OOP
Building Programs from Classes and Objects!
Building Programs from Classes and Objects!
Hello World, but like the pros do it!
Welcome to CC 410 - Advanced Programming. This course is designed to be a capstone experience at the end of the Computational Core program, building upon our prior knowledge and experience to help us become a truly effective programmer. In this course, we’ll not only learn new skills and techniques, but we’ll try to pull back the curtain and explain the history of programming and why we do some of the things we do.
In this course, we’re going to cover a lot of content. However, it can be grouped into a few big ideas in programming:
We’ll spend some time covering each of these in more detail as we go through the course. In this module, we’ll start working on the first two - writing professional code and minimizing bugs through testing and debugging.
Before we dive too deeply into this topic, let’s take a step back and examine some of the history of programming that lead to our current state of the art that revolves around object-oriented programming. To do that, we’ll need to explore the software crisis and the topic of structured programming.
The content on this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
By this point, you should be familiar enough with the history of computers to be aware of the evolution from the massive room-filling vacuum tube implementations of ENIAC, UNIVAC, and other first-generation computers to transistor-based mainframes like the PDP-1, and the eventual introduction of the microcomputer (desktop computers that are the basis of the modern PC) in the late 1970s. Along with a declining size, each generation of these machines also cost less:
| Machine | Release Year | Cost at Release | Adjusted for Inflation |
|---|---|---|---|
| ENIAC | 1945 | $400,000 | $5,288,143 |
| UNIVAC | 1951 | $159,000 | $1,576,527 |
| PDP-1 | 1963 | $120,000 | $1,010,968 |
| Commodore PET | 1977 | $795 | $5,282 |
| Apple II (4K RAM model) | 1977 | $1,298 | $8,624 |
| IBM PC | 1981 | $1,565 | $4,438 |
| Commodore 64 | 1982 | $595 | $1,589 |
This increase in affordability was also coupled with an increase in computational power. Consider the ENIAC, which computed at 100,000 cycles per second. In contrast, the relatively inexpensive Commodore 64 ran at 1,000,000 cycles per second, while the more pricey IBM PC ran 4,770,000 cycles per second.
Not surprisingly, governments, corporations, schools, and even individuals purchased computers in larger and larger quantities, and the demand for software to run on these platforms and meet these customers’ needs likewise grew. Moreover, the sophistication expected from this software also grew. Edsger Dijkstra described it in these terms:
The major cause of the software crisis is that the machines have become several orders of magnitude more powerful! To put it quite bluntly: as long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a mild problem, and now we have gigantic computers, programming has become an equally gigantic problem. – Edsger Dijkstra, The Humble Programmer (EWD340), Communications of the ACM
Coupled with this rising demand for programs was a demand for skilled software developers, as reflected in the following table of graduation rates in programming-centric degrees (the dashed line represents the growth of all bachelor degrees, not just computer-related ones):
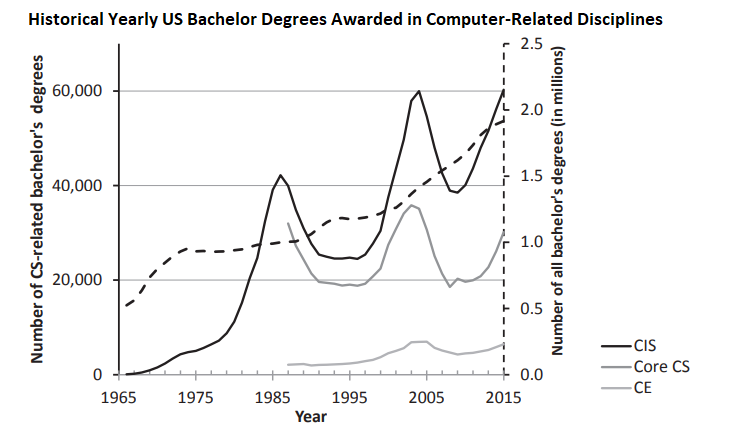
Unfortunately, this graduation rate often lagged far behind the demand for skilled graduates, and was marked by several periods of intense growth (the period from 1965 to 1985, 1995-2003, and the current surge beginning around 2010). During these surges, it was not uncommon to see students hired directly into the industry after only a course or two of learning programming (coding boot camps are a modern equivalent of this trend).
All of these trends contributed to what we now call the Software Crisis.
The content on this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
At the 1968 NATO Software Engineering Conference held in Garmisch Germany, the term “Software Crisis” was coined to describe the current state of the software development industry, where common problems included:
The software development industry sought to counter these problems through a variety of efforts:
This course will seek to instill many of these ideas and approaches into your programming practice through adopting them in our everyday work. It is important to understand that unless these practices are used, the same problems that defined the software crisis continue to occur!
In fact, some software engineering experts suggest the software crisis isn’t over, pointing to recent failures like the Denver Airport Baggage System in 1995, the Ariane 5 Rocket Explosion in 1996, the German Toll Collect system canceled in 2003, the rocky healthcare.gov launch in 2013, and the massive vulnerabilities known as the Meltdown and Spectre exploits discovered in 2018.
The content on this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
One of the strategies that computer scientists employed to counter the software crisis was the development of new programing languages. These new languages would often 1) adopt new techniques intended to make errors harder to make while programming, and 2) remove problematic features that had existed in earlier languages.
Let’s take a look at a working (and in current use) program built using Fortran, one of the most popular programming languages at the onset of the software crisis. This software is the Environmental Policy Integrated Climate (EPIC) Model, created by researchers at Texas A&M:
Environmental Policy Integrated Climate (EPIC) model is a cropping systems model that was developed to estimate soil productivity as affected by erosion as part of the Soil and Water Resources Conservation Act analysis for 1980, which revealed a significant need for improving technology for evaluating the impacts of soil erosion on soil productivity. EPIC simulates approximately eighty crops with one crop growth model using unique parameter values for each crop. It predicts effects of management decisions on soil, water, nutrient and pesticide movements, and their combined impact on soil loss, water quality, and crop yields for areas with homogeneous soils and management. -- EPIC Homepage
You can download the raw source code and the accompanying documentation. Open and unzip the source code, and open a file at random using your favorite code editor. See if you can determine what it does, and how it fits into the overall application.
Try this with a few other files. What do you think of the organization? Would you be comfortable adding a new feature to this program?
You probably found the Fortran code in the example difficult to wrap your mind around - and that’s not surprising, as more recent languages have moved away from many of the practices employed in Fortran. Additionally, our computing environment has dramatically changed since this time.
One clear example is symbol names for variables and procedures (functions) - notice that in the Fortran code they are typically short and cryptic: RT, HU, IEVI, HUSE, and NFALL, for example. You’ve been told since your first class that variable and function names should express clearly what the variable represents or a function does. Would rainFall, dailyHeatUnits, cropLeafAreaIndexDevelopment, CalculateWaterAndNutrientUse(), CalculateConversionOfStandingDeadCropResidueToFlatResidue() be easier to decipher? (Hint: the documentation contains some of the variable notations in a list starting on page 70, and some in-code documentation of global variables occurs in MAIN_1102.f90.).
Believe it or not, there was an actual reason for short names in these early programs. A six character name would fit into a 36-bit register, allowing for fast dictionary lookups - accordingly, early version of FORTRAN enforced a limit of six characters for variable names1. However, it is easy to replace a symbol name with an automatically generated symbol during compilation, allowing for both fast lookup and human readability at a cost of some extra computation during compilation. This step is built into the compilation process of most current programming languages, allowing for arbitrary-length symbol names with no runtime performance penalty.
Another common change to programming languages was the removal of the GOTO statement, which allowed the program execution to jump to an arbitrary point in the code (much like a choose-your-own adventure book will direct you to jump to a page). The GOTO came to be considered too primitive, and too easy for a programmer to misuse 2.
However, the actual functionality of a GOTO statement remains in higher-order programming languages, abstracted into control-flow structures like conditionals, loops, and switch statements. This is the basis of structured programming, a paradigm adopted by all modern higher-order programming languages. Each of these control-flow structures can be represented by careful use of GOTO statements (and, in fact the resulting assembly code from compiling these languages does just that). The benefit is using structured programming promotes “reliability, correctness, and organizational clarity” by clearly defining the circumstances and effects of code jumps 3.
The object-orientation paradigm was similarly developed to make programming large projects easier and less error-prone. We’ll examine just how it seeks to do so in the next few chapters. But before we do, you might want to see how language popularity has fared since the onset of the software crisis, and how new languages have appeared and grown in popularity in this animated chart from Data is Beautiful:
YouTube VideoInterestingly, the four top languages in 2019 (Python, JavaScript, Java, and C#) all adopt the object-oriented paradigm - though the exact details of how they implement it vary dramatically.
The term “Object Orientation” was coined by Alan Kay while he was a graduate student in the late 60s. Alan Kay, Dan Ingalls, Adele Goldberg, and others created the first object-oriented language, Smalltalk, which became a very influential language from which many ideas were borrowed. To Alan, the essential core of object-orientation was three properties a language could possess: 4
We’ll take a look at each of these in the next few chapters.
Weishart, Conrad (2010). “How Long Can a Data Name Be?” ↩︎
Dijkstra, Edgar (1968). “Go To Statement Considered Harmful” ↩︎
Wirth, Nicklaus (1974). “On the Composition of Well-Structured Programs” ↩︎
Eric Elliot, “The Forgotten History of Object-Oriented Programming,” Medium, Oct. 31, 2018. ↩︎
As we saw earlier in this module, the software development industry adopted many new processes and ideas to help combat the issues that arose during the software crisis. One of the major things they focused on was how to write code that is easy to understand, easy to maintain, and works as intended with a minimal amount of bugs. Let’s review a few of the concepts that came from those efforts, which we’ll learn more about throughout this semester.
The use of object-oriented programming languages was one major outcome of the software crisis. An object-oriented language allows developers to build code that represents real-world concepts and ideas, making it easier to reason about large software programs. In addition, the concept of encapsulation helped ensure data stored and manipulated by one part of the program wasn’t inadvertently changed by a bug in another part. Finally, through message passing and dynamic binding, we could write more advanced functions that allowed our code to be very modularized, flexible, and highly reusable. We’ll spend the next several modules in this course covering object-oriented programming in much greater detail.
Another major movement in the software industry was toward the use of automated testing frameworks and the use of unit testing. Unit testing involves writing detailed tests for small units of a program’s source code, often individual functions, that exercise the expected functionality of the code as well as checking for any edge cases or expected errors.
In theory, if the unit tests are properly written and perform all possible operations that the code should perform, than any code passing the tests should be considered complete and ready for use. Of course, coming up with a set of unit tests that can account for all possible scenarios is just as impossible as writing software that doesn’t contain any bugs, but it can be a great step toward writing better software.
A common software development methodology today is test-driven development or TDD. In test-driven development, the unit tests are developed first, based on the software specification, before the source code is ever written. In that way, it is easy to know if the software actually does what the requirements says it should, instead of the test simply being written to match the code that exists. (It is shockingly common for unit tests to be written based on the code it should test, which is equivalent of looking at the answers when doing a word scramble - you’ll find what you expect to find, but won’t actually learn anything useful from it.)
Another useful feature of unit tests is the ability to re-run tests on the program after an update has been developed, which is known as regression testing. If the program previously passed all available unit tests, then failed some of those tests after an update, we know that we introduced some unintended bugs in the code that can be repaired before publishing an update. In that way, we can avoid sending out an update that ends up making things even worse.
Along with unit testing, another useful technique is calculating the code coverage of a set of tests. Ideally, you’d like to make sure that each and every line of code in the program is executed by at least one test - otherwise, how can you really say that that line does what it should? This is especially difficult in programs that contain multiple conditional statements and loops, or any code that checks for and handles exceptions.
There are various ways to measure code coverage, including this list from Wikipedia:
true and false?There are various different ways to measure code coverage that we’ll discuss later in this course, but for now we’ll just look at statement coverage. Thankfully, there are some great tools for computing the code coverage of a set of unit tests. Our goal is always to get as close to 100% coverage as possible.
Another major focus among professional coders is the inclusion of documentation directly in the source code itself. Many languages, such as Java, Python, and C#, include standards for documenting what various pieces of the code are for. This includes each individual source code file, classes, functions, attributes, and more. In many cases, this is done by including specially structured code comments in various places throughout the source code.
To make those comments easier to read and understand, many languages also include tools to automatically create developer documents based on those comments. A prime example of this is the Java API Documentation, which is nearly entirely generated directly from comments in the Java source code. In fact, you can compare the source code for the ArrayList class and the ArrayList Documentation in the Java API to get an idea of how this works.
Finally, there are many tools available today that can perform static code analysis of source code, helping developers find and fix errors without ever even compiling and running the code. Some static code analysis tools are quite powerful, able to find logic errors or completely validate that the software meets a specification. These tools are commonly used in the development of critical software components, such as medical devices and avionics for aircraft, but they are also quite difficult to use.
In this course, we’re going to focus on a simpler form of static code analysis that will help us maintain good coding style. These tools are sometimes commonly referred to as “linters,” named for the old Unix ’lint’ tool that performed this task for code written in the C programming language. Of course, the use of the term “lint” is a reference to the tiny bits of fiber and fuzz that are shed by clothing, with the idea that by removing the “lint” that makes our code messy, we can have code that is cleaner and easier to read and maintain.
In fact, you may have already encountered these tools in your programming experience. Development environments such as the one used by Codio, as well as other integrated development environments (IDEs) such as Visual Studio Code, PyCharm, IntelliJ, and others all include support for static code analysis. Usually it takes the form of helpful error messages that show simple syntax and usage errors.
In this course, we’ll learn how to use some more powerful static code analysis tools to enforce a standard coding style across all of our source code. A [coding style] can be thought of as roughly equivalent to a dialect of a spoken or written language - it deals with common conventions and usage, beyond just the simple definitions and syntax rules of the language itself. By following a standardized style, our code will be easier to read and maintain for any developer who is familiar with that style.
Based on the previous page, it sounds like writing professional code can be quite difficult. There are so many tools and concepts to keep track of, and, in fact, you may end up spending just as much time working with everything else around your code as you do writing the code itself. The benefit of all of this work comes later, when you have to update or maintain the code. If you’ve done a good job writing unit tests, checking for coverage, documenting and styling your code, you’ll end up with fewer bugs overall, and hopefully it will be easier to patch and update the code over the long term that it is in use.
Thankfully, in this course, we’re going to start small in this module with a new project we’re calling “Hello Real World.”
Most programmers can recall the simple “Hello World” program they wrote when learning to program. For many of us, it is the first program we learned to write, and usually the first thing we write when learning a new language. It is almost a sacred tradition!
We’re going to build upon that in this module by learning to write a “Hello World” program of our own, but one that meets the following requirements:
That’s quite a tall order, but this is really how a professional software developer would approach writing good and maintainable code. In some languages, such as Java, a few parts of this process are pretty straightforward - Java is already fully object-oriented by default, and Java uses a common standard for creating in-code documentation. Other languages, such as Python, end up becoming more complex to work with as more requirements are added. For Python developers, a simple “Hello World” program is a single line of code, whereas this set of requirements requires multiple files to properly create a Python package. In addition, the Python language itself does not define a common standard for in-code documentation, so we must rely on external resources to determine what coding style we should follow.
Thankfully, we’ll go through this entire process step by step in the example portion of this module, and you’ll be able to follow along and build your own version of “Hello Real World.”
Portions of the content on this page were adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
In this chapter, we’ve discussed the environment in which object-orientation emerged. Early computers were limited in their computational power, and languages and programming techniques had to work around these limitations. Similarly, these computers were very expensive, so their purchasers were very concerned about getting the largest possible return on their investment. In the words of Niklaus Wirth:
Tricks were necessary at this time, simply because machines were built with limitations imposed by a technology in its early development stage, and because even problems that would be termed "simple" nowadays could not be handled in a straightforward way. It was the programmers' very task to push computers to their limits by whatever means available.
As computers became more powerful and less expensive, the demand for programs (and therefore programmers) grew faster than universities could train new programmers. Unskilled programmers, unwieldy programming languages, and programming approaches developed to address the problems of older technology led to what became known as the “software crisis” where many projects failed or floundered.
This led to the development of new programming techniques, languages, and paradigms to make the process of programming easier and less error-prone. Among the many new programming paradigms was structured programming paradigm, which introduced control-flow structures into programming languages to help programmers reason about the order of program execution in a clear and consistent manner. Also developed during this time was the object-oriented paradigm, which we will be studying in this course.
Today, many software developers have adopted techniques designed to produce high quality code. These include the use of automated unit testing and test-driven development, as well as standardized use of code comments and linters to maintain good coding style and ample documentation for future developers. In the project for this module, we’ll explore what this looks like by building a simple “Hello World” program that uses all of these techniques.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
The best programming paradigm, “objectively” speaking!
Much of the content in this chapter was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
A signature aspect of object-oriented languages is (as you might expect from the name), the existence of objects within the language. In this chapter, we take a deep look at objects, exploring why they were created, what they are at both a theoretical and practical level, and how they are used.
Some key terms to learn in this chapter are:
To begin, we’ll examine the term encapsulation.
The first criteria that Alan Kay set for an object-oriented language was encapsulation. In computer science, the term encapsulation refers to organizing code into units, which provide two primary benefits:
Think back to the FORTRAN EPIC model we introduced in an earlier module. All of the variables in that program were declared globally, and there were thousands of them. If we open the code today, could we even find where a variable was declared? Initialized? Used? Could we be sure that we found all the spots it was used?
Also, how easily could we determine what part of the system a particular block of code belonged to? If we knew the program involved modeling hydrology (how water moves through the soils), weather, erosion, plant growth, plant residue decomposition, soil chemistry, planting, harvesting, and chemical applications, could we find the code for each of those processes?
Recall from our discussion on the growth of computing that, as computers grew more powerful, we looked to use them in more powerful ways. The EPIC project grew from that desire - if we could model all the aspects influencing how well a crop grows, then we could use that to make better decisions in agriculture. Likewise, if we could model the processes involved in weather, we could help save lives by predicting dangerous storms! A century ago, the only way to know a tornado was coming when you heard its roaring winds approaching your home. Now we have warnings that conditions are favorable to produce one hours in advance! This is all thanks to our ability to use computers to model some very complex systems.
How do we go about writing those complex systems? We probably wouldn’t want to follow the model that the EPIC software gives us. And, thankfully, neither did most software developers at the time - so computer scientists set out to define better ways to write programs. David Parnas formalized some of the best ideas emerging from those efforts in his 1972 paper “On the Criteria To Be Used in Decomposing Systems into Modules”. 1
A data structure, its internal linkings, accessing procedures and modifying procedures are part of a single module.
Here he suggests organizing code into modules that group related variables and the procedures that operate upon them. For the EPIC module, this might mean all the code related to weather modeling would be moved into its own module. That means that if we needed to understand how weather was being modeled, we only had to look at the weather module.
They are not shared by many modules as is conventionally done.
Here he is laying the foundations for the concept we now call scope - the concept that a particular symbol (a variable or function name) is accessible only in certain locations within a program’s code. By limiting access to variables to the scope of a particular module, only code in that module can change the value. That way, we can’t accidentally change a variable declared in the weather module from somewhere else, like the soil chemistry module. This would be a very hard error to find, because if the weather module doesn’t seem to be working, that’s where we would probably spend our time looking for the error.
Programmers of the time referred to this practice as information hiding, as we “hid” parts of the program from other parts of the program. Parnas and his peers pushed for not just hiding the data, but also how the data was manipulated. By hiding these implementation details, they could prevent programmers who were used to the globally accessible variables of early programming languages from looking into our code and using a variable that we might change in the future.
The sequence of instructions necessary to call a given routine and the routine itself are part of the same module.
As the actual implementation of the code is hidden from other parts of the program, a mechanism for sharing controlled access to some part of that module in order to use it needed to be made. An interface, for example, that describes how the other parts of the program might trigger some behavior or access some value.
D. L. Parnas, “On the criteria to be used in decomposing systems into modules” Communications of the ACM, Dec. 1972. ↩︎
Let’s start by focusing on encapsulation’s benefits to organizing our code by exploring some examples of encapsulation you may already be familiar with.
The Java and Python libraries are organized into discrete units called packages. The primary purpose of this is to separate code units that potentially use the same name, which causes name collisions where the compiler or interpreter isn’t sure which of the possibilities you mean in your program. This means you can use the same name to refer to two different things in your program, provided they are in different packages. Many other languages refer to these as namespaces.
For example, there are two definitions for a Date class in Java: java.util.Date and java.sql.Date. While they are related, they serve different purposes, and we wouldn’t want to get them confused. If we needed to create an instance of both in our program, we would use their fully-quantified name to help the compiler know which we mean:
java.sql.Date sqlDate = new java.sql.Date(System.currentTimeMillis());
java.util.Date utilDate = new java.util.Date(System.currentTimeMillis());
System.out.println(sqlDate.toString());
System.out.println(utilDate.toString());Running that code gives this output:
2020-12-30
Wed Dec 30 17:23:50 GMT 2020So, as we can see, these two classes are functionally different in some important ways.
While Java does not support aliases in imports, we can use an alias in Python to import two classes with the same name using different identifiers. For example, if there are two User classes in different packages, we could import them like this:
from package_one import User as PackageOneUser
from package_two import User as PackageTwoUser
user_1 = PackageOneUser.User()
user_2 = PackageTwoUser.User()Encapsulating code within a package helps ensure that the types defined within are only accessible with a fully qualified name, or when the using directive is employed. In either case, the intended type is clear, and knowing the package can help other programmers find the type’s definition.
We can also declare our own packages, allowing us to use packages to organize our own code just as Java and Python have done with their standard libraries. Below are quick examples for how to do this in Java and Python.
To create a class ClassName in a package cc410.package_name, we would include a package line at the top of the file:
package cc410.package_name;
public class ClassName{
//code here
}The ClassName.java file would be stored in app/src/main/java/cc410/package_name/. Basically, the package name corresponds to the folders where the source code is stored.
To create a class ClassName in a package cc410.package_name, we would simply place ClassName.py in the src/cc410/package_name directory. We’d also need to include an __init__.py file in that directory to make it a package.
Finally, if we want the cc410 package to act as a meta-package and be executable we would also include an __init__.py and a __main__.py file in the src/cc410 directory as well.
In previous textbooks, we created different sections for both Java and Python code, so generally students would only see one or the other.
In this class, we feel that it is important for developers to become familiar with more than one language, as it may help increase understanding. So, nearly all examples in this book will be presented using both Java and Python. We will clearly label each language where needed, but hopefully at this point you are comfortable enough with your chosen language to recognize it clearly.
Before we go further into some object-oriented concepts, let’s briefly review one important concept in programming - data types and type systems.
Most programming languages include several primitive data types, which are the fundamental units of data that can be stored and represented by that programming language. Here’s a short list of those primitive data types for each language:
| Data | Java | Python |
|---|---|---|
| Whole Numbers | int (byte, short, long) |
int |
| Floating-point Numbers | double (float) |
float |
| Boolean Values | boolean |
bool |
| Single Character | char |
str^[A string of length 1] |
| String of Characters | String^[This is not a primitive, but the String class. However, it is so ubiquitous that we’ll include it here.] |
str |
Any data that is stored by our program must fit into one of these data types. That is an important fundamental rule to remember - no matter how complex our code gets, everything is stored in primitive data types. That’s simply all there is.
What if we want to store more complex data, such as information about a person? Well, we could easily create an integer that stores the person’s age, and perhaps a string for the person’s name. Those are still just primitive data types, so we’re good there.
However, as you probably already know, we can group those items together into classes. However, before we can really understand classes and how they relate to encapsulation, we must look at a precursor to classes first. We’ll cover that later in this module.
The way that programming languages handle these data types is known as the type system of the language. Let’s look at two different ways to categorize type systems to see how they differ.
