This is a free, online textbook for anyone interested in teaching Computer Science at any level. For those who do not come from a computer science background, it provides a brief exploration of the field, its history, and foundations. It also introduces the current understanding of how people learn computer science emerging from philosophy of education and cognitive science. Then it covers teaching approaches, lesson design strategies, and useful tools for teachers to adopt in their efforts.
Subsections of Teaching and Learning Computer Science
Introduction
What is Computer Science?
Subsections of What is Computer Science?
Introduction
If you are reading this, you are most likely getting ready to teach a course or unit on computer science. Congratulations!
But before we delve into how to best teach the subject, it is important to first understand what computer science is, and how we learn it. This chapter will address the first of those topics - what computer science actually is as a discipline, and why we want to teach it to our students.
The Discipline
Broadly speaking, Computer Science is:
The branch of knowledge concerned with the construction, programming, operation, and use of computers. (Oxford English Dictionary)
As this definition suggests, Computer Science lies at the intersection of computer hardware, computational techniques, and problem-solving approaches (computational thinking).
It is a relatively young discipline, only emerging as a distinct academic area in the 1950’s and 60’s. Prior to this point, people building and working with computers were drawn from related disciplines: mathematics, engineering, physics, linguistics, and philosophy.
In this chapter, we’ll examine each briefly before discussing how people engage with the field.
Computing Hardware
Computer hardware actually has a long and storied history. Early computers included devices like the Antikythera mechanism, a clockwork device for calculating the positions of the planets built in first or second-century BC in Greece and mechanical calculators incorporating the Leibniz wheel. These early devices can be classified as fixed-program computers, as they can only carry out specific kinds of activities as determined by their structure.
Charles Babbage invented two computing devices, the Difference Engine and the Analytical Engine, both mechanical computers that carried out calculations, that were notable for their size and complexity. The Analytical Engine also marked the first programmable computer design - one that could be easily reconfigured to carry out different kinds of operations. In describing the function of this computer, Ada Lovelace proposed using the computer to compose original music, marking the first time computers were considered for broader use than computations.
Info
Babbage’s Difference Engine No. 2 was designed in 1840, but never built until the modern era. This video discusses that effort spearheaded by the Science Museum of London.
The Z3 and ENIAC were some of the earliest electronic computer devices. They used transistors (switches that could be on or off) to represent data. With only two states, these computers were designed to operate with binary math - 0’s and 1’s. This was a major departure from earlier approaches which operated in the more familiar base 10 (Babbage’s engines represented digits by wheels with 10 faces). Both were programmable: the Z3 read its program from a punched tape, while the ENIAC could be programmed through the use of a plugboard similar to those used by phone operators. The Z3 was considered non-vital by the German military, and was later destroyed in bombing. In contrast, the ENIAC was used to carry out calculations to support American World War II efforts (including carrying out calculations for the atom bomb), and during this time was exclusively programmed by women mathematicians, including Kay McNulty, Betty Jennings, Betty Snyder, Marylyn Wescoff, Fran Bilas, and Ruth Licherman. Their story is discussed in the documentary Top Secret Rosies: The Female “Computers” of WWWII.
The next major step forward was stored program computers - computers that had a limited number of instructions they could carry out that were stored in the computer’s memory along with the data on which those programs would operate. These were originally proposed by Alan Turing with his Turing Machine. The physical design on which modern computers are all based was popularized by John von Neumann and is known as the Von Neumann Architecture.
Thus, modern computers share certain characteristics:
They represent all information in a binary form
They can carry out a handful of operations on this binary information
These instructions can be triggered by programs, sequences of these operations
Both the programs and the data they operate on are stored in the memory of the computer
But hardware is only part of the picture. The programs that run on them are just as important. We’ll turn to these next.
