, which is a machine learning library, and all sorts of other information processing libraries that live at this layer. And this is where we’re going to do some things like machine learning artificial intelligence, we’re going to crunch that data transform that data to prepare it to be displayed to the user, which is done at the service layer.
Now the service layer at the top is where we all primarily interact with online. So when we go to Amazon, and we see those recommended items, or even if we open up Google News, or even Flipboard, or Pinterest, or whatever, those user curated websites and mobile apps, where we have our news articles that are presented to us, and a lot of those are curated for your viewing interest and reading interests. And so how do we take all of the data all of the news articles in the entire world and collapse them to a smaller bite of information in a smaller chunk bite sized chunks that you can consume as a user? How do you consume the data that you want to consume? And so that’s where these services come into play things like news curation, even weather forecasting, pricing of items online recommendation of items online, and even things like online reputation. So how do you gain reputation or fame on the internet for SNAP something that’s trending on YouTube, or Twitter, or Instagram or something like that.
But where is all this going? So we talked about some of the services that are provided using big data. But a lot of this is primarily used for business, right? We consume as users a significant amount of this information. But underneath the hood, a lot of this is being driven by business objectives as well. So customization of services that that everyone provides. So anymore, right with web 2.0, everything that we use online is a tailored service to you as the user. So your login information, if you have it on Google that is being tracked, right and all of that information that you do would online searches, websites that you visit, you have that digital footprint, that digital footprint allows websites and companies to provide a tailored service to you specifically, also allows companies to help react to certain market trends a lot easier. So what’s trending at the moment. And they can make business decisions on that information. They real time optimizations for identifying certain costs and making more accurate decisions. And really, overall better holistic rd, right better research and development processes that are available, because we have all this information available to us. And we can crunch that information in a meaningful way make better decisions for our company. We have a lot of that information that we that big data stack that we saw before, right? Where we have, what we can, how we are able to provide information through things like Hadoop, and we’ll talk about MapReduce later. There’s a lot of other technologies listed there. ETL. So extract transform right load.
So how do we take the raw data that’s being generated by things like smart devices and transform that in a way that is easily searchable queryable and presentable to users in the middle area, right? How do we analyze that data? So things like Mahout, SciPy, Hive, a lot of machine learning libraries here statistical software, and then the real business and objectives here the the task here so predictive modeling, sentiment analysis. So how do you detect if a tweet is positive or negative in terms of sentiment? Is this user tweeting negatively about my product or very positively about my project or my product? So these are a lot of the different things that we can achieve using big data techniques and technology to transform that information. A great example of some of these services that businesses can provide are, for example, Google Analytics, and Google Trends.
So Google Trends is actually one of my personal favorites, Google Trends. And I’ll attach this link in Canvas. But Google Trends allows you to actually see what’s trending on Google right as far as who’s searching what. So really interesting thing to look at is year in search. So you can look at what has been trending in the past years. So out of the entire out of all of last year, what was the top five or top 10 things that people actually searched online for? You can look up things like different holidays, politics, gaming, music, movies, you name it, you can actually find and compare who was being searched the most for on Google and the previous year, or even right now. And if you think about the number of sheer number of people that have actually used that use Google, if we look at last year, 2019 3.8 million Google searches per second or per minute, so there every 60 seconds, 3.8 million searches on Google. So how do we actually transform that into something that is usable, right, that’s all information that we can actually look at, and rely on and make decisions on what’s currently being popular, and so forth.
Another interesting service of that nature is healthmap.org. Now, healthmap.org is a website that was originally a research project. But what they do is they actually go in and collect all of these different news articles on the web, and consume them and look for outbreaks. So viruses, diseases, things like that. And where are those news articles are actually being written and try to geo locate those outbreaks on on a map in order to track disease outbreaks. Take a look at this. This is also so mapping, taking things like news articles, and trying to map them on a geolocation. This is called the thematic mapping. As I mentioned, this site tracks disease outbreaks mentioned online by location and provides a map showing the current outbreaks it costs the crunchy. And you can also look around the world a little bit as well, I’m just showing a screenshot here of the US. But this screenshot here was back in 2015, when we had a big outbreak of the bird flu. And so you can kind of see, for example, here, these are articles written in Leavenworth County, that identified an outbreak of bird flu in that region. As you can see, the color and the size of the dots kind of indicate the the size of that outbreak and severity of that outbreak. And we can even compare that to current events with the COVID-19 crisis, where we can see a lot of different dots across the US and certain regions and areas that have higher concentrations of COVID-19 cases that have been reported in the news.