In programming, there are two common ways that programming languages deal with data types. The first is called static typing, where each variable has a particular data type associated with it as soon as it is declared, and that variable can only store items of that data type. Because of this, we can use tools like the Java compiler to analyze our code before we ever execute it, making sure that we always are storing the correct type of data in each variable.
Java is a statically typed language. When we create variables in Java, we must assign data types to them, as in this example:
int x = 5;
double y = 5.5;
String name = "CC 410";Similarly, when we create methods in Java, we must declare the types of all parameters, as well as the return type of the method.
Python, on the other hand, is a dynamically typed language. That means that variables in Python do not have a particular data type assigned to them, and they can store multiple different types of data throughout the course of the program. Here’s an example:
x = 5
x = 5.5
x = "CC 410"This is a perfectly valid program in Python, and will execute just fine. However, as we’ll soon learn, this could lead to some preventable errors, and we’ll see how to resolve them.
Programming languages can also be classified based on their use of type systems in one other way. A strongly typed language always knows what data type is stored in a variable at any given time during the program’s execution. In statically typed languages such as Java, this is trivial - if the program compiles, then we know that the only possible data type that could be stored in a variable is the type listed in that variable’s declaration. It’s pretty straightforward.
However, what about Python? Python is dynamically typed, which means that each variable could store multiple different data types during a single program’s execution, and each time the program executes it could be different. However, at any given instant during the execution of the program, the Python interpreter knows exactly what type of data is being stored in each of the variables in the program. We can use methods such as isinstance() to confirm this. So, Python is also a strongly typed language.
So, what is a weakly typed language? A great example is code written in an assembly language. The computer will simply execute whatever is written, and has no way of keeping track of the types of data stored in each variable. Instead, it depends on the compiler or developer to make sure there are no type errors in the assembly code.
As we learned in the “Hello Real World” project, we can add type annotations to Python code to convert Python into a statically typed language. Then, we can use tools such as Mypy to make sure there are no type errors in our code, much like the Java compiler does for Java code. So, here’s a rewritten example of Python code that is statically typed:
x: int = 5
y: float = 5.5
name: str = "CC 410"By adding these type annotations, we can tell Mypy what type of data we expect to be stored in each of these variables, and it can perform the same type checking process that the Java compiler uses. In this class, we’re going to focus on using statically typed Python code as much as we can.
We’re spending a little time reviewing types and type systems now because it will help us understand the new concepts being introduced in the next few pages. Before the introduction of object-oriented programming, programmers had to use other tools to build more complex data types than the primitives we’ve discussed here.
Many object-oriented languages, such as C++ and C#, include the concept of a struct that form the basis of objects. A struct is an example of a compound data type, a data type composed from other types. This allows us to represent data in more complex ways by combining multiple primitive data types into a new type. This too, is a form of encapsulation, as it allows us to collect several values into a single data structure. Consider the concept of a vector from mathematics - if we wanted to store three-dimensional vectors in a program, we could do so in several ways. Perhaps the easiest would be as an array or list:
double[] vector = {3.0, 4.0, 5.0};vector: List[float] = [3.0, 4.0, 5.0]However, other than the variable name, there is no indication to other programmers that this is intended to be a three-element vector. And, if we were to accept it in a function, say a dot product, we’d need to check that the length of both arrays or lists was exactly 3:
public double dotProduct(double[] a, double[] b){
if(a.length != 3 || b.length != 3){
throw new IllegalArgumentException();
}
return a[0] * b[0] + a[1] * b[1] + a[2] * b[2];
}def dot_product(a: List[float], b: List[float]) -> float:
if len(a) != 3 or len(b) != 3:
raise ValueError()
return a[0] * b[0] + a[1] * b[1] + a[2] * b[2]A struct provides a much cleaner option, by allowing us to define a type that is composed of exactly three integers. Java and Python don’t directly support structs, but we can use classes with just variables and a constructor to mimic a struct in those languages:
public class Vector3{
public double x;
public double y;
public double z;
public Vector3(double x, double y, double z){
this.x = x;
this.y = y;
this.z = z;
}
}class Vector3:
def __init__(self, x: float, y: float, z: float) -> None:
self.x = x
self.y = y
self.z = zThen, our dot product method can take two arguments of the Vector3 type:
public double dotProduct(Vector3 a, Vector3 b){
return a.x * b.x + a.y * b.y + a.z * b.z;
}def dot_product(a: Vector3, b: Vector3) -> float:
return a.x * b.x + a.y * b.y + a.z * b.zThere is no longer any concern about having the wrong number of elements in our vectors - it will always be three. We also get the benefit of having unique names for these fields (in this case, x, y, and z).
Thus, a struct allows us to create structure to represent multiple values in one variable, encapsulating the related values into a single data structure. We can then use those data structures as new data types in our program. Variables, and compound data types, together represent the state of a program. We’ll examine this concept in detail next.
It might seem like the kind of modules that Parnas was describing don’t exist in Java or Python, but they actually do - we just don’t call them “modules”. Consider how you would compute the square root of a number:
Math.sqrt(9.5);math.sqrt(9.5)The Math or math class in this example is actually used just like a module! We can’t see the underlying implementation of the sqrt() method, it just provides to us a well-defined interface (i.e. you call it with the symbol sqrt and a value as a parameter). This method and other related math functions are encapsulated within the Math or math class.
We can define our own module-like classes by making them static, i.e. we could group our vector math functions into a static VectorMath class.
import java.lang.Math;
public static class VectorMath(){
public static double dotProduct(Vector3 a, Vector3 b){
return a.x * b.x + a.y * b.y + a.z * b.z;
}
public static double magnitude(Vector3 a){
return Math.sqrt(Math.pow(a.x, 2) + Math.pow(a.y, 2) + Math.pow(a.z, 2));
}
}Usage:
Vector3 vect1 = new Vector3(3.0, 4.0, 5.0);
Vector3 vect2 = new Vector3(6.0, 7.0, 8.0);
System.out.println(VectorMath.dotProduct(vect1, vect2));
System.out.println(VectorMath.magnitude(vect1));import math
class VectorMath:
@staticmethod
def dot_product(a: Vector3, b: Vector3) -> float:
return a.x * b.x + a.y * b.y + a.z * b.z
@staticmethod
def magnitude(a: Vector3) -> float:
return math.sqrt(a.x ** 2 + a.y ** 2 + a.z ** 2)Usage:
vect1: Vector3 = Vector3(3.0, 4.0, 5.0)
vect2: Vector3 = Vector3(6.0, 7.0, 8.0)
print(VectorMath.dot_product(vect1, vect2))
print(VectorMath.magnitude(vect2))The data stored in a program at any given moment (in the form of variables, objects, etc.) is the state of the program. Consider a variable:
int a = 5;The state of the variable a after this line is 5. If we then run:
a = a * 3;The state is now 15. Consider the Vector3 struct we defined earlier. If we create an instance of that struct in the variable b:
Vector3 b = new Vector3(1.2, 3.7, 5.6);The state of our variable b is {$1.2, 3.7, 5.6$}. If we change one of b’s fields:
b.x = 6.0;The state of our variable b is {$6.0, 3.7, 5.6$}.
We can also think about the state of the program, which would be something like:
{$a: 5, b:${$x: 6.0, y: 3.7, z: 5.6$}}
We can therefore think of a program as a state machine. We can in fact, draw our entire program as a state table listing all possible legal states (combinations of variable values) and the transitions between those states. Techniques like this can be used to reason about our programs and even prove them correct!
This way of reasoning about programs is the heart of Automata Theory, a subject you may choose to learn more about if you pursue graduate studies in computer science.
What causes our program to transition between states? If we look at our earlier examples, it is clear that the assignment statement is a strong culprit. Expressions clearly have a role to play, as do control-flow structures, which decide which transformations take place. In fact, we can say that our program code is what drives state changes - the behavior of the program.
Thus, programs are composed of both state (the values stored in memory at a particular moment in time) and behavior (the instructions to change that state).
Now, can you imagine trying to draw the state table for a large program? Something on the order of EPIC?
On the other hand, with encapsulation we can reason about state and behavior on a much smaller scale. Consider this function working with our Vector3 struct:
public static Vector3 scale(Vector3 vec, double scale){
double x = vec.x * scale;
double y = vec.y * scale;
double z = vec.z * scale;
return new Vector3(x, y, z);
}@staticmethod
def scale(vec: Vector3, scale: float) -> Vector3:
x: float = vec.x * scale
y: float = vec.y * scale
z: float = vec.z * scale
return Vector3(x, y, z)If this method was invoked with a vector {$4.0, 1.0, 3.4$} and a scale $2.0$, our state table would look something like:
| step | vec.x | vec.y | vec.z | scale | x | y | z | return.x | return.y | return.z |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 4.0 | 1.0 | 3.4 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 2.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 2.0 | 6.8 | 0.0 | 0.0 | 0.0 |
| 4 | 4.0 | 1.0 | 3.4 | 2.0 | 8.0 | 2.0 | 6.8 | 8.0 | 2.0 | 6.8 |
Because the parameters vec and scale, as well as the variables x, y, z, and the unnamed Vector3 we return are all defined only within the scope of the method, we can reason about them and the associated state changes independently of the rest of the program. This greatly simplifies both writing and debugging programs.
The module-based encapsulation suggested by Parnas and his contemporaries grouped state and behavior together into smaller, self-contained units. Alan Kay and his co-developers took this concept a step farther. Alan Kay was heavily influenced by ideas from biology, and saw this encapsulation in similar terms to cells.
Biological cells are also encapsulated - the complex structures of the cell and the functions they perform are all within a cell wall. This wall is only bridged in carefully-controlled ways, i.e. cellular pumps that move resources into the cell and waste out. While single-celled organisms do exist, far more complex forms of life are made possible by many similar cells working together.
This idea became embodied in object-orientation in the form of classes and objects. An object is like a specific cell. You can create many, very similar objects that all function identically, but each have their own individual and different state. The class is therefore a definition of that type of object’s structure and behavior. It defines the shape of the object’s state, and how that state can change. But each individual instance of the class (an object) has its own current state.
Let’s re-write our Vector3 struct using this concept.
public class Vector3{
public double x;
public double y;
public double z;
public Vector3(double x, double y, double z){
this.x = x;
this.y = y;
this.z = z;
}
public double dotProduct(Vector3 other){
return this.x * other.x + this.y * other.y + this.z * other.z;
}
public void scale(double scalar){
this.x *= scalar;
this.y *= scalar;
this.z *= scalar;
}
}class Vector3:
def __init__(self, x: float, y: float, z: float) -> None:
self.x = x
self.y = y
self.z = z
def dot_product(self, other: Vector3) -> float:
return self.x * other.x + self.y * other.y + self.z * other.z
def scale(self, scalar: float) -> None:
self.x *= scalar
self.y *= scalar
self.z *= scalarHere we have defined:
x, y, and zscale() methodWe can create as many objects from this class definition as we might want. Each one will have the same behavior but different state.
Vector3 one = new Vector3(1.0, 1.0, 1.0);
Vector3 up = new Vector3(0.0, 1.0, 0.0);
Vector3 a = new Vector3(5.4, -21.4, 3.11);one: Vector3 = Vector3(1.0, 1.0, 1.0)
up: Vector3 = Vector3(0.0, 1.0, 0.0)
a: Vector3 = Vector3(5.4, -21.4, 3.11)Conceptually, what we are doing is not that different from using a compound data type like a struct and a module of functions that work upon that struct. But practically, it means all the code for working with vectors appears in one place. This arguably makes it much easier to find all the pertinent parts of working with vectors, and makes the resulting code better organized and easier to maintain and add features to. This highlights why encapsulation is one of the key concepts in object-oriented programming.
Most of the content below will apply to the Java language only. Python does not directly support information hiding through access modifiers, but simulates it by allowing developers to prefix variables with underscores to indicate that they are “protected” and should be left alone. Likewise, prefixing a Python variable or method name with two underscores will make it appear private to the class, but a developer can simply add the class name to the variable or method name in order to access it. So, in places below where we state that an external class “cannot” access a private attribute, keep in mind that in Python it is always possible and “should not” is a better term to use.
Thankfully, the concepts are mostly the same, so this is good information for both Java and Python developers to understand.
Now let’s return to the concept of information hiding, and how it applies in object-oriented languages.
Unanticipated changes in state are a major source of errors in programs. Again, think back to the EPIC source code we looked at earlier. It may have seemed unusual now, but it used a common pattern from the early days of programming, where all the variables the program used were declared in one spot, and were global in scope (i.e. any part of the program could reassign any of those variables).
If we consider the program as a state machine, that means that any part of the program code could change any part of the program’s state. Provided those changes were intended, everything works fine. But if the wrong part of the state was changed, problems would ensue.
For example, if we were to make a typo in the part of the program dealing with water run-off in a field, which ends up assigning a new value to a variable that was supposed to be used for crop growth, we’ve just introduced a very subtle and difficult to find error. When the crop growth modeling functionality fails to work properly, we’ll probably spend serious time and effort looking for a problem in the crop growth portion of the code, but the problem doesn’t lie in that code at all!
Java, along with many other object-oriented languages, use access modifiers to implement data hiding. Consider a class representing a student:
public class Student{
private String first;
private String last;
private int wid;
public Student(String first, String last, int wid){
this.first = first;
this.last = last;
this.wid = wid;
}
}class Student:
def __init__(self, first: str, last: str, wid: int) -> None:
self.__first = first
self.__last = last
self.__wid = widBy using the access modifier private in Java, or prefixing the attributes with two underscores in Python, we have indicated that our fields first, last, and wid cannot be accessed (seen or assigned) outside of this code. For example, if we were to create a specific student:
Student willie = new Student("Willie", "Wildcat", 888888888);willie: Student = Student("Willie", "Wildcat", 888888888)We would not be able to change that student’s name. The statement willie.first = "Bob" would fail, because the field first is private. In fact, we cannot even see his name, so trying to print that value would also fail.
If we want to allow a field or method to be accessible outside of the object, we must declare it public in Java, or remove the underscores in Python. While we can declare fields public, this violates the core principles of encapsulation, as any outside code can modify our object’s state in uncontrolled ways. This is definitely not what we want.
Instead, in a true object-oriented approach we would write public accessor methods, a.k.a. getters and setters. These are methods that allow us to see and change field values in a controlled way. Adding accessors to our Student class might look like:
public class Student{
private String first;
private String last;
private int wid;
public Student(String first, String last, int wid){
this.first = first;
this.last = last;
this.wid = wid;
}
public String getFirst(){
return this.first;
}
public void setFirst(String value){
if(value.length() > 0){
this.first = value;
}
}
public String getLast(){
return this.last;
}
public void setLast(String value){
if(value.length() > 0){
this.last = value;
}
}
public int getWid(){
return this.wid;
}
}class Student:
def __init__(self, first: str, last: str, wid: int) -> None:
self.__first = first
self.__last = last
self.__wid = wid
@property
def first(self) -> str:
return self.__first
@first.setter
def first(self, value: str) -> None:
if len(value) > 0:
self.__first = value
@property
def last(self) -> str:
return self.__last
@last.setter
def last(self, value: str) -> None:
if len(value) > 0:
self.__last = value
@property
def wid(self) -> int:
return self.__widNotice how the setFirst() and setLast() setters in Java, and the first() and last() setters in Python, check that the provided name has at least one character? We can use setters to make sure that we never allow the object state to be set to something that makes no sense.
Also, notice that the wid field only has a getter. This effectively means once a student’s wid is set by the constructor, it cannot be changed (it’s read only). This allows us to share data without allowing it to be changed outside of the class.
Notice that Java uses methods called getFirst and setFirst as getters and setters, while Python uses the @property decorator and methods that share the same name. These properties in Python simplify the use of getters and setters in code.
For example, in Java, if we want to use a getter or setter, we must call them by the function name:
willie.setFirst("William");
System.out.println(willie.getFirst());Through the use of properties in Python, we can refer to the field directly by name, as if it were a public field, and our getter or setter will be called automatically:
willie.first = "William"
print(willie.first)Unfortunately, Java does not support the use of properties at this time.
We often talk about the class as a blueprint for an object. This is because classes define what properties and methods an object should have, in the form of a constructor. Consider this class representing a planet:
public class Planet{
private double mass;
public double getMass(){
return this.mass;
}
private double radius;
public double getRadius(){
return this.radius;
}
public Planet(double mass, double radius){
this.mass = mass;
this.radius = radius;
}
}class Planet
@property
def mass(self) -> float:
return self.__mass
@property
def radius(self) -> float:
return self.__radius
def __init__(self, mass: float, radius: float) -> None:
self.__mass = mass
self.__radius = radiusIt describes a planet as having a mass and a radius, which will be stored as the ratio of this planet’s attribute compared to Earth. We can create a specific planet by invoking its constructor, i.e.:
Planet earth = new Planet(1.0, 1.0);earth: Planet = Planet(1.0, 1.0)In this example, earth is an instance of the class Planet. We can create other instances, i.e.
Planet mars = new Planet(0.107, 0.53);mars: Planet = Planet(0.107, 0.53)We can even create a Planet instance to represent one of the exoplanets discovered by NASA’s TESS:
Planet hd21749b = new Planet(23.20, 2.836);hd21749b: Planet = Planet(23.20, 2.836)Let’s think more deeply about the idea of a class as a blueprint. A blueprint for what, exactly? For one thing, it serves to describe the state of the object, and helps us label that state. If we were to check the radius of our variable mars, we would access the getter for the radius field:
mars.getRadius()mars.radiusBut a class does more than just labeling the properties and fields and providing methods to mutate the state they contain. It also specifies how memory needs to be allocated to hold those values as the program runs.
Looking at our Planet class again, we can see it contains two floating point values. So, when we run the constructor for that class, our computer will know that it needs to allocate enough space in memory for those two values (8 bytes each in Java, and 24 bytes each in Python).
State and memory are clearly related - the current state is what data is stored in memory. It is possible to take that memory’s current state, write it to persistent storage (like the hard drive), and then read it back out at a later point in time and restore the program to exactly the state we left it with. This is actually what your operating system does when you put it into hibernation mode.
The process of writing out the state is known as serialization, and it’s a topic we’ll revisit later.
You might have wondered how the static modifier plays into objects. Essentially, the static keyword indicates the field or method it modifies exists in only one memory location. I.e. a static field references the same memory location for all objects that possess it.
Consider this simple example class:
public class Simple:
public static int x;
public int y;
public Simple(int x, int y){
this.x = x;
this.y = y;
}
}class Simple:
x: int = 0
def __init__(self, x: int, y: int) -> None:
Simple.x = x
self.y = yNotice that the Java language uses the static keyword for fields, whereas in Python the field is simply defined outside of the constructor, and only attached to the class name and not self.
We can also create a couple of instances:
Simple first = new Simple(10, 12);
Simple second = new Simple(8, 5);first: Simple = Simple(10, 12)
second: Simple = Simple(8, 5)Once we’ve created both instances, the value of first.x would be 8 - because first.x and second.x reference the same memory location (a static unchanging location), and second.x was set after first.x. If we changed it again:
first.x = 3Then both first.x and second.x would have the value 3, as they share the same memory location. first.y would still be 12, and second.y would still be 5.
Another way to think about static is that it means the field or method we are modifying belongs to the class and not the individual object. Hence, each object shares a static variable, because it belongs to their class.
Used on a method, the static keyword in Java or the @staticmethod decorator in Python indicates that the method belongs to the class definition, not the object instance. Hence, we must invoke it from the class, not an object instance: i.e. Math.pow().
Finally, when used with a class in Java, static indicates we can’t create objects from the class - the class definition exists on its own. Hence, the Math m = new Math(); is actually an error, as the Math class is declared static. Python does not directly support the static keyword for classes themselves, but classes which only contain static attributes and methods could be considered static classes.
The second criteria Alan Kay set for object-oriented languages was message passing. Message passing is a way to request a unit of code engage in a behavior, i.e. changing its state, or sharing some aspect of its state.
Consider the real-world analogue of a letter sent via the postal service. Such a message consists of: an address the message needs to be sent to, a return address, the message itself (the letter), and any data that needs to accompany the letter (the enclosures). A specific letter might be a wedding invitation. The message includes the details of the wedding (the host, the location, the time), an enclosure might be a refrigerator magnet with these details duplicated. The recipient should (per custom) send a response to the host addressed to the return address letting them know if they will be attending.
In an object-oriented language, message passing primarily take the form of methods. Let’s revisit our example Vector3 class from earlier:
public class Vector3{
public double x;
public double y;
public double z;
public Vector3(double x, double y, double z){
this.x = x;
this.y = y;
this.z = z;
}
public double dotProduct(Vector3 other){
return this.x * other.x + this.y * other.y + this.z * other.z;
}
public void scale(double scalar){
this.x *= scalar;
this.y *= scalar;
this.z *= scalar;
}
}class Vector3:
def __init__(self, x: float, y: float, z: float) -> None:
self.x = x
self.y = y
self.z = z
def dot_product(self, other: Vector3) -> float:
return self.x * other.x + self.y * other.y + self.z * other.z
def scale(self, scalar: float) -> None:
self.x *= scalar
self.y *= scalar
self.z *= scalarWe can also create a couple of instances of the class, and use its dot product method:
Vector3 a = new Vector3(1.0, 1.0, 2.0);
Vector3 b = new Vector3(4.0, 2.0, 1.0);
double c = a.dotProduct(b);a: Vector3 = Vector3(1.0, 1.0, 2.0)
b: Vector3 = Vector3(4.0, 2.0, 1.0)
c: float = a.dot_product(b)Consider the invocation of a.dotProduct(b) (Java) or a.dot_product(b) (Python) above. The method name, dotProduct or dot_product provides the details of what the message is intended to accomplish (the letter). Invoking it on a specific variable, i.e. a, tells us who the message is being sent to (the recipient address). The return type indicates what we need to send back to the recipient (the invoking code), and the parameters provide any data needed by the class to address the task (the enclosures).
Let’s define a new method for our Vector3 class that emphasizes the role message passing plays in mutating object state:
public void normalize(){
double magnitude = Math.sqrt(Math.pow(this.x, 2) + Math.pow(this.y, 2) + Math.pow(this.z, 2));
this.x /= magnitude;
this.y /= magnitude;
this.z /= magnitude;
}def normalize(self) -> None:
magnitude: float = math.sqrt(self.x ** 2 + self.y ** 2 + self.z ** 2)
self.x /= magnitude
self.y /= magnitude
self.z /= magnitudeWe can now invoke the normalize() method on a Vector3 object to mutate its state, shortening the magnitude of the vector to length 1.
Vector3 f = new Vector3(9.0, 3.0, 2.0);
f.normalize();f: Vector3 = Vector3(9.0, 3.0, 2.0)
f.normalize()Note how here, f is the object receiving the message normalize. There is no additional data needed, so there are no parameters being passed in. Our earlier dot product method took a second vector as its argument, and used that vector’s values to mutate its state.
Message passing therefore acts like those special molecular pumps and other gate mechanisms of a cell that control what crosses the cell wall. The methods defined on a class determine how outside code can interact with the object. An extra benefit of this approach is that a method becomes an abstraction for the behavior of the code, and the associated state changes it embodies. As a programmer using the method, we don’t need to know the exact implementation of that behavior - just what data we need to provide, and what it should return or how it will alter the program state. This makes it far easier to reason about our program, and also means we can change the internal details of a class (perhaps to make it run faster) without impacting the other aspects of the program.
You probably have noticed that in many programming languages we speak of functions, but in Java and other object-oriented languages, we’ll often speak of methods. You might be wondering just what is the difference?