Computer Programming
As described in the previous section, modern computers have a limited instruction set that largely concerns moving binary data between memory and CPU registers, and performing mathematical operations on data in those registers. Programs are expressed in ‘assembly code’ or the binary equivalent ‘machine code’ and are essentially sequences of those commands. For example, a program to print the line “Hello World” looks like:
global_startsection.text_start: movrax, 1; system call for write
movrdi, 1; file handle 1 is stdout
movrsi, message; address of string to output
movrdx, 13; number of bytes
syscall; invoke operating system to do the write
movrax, 60; system call for exit
xorrdi, rdi; exit code 0
syscall; invoke operating system to exit
section.datamessage: db"Hello, World", 10;notethenewlineattheend
Writing programs in assembly code is a considerable challenge. Thankfully, visionary programmers like Grace Hopper, Betty Holberton, and Adele Mildred Koss realized they could use programs to write portions of other programs. Grace Hopper took this to the next logical step, writing a program that could translate a more human-friendly language into machine code, known as FLOW-MATIC.
In her later contributions to COBOL, Grace Hopper successfully advocated for expressing program instructions in English. This concept of compiling a human-readable programming language (a higher-order programming language) into machine code is the basis of all modern programming languages: C/C++, Java, Python, JavaScript, C#, etc.
Thus, the same program as above expressed in Python becomes:
print("Hello, World")
Much easier to understand!
Programming languages have continued to evolve, introducing new syntax and organizational approaches intended to make it easier to write programs, reduce errors, improve security, and encourage good programming practices.
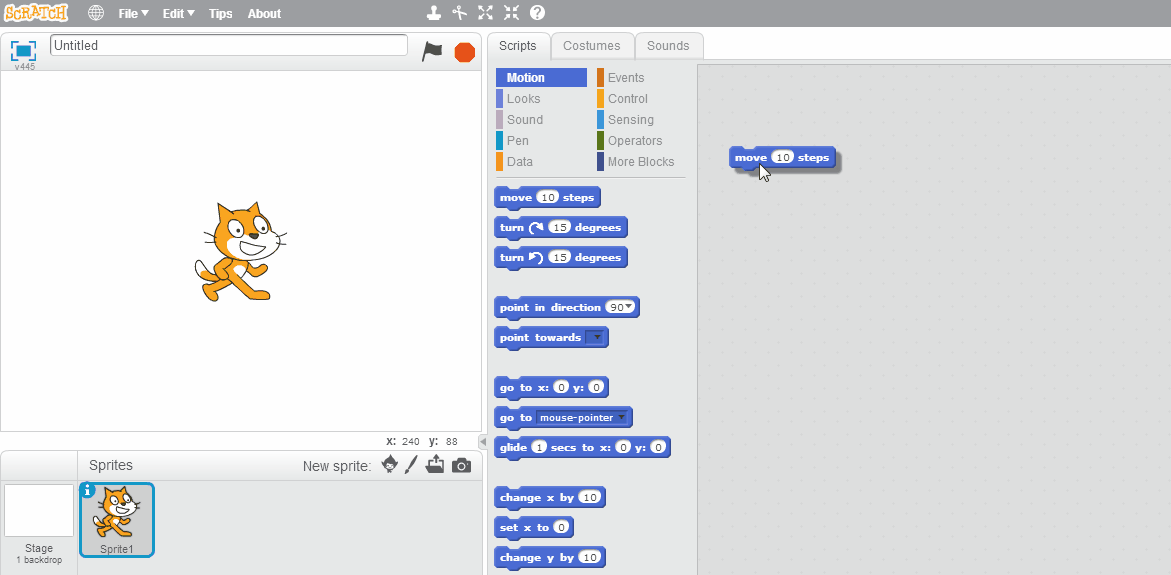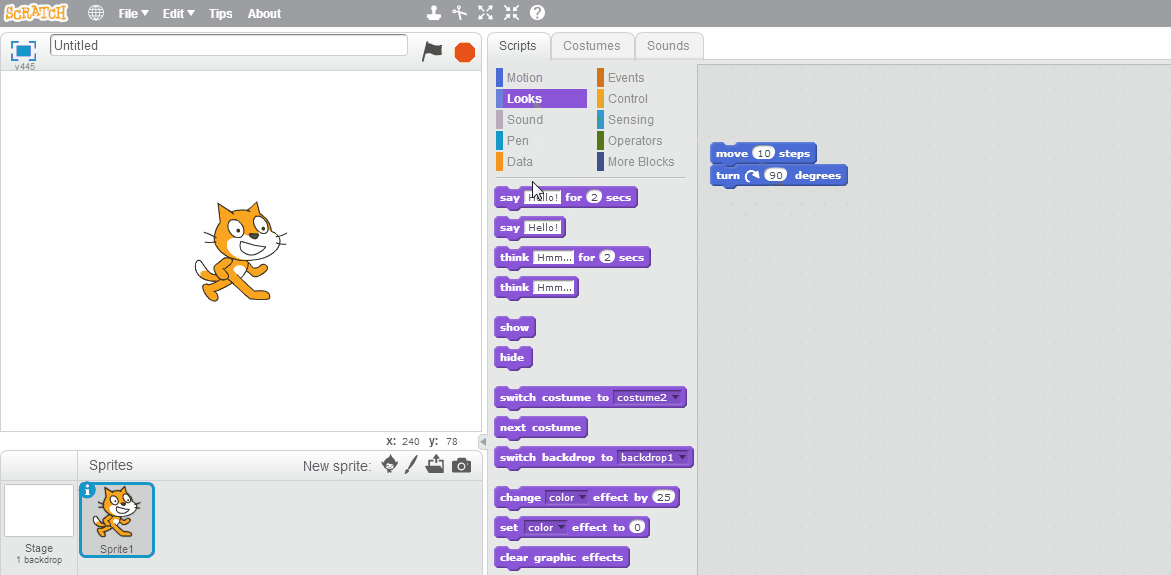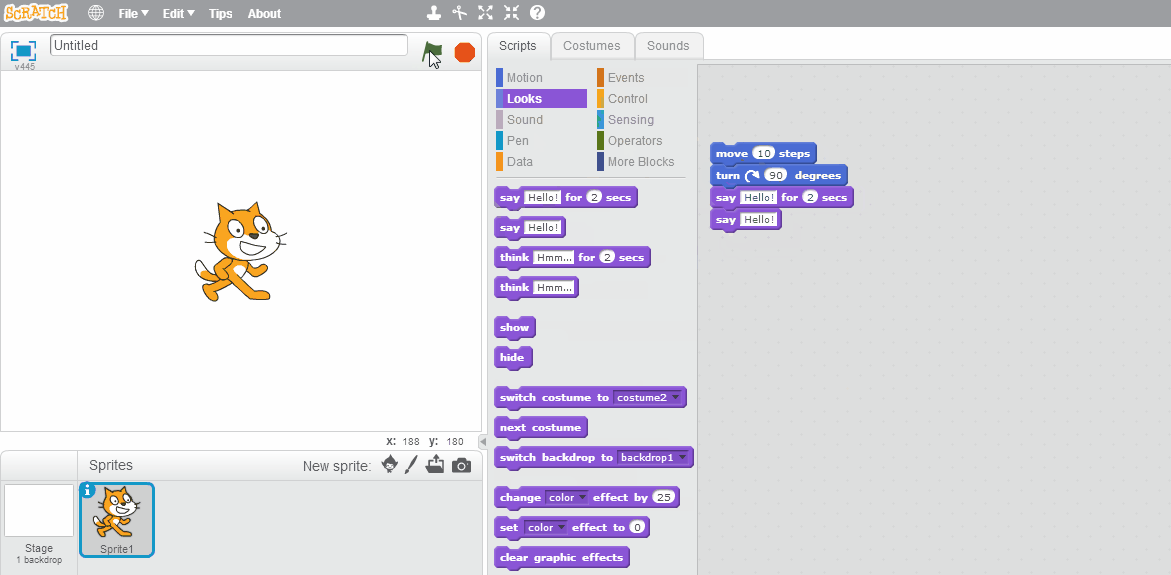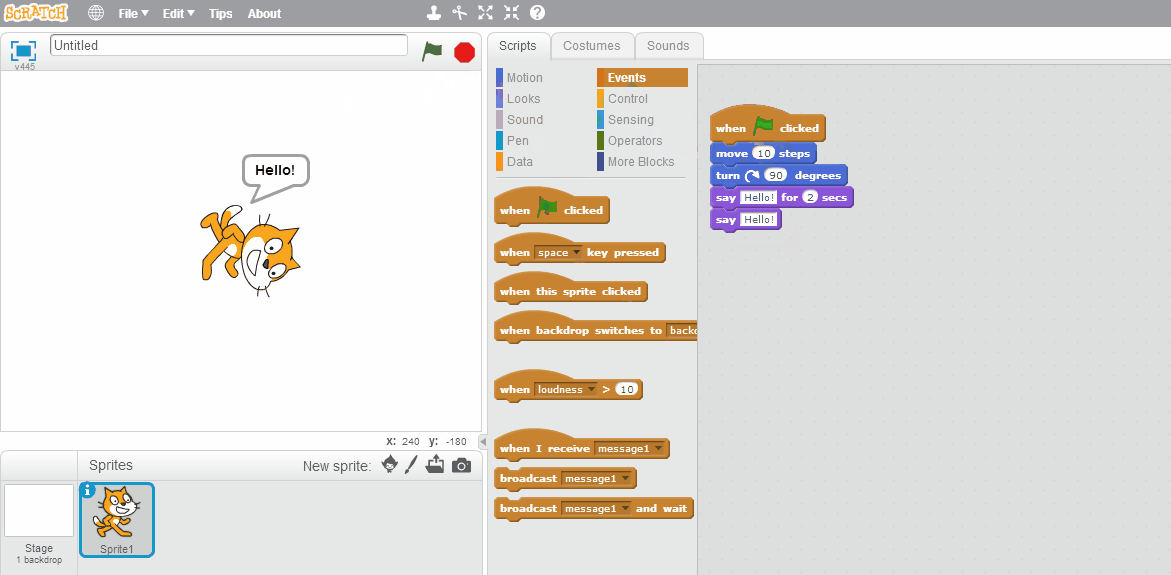
One advance in programming languages that is of especial interest to teachers are block-based programming languages like Scratch and Blockly. Instead of typing the program source code, in these languages you assemble the code by connecting graphical blocks. This approach avoids the possibility of an entire family of syntax errors, as the blocks will only snap together in ways that the compiler can interpret. As such, it makes learning to program more approachable for novices.
The same program as above in Scratch is:
Block-based programming is a great starting place for learning programming and computer science. But writing code by dragging and dropping blocks is also slower than typing, and eventually most programmers will transition to learning a text-based language.
Info
What is in a Name?
You may have noticed that the practice of writing programs has multiple names, for example: programming, coding, and hacking. Likewise, programs themselves have multiple names: programs, applications, apps, and software. You may wonder if there is a difference, and what should we call them?
When we write a program using a higher-order programming language, what we have written is the source code. Thus, programming or coding make a lot of sense. The term programming carries a slightly more serious connotation, while coding seems lighter and more fun - which is probably why it has been adopted by the Coding movement which advocates for getting kids involved in programming. Nonetheless, the two terms can (and are) used interchangeably.
Hacking is a bit more problematic. It suggests a more free-form approach to programming, such as ignoring guidelines on how to structure code to be readable to others. Moreover, the term also encompasses the exploitation of computer technology for committing crimes. So it is probably best to avoid using it to refer to the practice of writing programs.
Similarly, a compiled program is an application (app for short). More broadly, an application is a program intended to be used by a person, while programs and software may instead be intended to be run by other programs or directly control a mechanical system (i.e. a robot vacuum cleaner). As programs are stored in memory in a stored-program computer rather than being built into the computer’s physical architecture (the hardware), we can also call them software.
Intellectual Workers
In his landmark address now known as The Mother of All Demos, the computer scientist Douglas Engelbart introduced an early computer operating system developed at SRI. This system and demo introduced ideas like the computer mouse, graphics, hypertext, hyperlinking, collaborative real-time editing, videoconferencing, and screen sharing. These ideas became the basis and inspiration for both the Windows and Macintosh operating systems, as well as the World-Wide Web.