So this is a really interesting way to consume news articles in order to track outbreaks of diseases. There’s also been very similar use cases of thematic mapping with Twitter data, specifically Twitter data with tracking the impacts of natural disasters as well. So things like hurricanes, tornadoes, and things and earthquakes and things like that. There’s a lot of different uses of big data as you can imagine. And we’ve only shown a different a couple different ones. A lot of the big topics are listed here, though, with things like topic modeling, where we can analyze text of an article for an for an example to determine what is talking about. So I’m given three articles. One of them is about a sports game. One of them’s about a sports video game, and one of them is about a sports movie. How can a computer to tell the difference between the different topics, right? They’re all about sports. But how do we write an algorithm to determine which article is about the video game, which one is about the actual sport game, and which one is about about the movie. So there’s a lot of different situations that topic modeling can help us solve and actually teaching computers to actually recognize a section of text and what that section of text is actually about because we’re computer understanding natural language Whether it be written, or spoken like natural language processing as extreme and as an extremely difficult task. So that’s what NLP or natural language processing is actually trying to accomplish here out as a computer understand spoken words. We’ve already talked about the analytics and data forecasting.
Now that’s things like the Google Trends, sentiment analysis, and crowdsourcing. We’ve talked about that all as well. So is your brand getting good reviews? Right? How do we tell if a comment or a tweet is positive or negative? Can you? Can you use that to figure out what the problem is? So a lot of companies are really great at using this, others probably not so much. A lot of things with big data are reduced down into information visualization, as well. So how do you make sense of this large amount of data? One way is to visualize it so people can easily understand it. And this isn’t like making a simple xy chart, or graph in algebra or even using Excel. These are large amounts of information. So how do we transform that into a visualization that makes sense and allows us to extract the information that we need out of it, or the interesting information that that is that exists in it. And we’ve also already talked about thematic mapping, where we can map out data items by location or even geolocation and across time to understand what’s going on in the world around us.
To really understand how big data can be useful, we can look at four different aspects that are usually referred to as the four V’s of big data. These are volume. So how much data there is a variety, how much or how little variety actually exist, velocity, just how fast data is being produced and or received. And veracity. How accurate is that data, there’s also a fifth fee, typically referred to as value. But we won’t actually include that in this particular lecture. But if you are looking at Big Data information online, you might see that fifth V out there called value. But let’s take a deeper dive into each one of these.
So volume of data, as I mentioned, deals with the scale of information. So how much is there. And so I was mentioned, this, and this graphic here is from a few years ago, but they mentioned that by 2020, there will be 40 zettabytes of data or 43 trillion gigabytes. That’s an increase of over 300 times more from 2005. And also 6 billion people have cell phones, which is an insane amounts of cellular devices. And if you think about how many of those are smartphones, which are generating a significant amount of information, right? It’s just amazing the amount of information that we are generating nowadays, especially with so many internet connected devices, things like smartwatches, smart cars, and even semi smart cars that aren’t truly self driving, but have electronics in them that generate information. And things like businesses, though, have increased the sheer amount of data that they’re dealing with now, as well, because 2030 years ago, there really wasn’t the means to actually buy one generate this kind of level of data, as well as store and store that type of information as well. So now we just basically store everything. And overall storage has become significantly cheaper than it has been in the past. And we can, technology has gotten a lot better. And we can store a lot more information in a much smaller amount of space.