Both are forms of message passing, and share many of the same characteristics. Broadly speaking though, methods are functions defined as part of an object. Therefore, their bodies can access the state of the object. In fact, that’s what the this keyword in Java means - it refers to this object, i.e. the instance of the class that the method is currently executing for. In Python, any class methods include a parameter typically named self that represents the same concept - the instance of the class that the method was called on. For non-object-oriented languages, there is no concept of this (or self as it appears in other languages).
However, many times developers will use the terms function and method interchangeably. Likewise, variables stored in a class may be referred to as both attributes and fields. Sadly, we are not very exacting about how we use our own terms, even though our field requires us to be exacting in other ways. So, we’ll just have to do our best to read the context clues and interpret what is meant. In this book, we’ll try to use these terms as clearly as we can.
In this chapter, we looked at how object-orientation adopted the concept of encapsulation to combine related state and behavior within a single unit of code, known as a class. We further explored how objects are instances of a class created through invoking a constructor method.
We also discussed several different ways of looking at and reasoning about objects - as a state machine, and as structured data stored in memory. We discussed how a method is really a form of message passing that provides an interface to interact with objects safely.
Finally, we explored how all of these concepts are implemented in both the Java and Python programming languages.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
Writing code, taking notes!
Much of the content in this chapter was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
One of the strategies for combating the challenges of the software crisis is writing clear documentation to support both the end-users who will use the program, as well as other developers who will update and maintain the code. Today, including high-quality documentation along with your code, both in the form of code comments and other external documentation, is seen as an important practice among software developers, especially those working on large projects with multiple developers.
In this chapter, we’ll learn about these terms:
After this chapter and the associated example project, we should be able to write effective documentation within our code using the correct format for our chosen programming language.
Documentation refers to the written materials that accompany program code. Documentation plays multiple, and often critical roles. Broadly speaking, we split documentation into two categories based on the intended audience:
As you might expect, the goals for these two styles of documentation are very different. User documentation instructs the user on how to use the software. Developer documentation helps orient the developer so that they can effectively create, maintain, and expand the software.
Historically, documentation was printed separately from the software. This was largely due to the limited memory available on most systems. For example, the EPIC software we discussed had two publications associated with it: a User Manual, which explains how to use it, and Model Documentation which presents the mathematic models that programmers adapted to create the software. There are a few very obvious downsides to printed manuals: they take substantial resources to produce and update, and they are easily misplaced.
As memory became more accessible, it became commonplace to provide digital documentation to the users. For example, with Unix (and Linux) systems, it became commonplace to distribute digital documentation alongside the software it documented. This documentation came to be known as man pages based on the man command (short for manual) that would open the documentation for reading. For example, to learn more about the Linux search tool grep, you would type the following command into a Linux terminal:
man grep That would open the documentation distributed with the grep tool. Man pages are written in a specific format; you can read more about it here.
While man pages are a staple of the Unix/Linux operating system, there was no equivalent in the DOS ecosystem (the foundations of Windows) until PowerShell was released in 2007, including the Get-Help tool. You can read more about it here.
However, once software began to be written with graphical user interfaces (GUIs), it became commonplace to incorporate the user documentation directly into the GUI, usually under a “Help” menu. This served a similar purpose to man pages by ensuring user documentation was always available with the software. Of course, one of the core goals of software design is to make the software so intuitive that users don’t need to reference the documentation. It is equally clear that developers often fall short of that mark, as there is a thriving market for books to teach certain software.
Of course, there are also thousands of YouTube channels devoted to teaching users how to use specific programs!
Developer documentation underwent a similar transformation. Early developer documentation was often printed and placed in a three-ring binder, as Neal Stephenson describes in his novel Snow Crash: 2
Fisheye has taken what appears to be an instruction manual from the heavy black suitcase. It is a miniature three-ring binder with pages of laser-printed text. The binder is just a cheap unmarked one bought from a stationery store. In these respects, it is perfectly familiar to Him: it bears the earmarks of a high-tech product that is still under development. All technical devices require documentation of a sort, but this stuff can only be written by the techies who are doing the actual product development, and they absolutely hate it, always put the dox question off to the very last minute. Then they type up some material on a word processor, run it off on the laser printer, send the departmental secretary out for a cheap binder, and that's that.
Shortly after the time this novel was written, the Internet became available to the general public, and the tools it spawned would change how software was documented forever. Increasingly, web-based tools are used to create and distribute developer documentation. Wikis, bug trackers, and autodocumentation tools quickly replaced the use of lengthy, and infrequently updated, word processor files.
https://commons.wikimedia.org/w/index.php?title=File:Dummies_(2973280850).jpg&oldid=478417927 ↩︎
Neal Stephenson, “Snow Crash.” Bantam Books, 1992. ↩︎
Developer documentation often faces a challenge not present in other kinds of documents - the need to be able to display snippets of code. Ideally, we want code to be formatted in a way that preserves indentation. We also don’t want code snippets to be subject to spelling and grammar checks, especially auto-correct versions of these algorithms, as they will alter the snippets. Ideally, we might also apply syntax highlighting to these snippets. Accordingly, a number of textual formats have been developed to support writing text with embedded program code, and these are regularly used to present developer documentation. Let’s take a look at several of the most common.
Since its inception, HTML has been uniquely suited for developer documentation. It requires nothing more than a browser to view - a tool that nearly every computer is equipped with (in fact, most have two or three installed). And the <code> element provides a way of styling code snippets to appear differently from the embedded text, and <pre> can be used to preserve the snippet’s formatting. Thus:
<p>This algorithm reverses the contents of the array, <code>nums</code></p>
<pre><code>for(int i = 0; i < nums.length/2; i++) {
int tmp = nums[i];
nums[i] = nums[nums.length - 1 - i];
nums[nums.length - 1 - i] = tmp;
}
</code></pre>Will render in a browser as:
This algorithm reverses the contents of the array, nums
for(int i = 0; i < nums.length/2; i++) {
int tmp = nums[i];
nums[i] = nums[nums.length - 1 - i];
nums[nums.length - 1 - i] = tmp;
}
JavaScript and CSS libraries like highlight.js, prism, and others can provide syntax highlighting functionality without much extra work.
Of course, one of the strongest benefits of HTML is the ability to create hyperlinks between pages. This can be invaluable in documenting software, where the documentation about a particular method could include links to documentation about the classes being supplied as parameters, or being returned from the method. This allows developers to quickly navigate and find the information they need as they work with your code.
However, there is a significant amount of boilerplate involved in writing a webpage (i.e. each page needs a minimum of elements not specific to the documentation to set up the structure of the page). The extensive use of HTML elements also makes it more time-consuming to write and harder for people to read in its raw form. Markdown is a markup language developed to counter these issues. Markdown is written as plain text, with a few special formatting annotations, which indicate how it should be transformed to HTML. Some of the most common annotations are:
#) indicates it should be a <h1> element, two hashes (##) indicates a <h2>, and so on…_) or asterisks (*) indicates it should be wrapped in a <i> element__) or double asterisks (**) indicates it should be wrapped in a <b> element[link text](url), which is transformed to <a href="url">link text</a>, which is transformed to <img alt="alt text" src="url"/>Code snippets are indicated with backtick marks (`). Inline code is written surrounded with single backtick marks, i.e. `int a = 1` and in the generated HTML is wrapped in a <code> element. Code blocks are wrapped in triple backtick marks, and in the generated HTML are enclosed in both <pre> and <code> elements. Thus, to generate the above HTML example, we would use:
This algorithm reverses the contents of the array, `nums`
```
for(int i = 0; i < nums.length/2; i++) {
int tmp = nums[i];
nums[i] = nums[nums.length - 1 - i];
nums[nums.length - 1 - i] = tmp;
}
```
Most markdown compilers also support specifying the language (for language-specific syntax highlighting) by following the first three backticks with the language name, i.e.:
```java
String aString = "abc123";
```
Nearly every programming language features at least one open-source library for converting Markdown to HTML. In addition to being faster to write than HTML, and avoiding the necessity to write boilerplate code, Markdown offers some security benefits. Because it generates only a limited set of HTML elements, which specifically excludes some most commonly employed in web-based exploits (like using <script> elements for script injection attacks), it is often safer to allow users to contribute markdown-based content than HTML-based content. Note: this protection is dependent on the settings provided to your HTML generator - most markdown converters can be configured to allow or escape HTML elements in the markdown text.
In fact, both the Codio guides in this course, as well as the website used to store the project milestones, was written using Markdown. Codio includes its own Markdown converter, whereas the website was converted to HTML using the Hugo framework, a static website generator built using the Go programming language.
Additionally, chat servers like RocketChat and Discord support using markdown in posts! Try it out sometime!
GitHub even incorporates a markdown compiler into its repository displays. If your file ends in a .md extension, GitHub will evaluate it as Markdown and display it as HTML when you navigate your repository. If your repository contains a README.md file at the top level of your project, it will also be displayed as the front page of your repository. GitHub uses an expanded list of annotations known as GitHub-flavored markdown that adds support for tables, task item lists, strikethroughs, and others. You can also use Markdown in GitHub pull requests, comments, and more!
It is best practice to include a README.md file at the top level of a project stored as Git repository. This document provides an overview of the project, as well as helpful instructions on how it is to be used and where to go for more information. For open-source projects, you should also include a LICENSE file that contains the terms of the license the software is released under. For example, much of the content in this course is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
Extensible Markup Language (XML) is a close relative of HTML - they share the same ancestor, Standard Generalized Markup Language (SGML). It allows developers to develop their own custom markup languages based on the XML approach, i.e. the use of elements expressed via tags and attributes. XML-based languages are usually used as a data serialization format. For example, this snippet represents a serialized fictional student:
<student>
<firstName>Willie</firstName>
<lastName>Wildcat</lastName>
<wid>8888888</wid>
<degreeProgram>BCS</degreeProgram>
</student>While XML is most known for representing data, it can also be used to create documentation, most notably in the Microsoft .NET ecosystem.
Of course, one of the most important ways that developers can add documentation to their software is through the use of code comments. A code comment is simply extra text added to the source code of a program which is ignored by the compiler or interpreter - it is only visible within the source code itself. Nearly every programming language supports the inclusion of code comments to help describe or explain how the code works, and it is a vital way for developers to make notes, share information, and make sure anyone else reading the code can truly understand what it does.
Unfortunately, there is not a well established rule for what constitutes a useful code comment, or even how many comments should be included in code. Various developers have proposed ideas such as Literate Programming, which involves writing complete explanations of the program’s logic, all the way down to Self-Documenting Code, which proposes the idea that using properly named variables and well structured code will eliminate the need for any documentation at all, and everything in between. There are numerous articles and books written about how to document code properly that can be found through a simple online search.
For the purposes of this course, we recommend writing useful code comments anytime the code contains something interesting or unique, or something that required a bit of thinking and effort to create or understand. In that way, the next time a developer looks at the code, we can reduce the amount of time that developer spends trying to understand what the code is doing.
In short, we should write comments that help us understand our code better, but we shouldn’t focus on commenting every single line or expression, especially when it is pretty obvious what it does. To help with that, we can use properly named variables that accurately describe the data being manipulated, and use simple expressions that are easy to follow instead of complex ones.
Each programming language defines its own specification for comments. Here is the basic information for both Java and Python.
// Single line Java comments are prefixed by two slashes.
int x = 5; // Comments can be placed at the end of a line.
/*
* This is an example of a block comment.
*
* It begins with a slash and an asterisk, and ends
* with an asterisk and a slash.
*
* By convention, each line is prefixed with an asterisk
* that is aligned with the starting asterisk, but this is not
* strictly required.
*/
/**
* This is an example of a documentation comment.
*
* It begins with a slash and a two asterisks, and ends
* with an asterisk and a slash.
*
* By convention, each line is prefixed with an asterisk
* that is aligned with the starting asterisk, but this is not
* strictly required.
*
* These blocks are processed by Javadoc to create documentation.
*/# Single line Python comments are prefixed by a hash symbol
x = 5 # comments can be placed at the end of a line
""" Python does not directly support block comments.
However, a bare string literal, surrounded by three double-quotes
can be used to create a longer comment.
Python refers to these comments as docstrings when used
to document elements such as functions or classes
"""In addition to comments within the source code, we can also include formal documentation comments about classes and methods in our code. These comments help describe the functionality of parts of our code, and can be parsed to create generated documentation. On the next two pages, we’ll introduce the documentation standard for both Java and Python. Feel free to only read about the language you are learning, but it might be interesting to see how other languages handle the same idea in different ways.
The Java software development kit (SDK) includes a tool called Javadoc, which can create documentation based on the documentation comments included in the code. Both the Javadoc Documentation and the Google Style Guide include information about how those documentation comments should be structured and the information each should contain. This page will serve as a quick guide for the most common use cases, but you may wish to refer to the documentation linked above for more specific examples and information. The Checkstyle tool is also a great way to check that the documentation comments are properly structured.
A properly structured Javadoc comment includes a few parts:
<p> tag. However, unlike HTML, notice that there is no matching </p> closing tag required.@author (classes and interfaces only)@version (classes and interfaces only)@param (methods and constructors only)@return (methods only)@throws@seeWhen including multiple @author, @param or @throws tags, there are some rules governing the ordering of the tags as well. You can find much more information about the tags and how they can be used in the Javadoc Documentation.
Let’s begin by looking at the Javadoc comment for a class. Here’s an example:
/**
* Represents a chessboard and moves chess pieces.
*
* <p>This class stores a chessboard in a 2D array and includes
* methods to move various chess pieces across the board. Squares
* are labelled using algebraic chess notation.
*
* @author Russell Feldhausen russfeld@ksu.edu
* @version 0.1
*/
public class Chessboard {This comment includes a summary fragment, and additional paragraph, and the two required tags for a class comment, @author and @version. At a minimum, each class we develop should include this information directly above the class declaration.
This comment provides enough information for us to understand what the class is used for and a bit about how it works, even without seeing the code.
Here’s another example Javadoc comment, this time for a method:
/**
* Moves a knight from one square to another
*
* <p>If a knight is present on <code>source</code> and
* can make a legal move to <code>destination</code>, the method
* will perform the move.
*
* @param source the source square in algebraic chess notation
* @param destination the destination square in algebraic chess notation
* @return <code>true</code> if a piece was captured;
* <code>false</code> otherwise
* @throws IllegalArgumentException if a knight is not present on
* <code>source</code> or if that knight
* cannot move to <code>destination</code>
*/
public boolean moveKnight(String source, String destination) {Similar to the comment above, this comment includes enough information for us to understand exactly what the method does. It tells us about the parameters it accepts and the format it expects, the return value, and any exceptions that could be thrown by this code. With this comment alone, we could probably write the code for the method itself!
The two examples above cover most places where we would use Javadoc comments in our code. The only other example would be for any public attributes of a class, as in this example:
/** The Student's Wildcat ID */
public int wid;However, as we discussed in a previous module, if we follow the concepts of encapsulation and information hiding we shouldn’t have any publicly-accessible attributes, only public accessor methods such as getters and setters, which can be documented as methods. So, we probably won’t end up using this much in our own code.
Many Python developers have standardized on the use of docstrings as documentation comments. Both PEP 257 and the Google Style Guide include information about how those documentation comments should be structured and the information each should contain. This page will serve as a quick guide for the most common use cases, but you may wish to refer to the documentation linked above for more specific examples and information. The flake8 tool along with the flake8-docstrings plugin is also a great way to check that the documentation comments are properly structured.
A properly structured docstring comment includes a few parts:
Author (files only)Version (files only)Attributes (classes with public attributes only)Args (methods and constructors only)Returns (methods only)RaisesYou can find more information about the structure of docstrings in the Google Style Guide.
Let’s begin by looking at the docstring comment for a file. Here’s an example:
"""Implements a simple chessboard.
This file contains a class to represent a chessboard.
Author: Russell Feldhausen russfeld@ksu.edu
Version: 0.1
"""The file docstring gives information about the contents of the file. For object-oriented programs where each file contains a single class, this can be a bit redundant, but it is useful information nonetheless. For other Python files, this may be the only comment included in the file.
While the Python documentation format does not require listing the author or the version, it is a nice convention from the Javadoc format that we can carry over into our Python docstrings as well.
Next, let’s look at the docstring comment for a class. Here’s an example:
class Chessboard:
"""Represents a chessboard and moves chess pieces.
This class stores a chessboard in a 2D array and includes
methods to move various chess pieces across the board. Squares
are labelled using algebraic chess notation.
"""This comment includes a summary fragment, and an additional paragraph. Since the class doesn’t include any public attributes, we omit that section. Instead, we’ll document the accessor methods, or getters and setters, as part of the Python property that is used to access or modify private attributes.
This comment provides enough information for us to understand what the class is used for and a bit about how it works, even without seeing the code.
Here’s another example docstring comment, this time for a method:
def move_knight(self, source: str, destination: str) -> bool:
"""Moves a knight from one square to another
If a knight is present on source and
can make a legal move to destination, the method
will perform the move.
Args:
source: the source square in algebraic chess notation
destination: the destination square in algebraic chess notation
Returns:
True if a piece was captured; False otherwise
Raises:
ValueError: if a knight is not present on source or
if that knight cannot move to destination
"""Similar to the comment above, this comment includes enough information for us to understand exactly what the method does. It tells us about the parameters it accepts and the format it expects, the return value, and any exceptions that could be thrown by this code. With this comment alone, we could probably write the code for the method itself!
One of the biggest innovations in documenting software was the development of documentation generation tools. These were programs that would read source code files, and combine information parsed from the code itself and information contained in code comments to generate documentation in an easy-to-distribute form (often HTML).
This approach meant that the language of the documentation was embedded within the source code itself, making it far easier to update the documentation as the source code was refactored. Then, every time a release of the software was built, the documentation could be regenerated from the updated comments and source code. This made it far more likely developer documentation would be kept up-to-date.
So, once we have properly documented our code using documentation comments, we can then use tools such as Javadoc for Java or pdoc3 for Python to automatically generate documentation for developers. That documentation contains all of the contents of our documentation comments, and serves as a handy reference for any developers who wish to use our code.
In the Java ecosystem, this is best represented by the Java API itself, which is generated using Javadoc directly from the source code of the Java SDK itself.
For Python, there are many documentation generators available, but we’ve chosen to use pdoc3. An example of its output is the pdoc3 Documentation.
In either case, the use of these tools, combined with up to date documentation comments in our code, means that we can easily generate documentation quickly and easily.
In this chapter, we examined the need for software documentation aimed at both end-users and developers (user documentation and developer documentation, respectively). We also examined some formats this documentation can be presented in: HTML, Markdown, and XML. We also discussed documentation generation tools, which generate developer documentation from specially-formatted comments in our code files.
We examined the both the Java and Python approach to documentation comments, helping other developers understand our code. For this reason, as well as the ability to produce HTML-based documentation using a documentation generator tool, it is best practice to use documentation comments in all our programs.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
Making sure everything works correctly!
Much of the content in this chapter was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
A critical part of the software development process is ensuring the software works! We mentioned earlier that it is possible to logically prove that software works by constructing a state transition table for the program, but once a program reaches a certain size, this strategy becomes less feasible. Similarly, it is possible to model a program mathematically and construct a theorem that proves it will perform as intended. But in practice, most software is validated through some form of testing. This chapter will discuss the process of testing object-oriented systems.
Some key terms to learn in this chapter are:
The key skill to learn in this chapter is how to write unit tests in our chosen language. For Java, we’ll be using JUnit 5 to write our tests, and in Python we’ll use pytest as our test framework. We will also explore using the Hamcrest assertion library for both Java and Python.
As you’ve developed programs, you’ve probably run them, supplied input, and observed if what happened was what you wanted. This process is known as informal testing. It’s informal, because you don’t have a set procedure you follow, i.e. what specific inputs to use, and what results to expect. Formal testing adds that structure. In a formal test, you would have a written procedure to follow, which specifies exactly what inputs to supply, and what results should be expected. This written procedure is known as a test plan.
Historically, the test plan was often developed at the same time as the design for the software (but before the actual programming). The programmers would then build the software to match the design, and the completed software and the test plan would be passed onto a testing team that would follow the step-by-step testing procedures laid out in the testing plan. When a test failed, they would make a detailed record of the failure, and the software would be sent back to the programmers to fix.
This model of software development has often been referred to as the “waterfall model” as each task depends on the one before it:
Unfortunately, as this model is often implemented, the programmers responsible for writing the software are reassigned to other projects as the software moves into the testing phase. Rather than employ valuable programmers as testers, most companies will hire less expensive workers to carry out the testing. So either a skeleton crew of programmers is left to fix any errors that are found during the tests, or these are passed back to programmers already deeply involved in a new project.
The costs involved in fixing software errors also grow larger the longer the error exists in the software. The table below comes from a NASA report of software error costs throughout the project life cycle:
It is clear from the graph and the paper that the cost to fix a software error grows exponentially if the fix is delayed. You probably have instances in your own experience that also speak to this - have you ever had a bug in a program you didn’t realize was there until your project was nearly complete? How hard was it to fix, compared to a error you found and fixed right away?
It was realizations like these, along with growing computing power, that led to the development of automated testing, which we’ll discuss next.
File:Waterfall model.svg. (2020, September 9). Wikimedia Commons, the free media repository. Retrieved 16:48, October 21, 2021 from https://commons.wikimedia.org/w/index.php?title=File:Waterfall_model.svg&oldid=453496509. ↩︎
Jonette M. Stecklein, Jim Dabney, Brandon Dick, Bill Haskins, Randy Lovell, and Gregory Maroney. “Error Cost Escalation Through the Project Life Cycle”, NASA, June 19, 2014. ↩︎
Automated testing is the practice of using a program to test another program. Much as a compiler is a program that translates a program from a higher-order language into a lower-level form, a test program executes a test plan against the program being tested. And much like you must supply the program to be compiled, for automated testing you must supply the tests that need to be executed. In many ways, the process of writing automated tests is like writing a manual test plan - you are writing instructions of what to try, and what the results should be. The difference is with a manual test plan, you are writing these instructions for a human. With an automated test plan, you are writing them for a program.
Automated tests are typically categorized as unit, integration, and system tests:
The complexity of writing tests scales with each of these categories. Emphasis is usually put on writing unit tests, especially as the classes they test are written. By testing these classes early, errors can be located and fixed quickly.
In this course, we’ll focus on the creation of unit tests to effectively test the software we create. At a minimum, our goal is to write enough tests to achieve a high level of code coverage of our program being tested. Recall that code coverage is a measure of the amount of code in a program that is executed by a set of unit tests.
In theory, a good set of unit tests should, at a minimum, execute every line of code in the program at least once. Of course, that doesn’t nearly guarantee that the unit tests are sufficient to find all bugs, or even a majority of bugs, but it is a great place to start and make sure that the unit tests are properly testing the entirety of the program.
On the next few pages, we’ll discuss how to write unit tests for programs written in both Java and Python. Feel free to only read about the language you are learning, but it might be interesting to see how other languages handle the same idea in different ways.
Writing tests is in many ways just as challenging and creative an endeavor as writing programs. Tests usually consist of invoking some portion of program code, and then using assertions to determine that the actual results match the expected results. The result of these assertions are typically reported on a per-test basis, which makes it easy to see where your program is not behaving as expected.
Consider a class that is a software control system for a kitchen stove. We won’t write the code for the class itself, because it is important for us to be able to write tests that effectively test the code without even seeing it. It might have properties for four burners, which correspond to what heat output they are currently set to. Let’s assume this is as an integer between 0 (off) and 5 (high). When we first construct this class, we’d probably expect them all to be off! A test to verify that expectation would be:
import static org.junit.jupiter.api.Assertions.assertEquals;
import org.junit.jupiter.api.Test;
public class StoveTest{
@Test
public void testBurnersShouldBeOffAtInitialization(){
Stove stove = new Stove();
assertEquals(0, stove.getBurnerOne(), "Burner is not off after initialization");
assertEquals(0, stove.getBurnerTwo(), "Burner is not off after initialization");
assertEquals(0, stove.getBurnerThree(), "Burner is not off after initialization");
assertEquals(0, stove.getBurnerFour(), "Burner is not off after initialization");
}
}Here we’ve written the test using the JUnit 5 test framework, which is one of the most commonly used Java unit testing frameworks today.