Info
SRI released the full recording of Douglas Engelbart’s demo to YouTube, and the playlist is embedded below. Be warned - the full presentation is 1 hour and 45 minutes (which helps explain the nickname “Mother of all Demos”)
In proposing these technologies, Engelbart suggested that they would support the development of a new class of “Intellectual Worker,” a new class of worker that would use computers to communicate, structure, store, and retrieve data and use computer technology to augment their natural problem-solving capabilities. The introduction of the personal computer in the 1980’s accelerated the development of this class of worker, who primarily relied upon programs built to support various efforts (i.e. a word processor for writing documents, an email client for sending emails). Thus, an intellectual worker was primarily a consumer of programs written by computer scientists.
However, as computing hardware became more available and widely used increasingly intellectual workers began to author their own programs to meet the specific needs of their work. This exploration of programming within specific domains has transformed the way we approach problems in multiple fields:
We have witnessed the influence of computational thinking on other disciplines. For example, machine learning has transformed statistics. Statistical learning is being used for problems on a scale, in terms of both data size and dimension, unimaginable only a few years ago. […] Computer science’s contribution to biology goes beyond the ability to search through vast amounts of sequence data looking for patterns. The hope is that data structures and algorithms – our computational abstractions and methods – can represent the structure of proteins in ways that elucidate their function. Computational biology is changing the way biologists think. Similarly, computational game theory is changing the way economist think; nanocomputing, the way chemists think; and quantum computing, the way physicists think. (Jeanette Wing, 2006, p. 34)
In other words, intellectual workers are increasingly using the tools of computer science, not just the products. This realization has driven the call for teaching computer science in K-12 education - as today’s students will increasingly need to be able to use computational thinking and programming in their future work, even if they aren’t going to be a computer scientist.
Computational Thinking
The term “Computational Thinking” has recently caught on as a way to describe how we can approach problem-solving using computation. While there is some debate on exactly what constitutes computational thinking, I like the definition:
Computational thinking is the thought processes involved in formulating problems and their solutions so that the solutions are represented in a form that can effectively be carried out by an information-processing agent.
In other words, computational thinking is about reformulating problems. You’ve already done this in your own education. Remember word problems like:
Two trains leave a station, one a passenger train traveling east at 8 miles per hour, and one a freight train traveling west at 12 miles per hour. The two stations are 521 miles apart. Assuming the two trains are traveling on parallel tracks, how much time will elapse before they pass each other?
To solve this, you probably would reformat it into algebraic formulas:
In this example, you are the information-processing agent. You reformulated the problem into a form you knew how to solve (algebraic expressions).
But when we talk about computational thinking, the information-processing agent we are typically referring to is a digital computer. We need to structure the problem in a form it can process - a program. Thus, computational thinking is really about taking real-world problems and reformulating them as programs that solve them.
Note that we need two separate but related skills to do this - we must be able to come up with an approach to find a solution, and we must know enough programming to express it.
Summary
In this chapter we discussed what computer science is as a discipline and explored a bit of its history and foundations. We also discussed computational thinking, a problem-solving approach that leverages the tools of computer science - computers and programs - to solve problems. We briefly covered how computational thinking is transforming how people solve problems in their disciplines, which helps explain why it is increasingly necessary to teach it to our students.
In the next chapter, we will look at the science behind how people actually learn computer science and computational thinking.
Learning Computer Science
Subsections of Learning Computer Science
Introduction
Now that you understand a bit of what computer science is as a discipline, we will turn our attention to how it is learned. Understanding the learning process is key to effective teaching, especially in how it is grounded in a domain (like computer science). Once you grasp how learning occurs:
You will be more aware of what challenges your students are facing
You will have a better grasp of how to support their learning
You can better evaluate or develop pedagogically-grounded lessons for your teaching
As we go through this chapter, remember that computer science is all about solving problems with computers through programming and computational thinking.
Natural Born Programmers
There is a prevalent myth that some people are “natural born programmers” to whom programming comes easily. This is a dangerous idea, as in accepting it, you are also accepting anyone who struggles learning programming is not meant to be a programmer.
Warning
This idea is especially dangerous idea for a teacher, as accepting it will cause bias in how you interact with your students. Research has consistently shown that this kind of unconscious bias on part of teachers subtly but effectively influences students’ interest and effort in learning computer science. We’ll explore this and related issues more in a later chapter.
The truth is that in learning to program, we are learning to solve problems in a way that can be performed by a computing machine. As we discussed in the previous chapter, this must be expressed in a programming language that has a limited and specific set of operations it can carry out. It has no ability to interpret our intent - only the ability to carry out instructions exactly as written and only if these are written in a language it knows.
As a way of exploring these limitations, see how giving instructions to a “computational agent” goes for the Darnit family:
The point of this exercise is to understand the exactitude or precision with which programs must be written. But it also reveals just how different people are from computers. The simple truth is that to become good programmers, we must learn to write programs by developing an understanding of how the computers work, as well as how to express instructions in a form they can use.
The rest of this chapter is devoted to understanding that learning process.
Genetic Epistemology
You have probably heard of Constructivism, a theory that states as we learn we are ‘constructing’ a mental model through which we understand the world. The foundations of this philosophy arise from the work of Jean Piaget, a biologist and psychologist who performed some of the earliest studies on knowledge acquisition in children.
Of especial interest to us is his theory of genetic epistemology. Epistemology is the study of human knowledge, and genetic in this sense refers to origins i.e. the genesis, so his theory concerns how knowledge is created by humans.
Piaget’s genetic epistemology was inspired by studies he conducted of snails of the genus Lymnea native to the lakes of his home, Switzerland. He was able to establish that what had previously been considered different species of snails based on the shape of their shells were actually one species. He showed that when the snails of one lake were placed in a different lake, the way their shells grew changed to match those of the snails living in the second lake. In other words, the traits the snails displayed altered in response to their environment.
Piaget suspected a similar mechanism was at work in human learning. He proposed that the human brain, much like the bodies of the snails, sought to exist in equilibrium with its environment. For the brain, this environment meant the ideas it was exposed to. He proposed two different mechanisms for learning, accommodation and assimilation, which related to how structures of knowledge were formed in the brain.
Assimilation referred to the process of adding new knowledge into existing mental structures. For example, once you know of and understand colors, you might encounter a new one - say periwinkle, which falls between blue and violet. Since you already know blue and violet, adding the knowledge of periwinkle is a straightforward task for the brain of assigning it to a slot between the two in the mental structure of ‘colors’.
In contrast, accommodation refers to the process by which knowledge for which you have no mental structures to represent are learned. This process involves building these mental structures, and is far more work. Modern cognitive science equates this process to the formation and reinforcement of new connections between neurons - a significant biological investment. Thus, triggering accommodation requires significant stimulus, in the form of wrestling with concepts that are currently beyond your grasp - a struggle that creates disequilibrium for your brain, eventually leading to it creating the new structure to accommodate the new knowledge.
This is the basis of the ’eureka’ moment, when a difficult concept has finally become clear. No doubt you have experienced this in a subject such as mathematics or programming, where a skill or idea you’ve been struggling with suddenly snaps into place, and becomes far easier to work with. This is also why your math and programming courses put so much emphasis on homework - this work helps create the disequilibrium you need to trigger accommodation.
This understanding of the process of knowledge acquisition and accommodation have some important implications, as well as tying into other theories of learning. Let’s look at those next.
Cognitive Load
The theory of cognitive load suggests that we can only hold five to nine pieces of novel information in our working memory at a time. This working memory is the information at the “tip of your mind.” Have you ever walked upstairs to get something and forgotten what it was by the time you got there? This is because it passed out of your working memory (likely to make room for something new that distracted you on the way).
If this is the case, how do we get anything done? We create mental structures that allow us to store multiple pieces of information in schemas, essentially, patterns of information that can help us work with it, as a schema populated with information is treated as a single chunk by working memory. These schemas can help us organize information and also automate behaviors.
Remember learning to drive a car? How you had to pay attention to so many things? What was on the road ahead of you, what was behind you, next to you. What your control panel was displaying? How fast you were going? What the speed limit was? Likely you found it difficult to keep all of that in focus - but as you developed schema to help with it, driving became much easier. Possibly to the point that sometimes you don’t even remember how you got to your destination!