Variety of data is really important as well. So what kind of information are we actually generating? And we already saw what happened in a an internet minute earlier in a previous video. So what does that really equate to as well, things like smartwatches, smart devices, internet connected devices, so smartwatches, smartphones, things like your IoT devices inside of your house, internet connected lights, and social media is a huge one, everyone is using some form of social media, whether it be Facebook, Twitter, Instagram, Snapchat, streaming services, YouTube, Twitter, YouTube, Twitch, Netflix, Hulu, all of those sorts of streaming services. And then we even also have health care. So 2030 years ago, healthcare was still all pure pencil and or pen and paper, right? When you went to the doctor’s office, they came in with your file on a clipboard and filled out all of your information. Now, if you go to the doctor’s office, majority of the time, they’re going to come in with a laptop instead of a clipboard. And so all of your information is now digitize your chart, all of your health information is online, or at least digitize instead of being an on physical paper. That’s 150 exabytes. And that was in 2011. Due to our reliance, of technology, and the fact that pretty much everyone is online almost all the time during the day, we’re generating a sheer amount of information in a variety of different contexts. And so that provides a lot more interesting use cases of the Information Network generating online and are in our daily routine.
The third V of big data that we talked about is velocity. So velocity deals with essentially the speed right of how we’re actually retrieving that information. So, for example, the New York Stock Exchange deals with one terabyte of trade information during each trading session, and 20. By 2016, there was an estimated amount of almost 19 billion network connections. So that’s almost two as two and a half connections per person on earth. And if we stop to think about how many devices that you can currently have are currently own, that are connected to the internet and at any given point in time, the lot, right? When I was a kid, we might have had one computer that was connected intermittently to the Internet through a dial up connection. But now I have a smartphone, a smartwatch, Alexa devices that are in my house that are always connected online, my TV has a wireless internet connection, your gaming devices have an internet connection. So the number of things that are connected anymore, the number of connections that you have to the outside world, have increased drastically, and so has the speed of which you have your speed of your internet connection is before right with a dial up internet connection, there’s only so much information I can be exchanged on the internet every second. But now with high speed internet access, many more people are able to generate and consume significant amount of more information than we ever have been able to before. And that’s not just typical devices that we experience. We even have things like cars, right cars are generating the sheer, more more amount of information that they ever have as well. Even if you don’t own a smart car, most modern cars come equipped with far more sensors that are actually can actually transmit back to even the manufacturer to tell them information about your vehicle. Or even just tell you more about your vehicle than what information that you would have had before. The last fee in the last fee that we’ll be talking about today is veracity, which deals with the uncertainty of information. And this is a really important one because we have a significant amount of information. And a lot of business revolves around that information as well. So recommender systems online on Amazon, Google searches, your digital footprint that you leave online, all of that information is consumed in some way shape, or form, whether or not be from the company that you actually use a service for and generated that information. Or you personally as a user for things like your your health, so smartwatches Fitbit trackers, that sort of thing.
Is that data accurate? Is that data valid? That’s where we’re dealing with the veracity or uncertainty of that information. And so this is a really interesting aspect here, one in three business leaders don’t actually trust the information that they use to make valid decisions. A little over a quarter of people done in the survey, were unsure about how much how accurate they’re getting, it actually was. This cost a significant amount of money, as estimated that poor data cost us about three and a half $3.1 trillion a year. So if you think about the number of businesses decisions that are actually made using this data, or the number of services that you use, that rely on big data techniques, or data that has been generated a lot, right, a lot of business revolves around that. And if that data is incorrect, or invalid, that’s money loss. And it can cause a lot of different controversies. And in some cases, and in terms of things like health care, borrows and various other things that can actually cost lives as well. So the veracity or certainty of data is an extremely important aspect of how we actually work with big data, how we store it, how we retrieve it, and how we actually analyze it.