Notice that the test is simply a method, defined in a class. This is very common for test frameworks, which tend to be written using the same programming language the programs they test are written in (which makes it easier for one programmer to write both the code unit and the code to test it). Above the test method is a method annotation @Test that tells JUnit to use this method as a unit test. Omitting the @Test annotation allows us to build other helper methods within our test classes as needed. Annotations are a way of supplying metadata within Java code. This metadata can be used by the compiler and other programs to determine how it works with your code. In this case, it indicates to the JUnit test runner that this method is a test.
Inside the method, we create an instance of stove, and then use the assertEquals(actual, expected, message) method to determine that the actual and expected values match. If they do, the assertion is marked as passing, and the test runner will display this pass. If it fails, the test runner will report the failure, along with details to help find and fix the problem (what value was expected, what it actually was, and which test contained the assertion).
To use the portions listed below, we’ll need to modify our build.gradle file to include the following dependencies:
dependencies {
// Use JUnit Jupiter API for testing.
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2', 'org.hamcrest:hamcrest:2.2', 'org.junit.jupiter:junit-jupiter-params'
// Use JUnit Jupiter Engine for testing.
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine'
// This dependency is used by the application.
implementation 'com.google.guava:guava:29.0-jre'
}Notice that we added a junit-jupiter-params library.
The JUnit framework provides for two kinds of tests, Test, which are written as functions that have no parameters, and ParameterizedTest, which do have parameters. The values for these parameters are supplied with another annotation, typically @ValueSource. For example, we might test that when we set a burner to a setting within the valid 0-5 range, it is set to that value:
import static org.junit.jupiter.api.Assertions.assertEquals;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.params.ParameterizedTest;
import org.junit.jupiter.params.provider.ValueSource;
public class StoveTest{
@ParameterizedTest
@ValueSource(ints = {0, 1, 2, 3, 4, 5})
public void ShouldBeAbleToSetBurnerOneToValidRange(int setting){
Stove stove = new Stove();
stove.setBurnerOne(setting);
assertEquals(setting, stove.getBurnerOne(), "Burner does not have expected value");
}
}The values in the parentheses of the @ValueSource annotation are the values supplied to the parameter list of the parameterized test method. Thus, this test is actually six tests; each test makes sure that one of the settings is working. We could have done all six as separate assignments and assertions within a single test method, but using a parameterized test means that if only one of these settings doesn’t work, we will see that one test fail while the others pass. This level of specificity can be very helpful in finding errors.
So far our tests cover the expected behavior of our stove. But where tests really prove their worth is with the edge cases - those things we as programmers don’t anticipate. For example, what happens if we try setting our range to a setting above 5? Should it simply clamp at 5? Should it not change from its current setting? Or should it shut itself off entirely because its user is clearly a pyromaniac bent on burning down their house? If the specification for our program doesn’t say, it is up to us to decide. Let’s say we expect it to be clamped at 5:
@ParameterizedTest
@ValueSource(ints = {6, 18, 1000000})
public void BurnerOneShouldNotExceedFive(int setting){
Stove stove = new Stove();
stove.setBurnerOne(setting);
assertEquals(5, stove.getBurnerOne(), "Burner does not have expected value");
}Note that we don’t need to exhaustively test all numbers above 5 - it is sufficient to provide a representative sample, ideally the first value past 5 (6), and a few others. Also, now that we have defined our expected behavior, we should make sure the documentation of our BurnerOne property matches it:
/**
* Sets the value of Burner One.
*
* Should be an integer between 0 (off) and 5 (high)
* If a value higher than 5 is provided, the burner will be
* set to 5 instead.
*
* @param value the value of the burner
*/
public void setBurnerOne(int value){This way, other programmers (and ourselves, if we visit this code years later) will know what the expected behavior is. We’d also want to test the other edge cases: i.e. when the burner is set to a negative number.
For a complete guide to parameterized tests in JUnit, including how to use enumerations as a value source, refer to the Guide to JUnit 5 Parameterized Tests from Baeldung.
Recognizing and testing for edge cases is a critical aspect of test writing. But it is also a difficult skill to develop, as we have a tendency to focus on expected values and expected use-cases for our software. But most serious errors occur when values outside these expectations are introduced. Also, remember special values, like Double.POSITIVE_INFINITY, Double.NEGATIVE_INFINITY, and Double.NaN.
Like most testing frameworks, the JUnit framework provides a host of specialized assertions. They are all created as static methods within the Assertions class, and many of them are described in the JUnit 5 User Guide.
For example, JUnit provides two boolean assertions:
assertTrue(condition) - asserts that the value supplied is trueassertFalse(condition) - asserts that the value supplied is falseAs with any assertion statements in JUnit, we can also optionally supply a message string as an additional parameter to these assertion statements. That message will be present in the error message when this assertion fails.
The workhorse of the JUnit assertion library are the assertEquals() and assertNotEquals() methods. That method is overloaded, with implementations that accept many different data types. These are all listed in the Assertions documentation, but they all follow the same basic form:
assertEquals(expected, actual)assertNotEquals(expected, actual)For floating-point values such as the double data type, you can also specify a delta value, such that the values are considered equal as long as their positive difference is less than delta
assertEquals(expected, actual, delta)assertNotEquals(expected, actual, delta)Why do we need to include a delta value? This is because floating-point values are by their nature imprecise, and can sometimes lead to strange errors. Consider this example from GeeksforGeeks:
public static void main(String[] args)
{
double a = 0.7;
double b = 0.9;
double x = a + 0.1;
double y = b - 0.1;
System.out.println("x = " + x);
System.out.println("y = " + y );
System.out.println(x == y);
}While we would expect both x and y to store the same value, they are actually slightly different.
So, we may need to account for this imprecision in our unit tests. We could also rewrite our code to avoid the use of floating point values. For example, many programs that deal with monetary values actually store them as integers based on cents instead of dollars, and simply add the decimal point only when the value is printed.
JUnit also includes assertions for arrays. These methods are also overloaded to handle many different data types:
assertArrayEquals(expected, actual)This method is really handy when we need to check that the contents of an entire array match the values we expect it to contain.
For lists of strings (List<String> data type), JUnit also includes a special method to confirm that each line matches what is expected.
assertLinesMatch(expectedLines, actualLines)This is very handy for checking that multiple lines of output produced by a program match the expected output.
JUnit also includes several helpful assertion methods that allow us to determine if two objects are the same actual object in memory (the same reference), as well as if an object is null:
assertNull(actual)assertNotNull(actual)assertSame(expected, actual)assertNotSame(expected, actual)JUnit also includes a special type of assertion that can be used to catch exceptions. This allows us to assert that a particular piece of code being tested should, or should not, throw an exception.
To do this, JUnit uses a lambda expression, which we haven’t covered yet in this course. We’ll discuss lambdas more in a later chapter. Thankfully, the syntax is very simple. Here’s an example, taken from the JUnit 5 User Guide:
@Test
void exceptionTesting() {
Exception exception = assertThrows(ArithmeticException.class, () ->
calculator.divide(1, 0));
assertEquals("/ by zero", exception.getMessage());
}The assertThrows(expectedType, executable) method is used to assert that the calculator.divide() method will throw an exception, specifically an ArithmeticException. If that method call does not throw an exception, then the assertion will fail.
The second argument to the assertThrows() method is a lambda expression. In Java, a lambda expression can be thought of as an anonymous function - we are defining a block of code that acts like a function, but we’re not giving it a name. That allows us to pass that block of code as a parameter to another method, where it can be executed. See Anonymous Function on Wikipedia for a deeper explanation. As we mentioned before, we’ll learn more about lambda expressions later in this course.
We can also write code to assert that a method does not throw an exception using the assertDoesNotThrow() assertion:
@Test
void noExceptionTesting() {
assertDoesNotThrow(() ->
calculator.multiply(1, 0));
}JUnit includes one other assertion that is used to simply fail a test:
fail(message)By including the fail() method in our unit test, we can cause a test to fail immediately. This allows us to build conditional statements to test complex values that are difficult to express in the provided assertion methods, and then fail a test if the conditional expression reaches the wrong branch. Here’s a quick example:
@Test
void testFail() {
if(calculator.multiply(1, 0) > calculator.multiply(0, 1)){
fail("Commutative property violated!");
}
}One task we may want to be able to perform in our unit tests is capturing output printed by the program. By default, any output that is printed using System.out is immediately sent to the terminal, but we can actually redirect that output without our tests in order to capture it and examine its contents.
We already saw how to do this in the “Hello Real World” project. Here’s that code once again:
@Test
public void testHelloWorldMain() {
HelloWorld hw = new HelloWorld();
final PrintStream systemOut = System.out;
ByteArrayOutputStream testOut = new ByteArrayOutputStream();
System.setOut(new PrintStream(testOut));
hw.main(new String[]{});
System.setOut(systemOut);
assertEquals(testOut.toString(), "Hello World\n", "Unexpected Output");
}In that code, we start by storing a reference to the existing System.out as a java.io.PrintStream named systemOut. This will allow us to undo our changes at the end of the test.
Then, we create a new java.io.ByteArrayOutputStream called testOut to store the output printed to the terminal, and use the System.setOut method to redirect System.out to a new PrintStream based on our testOut stream. So, anything printed using System.out will be sent to that PrintStream and captured in our testOut variable.
Once we’ve done those changes, we can then execute our code, calling any functions and including any assertions that we’d like to check. When we are finished, we can then reset System.out back to the original reference using the System.setOut(systemOut) line.
Then, to check the output we received, we can use testOut.toString() to get the output it captured as a single string. If multiple lines of output were printed, they would be separated by \n character, so we could use String.split() to split that single string into individual lines if needed.
We can also choose to use the Hamcrest assertion library in our code, either instead of the JUnit assertions or in addition to them. Hamcrest includes some very helpful assertions that are not part of JUnit, and also includes version for many languages, including both Java and Python. Most of the autograders in previous Computational Core courses are written with the Hamcrest assertion library!
Hamcrest uses a single basic assertion method called assertThat() to perform all assertions. It comes in two basic forms:
assertThat(actual, matcher) - asserts that actual passes the matcher.assertThat(message, actual, matcher) - asserts that actual passes the matcher. If not, it will print message as part of the failure.The real power of Hamcrest lies in the use of Matchers, which are used to determine if the actual value passes a test. If not, then the assertThat method will fail, just like a JUnit assertion.
For example, to test if an actual value returned by a fictional calculator object is equal to an expected value, we could use this statement:
assertThat(calculator.add(1, 3), is(4));As we can see, reading this statement out loud tells us everything we need to know: “Assert that calculator.add(1, 3) is 4!”
Here are a few of the most commonly used Hamcrest matchers, as listed in the Hamcrest Tutorial. The full list of matchers can be found in the Matchers class in the Hamcrest documentation:
is(expected) - a shortcut for equality - an example of syntactic sugar as discussed below.equalTo(expected) - will call the actual.equals(expected) method to test equalityisCompatibleType(type) - can be used to check if an object is the correct type, helpful for testing inheritancenullValue() - check if the value is nullnotNullValue() - check if the value is not nullsameInstance(expected) - checks if two objects are the same instancehasEntry(entry), hasKey(key), hasValue(value) - matchers for working with Maps such as HashMapshasItem(item) - matcher for Collections such as LinkedListhasItemInArray(item) - matcher for arrayscloseTo(expected, delta) - matcher for testing floating-point values within a rangegreaterThan(expected), greaterThanOrEqualTo(expected), lessThan(expected), lessThanOrEqualTo(expected) - numerical matchersequalToIgnoringCase(expected), equalToIgnoringWhiteSpace(expected), containsString(string), endsWith(string), startsWith(string) - string matchersallOf(matcher1, matcher2, ...), anyOf(matcher1, matcher2, ...), not(matcher) - boolean logic operators used to combine multiple matchersHamcrest includes a helpful matcher called is that makes some assertions more easily readable. For example, each of these assertion statements from the Hamcrest Tutorial all test the same thing:
assertThat(theBiscuit, equalTo(myBiscuit));
assertThat(theBiscuit, is(equalTo(myBiscuit)));
assertThat(theBiscuit, is(myBiscuit));By including the is matcher, we can make our assertions more readable. We call this syntactic sugar since it doesn’t add anything new to our language structure, but it can help make it more readable.
There are lots of great examples of how to use Hamcrest available on the web. Here are a couple that are worth checking out:
Writing tests is in many ways just as challenging and creative an endeavor as writing programs. Tests usually consist of invoking some portion of program code, and then using assertions to determine that the actual results match the expected results. The result of these assertions are typically reported on a per-test basis, which makes it easy to see where your program is not behaving as expected.
Consider a class that is a software control system for a kitchen stove. We won’t write the code for the class itself, because it is important for us to be able to write tests that effectively test the code without even seeing it. It might have properties for four burners, which correspond to what heat output they are currently set to. Let’s assume this is as an integer between 0 (off) and 5 (high). When we first construct this class, we’d probably expect them all to be off! A test to verify that expectation would be:
from src.hello.Stove import Stove
class TestStove:
def test_burners_should_be_off_at_initialization(self):
stove = Stove()
assert stove.burner_one == 0, "Burner is not off after initialization"
assert stove.burner_two == 0, "Burner is not off after initialization"
assert stove.burner_three == 0, "Burner is not off after initialization"
assert stove.burner_four == 0, "Burner is not off after initialization"Here we’ve written the test using the pytest test framework, which is one of the most commonly used Python unit testing frameworks today.
Notice that the test is simply a method, defined in a class. This is very common for test frameworks, which tend to be written using the same programming language the programs they test are written in (which makes it easier for one programmer to write both the code unit and the code to test it). The test method itself is prefixed with test, as well as the file where the test is stored. In addition, the class name also includes the word Test. These naming conventions help pytest find test methods in the code, as described in the pytest Guide. Omitting the test prefix in the method name allows us to build other helper methods within our test classes as needed.
Inside the method, we create an instance of stove, and then use the assert statement to determine that the actual and expected values match. If they do, the assertion is marked as passing, and the test runner will display this pass. If it fails, the test runner will report the failure, along with details to help find and fix the problem (what value was expected, what it actually was, and which test contained the assertion).
The pytest framework provides for two kinds of tests, standard tests, which are written as functions that have no parameters, and parameterized tests, which do have parameters. The values for these parameters are supplied with a special method annotation, typically @pytest.mark.parametrize. For example, we might test that when we set a burner to a setting within the valid 0-5 range, it is set to that value:
from src.hello.Stove import Stove
import pytest
class TestStove:
@pytest.mark.parametrize("value", [0, 1, 2, 3, 4, 5])
def test_should_be_able_to_set_burner_one_to_valid_range(self, value):
stove = Stove()
stove.burner_one = value
assert stove.burner_one == value, "Burner does not have expected value"Note the creative spelling of the @parametrize annotation! Be careful to not misspell it (by spelling it correctly) in your code.
The values in the parentheses of the @parametrize annotation are the values supplied to the parameter list of the parameterized test method. Thus, this test is actually six tests; each test makes sure that one of the settings is working. We could have done all six as separate assignments and assertions within a single test method, but using a parameterized test means that if only one of these settings doesn’t work, we will see that one test fail while the others pass. This level of specificity can be very helpful in finding errors.
So far our tests cover the expected behavior of our stove. But where tests really prove their worth is with the edge cases - those things we as programmers don’t anticipate. For example, what happens if we try setting our range to a setting above 5? Should it simply clamp at 5? Should it not change from its current setting? Or should it shut itself off entirely because its user is clearly a pyromaniac bent on burning down their house? If the specification for our program doesn’t say, it is up to us to decide. Let’s say we expect it to be clamped at 5:
@pytest.mark.parametrize("value", [6, 18, 1000000])
def test_burner_one_should_not_exceed_five(self, value):
stove = Stove()
stove.burner_one = value
assert stove.burner_one == 5, "Burner does not have expected value"Note that we don’t need to exhaustively test all numbers above 5 - it is sufficient to provide a representative sample, ideally the first value past 5 (6), and a few others. Also, now that we have defined our expected behavior, we should make sure the documentation of our burner one property matches it:
@property
def burner_one(self) -> int:
"""Sets the value of Burner One.
Should be an integer between 0 (off) and 5 (high)
If a value higher than 5 is provided, the burner will be
set to 5 instead.
Args:
value: the value of the burner
"""This way, other programmers (and ourselves, if we visit this code years later) will know what the expected behavior is. We’d also want to test the other edge cases: i.e. when the burner is set to a negative number.
For a complete guide to parameterized tests in pyunit, refer to the pyunit Guide.
Recognizing and testing for edge cases is a critical aspect of test writing. But it is also a difficult skill to develop, as we have a tendency to focus on expected values and expected use-cases for our software. But most serious errors occur when values outside these expectations are introduced. Also, remember special values, like float("inf"),, float("-inf"), and float("nan").
Unlike many testing frameworks, the pytest framework by default only uses the built-in assert statement in Python. It doesn’t include a large number of specialized assertions, and instead relies on the developer to write Boolean logic statements to perform the desired testing. More information can be found in the pytest documentation
The pytest framework can leverage the assertions already present in other Python unit testing libraries such as the built-in unittest library. So, for developers familiar with that approach, those assertions can be used.
For this course, we’ll discuss how to use the built-in assert statement, as well as the Hamcrest assertion library.
In general, an assert statement for pytest includes the following structure:
assert <boolean expression>For example, to test if the variable actual is equal to the variable expected, we would write the following assertion:
assert actual == expectedWe can optionally add an error message describing the assertion, as in this example:
assert actual == expected, "The value returned is incorrect"This allows us to provide additional information along with the failure. However, by including a message in this way, it may reduce the amount of information that pytest gives us when the test fails. So, we may find it easier to omit these messages, or include them as comments in the code near the assertion, instead of as part of the assertion itself.
Let’s look at some examples to see how we can use the assert statement in various ways.
assert actual == Trueassert actual == Falseassert acutal == expectedassert actual != expectedassert actual == pytest.approx(expected)assert actual is expected - true if both actual and expected are the same object in memoryassert actual is None - true if actual is the value NoneWhy do we need to deal with approximate floating-point values? This is because floating-point values are by their nature imprecise, and can sometimes lead to strange errors. Consider this example from GeeksforGeeks:
a = 0.7
b = 0.9
x = a + 0.1
y = b - 0.1
print(x)
print(y)
print(x == y)While we would expect both x and y to store the same value, they are actually slightly different.
So, we may need to account for this imprecision in our unit tests. We could also rewrite our code to avoid the use of floating point values. For example, many programs that deal with monetary values actually store them as integers based on cents instead of dollars, and simply add the decimal point only when the value is printed.
The pytest framework also includes a special method that can be used to catch exceptions. This allows us to assert that a particular piece of code being tested should, or should not, throw an exception.
Here’s an example, taken from the pytest documentation:
def test_zero_division():
with pytest.raises(ZeroDivisionError):
calculator.divide(1, 0)The with pytest.raises(ZeroDivisionError) statement is used to assert that the calculator.divide() method will throw an exception, specifically a ZeroDivisionError. If that method call does not throw an exception, then the assertion will fail. We can include multiple lines of code within the with block as well.
pytest includes one other assertion that is used to simply fail a test:
fail(message)By including the fail() method in our unit test, we can cause a test to fail immediately, such as when we reach a state that should be unreachable.
One task we may want to be able to perform in our unit tests is capturing output printed by the program. By default, any output that is printed using print() is immediately sent to the terminal, but we can actually redirect that output without our tests in order to capture it and examine its contents.
We already saw how to do this in the “Hello Real World” project. Here’s that code once again (with full type annotations):
from pytest import CaptureFixture
from _pytest.capture import CaptureResult
from typing import Any
from src.hello.HelloWorld import HelloWorld
def test_hello_world(self, capsys: CaptureFixture[Any]) -> None:
HelloWorld.main(["HelloWorld"])
captured: CaptureResult[Any] = capsys.readouterr()
assert captured.out == "Hello World\n", "Unexpected Output"In that code, we start by adding a parameter named capsys to the test method declaration. capsys is an example of a fixture in pytest. Fixtures allow us to do build more advanced test functions. The capsys fixture is described in the pytest documentation.
So, by including that parameter in our test function, we’ll gain access to all of the features of the capsys fixture. When we execute our code, we can then use capsys.readouterr() to get a CaptureResult object that contains the text that was output by our program. Then, using captured.out, we can check that text and make sure it matches our expectation in an assertion.
We can also choose to use the Hamcrest assertion library in our code, either instead of the pyunit assertions or in addition to them. Hamcrest includes some very helpful assertions that are not part of pyunit, and also includes version for many languages, including both Python and Java. Most of the autograders in previous Computational Core courses are written with the Hamcrest assertion library!
Hamcrest uses a single basic assertion method called assert_that() to perform all assertions. It comes in two basic forms:
assert_that(actual, matcher) - asserts that actual passes the matcher.assert_that(actual, matcher, message) - asserts that actual passes the matcher. If not, it will print message as part of the failure.The real power of Hamcrest lies in the use of Matchers, which are used to determine if the actual value passes a test. If not, then the assert_that method will fail, just like a pyunit assertion.
For example, to test if an actual value returned by a fictional calculator object is equal to an expected value, we could use this statement:
assert_that(calculator.add(1, 3), is_(4))As we can see, reading this statement out loud tells us everything we need to know: “Assert that calculator.add(1, 3) is 4!”
Here are a few of the most commonly used Hamcrest matchers, as listed in the Hamcrest Tutorial. The full list of matchers can be found in the Matcher Library in the Hamcrest documentation:
is_(expected) - a shortcut for equality - an example of syntactic sugar as discussed below. Notice the underscore to differentiate it from the Python keyword isequal_to(expected) - will call the actual.equals(expected) method to test equalityinstance_of(type) - can be used to check if an object is the correct type, helpful for testing inheritancenone() - check if the value is Nonenot_none() - check if the value is not Nonesame_instance(expected) - checks if two objects are the same instancehas_entry(key, value), has_key(key), has_value(value) - matchers for working with mapping types like dictionarieshas_item(item) - matcher for sequence types like listsclose_to(expected, delta) - matcher for testing floating-point values within a rangegreater_than(expected), greater_than_or_equal_to(expected), less_than(expected), less_than_or_equal_to(expected) - numerical matchersequal_to_ignoring_case(expected), equal_to_ignoring_whitespace(expected), contains_string(string), ends_with(string), starts_with(string) - string matchersall_of(matcher1, matcher2, ...), any_of(matcher1, matcher2, ...), is_not(matcher) - boolean logic operators used to combine multiple matchersHamcrest includes a helpful matcher called is_() that makes some assertions more easily readable. For example, each of these assertion statements from the Hamcrest Tutorial all test the same thing:
assert_that(theBiscuit, equal_to(myBiscuit))
assert_that(theBiscuit, is_(equal_to(myBiscuit)))
assert_that(theBiscuit, is_(myBiscuit))By including the is_() matcher, we can make our assertions more readable. We call this syntactic sugar since it doesn’t add anything new to our language structure, but it can help make it more readable.
Once we’ve written our unit tests, we can execute them against our code to see how well it works. Tests are usually run with a test runner, a program that will execute the test code against the code to be tested. The exact mechanism involved depends on the testing framework.
As we discovered in the “Hello Real World” project, both JUnit and pytest have a way to automatically discover all of the tests we’ve created, provided we place them in the correct location and possibly give them the correct name.
Outside of Codio, many integrated development environments, or IDEs, support running unit tests directly through their interface. We won’t cover much of that in this class, but it is handy to know that it can be done graphically as well.