Creating new schema is essentially what the process of accommodation is. And once those schemas exist, learning new information that maps to them is the process of assimilation. For example, once you’ve learned what mammals are and several examples of mammals, learning about a new one is mostly a process of determining how it compares to the ones you already know about.
Understanding cognitive load can help us teach better, because we can take steps to reduce the number of pieces of novel ideas our students need to grapple with until they can develop their schema. Building scaffolding into early lessons and then gradually removing it is a key strategy. Also, cognitive load can help us better understand the challenges faced by students with ADD - in this condition, the brain has trouble determining what information should be held in working memory, and often displaces it with other sensory information.
Mindsets
Carol Dweck is a researcher who has been developing a theory on Mindsets, which are individual beliefs we each possess about what we are capable of learning. She describes her research in the following Ted Talk:
Essentially, her work identifies two common mindsets - a fixed mindset, which suggests that you have an innate capacity for learning a subject that cannot be exceeded, or a growth mindset which suggests that with practice and effort, you can continue to learn.
These mindsets influence how we cope with the cognitive disequilibrium from Piaget’s Genetic Epistemology. Remember, this disequilibrium is necessary to trigger accommodation - the process of building new mental structures. But it is also uncomfortable and frustrating - we often describe it as “hitting a wall” or “banging my head against a problem.”
Students with a fixed mindset encountering this disequilibrium assume they’ve reached the limit of what they can learn in the field. As you might expect, they don’t see the point of continuing to try. Instead, they look for other ways to relieve the discomfort that the disequilibrium is creating. They may act out, withdraw from active participation, drop the course, or even engage in cheating.
In contrast, students with a growth mindset believe that with more effort, they can persevere and learn what they are struggling with. Thus, they continue to try. And in doing so, they will eventually resolve that disequilibrium by the process of accommodation - building those new mental structures that allow them to reason about programming and computational thinking in new ways.
With this in mind, fostering a growth mindset should always be a goal while we teach computer science. Also, be aware that our mindsets are discipline-specific: a student can have a growth mindset in one area (like science) and a fixed mindset in another (i.e. mathematics).
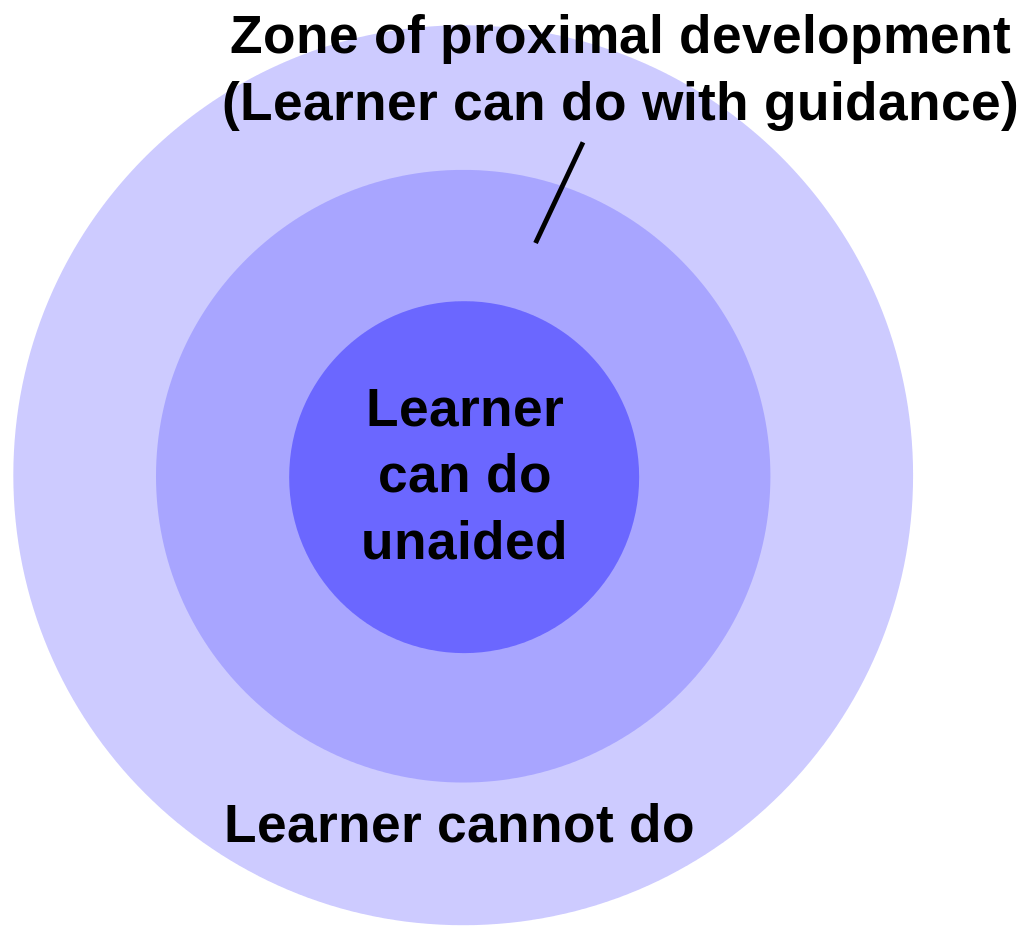
Zone of Proximal Development
Another theory that often is referenced with teaching and curriculum development is Lev Vigotsky’s Zone of Proximal Development. This zone represents the distance between what a student can do unaided, what they can do with assistance, and what they are incapable of doing.
As a student learns, the central zone (what the student can do) grows, reflecting the development of new cognitive structures in their mind that support the knowledge and skills they need to use.
As that central zone grows, the zone of proximal development is likewise pushed outward. From a genetic epistemology standpoint, this zone represents the “right” amount of challenge to create enough disequilibrium to trigger accommodation, but not so much to overwhelm the learner.
Keeping this zone in mind when developing or selecting curriculum materials is especially important - you don’t want your tasks to fall too far into the center zone (representing boring make-work), or in the outer zone (too challenging for the student to even know where to start). You want to keep the tasks firmly in the students’ zone of proximal development. We’ll discuss strategies for this in the next chapter. But before we do, we’ll return to Jean Piaget and some of his other theories.
Stage Theory
In addition to the mechanisms of accommodation and assimilation Jean Piaget outlined in his Genetic Epistemology theories, Piaget identified four stages children progress through as they learn to reason more abstractly. Those stages are:
Sensorimotor - where the learner uses their senses to interact with their surroundings. This is the hallmark of babies and toddlers who gaze wide-eyed at, touch, and taste the objects in their surroundings.
Preoperational - in this stage the learner begins to think symbolically, using words and pictures to represent objects and actions.
Concrete Operational - In this stage, the learner begins to think logically, but only about concrete events. Inductive logic - the ability to reason from specific information to a general principle also appears.
Formal Operational - This final stage marks the ability to grasp and work with abstractions, and is marked by hypothetico-deductive reasoning (i.e. formulating and testing hypotheses)
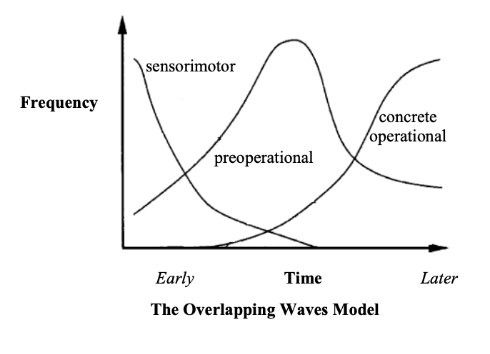
Neo-Piagetian Theory
While Piaget focused his study on children, many of the researchers who followed him also looked at how adults learn. Their findings suggest that all learners progress through the four stages with any new learning. That is, when you begin to learn a novel concept or skill, you are building the cognitive structures necessary to support it, and that your progress through this process corresponds to these four stages. Moreover, they have found that the divisions between stages are not rigid and clearly delineated; learners can exist in multiple stages at once (which they call the overlapping waves model).