One of the last things I want to talk about here with big data is some of the algorithms that we can actually use to work with this sheer amount of information. So one that I want to highlight here is called MapReduce. Oh, MapReduce is a very well known algorithm and big data realm. And now it’s been, of course, transformed significantly, since its original inception, inception, to handle even larger amounts of information. But the idea here is that we take a very large amount of information, let’s say text, and then we map it to smaller parts, break it out, and then we recombine that and to produce a final result. Okay. And so if you can use this as an example, right, if we’re trying to, let’s say, sort of deck of cards, okay, if I asked if I give you a whole bunch, or if I give you a full deck of cards that is completely shuffled, but I want you to sort it out in numerical order, as well as the suits would actually take you a little bit of time to actually achieve that task. But if I were allow it, if I gave you a deck of cards in a group, well, so let’s say I gave a group of 10 people, one single deck of cards, and I said, sort do the same thing, it will take them significantly less time than it will if I gave just one person a deck of cards to actually achieve that end result.
So that’s the idea of MapReduce, we partition our information out into very small parts. And then each of those small parts has the same task done to it. And once that task has been executed on the small parts, all of the end results are then combined to produce the final results. So let’s take a look at another example here with word count, which is pretty a real classic example of how MapReduce works. So our input here is a very simple section of texts. So a bunch of different words, dear bear, river, car, car, river, deer car bear. And so you can imagine this being a very large book or something like that. And we want to count the count the occurrences of each word in our in our data set. So first thing that we do here, let’s split this data out. So let’s say that each line of text here is our initial split. So deer, bear, river, car, car, river, and deer car bear. So we have these three, these three data sets that are that are our big data set has been split into these individual data sets. Where each the key value we have key value pair, where the key is this as a document, the value is the the text that we actually contain. So each of these documents here are then going to be mapped to a task. And our task here is to count the word occurrences.
So in this mapping task, I’m going to map each word to a number. So each word of course, and individualized is only going to occur once. So deer occurs once bear occurs once and river occurs once. The key here is going to be word and the value here is going to be of course, the word count. As you can see down here in this middle example, where we have two cars, that’s okay, because it’s individual tasks, remember, so each car is still going to be one key value pair here. Because the important part actually comes in the next step. And the next few steps here. So we’re actually going to shuffle this out on the shuffling process is going to take care of essentially sorting the result of our mapping process. Because once it’s actually sorted, it’s a lot easier to easier to actually reduce and combine. So when we actually shuffle all of the bears and get put in one bin, all the cars get put in one bin, all the deer get put in one bin and all of the rivers get put in one bin.
And then all that happens here is actually the reducing so we actually combining one more step actually combining the information. So we sum the word counts. So bear occurred twice, car three, deer two and river two. So we’ve taken all of the individual words here, counted them and sorted them out and summed them. And then the final reduce phase is we’ve combined this all back into a single list, where the key is the word and the value is the total word count over the entire day. To set. But you can imagine this to be significantly faster than having a one single process or one single out or one single computer doing this, we can use this on things like Beocat, a distributed computer system where we can throw a split the data set up and onto a lot of different processors and have each processor each thread actually execute the mapping, shuffling and reducing task. And then they all come in back together at the end to form the final results. But this is just one of the big data algorithms out there. There’s obviously a significant amount of other types of techniques and algorithms and tasks out there, that big data can actually accomplish. So we’ve just scratched the surface here. But if you’re interested in learning more, please reach out and we happy to actually connect to you with more resources.

![]()
![]()
Hello there, my name’s Gavin, and welcome to this episode of The Slow Mo Guys very oddly presented from my living room.
A while ago, I made a video called “How a Camera Works In Slow Mo”, and the response was great. So I thought a good natural progression to that video would be how a TV works in slow mo.
This is an 85-inch LCD TV, and whenever I’m playing something on it or watching something on it, my eyes and brain are being misled and tricked, giving me the illusion of watching a moving object when in fact I’m just watching several still images just shown to me very, very fast. If I’m watching a film, I’m being shown 24 images every second, and to my eyes, that looks like I’m looking at a moving object when in fact I’m looking at 24 individual pictures. If I’m playing a game, it’s the same, except maybe 30 to 60 frames a second, and if I’m on a PC, it could be 100s, PC master race.
But a TV like this is actually incapable of showing you one image and then 1/24 of a second later just switching all at once to the next image, and to illustrate this next point, I’m gonna use a very old and very crap CRT TV. That stands for cathode ray tube. If you’ve ever seen one of these filmed, you may notice that it looks slightly different on camera than it does to your eye. Look at that.