Once the test runner is done executing our tests, we’ll be given information about the tests which failed. We’ve also learned how to create an HTML report that gives us helpful information about our tests and why they failed. So, we can look through that information to determine if our code needs to be updated, or if the test is not testing our code correctly.
Occasionally, you may end up with problems executing your tests. So, as with any development process, it is helpful to work incrementally, and run your tests each time you add or change code. This allows you to catch errors as they happen when the code is fresh in your mind, and it will be that much easier to fix the problem.
It’s also a good idea to run all of your previously passed tests anytime you make a change to your code. This practice is known as regression testing, and can help you identify errors your changes introduce that break what had previously been working code. This is also one of the strongest arguments for writing test code rather than performing ad-hoc testing; automated tests are easy to repeat.
The term test code coverage refers to how much of your program’s code is executed as your tests run. It is a useful metric for evaluating the depth of your test, if not necessarily the quality. Basically, if your code is not executed in the test framework, it is not tested in any way. If it is executed, then at least some tests are looking at it. So aiming for a high code coverage is a good starting point for writing tests.
While test code coverage is a good starting point for evaluating your tests, it is simply a measure of quantity, not quality. It is easily possible for you to have all of your code covered by tests, but still miss errors. You need to carefully consider the edge cases - those unexpected and unanticipated ways your code might end up being used.
Unit testing is a small part of a much larger world of software testing strategies that we can employ in our workflow. On this page, we’ll review some of the more common testing strategies that we may come across.
First, it is important to differentiate between two different approaches to testing. The white box testing approach means that the developer writing the test has full access to the source code, and it is used to verify not just the functionality of a program as it might appear externally, but also that the internal workings of the program are correct.
By having access to the source code, you can take advantage of tools that determine code coverage, and develop tests that are specifically designed to test edge cases or paths found in the code itself.
On the other hand, black box testing means that the tester cannot see the source code of the application itself, and can only test it by calling the publicly available methods, sometimes referred to as the application programming interface or API of the software.
For example, consider testing the code in a library that we didn’t develop. We can access the documentation to see what functions it provides and how they should operate, and we can then write tests that verify those functions. This can be helpful to avoid some of the biases that may be introduced by reading the code itself. We could easily look at a line of code and convince ourselves that it is correct, such that we may not adequately test it’s functionality.
However, because we won’t be able to see the code itself, it can be much harder to test edge cases or unique functionality in the code since we cannot inspect it ourselves. So, we’ll have to be a bit more creative and deliberate in developing our test cases.
Beyond unit testing, many software programs also undergo integration testing, where each individual software component is tested to make sure its interface matches the design specifications, and also that multiple parts of the system work together properly. As programs become larger and larger, it is important to not only test the individual units but the links between those units as well. By creating a well defined interface and performing integration testing, we can ensure that all parts of our program work well together.
We’ve already discussed this a bit. Regression testing involves running our set of tests after a major change in the software, trying to ensure that we didn’t introduce any new bugs or break any working features, causing the software to regress in quality.
This can be really important if we plan on developing a new version of our program that remains compatible with previous versions. In that case, we may end up developing an entirely new suite of tests for our new version, while still using the previous version’s tests as a form of regression testing to ensure compatibility. As the software matures and new versions are released, maintaining backwards compatibility can be a major challenge.
Once the software is complete, a final phase of testing is the acceptance testing, where the software is tested by the eventual end user to confirm that it meets their needs. Acceptance testing could include phases such as alpha testing and beta testing, where incomplete versions of the software are tested by potential users to identify bugs. This is very common today in video game development.
Finally, one important concept in the world of software development is the test-driven development methodology. In contrast to more traditional software development methodologies where the software is developed and then tested, test-driven development requires that software tests be written first, and then the software itself is written to pass the tests. Through this method, if we adequately write our tests to match the requirements of the software, we can be sure that our software actually does what it should if it passes the tests.
This can be quite tricky, since writing tests can be much more complex than writing the actual software, and in some cases it is important to understand how the software itself will be structured before the tests can be effectively written.
For more information about the world of software testing, check out the Software Testing article on Wikipedia, as well as the many articles linked from that page.
In this chapter we learned about testing, both manually using test plans and automatically using a testing framework. We saw how the cost of fixing errors rises exponentially with how long they go undiscovered. We discussed how writing automated tests during the programming phase can help uncover these errors earlier, and how regression testing can help us find new errors introduced while adding to our programs.
We learned a bit more about the testing frameworks we have available to us in our chosen programming language and how to use them. And finally, we discussed some more advanced topics related to software testing.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
A unified way to model your software’s structure!
Much of the content in this chapter was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
As software systems became more complex, it became harder to talk and reason about them. Unified Modeling Language (UML) attempted to correct for this by providing a visual, diagrammatic approach to communicate the structure and function of a program. If a picture is worth a thousand words, a UML diagram might be worth a thousand lines of code.
Some key terms to learn in this chapter are:
The key skill to learn in this chapter is how to draw UML class diagrams for programs we are developing.
Unified Modeling Language (UML) was introduced to create a standardized way of visualizing a software system design. It was developed by Grady Booch, Ivar Jacobson, and James Rumbah at Rational Software in the mid-nineties. It was adopted as a standard by the Object Management Group in 1997, and also by the International Organization for Standardization (ISO) as an approved ISO standard in 2005.
The UML standard actually provides many different kinds of diagrams for describing a software system - both structure and behavior:
The full UML specification is 754 pages long, so there is a lot of information packed into it. For the purposes of this class, we’re focusing on a single kind of diagram - the class diagram.
UML class diagrams are largely composed of boxes - basically a rectangular border containing text. UML class diagrams use boxes to represent units of code - i.e. classes, structs, and enumerations. These boxes are broken into compartments. For example, an Enum is broken into two compartments:

UML is intended to be language-agnostic. But we often find ourselves in situations where we want to convey language-specific ideas, and the UML specification leaves room for this with stereotypes. Stereotypes consist of text enclosed in double less than and greater than symbols. In the example above, we indicate the box represents an enumeration with the <<enum>> stereotype. Another commonly used stereotype is the <<interface>> stereotype that is used with interfaces in Java.
A second basic building block for UML diagrams is a typed element. Typed elements (as you might expect from the name) have a type. Fields and parameters are typed elements, as are method parameters and return values.
The pattern for defining a typed element is:
[visibility] element: type [constraint]The optional [visibility] indicates the visibility of the element, the element is the name of the typed element, and the type is its type, and the [constraint] is an optional constraint.
In UML visibility (based on access modifiers in Java, or the use of underscores in Python) is indicated with symbols, i.e.:
+ indicates public access.- indicates private access.# indicates protected access, which we will discuss in a later chapter.Consider, for example, a private size field. In a Java class, we would do the following:
private int size;Consider, for example, a private size field. In Python, we might have the following assignment in our constructor:
self.__size: int = 0;In a UML diagram, that field would be expressed as:
- size: intA typed element can include a constraint indicating some restriction for the element. The constraints are contained in a pair of curly braces after the typed element, and follow the pattern:
{element: boolean expression}For example:
- age: int {age: >= 0}indicates the private variable age must be greater than or equal to 0.
In a UML class diagram, individual classes are represented with a box divided into three compartments, each of which is for displaying specific information:

The first compartment identifies the class - it contains the name of the class. The second compartment holds the attributes of the class (the fields and properties). And the third compartment holds the operations of the class (the methods) of the class.
In the diagram above, we can see the Fruit class modeled on the right side.
UML is a very flexible tool, but it can become difficult to create UML diagrams that accurately reflect the differences between programming languages. So, different developers might implement the same UML class diagram in slightly different ways.
For example, in Java we would use a boolean data type to represent a Boolean value, whereas Python uses the bool type. Likewise, Java also includes a class called Boolean that is an object wrapper around a primitive boolean variable, allowing it to be used in various Java collections. Additionally, some other languages do not include a Boolean data type at all, and instead use a small integer with 0 representing true and other values representing false.
In prior CC courses, it was important for the software to exactly match the specification so that our autograders would work. In that case, we provided UML diagrams that were somewhat unique to each programming language. For this course, we will create UML diagrams that are a bit more generalized.
In the descriptions below, we’ll include discussions of ways to properly represent each UML element for each language, but it may allow for some flexibility. In general, as long a similarly experienced developer can follow the UML diagram and/or the source code and correlate the two, we will consider that good enough.
The attributes in UML represent the state of an object. For most object-oriented languages, this would correspond to the fields and properties of the class.
We indicate fields in our UML diagram with a typed element. So, to create a private Boolean variable named blended, we would include the following:
- blended: boolean- blended: boolFor Python, we may also choose to include the underscores in front of the name to show that it should be treated as a private attribute, as implied by the - at the start of the element:
- __blended: boolHowever, this can make the UML a bit more difficult to read, so we generally won’t do this in the UML diagrams in this course.
Java and Python handle accessor methods differently, and they can be denoted in UML in many different ways.
A general solution would be to include a stereotype after the element, indicating if a public getter or setter should be created for that element. So, to create a getter and a setter for our blended attribute, we could do the following:
- blended: boolean <<get,set>>- blended: bool <<get,set>>Of course, each language would handle this a bit differently. In Java, we would create public getBlended() and setBlended(boolean) methods in our class. In Python, we would use the @property and @blended.setter decorators to create a Python property. While all of those are technically methods, they are really meant to implement the functionality of an attribute, so we’ll treat them as part of the attribute in UML.
What if our accessors implement unique functionality, or we want one of them to be protected instead of public? In those cases, we may want to include the explicit accessor methods as operations as described below. However, in general, it is best practice to make our UML as concise as possible, so we generally don’t list accessor methods directly unless there is a good reason to do so.
The operations in UML represent the behavior of the object, i.e. the methods we can invoke upon it. These are declared using the pattern:
visibility name([parameter list])[:return type]The [visibility] portion uses the same symbols as typed elements, with the same correspondences. The name is the name of the method, and the [parameter list] is a comma-separated list of typed elements, corresponding to the parameters of the method. The [:return type] indicates the return type for the method. That portion can be omitted if the method doesn’t explicitly return a value (void in Java or None in Python).
Thus, in the example above, the protected method Blend has no parameters and returns a string.
Consider a method that adds together two integers and returns the result. The examples below show how the method’s signature corresponds to its UML element.
public int add(int a, int b){
return a + b;
}def add(a: int, b: int) -> int:
return a + b+ add(a: int, b: int): intIn UML, we indicate a class is static by underlining its name in the first compartment of the class diagram. We can similarly indicate operations and methods are static by underlining the entire line referring to them.
To indicate a class is abstract, we italicize its name. Abstract methods are also indicated by italicizing the entire line referring to them.
We’ll talk more about some of these concepts in a later chapter.
Class diagrams also express the associations between classes by drawing lines between the boxes representing them.

There are two basic types of associations we model with UML: has-a and is-a associations. We break these into two further categories, based on the strength of the association, which is either strong or weak. These associations are:
| Association Name | Association Type | Typical Usage |
|---|---|---|
| Realization | weak is-a | Interfaces |
| Generalization | strong is-a | Inheritance |
| Aggregation | weak has-a | Collections |
| Composition | strong has-a | Encapsulation |
Is-a associations indicate a relationship where one class is a instance of another class. Thus, these associations represent polymorphism, where a class can be treated as another class, i.e. it has both its own, and the associated classes’ types.
Realization refers to making an interface “real” by implementing the methods it defines. An interface is a special type of abstract class that only includes abstract methods. In effect, it is creating an defined list of operations, or an interface (or API), that subclasses must include so that they can all be used in the same way. For Java, this corresponds to a class that implements an interface. The Python language doesn’t have interfaces, but we’ll learn how to create something similar using abstract classes. We call this a is-a relationship, because the class can be treated as being the same data type of the interface class. It is also a weak relationship as the same interface can be implemented by otherwise unrelated classes. In UML, realization is indicated by a dashed arrow in the direction of implementation:

Generalization refers to extracting the shared parts from different classes to make a general base class of what they have in common. For Java and Python, this corresponds to inheritance. We call this a strong is-a relationship, because the class has all the same state and behavior as the base class. In UML, realization is indicated by a solid arrow in the direction of inheritance:

Also notice that we show that Fruit and its blend() method are abstract by italicizing them. The association tells us that the Banana class is a Fruit.
Has-a associations indicates that a class holds one or more references to instances of another class. In Java or Python, this corresponds to having a variable or collection with the type of the associated class. This is true for both kinds of has-a associations. The difference between the two is how strong the association is.
Aggregation refers to collecting references to other classes. As the aggregating class has references to the other classes, we call this a has-a relationship. It is considered weak because the aggregated classes are only collected by the aggregating class, and can exist on their own. It is indicated in UML by a solid line from the aggregating class to the one it aggregates, with an open diamond “fletching” on the opposite site of the arrow (the arrowhead is optional).

Composition refers to assembling a class from other classes, “composing” it. As the composed class has references to the other classes, we call this a has-a relationship. However, the composing class typically creates the instances of the classes composing it, and they are likewise destroyed when the composing class is destroyed. For this reason, we call it a strong relationship. It is indicated in UML by a solid line from the composing class to those it is composed of, with a solid diamond “fletching” on the opposite side of the arrow (the arrowhead is optional).

Aggregation and composition are commonly confused, especially given they both are defined by holding a variable or collection of another class type. Here’s a helpful analogy to explain the difference, based on the diagrams listed above:
Aggregation is like a shopping cart. When you go shopping, you place groceries into the shopping cart, and it holds them as you push it around the store. Thus, a ShoppingCart class might have a List<Grocery> named items, and you would add the items to it. When you reach the checkout, you would then take the items back out. The individual Grocery objects existed before they were aggregated by the ShoppingCart, and also after they were removed from it. The ShoppingCart class just keeps track of them.
In contrast, composition is like an organism. Say we create a class representing a Dog. It might be composed of classes like Tongue, Ear, Leg, and Tail. We would probably construct these parts in the Dog class’s constructor, and when we dispose of the Dog object, we wouldn’t expect these component classes to stick around. So, they are inherently a part of the encapsulating class.
Additionally, sometimes the attributes containing these external items may be omitted from the UML diagram of the composing or aggregating class. This is mainly because the existence of those attributes can be inferred by the relationships themselves. However, in this course, we will include the relevant attributes in the encapsulating class, as well as the association arrows, in our UML diagrams
With aggregation and composition, we may also place numbers on either end of the association, indicating the number of objects involved. We call these numbers the multiplicity of the association.
For example, the Frog class in the composition example has two instances of front and rear legs, so we indicate that each Frog instance (by a 1 on the Frog side of the association) has exactly two (by the 2 on the leg side of the association) legs. The tongue has a 1 to 1 multiplicity as each frog has one tongue.
Multiplicities can also be represented as a range (indicated by the start and end of the range separated by ..). We see this in the ShoppingCart example above, where the count of GroceryItems in the cart ranges from 0 to infinity (infinity is indicated by an asterisk *).
Generalization and realization are always one-to-one multiplicities, so multiplicities are typically omitted for these associations.
There are many tools available to help you develop your own UML diagrams. Here are a few that we recommend using for this course.
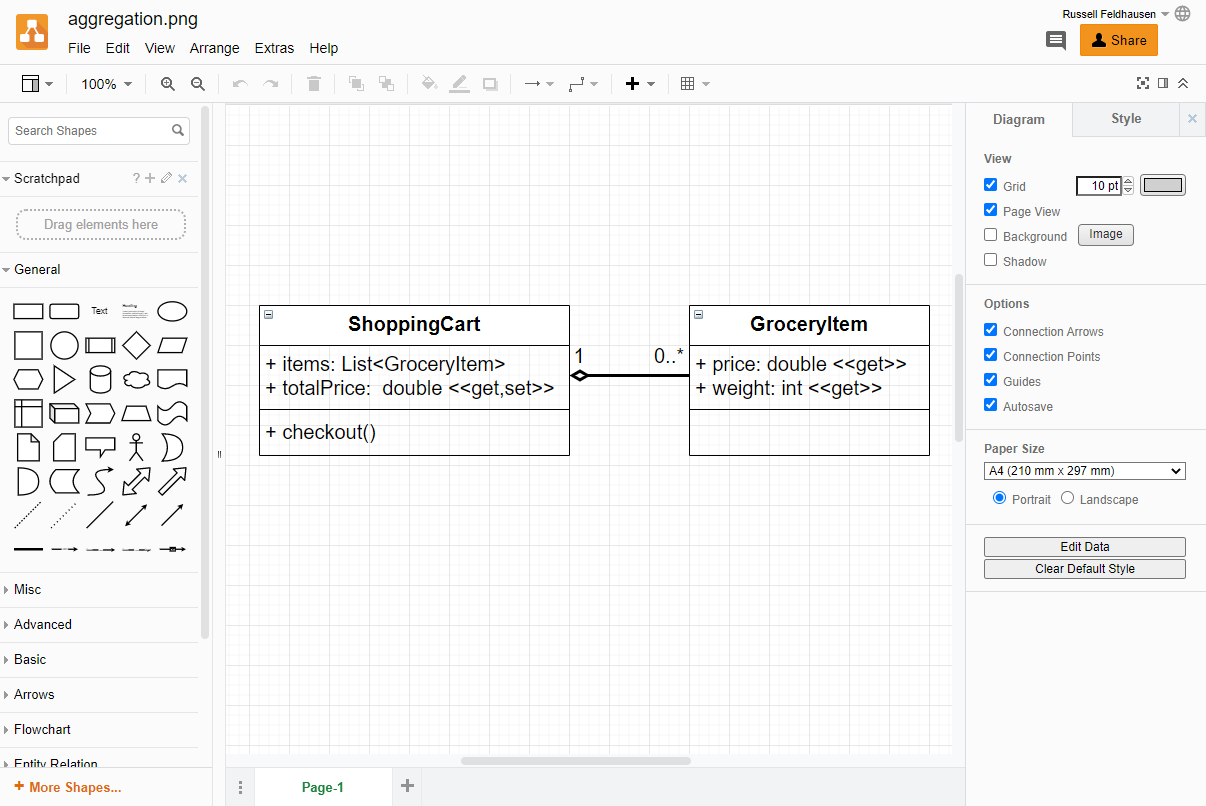
Most of the graphics used in the Computational Core program, including the UML diagrams in this and previous courses, are made using the free Diagrams.net tool.
When creating a new diagram, you can select the UML Diagram template to get started. The interface is really simple and easy to use, with lots of drag-and-drop components you can add to your diagram.
To create multiplicities, you can simply add text boxes to your arrows.
To export a diagram, click the File menu and choose the Export To option. You can create both PNG and SVG files!
One great feature of Diagrams.net is the ability to embed the diagram data directly into an image file exported from the application. In that way, we only have to have access to the image in order to open the diagram and update the image.
Try it yourself! Right-click on a UML diagram in this book to download it as an image, and then open the image using the upload option in Diagrams.net. You should be able to edit the diagram!
Another tool we can use to create UML diagrams is Microsoft Visio. For Kansas State University Computer Science students, this can be downloaded through your Azure Student Portal.
Visio is a vector graphics editor for creating flowcharts and diagrams. it comes preloaded with a UML class diagram template, which can be selected when creating a new file:
Class diagrams are built by dragging shapes from the shape toolbox onto the drawing surface. Notice that the shapes include classes, interfaces, enumerations, and all the associations we have discussed. Once in the drawing surface, these can be resized and edited.
Right-clicking on an association will open a context menu, allowing you to turn on multiplicities. These can be edited by double-clicking on them. Unneeded multiplicities can be deleted.
To export a Visio project in PDF or other form, choose the “Export” option from the file menu.
Let’s work through an example of creating a UML class diagram based on existing code. This is loosely based off a project from an earlier course, so some of the structure may be familiar.
This project is a number calculator that makes use of object-oriented concepts such as inheritance, interfaces, and polymorphism to represent different types of numbers using different classes. We’ll also follow the Model-View-Controller (MVC) architectural pattern.
We’ll start by looking at the Number interface, which is the basis of all of the number classes. We’re omitting the method code in these examples, since we are only concerned with the overall structure of the classes themselves.
public interface Number {
Number add(Number n);
Number subtract(Number n);
Number multiply(Number n);
Number divide(Number n);
}class Number(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass: type) -> bool:
@abc.abstractmethod
def add(self, n: Number) -> Number:
@abc.abstractmethod
def subtract(self, n: Number) -> Number:
@abc.abstractmethod
def multiply(self, n: Number) -> Number:
@abc.abstractmethod
def divide(self, n: Number) -> Number:In UML, we’d represent this interface using the following box. It includes the <<interface>> stereotype, as well as the listed methods shown in italics since they are all abstract. Finally, each method in an interface is assumed to be public, so we’ll include a plus symbol + in front of each method.

Next is the class for representing real numbers. This class will be a realization of the Number interface, as we can see in the code:
public class RealNumber implements Number {
private double value;
public RealNumber(double value){ }
public Number add(Number n){ }
public Number subtract(Number n){ }
public Number multiply(Number n){ }
public Number divide(Number n){ }
@Override
public String toString(){ }
@Override
public boolean equals(Object o){ }
}class RealNumber(Number):
def __init__(self, value: float) -> None:
self.__value = value
def add(self, n: Number) -> Number:
def subtract(self, n: Number) -> Number:
def multiply(self, n: Number) -> Number:
def divide(self, n: Number) -> Number:
def __str__(self) -> str:
def __eq__(self, o: object) -> bool:it also includes implementations for a couple of other methods beyond the interface, including a constructor. So, in our UML diagram, we’ll add another box to represent that class, and use the realization association arrow to show the connection between the classes. Remember that the arrow itself points toward the interface or parent class.

From here, it’s pretty easy to see how we can use inheritance to create a RationalNumber class and an IntegerNumber class. The only way that they differ from the RealNumber class are the attributes. So, we’ll quickly add those to our UML diagram as well.

At this point, we can add a new class to represent complex numbers. A complex number consists of two parts - a real part and an imaginary part. So, it will both implement the Number interface, but it will also be composed of two RealNumber attributes. Notice that we’re using RealNumber as the attribute instead of the Number interface. This is because we don’t want a complex number to contain a complex number, so we’re being careful about our inheritance. In code, this class would look like this:
public class ComplexNumber implements Number {
private RealNumber real;
private RealNumber imaginary;
public ComplexNumber(RealNumber real, RealNumber imaginary){ }
public Number add(Number n){ }
public Number subtract(Number n){ }
public Number multiply(Number n){ }
public Number divide(Number n){ }
@Override
public String toString(){ }
@Override
public boolean equals(Object o){ }
}class ComplexNumber(Number):
def __init__(self, real: RealNumber, imaginary: RealNumber) -> None:
self.__real = real
self.__imaginary = imaginary
def add(self, n: Number) -> Number:
def subtract(self, n: Number) -> Number:
def multiply(self, n: Number) -> Number:
def divide(self, n: Number) -> Number:
def __str__(self) -> str:
def __eq__(self, o: object) -> bool:In our UML diagram, we’ll add a box for this class. We’ll also add both a realization association to the Number interface, but also a composition association to the RealNumber class, complete with the cardinality of the relationship.

Once we’ve created all of our number classes, we can quickly create our View and Controller classes as well. They will handle getting input from the user, performing operations, and displaying the results.
public class View {
public View(){ }
public void show(Number n){ }
public String input(){ }
}
public class Controller {
private List<Number> numbers;
private View view;
public Controller(){ }
public void build(){ }
public void sum(){ }
public static void main(String[] args){ }
}class View:
def __init__(self) -> None:
def show(self, n: Number) -> None:
def input(self) -> str:
class Controller:
def __init__(self) -> None:
self.__numbers: List[Number] = list()
self.__view: View = View()
def build(self) -> None:
def sum(self) -> None:
@classmethod
def main(self, args: List[str]) -> None:In the code, we see that the Controller class contains an attribute for a single View() instance, and also a list of Number instances. So, we’ll end up using a composition association between Controller and View, and an aggregation association between Controller and the Number interface.