Neo-Piagetians have gone on to create domain-specific theories expounding on these ideas. We’ll take a look at one grounded in the discipline of programming next section.
Developmental Epistemology of Computer Programming
Among these neo-Piagetian researchers is a group including Raymond Lister and Donna M. Teague whom applied these theories to the learning of computer science, formulating a theory Lister calls The Developmental Epistemology of Computer Programming. This theory describes the traits of programmers at each of the stages of development. In particular, they use a student’s ability to trace code (explain line-by-line what it does) as a demarcation between stages.
Stage
Traits
Sensorimotor
Cannot trace code with >= 50% accuracy
Dominant problem-solving strategy is trial and error
Preoperational
Can trace code with >= 50% accuracy
Traces without abstracting any meaning from the code
Cannot see relationships between lines of code
Struggles to make effective use of diagrammatic abstractions of code
Dominant problem-solving strategy is quasi-random code changes and copious trial runs
Concrete Operational
Dominant problem-solving strategy is hasty design, futile patching
Can establish purpose of code by working backwards from execution results
Tends to reduce levels of abstraction to make concepts more understandable
Formal Operational
Uses hypothetico-deductive reasoning
Reads code rather than traces to deduce purpose
These stages reflect the progress the learner is making through accommodation, creating the mental structures needed to reason about programming. An expert has developed these structures, which reflect patterns in how code is written - that is why an expert no longer traces code - they can see the patterns in the code and immediately grasp its action and purpose. In contrast, the novice must deduce the result of each line of code, put those understandings together, and then deduce what it is doing overall.
Writing a program is similar, the expert begins with a clear picture of the patterns she must employ, and focuses on fleshing those out, while a novice must create the program ‘from whole cloth’, reasoning out each step of the process. They are not yet capable of reasoning about the program they are writing in the abstract.
This also helps explain why learning to program can be so hard. Abstraction is considered a central tool in programming; we use abstractions constantly to simplify and make programs more understandable to other programmers. Consider a higher-level programing language, like C#. Each syntax element is an abstraction for a more complex machine-level process. The statement:
x += 2;
Stands in for machine instructions along the lines of:
PUSH REG5 TO REG1
PUSH 2 TO REG2
ADD REG1 AND REG2
PUSH REG3 TO REG5
Which are in turn, simplifications and abstractions of the actual process of adding the two binary values in register 1 and register 2.
What is interesting is we don’t really need to understand all of that complexity - we just need to understand enough to be able to write the programs we want to create effectively. We’ll talk about that next.
Notional Machines
Going back to the previous chapter, we discussed both computing hardware and programming languages. Remember, modern computers have very limited instruction sets. But a programming language can provide a single command that translates into a lot of individual instructions in machine code.
Thus, when writing programs, we need to have some knowledge of both. But the good news is we don’t need exhaustive knowledge - just enough to understand the programs we are writing. Computer scientists often call this combined functionality the notional machine, an idealized computer that represents the combination of features from the hardware and programming language that together establish how a program running on that machine will behave. In other words, it is a simplified model of how computation is carried out.
The concept of notional machines was originally developed to help teach computer science. But when we adopt a constuctivist standpoint, we can also argue that in learning to program, each student is actually constructing their own notional machine, which incorporates everything they understand about the hardware and programming language they are learning. This concept of an internalized notional machine is very helpful, as a student misconception is essentially a flaw in that internalized notional machine. Because of this misalignment between their internalized notional machine and the real notional machine, a program that they write may not behave as they expect it to.
The process of developing programming skill is therefore one of developing a robust and accurate internalized notional machine. The skills of computational thinking then use this internalized notional machine to determine how to solve problems, as well as create the programs to embody those solutions.
Summary
In this chapter, we explored theories of learning and how learning computer science fits into them. In particular, we saw that learning computer science and programming creates new structures in the mind corresponding to physical changes in the connections between brain neurons. Piaget’s genetic epistemology theory tells us the process of building these structures requires a certain amount of cognitive disequilibrium - grappling with the subject material and trying to make sense of it.
Carol Dweck’s theory of mindsets helps us understand how students respond to this disequilibrium. Ideally our students adopt a growth mindset which encourages them to continue to work at learning the material, eventually building those mental structures. Vigotksy’s zone of proximal development helps define how much disequilibrim we need to create, and provides some guidance on how to control that.
Piaget’s stage theory, as elaborated in the developmental epistemology of programming, gives us a way to reason about where students’ development is. And the neo-Piagitian overlapping waves model helps us understand that development is specific to individual concepts within the domain. And finally, internalized notional machines are a way of understanding exactly what some of those mental structures our students are building are - a mental model of how the computer and programming language work together that helps them design and write programs.
CS Teaching Approaches
Chapter 3
Computer Science Teaching Approaches
Subsections of CS Teaching Approaches
Introduction
Now that you understand more about what computer science is, and how we learn it, we can turn our attention to pedagogy and tools for effectively teaching computer science. Remember, our goal is to help students develop cognitive structures that help them read and write programs and solve problems with computational thinking. Ultimately, there is a lot for students to learn in order to engage with computer science effectively. We therefore need to carefully scaffold our teaching efforts to help minimize the cognitive load our students encounter as they develop the mental structures they need to reason about both programming and computational thinking. We need to keep the students in the zone (the zone of proximal development)!
This chapter will discuss tools and teaching techniques to help manage this cognitive load.
CS Unplugged
Learning computer science can be hard - you’re trying to learn the skills of computational thinking and a new language at the same time. Consider what it would be like learning algebra for the first time in Spanish at the same time you were learning Spanish, and you’ll get the idea of the challenge.
Of course, there are important differences:
With a language like Spanish, a skilled speaker will be able to interpret your meaning even if you don’t quite follow the grammatical rules of the language. A computer will not - you must follow the rules exactly!
A programming language contains a much smaller vocabulary and fewer grammatical rules than a human one like Spanish, so there is ultimately less to learn.
Programming languages typically use English words, so you don’t have to learn a whole new set of words and meanings… except the way a programming language uses those words doesn’t always line up with our expectations based on the English language - this makes for some significant gotchas.
CS Unplugged curriculum is an attempt to sidestep the programming language challenge entirely, and focus on teaching computational thinking with no computers at all. Instead, it teaches the concepts through games, puzzles, and lots of physical real-world action.
Based on our readings from chapter 2, you probably realize that we need to incorporate use of an actual computer and programming language to help our students develop an accurate internal notional machine to guide problem-solving efforts to utilize a computer. And indeed, research into CS Unplugged suggests that by itself, it does not help students become better programmers. This is actually part of a broader issue of knowledge transfer - humans are not great at taking what they learn in one domain and applying it in another, without guidance on how the two connect.
But combining CS Unplugged activities with the other strategies laid out in this chapter can be a recipe for success. When you do so, be sure to explicitly call out the connections between the various activities to help your students see how it all connects.
Block-based Programming
In learning a programming language, few tools have been as powerful for reducing cognitive load on students learning computer science as block-based programming. In a block-based programming environment, instead of typing program code, you drag and connect graphical blocks representing program code. This means students don’t have to remember and reproduce the exact spelling of program syntax, and blocks can only ‘snap’ together in grammatically correct ways. This eliminates the possibility of making two of the most common families of errors novice programmers face - syntax and grammar errors - and allows them to focus on learning how to solve problems with programs.
While any programming language could be presented in block-based form, a number of pedagogical programming languages (programming languages specifically developed to be easy to learn) have been developed using this approach. These include MIT’s Scratch (pictured above), Berkley’s Snap!, and Google’s Blockly.
Scratch is especially used in elementary and middle school education. It is completely browser-based, and can run on any computing platform (PC, Mac, iPads, Android tablets). It is a multimedia programming environment, where programs can control sprites on a virtual stage. If students create an account, their work is also saved to the cloud, so they can edit their programs both at home and school. Scratch also has plugins for programming many popular robotics and electronics kits. Finally, numerous curriculum resources exist to support teachers interested in using it: Scratch’s Educator Guides, ScratchEd’s Creative Computing Curriculum, Google’s CS First Curriculum, and my own Scratch K-12 Curriculum Materials.