The reason it looks like this is because the shutter speed of this camera is out of sync with the refresh rate of this screen. The frame is constructed from the top to the bottom multiple times per second; that’s 60 times in the US, 60 Hertz. I’ve prepared for you some high speed footage that I shot a long time ago on the v2511 of this screen and this screen and some others. A lot of it is Dan paying “Super Mario” on the NES extremely badly.
Here’s the TV and the cat played back at 25; this is how it would be perceived in real time. And now at 1600 frames a second, you can actually see the scan line moving from the top to the bottom, and you’ll notice that on a CRT screen, it’s only the active line of pixels that’s bright, and your persistence of vision will actually build that into a complete image. It’s messing with my eyes, this. - It’s like a dance floor. Oh, I didn’t even make it past the first guy. -
Slowed all the way down to 2500 frames a second, you can now differentiate each individual frame being built from top to bottom. It takes an extremely fast camera to see that each frame is built line by line from top to bottom, but it takes an even faster camera to see that each line is drawn from left to right. Slowed down to 28,500 frames a second, we’re now seeing glimpses of that, but we do need to go even slower. This is now 118,000 frames a second, and I’m gonna put the stats up for you here so you can see the actual amount of time that it took, and you can see now that the line is being drawn from left to right on the screen.
Now at 146,000 frames a second, to gain perspective on just how slow this actually is, you can see the exact time I shot this. So this is hours, it was just past midnight, 23 minutes, 41 seconds, this is 1/10 of a second, 1/100 of a second, 1/1000 of a second or a millisecond, and then over here you’ve got 1/10,000 of a second, 1/100,000 of a second, and this unit here is the millionth of a second, or a microsecond.
We are now at 380,000 frames a second as our recording frame rate. That is the highest frame rate we’ve ever shot so far on this channel, and using this information, here’s a little bonus fact: a CRT screen can draw Mario’s mustache in less than 1/380,000 of a second. That is some seriously fast facial hair.
And if you’re wondering why this footage looks extremely mucky and blurry, it’s because the resolution is only 256 by 128, which, plonked into a 4K frame, is this big. That CRT screen is standard def; this is a 4K screen, which means it’s 3840 by 2160 pixels. That’s over eight million pixels. So think of the processing power that this TV has to have to update an image that big that many times every second.
The first thing you’ll notice about a modern LCD screen is that it’s not only the active line of pixels that retains brightness; it’s the entire image. So you can actually see the full image as each scan-line passes down the screen. This is every frame of the start-up sequence on an Xbox One. I also recorded myself playing a game of “Halo”. Nothing will make you feel worse about your performance than watching your lousy aim in slow mo, look at that. It’s crazy to think that when you’re playing “Halo”, this is actually what is happening on your TV. If only you could see at this speed, your aim would be incredible.
It honestly makes me feel bad when I fall asleep watching TV, knowing that this TV is doing all this intensive work changing literally 10s of millions of pixels every second, and there’s no one there watching it. Here’s a fun fact: the same applies to an iPhone, except it’s in portrait mode. So if you’re watching a video in landscape mode on your iPhone, you’re actually getting updates from left to right, or right to left, depending on which way you’ve flipped it, and that just proved to me that you can’t see the refresh direction with your naked eye, because I had no idea, whenever I was watching a YouTube video on my iPhone, that the screen was updating in a completely different direction. I’m not sure if this is the case for all smartphones, but it’s certainly the case on an iPhone 7 Plus, which is what I filmed this on.
So we’ve talked about one illusion of TVs, the illusion of movement. The second illusion I wanna talk about is the illusion of color. For this next part, I’m gonna need a second camera. Here’s one, that’s you, hello, you. So in order to film this screen extremely close, I’m gonna have to set my focus to the minimum possible distance, so it’s sort of like right here now.