This is a small example, but it demonstrates many of the important object-oriented concepts in a single UML diagram:
Number class is an interface and abstract classRealNumber implements the Number class through a realization associationRationalNumber and IntegerNumber show direct inheritance through a generalization associationImaginaryNumber contains two RealNumber instances, showing the composition association and a multiplicity of 2.Controller, View and Number classes make up the various parts of an MVC architecture.Controller stores a list of Number instances, demonstrating the aggregation association.Controller also contains a single View instance, which is another composittion association with multiplicity of 1.UML is a very broad topic to cover in a single module, let alone a single class. For more information on building and reading UML diagrams, refer to these sources:
There are also many textbooks devoted to teaching UML concepts, as well as lots of examples online to learn from. The O’Reilly subscription through the K-State Libraries offers several books to choose from that can be accessed for free through this link:
In this section, we learned about UML class diagrams, a language-agnostic approach to visualizing the structure of an object-oriented software system. We saw how individual classes are represented by boxes divided into three compartments; the first for the identity of the class, the second for its attributes, and the third for its operators. We learned that italics are used to indicate abstract classes and operators, and underlining static classes, attributes, and operators.
We also saw how associations between classes can be represented by arrows with specific characteristics, and examined four of these in detail: aggregation, composition, generalization, and realization. We also learned how multiplicities can show the number of instances involved in these associations.
Finally, we saw how classes, interfaces, and enumerations are modeled using UML. We saw how the stereotype can be used to indicate language-specific features like properties. We also looked at creating UML class diagrams using Diagrams.net and Microsoft Visio.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
Like superclass, like subclass! Now, with interfaces!
Much of the content in this chapter was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
The term polymorphism means many forms. In computer science, it refers to the ability of a single symbol (i.e. a function or class name) to represent multiple types. Some form of polymorphism can be found in nearly all programming languages.
While encapsulation of state and behavior into objects is the most central theoretical idea of object-oriented languages, polymorphism - specifically in the form of inheritance - is a close second. In this chapter we’ll look at how polymorphism is commonly implemented in object-oriented languages.
Some key terms to learn in this chapter are:
Before we can discuss polymorphism in detail, we must first understand the concept of types. In computer science, a type is a way of categorizing a variable by its storage strategy, i.e., how it is represented in the computer’s memory. It also defines how the value can be treated and what operations can be performed on it.
You’ve already used types extensively in your programming up to this point. Consider the declaration:
int number = 5;number: int = 5The variable number is declared to have the type int. In Java, the type included in the declaration tells the Java compiler that the value of the number will be stored using a specific scheme for integer values. For Python, the type is implied by the value itself - since 5 is a whole number, it is treated like an integer. The type annotation int is used by Mypy for type checking, but us ignored by the Python interpreter itself.
Each language stores these values in memory differently, and we won’t worry about those technical differences in this course. What is important to remember is that the variable’s data type tells the computer how to store that value, and also what operations can be performed on that value.
For example, consider the following code:
int x = 5;
int y = 7;
String string = " apples";
System.out.println(x + y); // 12
System.out.prinltn(x + string); // 5 applesx: int = 5
y: int = 7
string: str = " apples"
print(x + y) # 12
print(x + string) # TypeErrorConsider the last two lines of each example - we are using the plus + operator between two different variables. In the first case, the two operands x and y are both integers. So, the computer will know that the plus operator should be treated like addition, and it will add those two integer values together.
In the second case, one operand x is an integer, but the other operand string is a string value. What should happen in that case? As it turns out, each language does this a bit differently. In Java, the plus operator can also be used for concatenation, so the result will be 5 apples. Python, however, will raise a TypeError since it doesn’t know what the plus operator means when applied to a string and an integer.
In either case, our computer is able to use the data type assigned to each variable to determine how it should be treated and what operations it can perform.
In addition to built-in types, most programming languages support user-defined types, that is, new types defined by the programmer. For example, we could define an enumerator called Grade:
public enum Grade {
A,
B,
C,
D,
F;
}from enum import Enum
class Grade(Enum):
A = 1
B = 2
C = 3
D = 4
F = 5This defines a new data type Grade. We can then create variables with that type:
Grade courseGrade = Grade.A;course_grade: Grade = Grade.AIn an object-oriented programming language, a class also defines a new type! As we discussed in an earlier chapter, a class defines the structure for the state for objects implementing that type. Consider a class named Student as shown in this example:
public class Student {
private int creditPoints;
private int creditHours;
private String first;
private String last;
// accessor methods for first and last omitted
public Student(String first, String last) {
this.first = first;
this.last = last;
}
/**
* Gets the student's grade point average.
*/
public double getGPA() {
return ((double) creditPoints) / creditHours;
}
/**
* Records a final grade for a course taken by this student.
*
* @param grade the grade earned by the student
* @param hours the number of credit hours in the course
*/
public void addCourseGrade(Grade grade, int hours) {
this.creditHours += hours;
switch(grade) {
case A:
this.creditPoints += 4 * hours;
break;
case B:
this.creditPoints += 3 * hours;
break;
case C:
this.creditPoints += 2 * hours;
break;
case D:
this.creditPoints += 1 * hours;
break;
case F:
this.creditPoints += 0 * hours;
break;
}
}
}class Student:
def __init__(self, first: str, last: str) -> None:
self.__first: str = first
self.__last: str = last
self.__credit_points: int = 0
self.__credit_hours: int = 0
# properties for first and last omitted
@property
def gpa(self) -> float:
"""Gets the student's grade point average.
"""
return self.__credit_points / self.__credit_hours
def add_course_grade(self, grade: Grade, hours: int) -> None:
"""Records a final grade for a course taken by this student.
Args
grade: the grade earned by the student
hours: the number of credit hours in the course
"""
self.__credit_hours += hours
if grade == Grade.A:
self.__credit_points += 4 * hours
elif grade == Grade.B:
self.__credit_points += 3 * hours
elif grade == Grade.C:
self.__credit_points += 2 * hours
elif grade == Grade.D:
self.__credit_points += 1 * hours
elif grade == Grade.F:
self.__credit_points += 0 * hoursIf we want to create a new student, we would create an instance of the class Student which is an object of type Student:
Student willie = new Student("Willie", "Wildcat");willie: Student = Student("Willie", "Wildcat")Hence, the type of an object is the class it is an instance of. This is a staple across all object-oriented languages.
A final note on types. You may hear languages being referred to as statically or dynamically typed. A statically typed language is one where the type is set by the code itself, either explicitly like Java:
int foo = 5;or implicitly, where the compiler or interpreter determines the type based on the value, as in this statement from C# using the special var type:
var bar = 6;In a statically typed language, a variable cannot be assigned a value of a different type, i.e.:
foo = 8.3;Will fail with an error in Java, as a floating point value is a different type than an integer. However, we can cast the value to a new type (changing how it is represented), i.e.:
int x = (int)8.9;x: int = int(8.9)For this to work, the language must know how to perform the cast. The cast may also lose some information - in the above example, the resulting value of x is 8 (the fractional part is discarded).
In contrast, in a dynamically typed language the type of the variable changes when a value of a different type is assigned to it. For example, in Python, this expression is legal:
a = 5
a = "foo"and the type of a changes from an integer (at the first assignment) to string (at the second assignment).
C#, Java, C, C++, and Kotlin are all statically typed languages, while Python, JavaScript, and Ruby are dynamically typed languages.
If we think back to the concept of message passing in object-oriented languages, it can be useful to think of the collection of public methods available in a class as an interface, i.e., a list of messages you can dispatch to an object created from that class. When you were first learning a language (and probably even now), you find yourself referring to these kinds of lists, usually in the language’s documentation:

Essentially, programmers use these interfaces to determine what methods can be invoked on an object. In other words, which messages can be passed to the object. This interface is determined by the class definition, specifically what methods it contains.
In dynamically typed programming languages, like Python, JavaScript, and Ruby, if two classes accept the same message, you can treat them interchangeably, i.e. if the Kangaroo class and Car class both define a jump() method, you could populate a list with both, and call the jump() method on each:
jumpables = [new Kangaroo(), new Car(), new Kangaroo()]
for jumper in jumpables:
jumper.jump()This is sometimes called duck typing, from the sense that “if it walks like a duck, and quacks like a duck, it might as well be a duck.”
However, for statically typed languages we must explicitly indicate that two types both possess the same message definition, by making the interface explicit. We do this by declaring an interface class, which is a special type of class. For example, an interface for classes that possess a parameter-less jump method might look like this in Java:
interface IJumpable {
void jump();
}In some languages, it is common practice to preface Interface names with the character I. The interface declaration defines an interface - the shape of the messages that can be passed to an object implementing the interface - in the form of a method signature. Note that this signature does not include a body, but instead ends in a semicolon (;). An interface simply indicates the message to be sent, not the behavior it will cause! We can specify as many methods in an interface declaration as we want.
On a later page, we’ll discuss how to create a similar structure in Python, which defines the methods that must be implemented by any class that inherits from our interface class. For now, we’ll discuss how interfaces are traditionally implemented in most other object-oriented languages such as Java.
Also note that the method signatures in an interface declaration do not have access modifiers. This is because the whole purpose of defining an interface is to signify methods that can be used by other code. In other words, public access is implied by including the method signature in the interface declaration. In addition, because the methods do not have implementations, they are also abstract as well.
This interface can then be implemented by other classes, usually by listing the interfaces as part of the class declaration. In most languages, a class may implement multiple interfaces. When a class implements an interface, it must define public methods with signatures that match those that were specified by the interface(s) it implements. Here’s an example of a couple of classes implementing the IJumpable interface in Java:
public class Kangaroo implements IJumpable {
public void jump() {
// implement method to jump over a fence here
}
}public class Car implements IJumpable {
public void jump() {
// implement method to jumpstart a car here
}
public void start() {
// implement method to normally start a car here
}
}We can then treat these two disparate classes as though they shared the same type, defined by the IJumpable interface:
List<IJumpable> jumpables = new LinkedList<>();
jumpables.add(new Kangaroo());
jumpables.add(new Car());
jumpables.add(new Kangaroo());
for(IJumpable jumper : jumpables) {
jumper.jump();
}Note that while we are treating the Kangaroo and Car instances as IJumpable instances, we can only invoke the methods defined in the IJumpable interface, even if these objects have other methods. Essentially, the interface represents a new type that can be shared amongst disparate objects in a statically-typed language. The interface definition serves to assure the static type checker that the objects implementing it can be treated as this new type - i.e. the interface provides a mechanism for implementing polymorphism.
We often describe the relationship between the interface and the class that implements it as a is-a relationship, i.e. a Kangaroo is a IJumpable (i.e. a Kangaroo is a thing that can jump). We further distinguish this from a related polymorphic mechanism, inheritance, by the strength of the relationship. We consider interfaces weak is-a connections, as other than the shared interface, a Kangaroo and a Car don’t have much to do with one another.
In Java, like most other object-oriented languages, a class can implement as many interfaces as we want, they just need to be separated by commas, i.e.:
public class Frog implements IJumpable, ICroakable, ICatchFlies {
// method here
}On the next few pages, we’ll look at how to implement interfaces more explicitly in both Java and Python. As always, feel free to read the page for the language you are studying, but it might be useful to review the other page as well. Then, we’ll look at inheritance, which represents a strong is-a relationship.
The Java programming language includes direct support for the creation of interfaces via the interface keyword. We’ve already seen one example of an interface created in Java, but let’s look at another example and dissect it a bit.
Here is a simple interface for a set of classes that are based on the Collection interface in Java 8:
public interface IMyCollection {
int size();
boolean isEmpty();
boolean add(Object o);
boolean remove(int i);
Object get(int i);
boolean contains(Object o);
}You may also review the full Collection interface source code from the OpenJDK library.
Here’s another example interface in Java for a Stack:
public interface IMyStack {
void push(Object o);
Object pop();
Object peek();
}When creating an interface in Java, there are a few things to keep in mind:
class keyword, we use the interface keyword in our declaration.public and abstract. We do not have to include those keywords in the method declaration.public, static, and final. They are generally used for constants.abstract class.{}, they end with a semicolon ;.Once we’ve created an interface, we can then create a class that implements that interface. Any class that implements an interface must provide an implementation for all methods defined in the interface.
For example, we can create a MyList class that implements the IMyCollection interface defined above, as shown in this example:
public class MyList implements IMyCollection {
private Object[] list;
private int size;
public List() {
this.list = new Object[10];
this.size = 0;
}
public int size() {
return this.size;
}
public boolean isEmpty() {
return this.size == 0;
}
public boolean add(Object o) {
if (this.size < 10) {
this.list[this.size++] = o;
return true;
}
return false;
}
public boolean remove(int i) {
if (i < 10) {
this.list[i] = this.list[9];
this.list[9] = null;
size--;
return true;
}
return false;
}
public Object get(int i) {
return this.list[i];
}
public boolean contains(Object o) {
for (Object obj : this.list) {
if (obj.equals(o)) {
return true;
}
}
return false;
}
}Notice that we use the implements keyword as part of the class declaration to list the interface that we are implementing in this class. Then, in the class, we include implementations for each method defined in the IMyCollection interface. Those implementations are simple and full of bugs, but they give us a good idea of what an implementation of an interface could look like. We can also include attributes and a constructor, as well as additional methods as needed.
One of the biggest benefits of using interfaces in Java is the ability to create a class that implements multiple interfaces. This is a special case of inheritance called multiple inheritance. Any class that implements multiple interfaces must provide an implementation for every method defined in each of the interfaces it implements.
For example, we can create a special MyListStack class that implements both the IMyCollection and IMyStack interfaces we defined above:
public class MyListStack implements IMyCollection, IMyStack {
// include all of the code from the MyList class
public void push(Object o) {
this.add(o);
}
public Object pop() {
Object out = this.list[this.size - 1];
this.remove(this.size - 1);
return out;
}
public Object peek(){
return this.list[this.size - 1];
}
}To implement multiple interfaces, we can simply list them following the implements keyword, separated by a comma.
Finally, recall from the previous page that we can treat any interface as a data type, so we can store classes that implement the same interface together. Here’s an example:
IMyCollection[] collects = new IMyCollection[2];
collects[0] = new MyList();
collects[1] = new MyListStack();
collects[0].add("String");
collects[1].add("Hello");However, it is important to remember that, even though the second element in the collects array is an instance of the MyListStack class, we cannot access the push and pop methods directly. This is because the collects array is using the IMyCollection data type. So, we only have access to methods that are defined in that interface. Put another way, we’ve told the Java compiler that those objects can only accept those messages.
If we want to treat that item as an instance of the MyListStack class, we can cast it to the correct type.
if (collects[1] instanceof MyListStack) {
((MyListStack) collects[1]).push("World");
}In Java, we can use the instanceof operator to determine if a particular object is an instance of a particular class or data type. If so, we can then cast it by placing the desired data type in parentheses before the variable we’d like to cast. In this example, we see that we can then wrap that in another set of parentheses and then access the methods or attributes of the desired type.
In an object-oriented language, inheritance is a mechanism for deriving part of a class definition from another existing class definition. This allows the programmer to “share” code between classes, reducing the amount of code that must be written.
Consider the Student class we created earlier:
public class Student {
private int creditPoints;
private int creditHours;
private String first;
private String last;
// accessor methods for first and last omitted
public Student(String first, String last) {
this.first = first;
this.last = last;
}
/**
* Gets the student's grade point average.
*/
public double getGPA() {
return ((double) creditPoints) / creditHours;
}
/**
* Records a final grade for a course taken by this student.
*
* @param grade the grade earned by the student
* @param hours the number of credit hours in the course
*/
public void addCourseGrade(Grade grade, int hours) {
this.creditHours += hours;
switch(grade) {
case A:
this.creditPoints += 4 * hours;
break;
case B:
this.creditPoints += 3 * hours;
break;
case C:
this.creditPoints += 2 * hours;
break;
case D:
this.creditPoints += 1 * hours;
break;
case F:
this.creditPoints += 0 * hours;
break;
}
}
}This would work well for representing a student. But what if we are representing multiple kinds of students, like undergraduate and graduate students? We’d need separate classes for each, but both would still have names and calculate their GPA the same way. So, it would be handy if we could say “an undergraduate is a student, and has all the properties and methods a student has” and “a graduate student is a student, and has all the properties and methods a student has.” This is exactly what inheritance does for us, and we often describe it as an is-a relationship. We distinguish this from the interface mechanism we looked at earlier by saying it is a strong is-a relationship, as an Undergraduate student is, for all purposes, also a Student.
Let’s define an undergraduate student class:
public class UndergraduateStudent extends Student {
public UndergraduateStudent(String first, String last) {
super(first, last);
}
}In Java, we use the extends keyword to declare that a class is inheriting from another class. So, public class UndergraduateStudent extends Student indicates that UndergraduateStudent inherits from (is a) Student. Thus, it has the attributes first and last that are inherited from Student. Similarly, it inherits the getGPA() and addCourseGrade() methods.
In fact, the only method we need to define in our UndergraduateStudent class is the constructor - and we only need to define this because the base class has a defined constructor taking two parameters, first and last names. This Student constructor must be invoked by the UndergraduateStudent constructor - that’s what the super(first, last) line does - it invokes the Student constructor with the first and last parameters passed into the UndergraduateStudent constructor. In Java, the super() method call must be the first line in the child class’s constructor. It can be omitted if the parent class includes a default (parameter-less) constructor.
Let’s define a GraduateStudent class as well. This will look much like an UndergraduateStudent, but all graduates have a bachelor’s degree:
public class GraduateStudent extends Student {
private String bachelorDegree;
public GraduateStudent(String first, String last, String degree) {
super(first, last);
this.bachelorDegree = degree;
}
public String getBachelorDegree() {
return this.bachelorDegree;
}
}Here we added a property for bachelorDegree. Since the attribute itself is marked as private, it can only be written to by the class, as is done in the constructor. To the outside world, it is treated as read-only through the getter method.
Thus, the GraduateStudent has all the state and behavior encapsulated in Student, plus the additional state of the bachelor’s degree title.
protected KeywordWhat you might not expect is that any fields declared private in the base class are inaccessible in the derived class. Thus, the private fields creditPoints and creditHours cannot be used in a method defined in GraduateStudent. This is again part of the encapsulation and data hiding ideals - we’ve encapsulated and hid those variables within the base class, and any code outside that assembly, even in a derived class, is not allowed to mess with it.
However, we often will want to allow access to such variables in a derived class. Java uses the access modifier protected to allow for this access in derived classes, but not the wider world.
In UML, protected attributes are denoted by a hash symbol # as the visibility of the attribute.
What happens when we construct an instance of GraduateStudent? First, we invoke the constructor of the GraduateStudent class:
GraduateStudent gradStudent = new GraduateStudent("Willie", "Wildcat", "Computer Science");This constructor then invokes the constructor of the base class, Student, with the arguments "Willie" and "Wildcat". Thus, we allocate space to hold the state of a student, and populate it with the values set by the constructor. Finally, execution returns to the super class of GraduateStudent, which allocates the additional memory for the reference to the BachelorDegree property. Thus, the memory space of the GraduateStudent contains an instance of the Student, somewhat like nesting dolls.
Because of this, we can treat a GraduateStudent object as a Student object. For example, we can store it in a list of type Student, along with UndergraduateStudent objects:
List<Student> students = new LinkedList<>();
students.Add(gradStudent);
students.Add(new UndergraduateStudent("Dorothy", "Gale"));Because of their relationship through inheritance, both GraduateStudent class instances and UndergraduateStudent class instances are considered to be of type Student, as well as their supertypes.
We can go as deep as we like with inheritance - each base type can be a superclass of another base type, and has all the state and behavior of all the inherited base classes.
This said, having too many levels of inheritance can make it difficult to reason about an object. In practice, a good guideline is to limit nested inheritance to two or three levels of depth.
If we have a base class that only exists to be inherited from (like our Student class in the example), we can mark it as abstract with the abstract keyword. An abstract class cannot be instantiated (that is, we cannot create an instance of it using the new keyword). It can still define fields and methods, but you can’t construct it. If we were to re-write our Student class as an abstract class:
public abstract class Student {
private int creditPoints;
private int creditHours;
protected String first;
protected String last;
// accessor methods for first and last omitted
public Student(String first, String last) {
this.first = first;
this.last = last;
}
/**
* Gets the student's grade point average.
*/
public double getGPA() {
return ((double) creditPoints) / creditHours;
}
/**
* Records a final grade for a course taken by this student.
*
* @param grade the grade earned by the student
* @param hours the number of credit hours in the course
*/
public void addCourseGrade(Grade grade, int hours) {
this.creditHours += hours;
switch(grade) {
case A:
this.creditPoints += 4 * hours;
break;
case B:
this.creditPoints += 3 * hours;
break;
case C:
this.creditPoints += 2 * hours;
break;
case D:
this.creditPoints += 1 * hours;
break;
case F:
this.creditPoints += 0 * hours;
break;
}
}
}Now with Student as an abstract class, attempting to create a Student instance:
Student theWiz = new Student("Wizard", "Oz");would fail with an exception. However, we can still create instances of the derived classes GraduateStudent and UndergraduateStudent, and treat them as Student instances. It is best practice to make any class that serves only as a base class for derived classes and will never be created directly an abstract class.
Some programming languages, such as C#, include a special keyword sealed that can be added to a class declaration. A sealed class is not inheritable, so no other classes can extend it. This further adds security to the programming model by preventing developers from even creating their own version of that class that would be compatible with the original version.
This is currently a proposed feature for Java version 15. The full details of that proposed feature are described in the Java Language Updates from Oracle.
Since we are focusing on learning Java that is compatible with Java 8, we won’t have access to that feature.
A class can use both inheritance and interfaces. In Java, a class can only inherit one base class, and it should always be listed first after the extends keyword. Following that, we can have as many interfaces as we want listed after the implements keyword, all separated from each other and the base class by commas (,):
public class UndergraduateStudent extends Student implements ITeachable, IEmailable {
// TODO: Implement student class
}The Python programming language doesn’t include direct support for interfaces in the same way as other object-oriented programming languages. However, it is possible to construct the same functionality in Python with just a little bit of work. For the full context, check out Implementing in Interface in Python from Real Python. It includes a much deeper discussion of the different aspects of this code and why we use it.
To create an interface in Python, we will create a class that includes several different elements. Let’s look at an example for a MyCollection interface that we could create, which can be used for a wide variety of collection classes like lists, stacks, and queues:
import abc
from typing import List
class IMyCollection(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass: type) -> bool:
if cls is IMyCollection:
attrs: List[str] = ['size', 'empty']
callables: List[str] = ['add', 'remove', 'get', 'contains']
ret: bool = True
for attr in attrs:
ret = ret and (hasattr(subclass, attr)
and isinstance(getattr(subclass, attr), property))
for call in callables:
ret = ret and (hasattr(subclass, call)
and callable(getattr(subclass, call)))
return ret
else:
return NotImplemented
@property
@abc.abstractmethod
def size(self) -> int:
raise NotImplementedError
@property
@abc.abstractmethod
def empty(self) -> bool:
raise NotImplementedError
@abc.abstractmethod
def add(self, o: object) -> bool:
raise NotImplementedError
@abc.abstractmethod
def remove(self, i: int) -> bool:
raise NotImplementedError
@abc.abstractmethod
def get(self, i: int) -> object:
raise NotImplementedError
@abc.abstractmethod
def contains(self, o: object) -> bool:
raise NotImplementedErrorThis code includes quite a few interesting elements. Let’s review each of them:
abc library, which as you may recall is the library for Abstract Base Classes.List class from the typing library to assist with some type checking.IMyCollection class, we are listing the abc.ABCMeta class as the metaclass for this class. This allows Python to perform some analysis on the code itself. You can read more about Python Metaclasses from Real Python.__subclasshook__. This method is used to determine if a given class properly implements this interface. When we use the Python issubclass method, it will call this method behind the scenes. See below for a discussion of what that method does.@abc.abstractmethod decorator. Those methods simply raise a NotImplementedError, which enforces any class implementing this interface to provide implementations for each of these methods. Otherwise, the Python interpreter will raise that error for us.The __subclasshook__ method in our interface class above performs a task that is normally handled automatically for us in many other programming languages. However, since Python is dynamically typed, we will want to override this method to help us determine if any given object is compatible with this interface. This method uses a couple of metaprogramming methods in Python.