Snap! is similar to Scratch in many ways - it also browser-based and can run on any platform, and provides a multimedia programming environment. It also sports many plugins for robots and electronics. However, its colors are more muted and its blocks are smaller, helping it feel more “professional”. And while Scratch’s core focus has always been approachability, Snap! focuses more on providing additional functionality found in other programming languages (like the recently added map and combine functions). This makes it more powerful, but at a cost of additional complexity. As such, it is less a beginner programming environment than an opportunity for students who have mastered Scratch to explore more complex programming approaches. The Snap! Manual. describes these ideas in detail. Berkley offers a companion curriculum, Beauty and Joy of Computing.
Google’s Blockly is not a stand-alone programming environment, rather it is a tool for creating such environments (in fact, Scratch uses Blockly for its blocks). Blockly is also the basis on which the Code.org programming environments are built, as well as MIT’s App Inventor, which allows you to create Android and iPhone apps using a block-based programming approach.
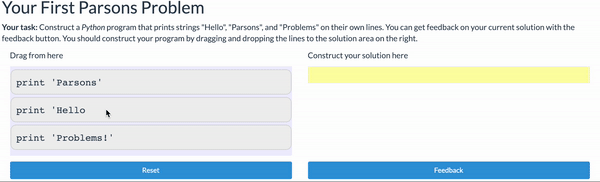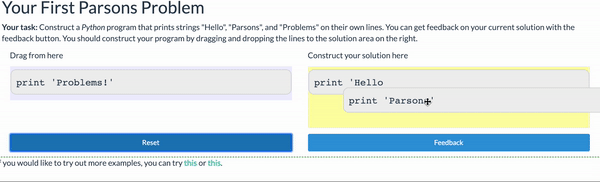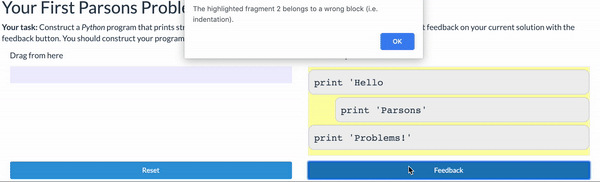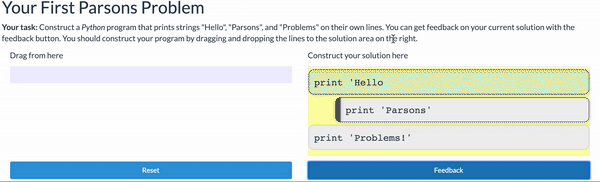
Parsons Problems
Parsons problems are another commonly used tool for reducing the cognitive load of learning to program. A Parsons Problem gives the student all the lines of code needed to complete a task, and asks them to arrange them in order. While this can be done on paper (by marking an order), they are commonly delivered using a drag-and-drop interactive interface that also allows the student to verify they have completed the task correctly:
Parsons problems can be used with any programming language, including text-based ones like the Python example above. But they offer some of the same benefits of block-based programming: the student doesn’t need to remember the exact syntax constructions - just recognize them and be able to order them correctly.
Thus, Parsons problems are commonly used to practice syntax as students are learning it. Additionally, they are commonly used in assessments. You can fine-tune the challenge of a Parsons problem by “fixing” some of the solution lines in place (so they aren’t draggable, and by adding detractors (lines that don’t actually belong in the program).
Code Tracing
Moving beyond tools for reducing cognitive load on our students, let’s turn our attention to specific activities we can employ in our teaching. Perhaps one of the most important, and commonly overlooked, is reading code. Think for a moment about how writing a program is like writing a story or essay. You wouldn’t ask a student to write a story until after they have read many examples of stories, would you? Likewise, when we introduce essay writing, we first have students read many good examples of essays. The same should be true of programming - students learn to write good programs in part from reading good programs.
But how do we read a program? There is a specific strategy we employ known as code tracing, and it refers to evaluating what happens in a program on a line-by-line basis. You start at the entry point of the program - the first line that is executed (often the first line for many programming languages, though for C/C++, Java, and C# it will be the first line in the main method).
Then, for each line, you determine what that line is doing. If it carries out a calculation, you carry out the calculation. If it declares a variable, you draw a box on a piece of scratch paper to represent the variable. If it assigns a value to that variable, you write the value in the box. If you reach a branching point (i.e. an if statement), you determine which branch to follow based on its test condition. And if you enter a loop, you repeat the lines of code in the loop until its test condition is no longer true.
Below are some example videos walking through code tracing with Scratch and Java:
The Developmental Epistemology of Programming we discussed in the prior chapter claims that when students are able to trace code with greater than 50% accuracy, they have moved into the preoperational stage, which marks initial readiness to start programming. Remember, that stage is specific to each code construct, so as you introduce new operations (like loops) you will need to repeat code tracing with examples of the new syntax.
It is also important to note that as students develop cognitive structures to reason about programs, they will need to perform line-by-line code traces less and less. Eventually, they will be able to recognize the purpose of multiple lines of code at a glance, i.e. when presented with this code:
They will recognize that it is testing the array numbers to determine if it is sorted in ascending order. This ability to recognize the purpose from a pattern of code corresponds with the Formal Operational stage.
Live Coding
An approach that has been used to teach computer science for many years is Live Coding (also known as Demonstration Coding or Apprenticeship Coding). In this strategy, the teacher models the activities of solving a problem and writing the corresponding program in front of the class.
An important aspect of this approach is explaining your thought process as you approach, think about, solve, the problem and write the program solution. By exposing your thought process out loud, you are guiding your students to think about their own processes.
It is a good idea to work through the problem and solution you want to demonstrate several times before you present it to students - but be sure to keep notes on your thought process during your first attempts so you can present it accurately. You don’t want to present students with a perfect step-by-step process; doing so will give them an unrealistic expectation of what programming should be. Showing them how you encounter and debug errors will help them understand that it is a normal part of the programming process. But you also don’t want so many that it derails the momentum of the lesson.
Live coding can be used with any part of working in CS, and combined with many of the pedagogical approaches we will discuss shortly.
Finally, some teachers have students “follow along” - write the same program the teacher is demonstrating. This can be helpful for getting students more practice programming and keep students’ attention focused on the lesson. But it also adds additional cognitive load, and may result in students missing some of the benefits of your modeling as they focus on getting their program to match yours. Also, you may find that students want you to move at different speeds - some want to go fast, while others will need you to slow down to get everything written. For large classes, this can become a major challenge. A good alternative for follow-along live coding is pre-recording a programming session and providing it as a video for your students to use. This allows them to proceed at their own pace, and also go back to review parts they missed.
Pair Programming
Peer programming is a technique where two students work together to create a program solution. One student takes on the role of the driver, and writes the actual program code, while the second is the navigator, who provides guidance on what code needs to be written. In effect we are reducing the cognitive load in that each student only needs to tackle a subset of the challenges in writing software. The navigator is primarily employing the skills of computational thinking, while the driver is primarily engaging in programming.
This approach also means two pairs of eyes (and the minds behind them) are seeing the code as it is written, which can help increase the chances that simple mistakes (like typos, using the wrong variable name, etc.) will be caught early. It also encourages the two programmers to discuss strategy and plan rather than jumping into programming blindly. For many of these reasons, pair programming is also used in professional practice.
Coaching
As students gain knowledge and skills in programming, we want to provide less structured scaffolding and allow them to develop more independent problem-solving skills. However, it is still common for a student to encounter an issue that is beyond their ability to solve even after they have developed significant skills (in fact, expert programmers still often find themselves confronted with a challenge they aren’t sure how to tackle). If students are left to struggle too long, frustration sets in, and learning is derailed.
Thus, as we move towards more independent programming, we want to shift to the role of a coach or mentor, and watch for those high levels of frustration and step in to provide guidance. It is important not to step in too early - as we can unwittingly relieve the cognitive dissonance the students need to be encountering to learn. But it is also important not to let them struggle too long with a problem beyond their current understanding.