Set to my minimum focus, as I slowly move towards the screen, it becomes sharper, and you will then, at the last minute, see a very odd looking pattern. And what you’re seeing there is an effect caused by the camera, this camera, trying to resolve individual pixels on the surface of this screen. As I push further forward, the effect disappears, and everything goes out of focus. That’s because I’m now beyond the minimum focal distance of this lens, which is about, well, that’s about there. Not close enough. In order to get closer, I’m gonna need a macro lens.
Here’s one. As I approach the white, and everything starts to become in focus, you can see that white isn’t so white anymore. It looks like I have to go closer even than that. Thankfully, I can go all the way to five times magnification. Now, one thing from this point, I am definitely gonna need a tripod, because there’s no way my arms are sturdy enough to hold this in place, but I’ll just ease it in just to show you the level of magnification we’re talking about now. Well, this close, it’s a different story altogether. I’m gonna get a tripod. Here’s one.
What a mission this is, all right, let’s see what we can do here. We’re so close up right now that I can actually disturb this image by blowing on the lens. We’re now looking at the sub-pixel level. A pixel is made up of three sub-pixels, red, green, and blue, RGB, you may have heard that before, and this creates the illusion of different colors. By dimming and brightening different sub-pixels to different intensities, this screen can create the illusion of literally millions of different colors. When all three are lit to full brightness, you get white. When all three dim, you go through gray all the way down to black. So if green dims away, and red and blue are still lit, then you go into magenta, purple, that sort of area, and that’s how the colors are made. So every time on your TV you’re looking at a white image, you’re looking at tons of blue, green, and red lights. They’re just so small they look like white to your eye. Before you get white; red, green, and blue blurs into yellow, cyan, and magenta, and that’s what happens here when I move the screen slightly out of focus.
This is too close to watch a Slow Mo Guys video. I might vomit. It’s the same situation, just entire blocks and they’re bigger. As I mentioned before, this is a 4K LCD screen, which, a while back, were typically lit by CCFLs, or a cold cathode fluorescent lamp, which means the entire panel is backlit by fluorescent tubes. Nowadays, they are backlit by LEDs. This is why this would actually be marketed as an LED TV. The benefit of LED screens over CCFL screens is that they’re a lot thinner.
Now I’m gonna point it at where some black text is. Now, interestingly, even though this area is black because all the sub-pixels have dimmed, they are still in fact backlit. Let me show you that right now. Now you can see, as we push in here, you have to pardon the noise, we’re at an extremely high ISO to get this shot through a macro lens, but you can see even the dimmed pixels, part of the liquid crystal display as it’s now trying to block all light from penetrating through, but it’s still a backlit pixel, and that’s one of the fundamental limitations of an LCD screen.
You can see this effect on an LCD screen in the credits of a film, ‘cause you’ve got an almost completely black image, but because there’s white text, the entire backlight has to be on to display the white, which means light will leak out from the black pixels, which means it’s not true black. There is another technology that’s becoming much more common these days, and that is an OLED screen, organic light-emitting diode. I did wanna include a comparison between an LCD panel and an OLED panel, but I didn’t actually have an OLED TV, and by sheer luck, right in the middle of me shooting all this footage, LG got in touch and offered to supply me with an OLED TV for the purpose of making this video, which I really appreciate. Thanks, LG.
Why don’t we go and take a look at it. This is a 77-inch LG OLED TV. The way OLED technology works is that each pixel is self-illuminating, depending on how much voltage is passing through it, which means there’s no global backlight on the TV. Each pixel is individually in control of how bright it is, and it’s not being lit from behind. And that means, when we go to our high ISO experiment, just like we did on the LCD, that when there’s an area of black on the screen, all of those pixels are off, and you can see here where I’m putting my cursor in front of the lens, you can see each sub-pixel lighting up and then completely turning off when it goes away. This technology means much deeper blacks, and the possibility of a very thin screen. And there you have it: a brief explanation of how a TV works in slow mo. If you found that video interesting, chances are you might find some other videos interesting on this channel, so make sure you boop, and once you’ve booped, feel free to check out our it’s just there. Thank you very much for watching. That was good timing, weren’t it? TV timed out, and now there’s fireworks.
Watch this trailer for “Tin Toy” for a precursor to the uncanny valley.