First, we must check and make sure the class that this method is being called on, cls, is our interface class. If not, we’ll need to return NotImplemented so Python will continue to use the normal methods for checking type.^[See https://stackoverflow.com/questions/40764347/python-subclasscheck-subclasshook for details]
Then, we see two lists of strings named attrs and callables. The attrs list is a list of all of the Python properties that should be part of our interface - in this case it should have a size and empty property. The callables list is a list of all the callable methods other than properties. So, our IMyCollection class will include add, remove, get, and contains methods.
Below that, we find two for loops. The first loop will check that the given class, stored in the subclass, contains properties for each item listed in the attrs list. It first uses the hasattr metaprogramming method to determine that the class has an attribute with that name, and then uses the isinstance method along with the getattr method to make sure that attribute is an instance of a Python property.
Similarly, the second for loop does the same process for the methods listed in the callables list. Instead of using isinstance, we use the callable method to make sure that the attribute is a callable method.
This method is a little complex, but it is a good look into how the compiler or interpreter for other object-oriented languages performs the task of making sure a class properly implements an interface. For our use, we can just copy-paste this code into any interface we create, and then update the attrs and callables lists as needed.
Let’s look at one more formal Python interface, this time for a stack:
import abc
from typing import List
class IMyStack(metaclass=abc.ABCMeta):
@classmethod
def __subclasshook__(cls, subclass: type) -> bool:
if cls is IMyStack:
attrs: List[str] = []
callables: List[str] = ['push', 'pop', 'peek']
ret: bool = True
for attr in attrs:
ret = ret and (hasattr(subclass, attr)
and isinstance(getattr(subclass, attr), property))
for call in callables:
ret = ret and (hasattr(subclass, call)
and callable(getattr(subclass, call)))
return ret
else:
return NotImplemented
@abc.abstractmethod
def push(self, o: object) -> None:
raise NotImplementedError
@abc.abstractmethod
def pop(self) -> object:
raise NotImplementedError
@abc.abstractmethod
def peek(self) -> object:
raise NotImplementedErrorThis is a simpler interface which simply defines methods for push, pop, and peek.
Once we’ve created an interface, we can then create a class that implements that interface. Any class that implements an interface must provide an implementation for all methods defined in the interface.
For example, we can create a MyList class that implements the IMyCollection interface defined above, as shown in this example:
from typing import List
class MyList(IMyCollection):
def __init__(self) -> None:
self.__list: List[object] = list()
self.__size: int = 0
@property
def size(self) -> int:
return self.__size
@property
def empty(self) -> bool:
return self.__size == 0
def add(self, o: object) -> bool:
self.__list.append(o)
self.__size += 1
return True
def remove(self, i: int) -> bool:
del self.__list[i]
return True
def get(self, i: int) -> object:
return self.__list[i]
def contains(self, o: object) -> object:
for obj in self.__list:
if obj == o:
return True
return FalseNotice that we include the interface class in parentheses as part of the class declaration, which will tell Python the interface that we are implementing in this class. Then, in the class, we include implementations for each method defined in the IMyCollection interface. Those implementations are simple and full of bugs, but they give us a good idea of what an implementation of an interface could look like. We can also include more attributes and a constructor, as well as additional methods as needed.
Python also allows a class to implement more than one interface. This is a special type of inheritance called multiple inheritance. Any class that implements multiple interfaces must provide an implementation for every method defined in each of the interfaces it implements.
For example, we can create a special MyListStack class that implements both the IMyCollection and IMyStack interfaces we defined above:
from typing import List
class MyListStack(IMyCollection, IMyStack):
# include all of the code from the MyList class
def push(self, o: object) -> None:
self.add(o)
def pop(self) -> object:
out = self.__list[self.__size - 1]
self.remove(self.__size - 1)
return out
def peek(self) -> object:
return self.__list[self.__size - 1]To implement multiple interfaces, we can simply list them inside of the parentheses as part of the class definition, separated by a comma.
Finally, recall from the previous page that we can treat any interface as a data type, so we can treat classes that implement the same interface in the same way. Here’s an example:
collects: List[IMyCollection] = list()
collects.append(MyList())
collects.append(MyListStack())
collects[0].add("String")
collects[1].add("Hello")However, it is important to remember that, because the second element in the collects array is an instance of the MyListStack class, we can also access the push and pop methods directly. This is because Python uses dynamic typing and duck typing, so as long as the object supports those methods, we can use them. Put another way, if the object is able to receive those messages, we can pass them to the object.
There are two special methods we can use to determine the type of an object in Python.
if isinstance(collects[1], MyListStack):
# do somethingThe isinstance method in Python is used to determine if an object is an instance of a given class.
if issubclass(collects[1], IMyStack):
# do somethingThe issubclass method is used to determine if an object is a subclass of a given class. Since we are creating a formal interface in Python and overriding the __subclasshook__ method, this will determine if the object properly includes all required properties and methods defined by the interface.
In an object-oriented language, inheritance is a mechanism for deriving part of a class definition from another existing class definition. This allows the programmer to “share” code between classes, reducing the amount of code that must be written.
Consider the Student class we created earlier:
class Student:
def __init__(self, first: str, last: str) -> None:
self.__first: str = first
self.__last: str = last
self.__credit_points: int = 0
self.__credit_hours: int = 0
# properties for first and last omitted
@property
def gpa(self) -> float:
"""Gets the student's grade point average.
"""
return self.__credit_points / self.__credit_hours
def add_course_grade(self, grade: Grade, hours: int) -> None:
"""Records a final grade for a course taken by this student.
Args
grade: the grade earned by the student
hours: the number of credit hours in the course
"""
self.__credit_hours += hours
if grade == Grade.A:
self.__credit_points += 4 * hours
elif grade == Grade.B:
self.__credit_points += 3 * hours
elif grade == Grade.C:
self.__credit_points += 2 * hours
elif grade == Grade.D:
self.__credit_points += 1 * hours
elif grade == Grade.F:
self.__credit_points += 0 * hoursThis would work well for representing a student. But what if we are representing multiple kinds of students, like undergraduate and graduate students? We’d need separate classes for each, but both would still have names and calculate their GPA the same way. So, it would be handy if we could say “an undergraduate is a student, and has all the properties and methods a student has” and “a graduate student is a student, and has all the properties and methods a student has.” This is exactly what inheritance does for us, and we often describe it as an is-a relationship. We distinguish this from the interface mechanism we looked at earlier by saying it is a strong is-a relationship, as an Undergraduate student is, for all purposes, also a Student.
Let’s define an undergraduate student class:
class UndergraduateStudent(Student):
def __init__(self, first: str, last: str) -> None:
super().__init__(first, last)In Python, we list the classes that a new class is inheriting from in parentheses at the end of the class definition. So, class UndergraduateStudent(Student): indicates that UndergraduateStudent inherits from (is a) Student. Thus, it has the attributes first and last that are inherited from Student, as well as the gpa property. Similarly, it inherits the add_course_grade() method.
In fact, the only method we need to define in our UndergraduateStudent class is the constructor - and we only need to define this because the base class has a defined constructor taking two parameters, first and last names. This Student constructor must be invoked by the UndergraduateStudent constructor - that’s what the super().__init__(first, last) line does - it invokes the Student constructor with the first and last parameters passed into the UndergraduateStudent constructor. In Python, the super() method call is usually the first line in the child class’s constructor, but it doesn’t have to be. It can be omitted if the parent class includes a default (parameter-less) constructor.
Let’s define a GraduateStudent class as well. This will look much like an UndergraduateStudent, but all graduates have a bachelor’s degree:
class GraduateStudent(Student):
def __init__(self, first: str, last: str, degree: str) -> None:
super().__init__(first, last)
self.__bachelor_degree = degree
@property
def bachelor_degree(self) -> str:
return self.__bachelor_degreeHere we added a property for bachelor_degree. Since the attribute itself is meant to be a private attribute (the name begins with two underscores __), it should only be written to by the class, as is done in the constructor. To the outside world, it is treated as read-only through the getter method. Of course, in Python, nothing is truly private, so a determined developer can always access these attributes if desired.
Thus, the GraduateStudent has all the state and behavior encapsulated in Student, plus the additional state of the bachelor’s degree title.
What you might not expect is that any fields that are private in the base class are inaccessible in the derived class. This is due to the way that Python performs name mangling of names that begin with two underscores __. Thus, the private fields credit_points and credit_hours cannot be used in a method defined in GraduateStudent. This is again part of the encapsulation and data hiding ideals - we’ve encapsulated and hid those variables within the base class, and any code outside that assembly, even in a derived class, is not allowed to mess with it.
However, we often will want to allow access to such variables in a derived class. In Python, we can use a single underscore _ in front of a variable or method name to indicate that it should be treated like a protected attribute, which is only accessed by the class that defines it and any classes that inherit from that class. However, as with anything else in Python, this attribute will still be accessible to any code within our program, so it is up to developers to respect the naming scheme and not try to access those directly.
In UML, protected attributes are denoted by a hash symbol # as the visibility of the attribute.
What happens when we construct an instance of GraduateStudent? First, we invoke the constructor of the GraduateStudent class:
grad_student: GraduateStudent = GraduateStudent("Willie", "Wildcat", "Computer Science")This constructor then invokes the constructor of the base class, Student, with the arguments "Willie" and "Wildcat". Thus, we allocate space to hold the state of a student, and populate it with the values set by the constructor. Finally, execution returns to the super class of GraduateStudent, which allocates the additional memory for the reference to the bachelor_degree property. Thus, the memory space of the GraduateStudent contains an instance of the Student, somewhat like nesting dolls.
Because of this, we can treat a GraduateStudent object as a Student object. For example, we can store it in a list that contains Student instances, along with UndergraduateStudent objects:
students: List[Student] = list()
students.append(grad_student)
students.append(UndergraduateStudent("Dorothy", "Gale"))Because of their relationship through inheritance, both GraduateStudent class instances and UndergraduateStudent class instances are considered to be of type Student, as well as their supertypes.
We can go as deep as we like with inheritance - each base type can be a superclass of another base type, and has all the state and behavior of all the inherited base classes.
This said, having too many levels of inheritance can make it difficult to reason about an object. In practice, a good guideline is to limit nested inheritance to two or three levels of depth.
If we have a base class that only exists to be inherited from (like our Student class in the example), we can mark it as abstract by inheriting from the ABC class. ABC is short for abstract base class. An abstract class cannot be instantiated (that is, we cannot create an instance of it by calling its constructor) unless all of its abstract methods have been overridden. It can still define fields and methods, but you can’t construct it. If we were to re-write our Student class as an abstract class:
from abc import ABC
class Student(ABC):
def __init__(self, first: str, last: str) -> None:
self.__first: str = first
self.__last: str = last
self.__credit_points: int = 0
self.__credit_hours: int = 0
# properties for first and last omitted
@property
def gpa(self) -> float:
"""Gets the student's grade point average.
"""
return self.__credit_points / self.__credit_hours
def add_course_grade(self, grade: Grade, hours: int) -> None:
"""Records a final grade for a course taken by this student.
Args
grade: the grade earned by the student
hours: the number of credit hours in the course
"""
self.__credit_hours += hours
if grade == Grade.A:
self.__credit_points += 4 * hours
elif grade == Grade.B:
self.__credit_points += 3 * hours
elif grade == Grade.C:
self.__credit_points += 2 * hours
elif grade == Grade.D:
self.__credit_points += 1 * hours
elif grade == Grade.F:
self.__credit_points += 0 * hoursNow with Student as an abstract class, attempting to create a Student instance:
the_wiz: Student = Student("Wizard", "Oz")would still be allowed since our Student class does not define any abstract methods. However, we can add an abstract method, such as the student_type method shown below.
@abstractmethod
def student_type(self) -> str:
raise NotImplementedErrorIf that method is placed within our Student class, we could no longer directly instantiate the class since it contains an abstract method. However, we can still create instances of the derived classes GraduateStudent and UndergraduateStudent, and treat them as Student instances, provided that they override the abstract method student_type in their code. It is best practice to make any class that serves only as a base class for derived classes and will never be created directly an abstract class.
Some programming languages, such as C#, include a special keyword sealed that can be added to a class declaration. A sealed class is not inheritable, so no other classes can extend it. This further adds security to the programming model by preventing developers from even creating their own version of that class that would be compatible with the original version.
This could theoretically be done in Python through the use of metaprogramming. However, due to the fact that no attributes or methods are truly private in Python, it wouldn’t have the desired effect of preventing other classes from gaining access to protected attributes and methods. So, we won’t cover how to do this here.
A class can use both inheritance and interfaces. In Python, a class can inherit multiple base classes, either as interfaces or as true parent classes. They work the same way - how the class is handled really depends on the code in the class that is being inherited.
class UndergraduateStudent(Student, ITeachable, IEmailable):For more on multiple inheritance in Python, check out the Multiple Inheritance in Python article from Real Python.
You have probably used casting to convert numeric values from one type to another, i.e.:
double a = 5.5;
int b = (int) a;a: float = 5.5
b: int = int(a)What you are actually doing when you cast is transforming a value from one type to another. In the first case, you are taking the value of a, which is the floating-point value 5.5, and converting it to the equivalent integer value 5.
Both of these are examples of an explicit cast, since we are explicitly stating the type that we’d like to convert our existing value to.
In some languages, we can also perform an implicit cast. This is where the compiler or interpreter changes the type of our value behind the scenes for us.
int a = 5;
double b = a + 2.5;a: int = 5
b: float = a + 2.5;In these examples, the integer value stored in a is implicitly converted to the floating point value 5.0 before it is added to 2.5 to get the final result. This conversion is done automatically for us.
However, as we’ve observed already, each language has some special cases where implicit casting is not allowed. In general, if the implicit cast will result in loss of data, such as when a floating-point value is converted to an integer, we must use an explicit cast instead.
Casting becomes a bit more involved when we consider inheritance. As you saw in the previous discussion of inheritance, we can treat derived classes as the base class. For example, in Java, the code:
Student willie = new UndergraduateStudent("Willie", "Wildcat");is actually implicitly casting the UndergraduateStudent object “Willie Wildcat” into a Student class. Because an UndergraduateStudent is a Student, this cast can be implicit. Going the other way requires an explicit cast as there is a chance that the Student we are casting isn’t an UndergraduateStudent, i.e.:
UndergraduateStudent u = (UndergraduateStudent)willie;If we tried to cast willie into a graduate student:
GraduateStudent g = (GraduateStudent)willie;The program would throw a ClassCastException when run.
In Python, things are a bit different. Recall that Python is a dynamically typed language. So, when we create an UndergraduateStudent object, the Python interpreter knows that that object has the type UndergraduateStudent. So, we can treat it as an instance of both the Student and UndergraduateStudent class. We don’t have to perform any conversions to do so.
However, if we try to treat it like an instance of the GraduateStudent class, it would fail with an AttributeError.
Both Java and Python include special methods for determining if a particular object is compatible with a certain type.
Student u = new UndergraduateStudent("Willie", "Wildcat");
if (u instanceof UndergraduateStudent) {
UndergraduateStudent uGrad = (UndergraduateStudent) willie;
// treat willie as an undergraduate student here
}u: Student = UndergraduateStudent("Willie", "Wildcat")
if isinstance(u, UndergraduateStudent):
# treat willie as an undergraduate student hereJava uses the instanceof operator to perform the check, while Python has a built-in isinstance method to perform the same task. Typically these statements are used as part of a conditional statement, allowing us to check if an object is compatible with a given type before we try to use that object in that way.
So, if we have a list of Student objects, we can use this method to determine if those objects are instances of UndergraduateStudent or GraduateStudent. It’s pretty handy!
The term dispatch refers to how a language decides which polymorphic operation (a method or function) a message should trigger.
Consider polymorphic functions in Java, also known as method overloading, where multiple methods use the same name but have different parameters. Here’s an example for calculating the rounded sum of an array of numbers:
public int roundedSum(int[] a){
int sum = 0;
for (int i : a) {
sum += i;
}
return sum
}
public int roundedSum(double[] a){
double sum = 0;
for (double i : a) {
sum += i;
}
return Math.round(sum);
}How does the computer know which version to invoke at runtime? It should not be a surprise that it is determined by the arguments - if an integer array is passed, the first is invoked, if a float array is passed, the second.
Python works a bit differently. In Python, method overloading is not allowed, so there cannot be two methods with the same name within a class. To achieve the same effect, optional parameters are used. In addition, because Python is dynamically typed, we could instead write our function to accept values of multiple types:
def rounded_sum(a: List[Union[int, float]]) -> int:
sum_value: float = 0.0
for i in a:
sum_value += i
return round(sum_value)As we can see, that function will accept a list of either integer values or floating-point values, and it can properly handle them in either case. In Python, the name of the method is the only thing that is used to determine which piece of code should be executed, not the arguments.
However, inheritance can cause some challenges in selecting the appropriate polymorphic form. Consider the following fruit implementations that feature a blend() method:
public class Fruit {
public String blend() {
return "A pulpy mess, I guess";
}
}
public class Banana extends Fruit {
@Override
public String blend() {
return "Yellow mush";
}
}
public class Strawberry extends Fruit {
@Override
public String blend() {
return "Gooey red sweetness!";
}
}class Fruit:
def blend(self) -> str:
return "A pulpy mess, I guess"
class Banana(Fruit):
def blend(self) -> str:
return "Yellow mush"
class Strawberry(Fruit):
def blend(self) -> str:
return "Gooey red sweetness!"Let’s add some fruit instances to a list, and invoke their blend() methods:
LinkedList<Fruit> toBlend = new LinkedList<>();
toBlend.add(new Fruit());
toBlend.add(new Banana());
toBlend.add(new Strawberry());
for(Fruit f : toBlend){
System.out.println(f.blend());
}to_blend: List[Fruit] = list()
to_blend.append(Fruit())
to_blend.append(Banana())
to_blend.append(Strawberry())
for f in to_blend:
print(f.blend())What will be printed? If we look at the declared types, we’d expect each of them to act like a Fruit instance, so in that case the output would be just three lines of A pulpy mess, I guess?
However, that is not correct! This is the powerful aspect of polymorphic method dispatch. In both Java and Python, we don’t look at the declared type of the object, but the actual underlying type of the instance itself. So, if the object was created as a Banana or Strawberry, then it will use the overridden methods from those child classes instead of the parent Fruit class. So, the actual output we’ll get is:
A pulpy mess, I guess
Yellow mush
Gooey red sweetness!In both Java and Python, we see an example of method overriding. If we include a method of the same name in the child class (and the same set of parameters, in the case of Java), we can override the method that exists in the parent class. In Java, we must use the @Override decorator, but Python doesn’t require anything special.
Of course, we can also update this example to either use an abstract class or an interface. There are some pros and cons to either option, but here’s a good rule of thumb to start with:
Car class and a subclass SportsCar that are both able to be instantiated.Canine class and subclasses Dog and Wolf, it might be best if the parent class cannot be instantiated directly.IUpdatable interface to require several classes to implement a method called update, but the classes themselves might not be related otherwise.Finally, remember that there are not really any correct answers here - each option comes with trade-offs, and it is up to you as a developer to help determine which is best. Therefore, it is very helpful to have experience with all three approaches so you understand how each one can be used.
In this chapter, we explored the concept of types and discussed how variables are specific types that can be explicitly or implicitly declared. We saw how in a statically-typed language (like Java), variables are not allowed to change types, though they can do so in a dynamically-typed language like Python. We also discussed how casting can convert a value stored in a variable into a different type. Implicit casts can happen automatically, but explicit casts must be indicated by the programmer using a cast operator, as the cast could result in loss of precision or the throwing of an exception.
We explored how class declarations and interface declarations create new types. We saw how polymorphic mechanisms like interface implementation and inheritance allow object to be treated as (and cast to) different types. We also introduced a few casting operators, which can be used to cast or test the ability to cast.
Finally, we explored how messages are dispatched when polymorphism is involved. We saw that the method invoked depends on what type the object was created as, not the type it is currently stored within.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
Fixing bugs & taking notes!
We’ve already spent quite a bit of time learning how to write code for our programs. But, what if something goes wrong? How can we fix it?
Unfortunately, it is nearly impossible to write a computer program that doesn’t contain any bugs. In fact, it is a common joke among programmers that the only truly bug-free program you’ll ever write is the classic “Hello World” program! So, we’ll need to have some tools at our disposal that we can use to find and fix the various bugs or errors in our code.
In this chapter, we’ll briefly discuss some of the concepts and techniques that we can use to explore and debug our code. In this chapter, we’ll introduce the following concepts:
First, let’s briefly discuss the art of debugging. Finding and fixing bugs in a complex piece of software is indeed an art, meaning that it something that takes a great amount of skill that comes with practice. So, how can we get better at this? Here are some tips. Much of this content was inspired by the talk The Art of Debugging by Remy Sharp.
This seems pretty obvious, but as we’ve discussed several times in this course, software bugs can be very costly to fix, and the longer they remain in the source code, the harder they can be to fix. So, as a developer, it is important for us to always focus on writing code that is free of any obvious bugs and errors.
If we take the time to think clearly about our code, trace it out on paper or in our head, and maybe even write small little test programs to make sure the code behaves the way we expect it to, we can greatly reduce the amount of simple bugs that get included in our programs. Even simple logic errors such as the classic “off by one” error (where we forget to properly handle the last item in an array) or more complex issues such as floating-point errors can be discovered and dealt with quickly by a programmer who is consciously thinking about how the code will be used and how it might fail.
Unfortunately, if a bug is introduced, we can follow a three step process to find and fix the bug.
The first step in debugging is figuring out how to consistently reproduce the bug. For example, say a customer complains that our point of sale application crashes once every few days. There could be all sorts of reasons why that might happen, and based on that information, it can be really difficult to tell what is going on.
However, with a bit more digging, we might find out that the customer only sells hot dogs on Fridays, and those are the days that the application crashes. That might give us a clue that something related to hot dogs might be the culprit.
So, we can start working with our program and figuring out exactly what causes the application to crash. Hopefully, we’ll be able to figure out a minimum set of steps or a short piece of sample code that can trigger the exact bug we are looking for. Once we are in a position to effectively reproduce the bug, we can start fixing it.
At this point, we know how to cause the bug, but we still may not know exactly why the bug is occurring, nor what piece of code is causing it. So, we’ll need to continually reproduce the bug while inspecting our program to determine the root cause. At this point, we can use several tools such as debuggers and stack traces to see exactly what is going on when the program crashes. We can also examine logs of data created by our program.
Finally, one of the simplest but surprisingly powerful methods of isolating a bug is to add some additional debugging code to our program, and then engage in a virtual “binary search” process to determine where the bug is. If the code reaches our debugging code before it crashes, we know that the bug occurs after that point in our program. While it may seem rudimentary, it can be a very powerful technique.
Once we have identified the location of bug, we can work on fixing it. At this point, one of the most powerful things we can do is write a unit test that causes the bug. We can use special methods in our unit test to assert that the code should or should not throw an exception, depending on how it should operate.