Also, when coaching, be very careful not to ‘solve’ the issue for your students. Keep your hands off their keyboard and mouse! Ask them leading questions to help them find the answer themselves, and have them add it to their programs themselves.
Peer coaching - allowing students to help each other - can also be a powerful tool. In peer coaching, more experienced students coach less-experienced ones (Note this is different from peer programming, in which the students are at a similar level of proficiency). However, peer coaching should be closely monitored, as bad interactions can discourage learners and dampen interest in computer science entirely.
Summary
In this chapter we explored tools and techniques for teaching computer science and limiting cognitive load. These include approaches that simplify the use of programming from eliminating it altogether (CS Unplugged) to providing a drag-and-drop interface to remove the need to type syntax correctly (block-based programming and Parsons problems).
We also discussed the importance of reading code for comprehension, which helps to develop the student’s internalized notional machine for the programming language they are learning. Likewise, live coding - modeling our development practice for our students can help them develop the skills necessary to write their own programs. Finally, peer programming and coaching can help support students as they continue to develop their own proficiency.
Designing CS Lessons
Subsections of Designing CS Lessons
Introduction
We’ve covered what computer science is, how it is learned, and have seen some teaching approaches and tools to help manage cognitive load. Building on that knowledge, in this chapter we’ll look at how to design or modify computer science lessons for our students.
Embedded CT
Before we delve into specific strategies for selecting and structuring lesson activities, let’s first discuss more broadly what those activities should be. Many Computer Science curriculums focus on the development of algorithms and data structures (a fact reflected in the name of one of the best classic textbooks in the field, Nickolas Wirth’s Data Structures + Algorithms = Programs). We can see this in the CS Unplugged curriculums’ focus on sorting algorithms and tree data structures, as well as many other curriculums.
While these topics are important, writing code to sort data or define data structures only appeals to a subset of our students. It also paints a somewhat unrealistic picture of what a computer science career would be for our students. The truth is, while it was once common practice, today very few programmers are actually writing sorting algorithms and data structures by hand. Instead, they are utilizing pre-built libraries that provide this functionality. While it is important to understand what these libraries are doing and how they structure data, it is not as important as many curriculums make it out to be.
Remember, computational thinking is all about problem solving, and the problems we want to solve come from all domains. Consider how real computer scientists and intellectual workers are using the tools of programming and computational thinking:
A computer scientist working for an online media company revises their recommendation algorithm to do a better job of helping users find videos they will enjoy
A social activist uses public databases and algorithms to reveal gerrymandering in a state’s proposed redistricting
An insurance actuary uses algorithms drawing on their company’s historical claims data to determine appropriate insurance rates for teen drivers
A computational geneticist uses big databases and algorithms to search for patterns in genomes to discover the root cause of a disease
A artist programs Raspberry Pis to cause elements of an interactive art exhibit to respond to patrons
A computational physicist builds a simulation to test a theory of how our moon formed
A DJ uses programming to help remix music from multiple tracks on the fly during a performance
An advertiser uses profile data collected online to provide highly targeted ads to people most likely to be interested in the products being sold
Building or selecting lessons that reflect this breadth of the use and impact of computer science can help students see that they can use the tools of computer science to support their interests. Research has shown that this approach also appeals to students who would never have thought computer science was something they would be interested in.
Tip
If you are a K-12 teacher, you have a unique opportunity to incorporate computer science activities into the other subjects you teach. This has the benefit of both adding depth to your CS lessons and also showing students how CS is normally used to solve problems in other domains!
CSSC Instructional Continuum
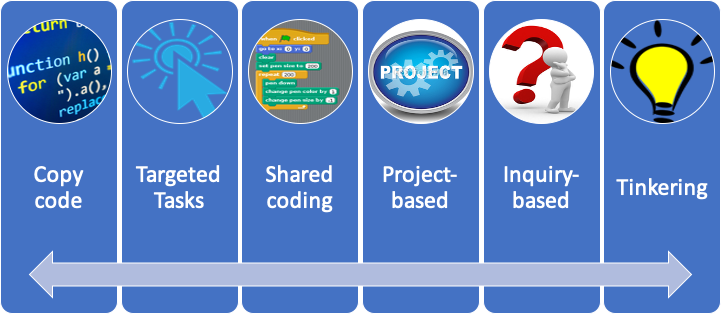
Now let’s turn our attention to thinking about approaches for delivering computer science lessons. A handy way to consider the cognitive load is the the Computer Science Student-Centred Instructional Continuum1, which represents a range of potential instructional approaches:
The continuum ranges from highly scaffolded (right side) to no scaffolding (left side). Based on the learning theory from the prior chapter, we want to start our students with activities with more scaffolding, and gradually reduce that scaffolding. Note that this applies for all new subjects - as we introduce them, we again want to have an appropriate level of scaffolding in place!
The continuum’s activities are:
Copy Code - students are giving step-by-step instructions to follow. This can be part of a Live Coding exercise, a recorded tutorial, or a worksheet to copy.
Targeted Tasks - students are given a short task, i.e. completing a method, fixing buggy code, transcribing music into a program, or Parsons problems.
Shared Coding - the teacher writes code, explaining their thought process (sometimes called demonstration coding, live coding, or apprenticeship). Students may be asked to write the same program at the same time.
This continuum can be helpful in evaluating existing curriculum materials; for example,
most Code.org lessons start with copy code activities using multimedia explanations of what that code does, and gradually shift to targeted tasks. Likewise, Scratch’s built-in tutorials also start with copy code activities. Once a student has developed comfort with this level of programming, you can introduce less tightly guided activities.
Jane Waite and Christine Liebe. 2021. Computer Science Student-Centered Instructional Continuum. In Proceedings of the 52nd ACM Technical Symposium on Computer Science Education (SIGCSE ‘21). Association for Computing Machinery, New York, NY, USA, 1246. DOI:https://doi-org.er.lib.k-state.edu/10.1145/3408877.3439591 ↩︎
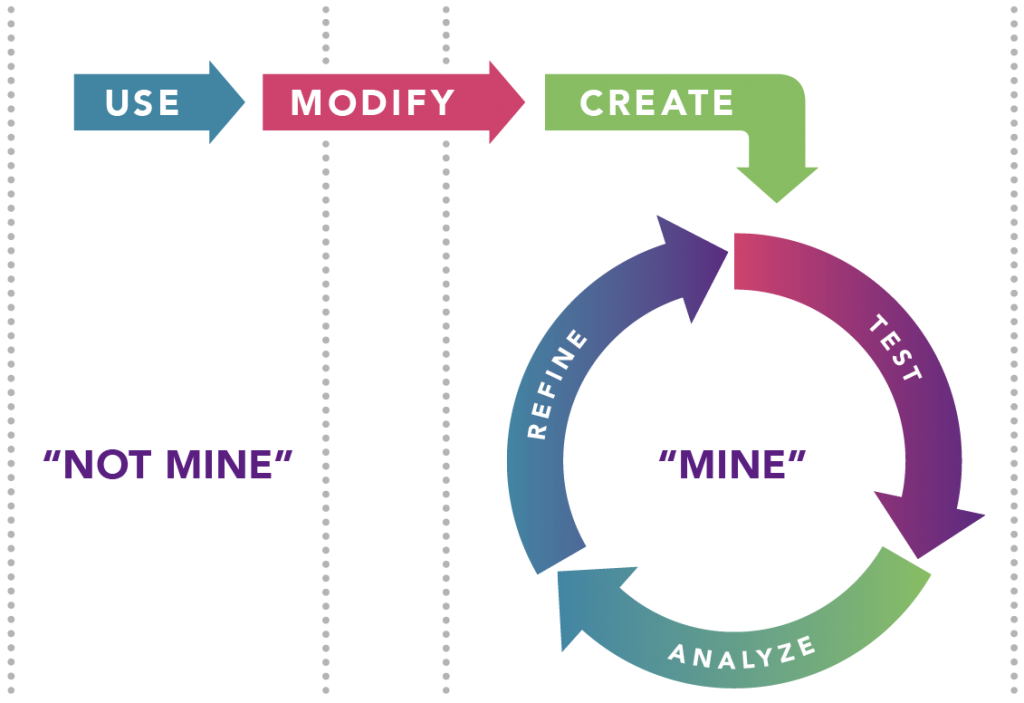
Use - Modify - Create
The Use → Modify → Create learning progression is a good example of a lesson design strategy that incorporates activities that progressively move from left to right on the instructional continuum. Students are introduced to an exemplar program that does something similar to the ultimate challenge you have in mind for them. They run the program and learn how to use it effectively. Then they are tasked with modifying the program in a way that allows them to tackle a different (but similar problem). Finally, they use what they hae learned to create an entirely new program1.
In addition to providing a gradual removal of scaffolding when teaching computer science, the Use-Modify-Create approach also encourages students to develop a growing sense of ownership over the code they author. This progression can be repeated to introduce new syntax, algorithms, or data models. Later projects can also be designed to challenge students to combine the approaches they have previously learned separately.
Nicholas Lytle, Veronica Cateté, Danielle Boulden, Yihuan Dong, Jennifer Houchins, Alexandra Milliken, Amy Isvik, Dolly Bounajim, Eric Wiebe, and Tiffany Barnes. 2019. Use, Modify, Create: Comparing Computational Thinking Lesson Progressions for STEM Classes. In Proceedings of the 2019 ACM Conference on Innovation and Technology in Computer Science Education (ITiCSE ‘19). Association for Computing Machinery, New York, NY, USA, 395–401. DOI:https://doi.org/10.1145/3304221.3319786 ↩︎
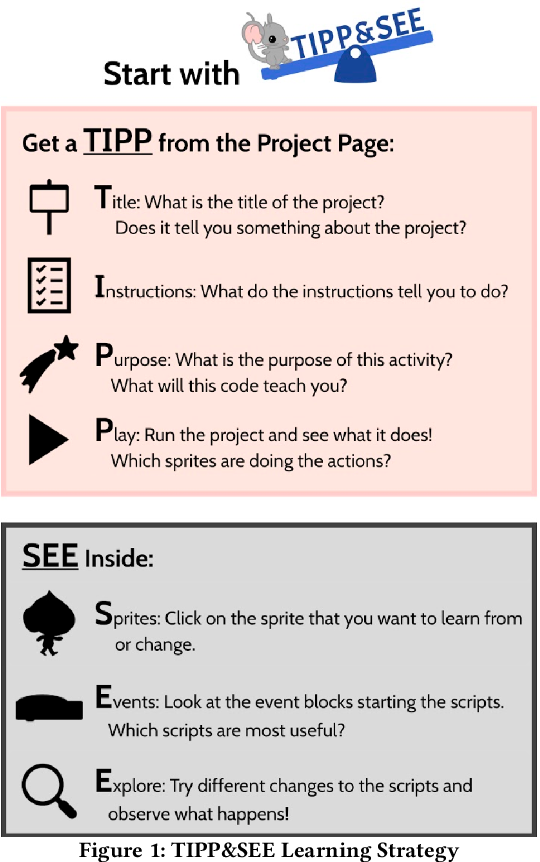
TIPP & SEE
TIPP & SEE is an adaption of the Use → Modify → Create → learning progression developed specifically for working with Scratch1. The name is an acronym for a multi-step process of interacting with Scratch projects. Scratch offers a website where programmers can publish and share their projects, and other programmers can remix them.
Remixing in Scratch means taking an existing project and modifying it, often to build in more functionality or to change its aesthetics. This parallels the professional open-source community, where professional programs write and distribute programs online using sites like GitHub for others to use and modify. This also means that the Scratch website can serve as a rich source of exemplar programs to share with your students.
Tip
Alternatively, you can provide a starting program for your students to remix that you authored yourself!
TIPP stands for Title, Instructions, Purpose, and Play, and describes examining the surface level of a Scratch project - reading its title, instructions, trying to determine the purpose of the project, and then running it to see what it does. SEE stands for Sprites, Events, and Explore, and describes examining the actual code of the project.
Jean Salac, Cathy Thomas, Chloe Butler, Ashley Sanchez, and Diana Franklin. 2020. TIPP&SEE: A Learning Strategy to Guide Students through Use - Modify Scratch Activities. Proceedings of the 51st ACM Technical Symposium on Computer Science Education. Association for Computing Machinery, New York, NY, USA, 79–85. DOI:https://doi.org/10.1145/3328778.3366821 ↩︎
The Block Model
The Block Model is an educational model for describing how students come to understand a program as they read it 1. It is expressed as a table that covers three dimensions in four levels. Each cell represents one aspect of understanding.
The three dimensions are the text surface (the actual text of the program), the program execution (the order in which the program commands happen, and how data is manipulated), and goals (what the program is meant to do). Text surface and program execution are further grouped into structure (the actual expression of code) and function (its intended purpose).
The levels are atoms (individual elements of the language, i.e. keywords and statements), blocks (groupings of code lines that work together, i.e. a loop that sums all the values in a collection), relations (the connections between the bocks), and macro (the overall program).
Macro Structure
Understanding the overall structure of the program
Understanding the 'algorithm' of the program
Understanding the goal/purpose of the program
Relations
References between blocks, eg. method calls, object creation, accessing data...
sequence of method calls - 'object sequence diagrams'
Understanding how subgoals relate to goals, how function is achieved by subfunctions
Blocks
'Regions of Interests' (ROI) that syntactically or semantically build a unit
Operation of a block of code, a method, or a ROI (as a sequence of statements)
Purpose of a block of code, possibly seen as a subgoal
Atoms
Language elements
Operation of a statement
Purpose of a statement
Text Surface
Program Execution (data flow and control flow)
Goals of the Program
Duality
Structure
Function
The block model has a direct relationship with the epistemology of programming and the development of schema. Beginning programmers are still learning the atoms of a language (mastering these reflects achieving the preoperational stage). The first schema programmers develop are to reason about the patterns found in the blocks, and further schema help to reason about the relationships between these blocks (Concrete operational stage). Finally, students learn to see how all the pieces of a program come together at the macro level (Formal operational stage).
The block model can therefore help us reason about how our students are able to engage with a program (novices read programs bottom-up, reflecting the order of the table), while more experienced programmers often read top-down, sussing out the purpose of code by the names of functions, classes, etc. and by recognizing the purpose of blocks of code without needing to use code tracing.
Carsten Schulte. 2008. Block Model: an educational model of program comprehension as a tool for a scholarly approach to teaching. In Proceedings of the Fourth international Workshop on Computing Education Research (ICER ‘08). Association for Computing Machinery, New York, NY, USA, 149–160. DOI:https://doi-org.er.lib.k-state.edu/10.1145/1404520.1404535 ↩︎
PRIMM
PRIMM is also an instructional approach building off the Use → Modify → Create strategy and the Block Model. Much like TIPP & SEE, it emphasizes reading and understanding code before writing. PRIMM is also an acronym for the stages that it structures learning activities in: Predict, Run, Investigate, Modify, Make.
Predict We start by presenting students with a prepared program, and the students try to predict what it will do. This works well as a think-pair-share or small groups activity, as discussion between students can enhance learning.
Run Then the students test their predictions by executing the program. Discussion can be used to help students verbalize the results and compare it with their predicted expectations.
Investigate The investigation stage is based on the Block Model, and can include activities like code tracing, explaining, annotating, debugging, etc.
Modify This stage is very similar to the Modify stage of Use - Modify - Create, and involves modifying the code they have just investigated to accomplish a related task. During this stage, the scaffolding support is gradually removed.
Make In this stage, learners are given a new problem to solve that uses the same ideas and skills introduced in earlier stages.
Summary
In this chapter we explored pedagogical techniques for evaluating and developing computer science lessons. We discussed embedding our lessons in the problem spaces of other disciplines, and how this can help students understand better how computer science fits into the world.
We also saw how the Student-Centered Computer Science Instructional Continuum can be used to help think about scaffolding to control cognitive load in our lessons. Then we saw a number of instructional models for developing CS lessons, including Use-Modify-Create, TIPP & SEE, the Block Model, and PRIMM.