Then, once we are sure our unit test will cause the bug, we can set about trying to fix it. This could involve some careful coding to either catch the specific case that causes the bug, or we may have to more generally refactor or restructure our code a bit to deal with larger errors.
Once we believe we’ve fixed the bug, we can run our unit test to confirm that it is no longer present in our code. At that point, we may also want to run all of our unit tests as a form of regression testing to make sure that our fix for this bug didn’t introduce any new bugs as well.
If everything looks good, then we can work on deploying the new version of our application, hopefully with at least one fewer bug!
Object in our object-oriented programs can really be thought of as two different parts - the state and behavior of the object. When debugging, we may need to consider both parts of the object to determine what is really going on behind the scenes. So, let’s look at some ways we can explore the state of our program.
The quickest and easiest way to explore the state of our program at any particular point during its execution is to simply add a print statement that prints the value of any variables we are interested in.
Many times we are dealing with objects that we’ve created, and printing them directly may not be very useful. So, it is very important for us to develop useful string representations of our objects that we can use when debugging. In Java, we can override the default toString() method for this. In Python, we have both the __str__() method that is used when printing, as well as the more complex __repr__() method that typically gives more information.
When printing this information, it is helpful to include additional information along with the value of the variable, such as the function and even the line of code where the statement is located:
TestCode:5 - a=5 b=6 c=7As we’ll see later in this chapter, we can also do this automatically when we use a logger along with our program.
Sometimes, we may only want to print our program’s state when a particular situation occurs. In that case, we can simply wrap our print statements in a conditional statement, or if statement, that checks for the desired condition. This helps minimize the amount of data we have to sort through to pinpoint our error.
While this may seem pretty obvious, its important to remember that we can use the same simple tools we use when building a program to debug that program as well.
As a last resort, we may wish to force our program to have a particular state to help us isolate a bug. This is best accomplished through a unit test, since we can call individual functions with the exact values we need.
Later in this chapter, we’ll learn about one more tool we can use to inspect state - a debugger!
We may also wish to inspect the behavior of our program that could lead to a particular error. Specifically, we may need to know what set of function calls and classes lead to the error itself. In that case, we’ll need a way to see what code was executed before the bug was reached.
One of the most useful ways to inspect the behavior of our application is to look at the call stack or stack trace of the program when it reaches an exception. The call stack will list all of the functions currently being executed, even including the individual line numbers of the currently executed piece of code.
For example, consider this code:
public class Test {
public void functionA() throws Exception{
this.functionB();
}
public void functionB() throws Exception{
this.functionC();
}
public void functionC() throws Exception{
throw new Exception("Test Exception");
}
public static void main(String[] args) throws Exception{
Test test = new Test();
test.functionA();
}
}class Test:
def function_a(self) -> None:
self.function_b()
def function_b(self) -> None:
self.function_c()
def function_c(self) -> None:
raise Exception("Test Exception")
Test().function_a()This code includes a chain of three functions, and the innermost function will throw an exception. When we run this code, we’ll get the following error messages:
Exception in thread "main" java.lang.Exception: Test Exception
at Test.functionC(Test.java:12)
at Test.functionB(Test.java:8)
at Test.functionA(Test.java:4)
at Test.main(Test.java:17)Traceback (most recent call last):
File "Test.py", line 11, in <module>
Test().function_a()
File "Test.py", line 3, in function_a
self.function_b()
File "Test.py", line 6, in function_b
self.function_c()
File "Test.py", line 9, in function_c
raise Exception("Test Exception")
Exception: Test ExceptionAs we can see, both Java and Python will automatically print a stack trace of the exact functions and lines of code that we executed when we were reaching the error. Recall that this relates to the call stack in memory that is created while this program is executed:
As we can see, Java will print the innermost call at the top of the call stack, whereas Python will invert the order and put the innermost call at the end. So, you’ll have to read carefully to make sure you are interpreting the call stack correctly.
What if we want to get a call stack without crashing our program? Both Java and Python support a method for this:
Thread.dumpStack();traceback.print_stack()In both instances, we just need to import the appropriate library, and we have a method for examining the complex behaviors of our programs at our fingertips. Of course, as we’ll see in a bit, both debuggers and loggers can be used in conjunction with these methods to get even more information from our program.
What if we want to have a bit more control over our programs and use a more powerful tool for finding bugs. In that case, we’ll need to use a debugger. A debugger is a special application that allows us to inspect another program while it is running. Using a debugger, we can inspect both the state and behavior of an application, and observe the program directly while it runs. Most debuggers can also be configured to pause a program at a particular line of code, and then execute each following line one at a time to quickly find the source of the error. Both Java and Python come with debuggers that we can use.
In practice, very few developers use a debugger in a standalone way as described below. Instead, typically the debugger is part of their integrated development environment, or IDE. Using a debugger in an IDE is much simpler than using it via the terminal. At the bottom of this page, we’ll describe how to use the built-in debugger in Codio, which will be a much simpler experience.
The Java debugger jdb is a core part of the Java Software Development Kit (SDK), and is already installed for us in Codio. To use the Java debugger, we have to perform two steps:
-agentlib:jdwp=transport=dt_shmem,server=y,suspend=njdb -attach jdbconnOnce we’ve started a Java debugger session, we can use several commands to control the application. The Java Debugger manual from Oracle gives a good overview of how to use the application.
Python also includes a debugger, called pdb. It can be imported as a library within the code itself, or it can be used as a module when running another script. Similar to the Java debugger, once the debugger is launched, there are many different commands we can use to control the application. The Python Debugger documentation is a great source of information for how to use the Python debugger itself.
Of course, as you might guess, using a debugger directly on the terminal is a very complex, time-consuming, and painful process. Thankfully, most modern integrated development environments, or IDEs, include a graphical interface for various debuggers, and Codio is no exception. Codio includes a built-in debugger that is capable of debugging both Java and Python code.
The Codio Documentation is a great place to learn about how to use the Codio debugger and all of the features it provides. In the example project for this module, we’ll also learn how to quickly integrate a debugger into our larger project in Codio.
Once the Codio debugger is launched, you’ll be given a view similar to this one:
On the right, we can see the debugging window that lists the current call stack, any local variables that are visible, as well as watches and breakpoints. A breakpoint is a line of code that we’ve marked in the debugger that causes execution to stop, or break, when it reaches that line. Basically, we are telling the debugger that we’d like to execute the program up to that point. Once the program is paused, we can examine the state and call stack, and decide how we’d like to proceed. There are 5 buttons at the top of the debugger panel, and they are described in the Codio documentation2 as follows:
These five buttons are common to most debuggers, so it is very important to get used to them and how they work. Stepping through your code quickly and efficiently using breakpoints and a debugger is an excellent skill to learn!
Unfortunately, one major limitation of the Codio debugger is that it does not allow us to accept input via the terminal while the debugger is running. So, we’ll have to come up with some other way of providing input to our program if we need to debug it.
The easiest way is to write our program to read input from a file where needed. We can then provide the file name as a command-line argument when the program is launched via the debugger. In our code, if a command-line argument is provided, we know we should read from a file. Otherwise, we should just read from the terminal like usual.
We’ve seen how to do this in our code in many of the previous CC courses, so feel free to go back and review some of that code for examples. We’ll also look at how to do this in the example project for this module.
The last major concept we’ll introduce around debugging is the use of a formal logger in our code. A logger allows us to collect debugging information throughout our program in a way that is lightweight, highly configurable, and surprisingly easy to use. Both Java and Python include some standard ways to create a simple log file.
The Java language includes the Logger class that can be used to create a logger within the code. Then, we can define what Level of items we’d like to log, and how we’d like to store it. Typically, it’ll either be stored in a file or just printed to the terminal.
Here’s a very simple example of using a logger in our code:
import java.util.logging.FileHandler;
import java.util.logging.Level;
import java.util.logging.Logger;
public class LogTest {
private final static Logger LOGGER = Logger.getLogger(Logger.GLOBAL_LOGGER_NAME);
public static void main(String[] args){
// Levels INFO, WARNING, and SEVERE will be printed
LOGGER.setLevel(Level.INFO);
// Add a file logger
LOGGER.addHandler(new FileHandler("log.xml"));
LOGGER.info("This is an info log.");
LOGGER.warning("This is a warning, but not too bad.");
LOGGER.severe("This is a severe message, THIS IS BAD!");
}
}When this program is executed, we see the following output in the terminal:
Jan 21, 2021 10:14:46 PM LogTest main
INFO: This is an info log.
Jan 21, 2021 10:14:46 PM LogTest main
WARNING: This is a warning, but not too bad.
Jan 21, 2021 10:14:46 PM LogTest main
SEVERE: This is a severe message, THIS IS BAD!We should also see a new file named log.xml in our current working directory, which contains an XML version of the log information printed to the terminal:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE log SYSTEM "logger.dtd">
<log>
<record>
<date>2021-01-21T22:14:46</date>
<millis>1611267286120</millis>
<sequence>0</sequence>
<logger>global</logger>
<level>INFO</level>
<class>LogTest</class>
<method>main</method>
<thread>1</thread>
<message>This is an info log.</message>
</record>
<record>
<date>2021-01-21T22:14:46</date>
<millis>1611267286139</millis>
<sequence>1</sequence>
<logger>global</logger>
<level>WARNING</level>
<class>LogTest</class>
<method>main</method>
<thread>1</thread>
<message>This is a warning, but not too bad.</message>
</record>
<record>
<date>2021-01-21T22:14:46</date>
<millis>1611267286139</millis>
<sequence>2</sequence>
<logger>global</logger>
<level>SEVERE</level>
<class>LogTest</class>
<method>main</method>
<thread>1</thread>
<message>This is a severe message, THIS IS BAD!</message>
</record>
</log>Of course, if we change the level to Level.SEVERE, then only the last message will be printed. We can even turn the log off completely. So, in this way, we can include the logging messages in our code wherever they are needed, and then configure the logger to only print the messages we want, or no messages at all. This is much more flexible than our earlier method of just using print statements, since we don’t have to worry about removing them from our code later on.
The Java language includes the logging library that can be used to create a logger within the code. It includes several common Logging Levels that we can use, and we can easily configure it to log items to the terminal or a file.
Here’s a very simple example of using a logger in our code, adapted from the Logging HOWTO in the Python documentation:
import logging
import sys
class LogTest:
@staticmethod
def main():
# get the root logger
logger = logging.getLogger()
# set the log level
logger.setLevel(logging.INFO)
# add a terminal logger
stream_handler = logging.StreamHandler(sys.stderr)
stream_handler.setFormatter(logging.Formatter("%(asctime)s - %(name)s\n%(levelname)s: %(message)s"))
logger.addHandler(stream_handler)
# add a file logger
file_handler = logging.FileHandler("log.txt")
file_handler.setFormatter(logging.Formatter("%(asctime)s - %(name)s\n%(levelname)s: %(message)s"))
logger.addHandler(file_handler)
logger.info("This is an info log.")
logger.warning("This is a warning, but not too bad.")
logger.critical("This is a critical message, THIS IS BAD!")
if __name__ == "__main__":
LogTest.main()When this program is executed, we see the following output in the terminal:
2021-01-21 22:33:53,224 - root
INFO: This is an info log.
2021-01-21 22:33:53,224 - root
WARNING: This is a warning, but not too bad.
2021-01-21 22:33:53,225 - root
CRITICAL: This is a critical message, THIS IS BAD!We should also see a new file named log.txt in our current working directory, which contains the same content.
Of course, if we change the level to logging.CRITICAL, then only the last message will be printed. We can even turn the log off completely. So, in this way, we can include the logging messages in our code wherever they are needed, and then configure the logger to only print the messages we want, or no messages at all. This is much more flexible than our earlier method of just using print statements, since we don’t have to worry about removing them from our code later on.
Now that we know how to create a logger for our program, it should be really simple to convert any existing print statements to logging statements. Then, in the main class of our program, we can simply configure the desired level of logging - we would typically turn it completely off or only allow severe errors to be logged when the application is deployed, but for testing we may want the log to include more information.
This gives us a quick and flexible way to gain information from our code through the use of logging.
In this chapter, we discussed some steps we can take when debugging our applications. When we find a bug, we should try to figure out how to replicate it first, then focus on isolating the bug, and finally fix the bug. While we do so, we can write additional unit tests to reproduce the bug that will help us confirm that we’ve fixed it, and we can perform some regression testing to make sure we didn’t introduce any new errors.
We discussed ways we can inspect the state and behavior of our application. We learned that we can create a call stack or stack trace from our code, giving us insight into exactly what lines of code are being executed at any given time.
We explored the use of debuggers, and saw that Codio has a built-in debugger that we can use in our projects.
Finally, we learned about the logging capabilities that are present in both Java and Python, and how we can convert our simple print statements to logging statements that can easily be turned on, off, or configured as needed.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
Because every function deserves to be a first-class citizen!
Once of the more interesting features that has been added to most object-oriented languages over time is lambda expressions. Lambda expressions are a unique way to handle functions in our code - basically, we can create a function on the fly, and then pass that function around as a parameter or store it in a variable, just like any other object. In true Von Neumann fashion, we are effectively treating the executable code of our program just like data.
In this chapter, we’ll briefly explore lambda expressions and where they came from. We’ll see some examples of how they are used in both Java and Python, and then we’ll discuss some best practices for when we should, or should not, consider using them in our code.
In this course, we generally won’t need to use lambda expressions in our programs except in a few cases, such as specific types of unit tests in Java. This chapter is meant to simply be informative and let you explore one interesting aspect of programming you may not have worked with up to this point.
The basis of lambda expressions comes from a special branch of mathematics known as Lambda Calculus. It was first introduced by Alonzo Church, who is often connected with Alan Turing in the early days of theoretical computer science. (You may have heard of the Church-Turing thesis that relates to the computability of functions on a Turing machine.)
Lambda calculus is a formal notation used to describe computation. Recall that most mathematics uses expressions or equations, which express values, but don’t necessarily include the information needed to express the process of computation itself. By having a formal notation for computation, we can study the fundamental aspects of computer science and mathematics in a more rigorous way.
In programming, lambda calculus leads to a particular programming paradigm known as Functional Programming. The programming paradigm we’ve been studying, object-oriented programming is usually combined with the procedural programming paradigm, itself a subset of imperative programming. In imperative programming, we write code that consists of commands that modify the programs state. So, to compute the square of a number, we would create a variable in our state to store the result, and then modify that state by computing the correct value and storing it in that variable. The commands to do this are typically written as procedures (or functions) in procedural programming, so we can reuse those pieces of code throughout our program. Procedural programming typically follows the structured programming paradigm as well, where programs are constructed of smaller structures such as sequences, conditional statements, and iterative statements. Object-oriented programming, as we’ve learned, further refines this process by grouping related state and behaviors (methods which represent functions or procedures in other paradigms) into objects that can be seen as independent pieces of a larger program.
Functional programming is quite different. Instead of creating an imperative list of steps to be taken to modify the state of the program and achieve a result, functional programming involves constructing and applying mathematical functions, which simply translate values from inputs to outputs. Functional programming is a form of declarative programming, where computer programs are built simply by expressing the logic of the computation but not the individual steps or control flow necessary to achieve the desired result. In effect, a declarative programming language is used to state what a program does, but not necessarily how to do it.
Here is an example of the imperative and functional programming paradigms being used to compute the same value. In this case, the program will multiply all even numbers in an array by 10, and then add them up and store the final result in a variable called result. These examples use the JavaScript programming language, which should be somewhat readable to us even though we’ve only studied Java or Python. This example is taken directly from the functional programming article on Wikipedia:
const numList = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let result = 0;
for (let i = 0; i < numList.length; i++) {
if (numList[i] % 2 === 0) {
result += numList[i] * 10;
}
}const result = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
.filter(n => n % 2 === 0)
.map(a => a * 10)
.reduce((a, b) => a + b);The imperative programming code is very similar to what we would write in Java or Python. We start with our array of numbers, then use a for loop to iterate through the entire array. Inside of the for loop, we determine if the individual number is an even number using the modulo operator. If so, we multiply that number by 10 and add that value to the result variable.
The functional programming code achieves the same result through the use of three higher-order functions. A higher-order function is a function that can accept a function as input - in this case a lambda expression in the form of an anonymous function that converts one or more input parameters into an output value. We’ll dig deeper into lambda expressions later in this chapter, but for now we’ll just observe what they do.
So, our functional program can be broken down into four parts:
filter function. This function accepts a lambda expression as an argument. That lambda should take a value from the array, and convert it to a boolean value, which is used to filter the values in the array. In this case, that boolean value will be true if the value n from the array is an even number. The filter function then uses that lambda to return a new array that just contains those values in the original array that return true in the lambda function provided to filter. So, our new array will contain [2, 4, 6, 8, 10].map function to that new array returned from filter. The map function also takes a lambda as an argument, and that lambda is used to transform, or map, the values from the array to new values. In this case, it will convert the existing value a to the value a * 10. So, once the map function is complete, the array would contain [20, 40, 60, 80, 100]. Remember that this value isn’t stored as state in the program, per se, but is representing the values that would result from applying these functions to the input array itself.reduce function to reduce all of the values in the array to a single resulting value. The result function uses a lambda expression as an argument. That lambda is used to describe how to combine two values from the array, a and b, to a single resulting value. In this case, we want to sum the values in the array, so the lambda will return in a + b as the result. The reduce function will repeatedly use that lambda to reduce two values in the array to a single value until only one value remains. That value will be the result of that function, which will be then represented by the result variable. Notice that it isn’t stored in that variable, since again we don’t have the concept of state. Instead, we are just stating that the variable result now represents the value that is the result of applying these functions to the given input value.Functional programming can be challenging to understand at first, especially for programmers that come from an imperative programming paradigm. However, it is very powerful, and has some interesting uses. Once of the more common uses of functional programming is the creation of programs that can be proven to work correctly. This is because there is no actual computation performed, so there can be no side effects from those computations. Therefore, as long as the functional statements yield the correct results via a mathematical proof, we know that the program works correctly.
Many programming languages today either support some form of functional programming, or at least support the use of lambda expressions within their code. Some languages, such as Python, JavaScript and Go, support the functional programming paradigm directly. Other languages, such as Java and C#, have introduced the ability to do some functional programming over time.
Other languages, such as Haskell, F#, Erlang, and Lisp are built almost exclusively for functional programming. While they are most used in academia, functional programming is also very commonly used in web back-end development, statistics, data science, and more.
One of the major concepts from functional programming is that functions are now treated as first-class citizens within a programming language. A first-class citizen is an element of a programming language that can be treated like any other element - it can be stored in a variable, provided as an argument to another function, returned from a function, and even modified by other code.
This can be a very strange concept to reason about - we are used to thinking of state and behavior as two separate parts of an object-oriented program. However, functional programming allows us to store a behavior as state, and then use that behavior as input to other parts of the code.
In both Java and Python, one of the most common ways to create a behavior that can be stored as state is to use a lambda expression. Lambda expressions are sometimes known as anonymous functions since they are effectively functions that are not given a name, though some languages like Python allow us to assign names to lambda expressions as well.
As we saw in the example on the previous page, JavaScript allows us to quickly create lambda expressions that perform a particular task, such as determining if a value meets a given criteria that was used with filter, converting a value to a new value as used with map, or taking two values and reducing them to a single value as used in the reduce function.
In that example, filter, map, and reduce are examples of higher-order functions that accept other functions as input. Those higher-order functions can then use the function provided as input to perform their work. In the case of filter, it uses the provided function to determine if each value in the array should be included in the result or not.
We’ve already seen a couple of examples of lambda expressions, or at least something similar, in our programs:
() -> new GameLogic() used as part of a unit test. That lambda is used to create a new object, and is used by the assertThrows assertion, itself a higher-order function, to determine if the code in the lambda expression results in an exception. In effect, that function executes the lambda and observes the result to determine if the exception is thrown.square_list = [x**2 for x in range(0, 10)]. While list comprehension isn’t exactly the same as a lambda expression, it is very similar in concept. We are effectively creating a small anonymous function that is used to populate a list. In fact, we could do the same thing with a lambda expression: square_list = list(map(lambda x: x**2, range(0, 10)))On the next pages, we’ll discuss the specifics of creating and using lambda expressions in both Java and Python. Feel free to read the page for the language you are studying, but it may be very informative to review how both languages handle the same concept.
Java introduced lambda expressions in Java version 8. As we would expect based on the previous pages, it allows us to create anonymous functions that can then be passed as arguments to other functions. Java includes several new types, such as Predicate and Consumer, all contained in the java.util.function package.
In general, a lambda expression in Java consists of the following syntax:
->{}Let’s look at an example of creating and using a lambda expression in our code. This example comes from Lambda Expressions from the Oracle Java Tutorials:
public class Calculator {
interface IntegerMath {
int operation(int a, int b);
}
public int operateBinary(int a, int b, IntegerMath op) {
return op.operation(a, b);
}
public static void main(String... args) {
Calculator myApp = new Calculator();
IntegerMath addition = (a, b) -> a + b;
IntegerMath subtraction = (a, b) -> a - b;
System.out.println("40 + 2 = " +
myApp.operateBinary(40, 2, addition));
System.out.println("20 - 10 = " +
myApp.operateBinary(20, 10, subtraction));
}
}In this simple calculator class, we are defining an internal interface called IntegerMath, which defines one operation between two integers, which also returns an integer. Then, in our Calculator class, we have a function operateBinary that accepts an argument of type IntegerMath.
So, in our main method, we are creating two lambda expressions that use the type IntegerMath. One is a lambda that accepts two values and returns the sum, and the other accepts two values and returns the difference. Java will automatically recognize that those lambda expressions match the operation method defined in the IntegerMath interface. So, when we call the operateBinary method and provide either addition or subtraction as arguments, it will use those lambda expressions to compute the result.
As we can see, we were able to create two functions, via lambda expressions, as first-class citizens in our language by storing them in variables, and then passing those functions as arguments to another method, which can then call the function itself.
In practice, Java tends to use lambda expressions for tasks such as sorting, filtering, or mapping data in a collection. Lambda Expressions from the Oracle Java Tutorials gives another example that can be used to quickly generate a filter that will print a list of email addresses for people in list who are males between the ages of 18 and 25:
The function that accomplishes this work is shown below:
public static void processPersonsWithFunction(
List<Person> roster,
Predicate<Person> tester,
Function<Person, String> mapper,
Consumer<String> block) {
for (Person p : roster) {
if (tester.test(p)) {
String data = mapper.apply(p);
block.accept(data);
}
}
}We can use that function by passing three lambdas, as shown here:
processPersonsWithFunction(
roster,
p -> p.getGender() == Person.Sex.MALE
&& p.getAge() >= 18
&& p.getAge() <= 25,
p -> p.getEmailAddress(),
email -> System.out.println(email)
);In this case, roster is a list of Person objects, and we have created three lambda expressions to filter the list to include only the people we want, them map those people to an email address, and finally print those emails to the terminal.
Finally, while methods in Java aren’t exactly first-class citizens, there is a shorthand that we can use to create lambda expressions that simply call a given method.
For example, the lambda expression:
a -> a.toLowerCase()simply calls the toLowerCase() method of the String class. So, we could replace that with this method reference:
String::toLowerCase()In effect, this allows us to reference a function as if it were a first-class citizen, even if we can’t truly store it in a variable like other objects in Java.
There are four different types of method references:
ClassName::staticMethodNameobjectInstance::instanceMethodNameClassName::methodNameClassName::newMany parts of the Java API accept method references along with lambda expressions, so this is yet another way we can make use of existing or anonymous functions in our code.
For more information on using lambda expressions and method references in Java, check out the references linked below.
Lambda expressions, typically called lambda functions in most Python documentation, are effectively a syntactic shortcut for defining a function within Python code. This is because normal Python functions are already first-class citizens in the language - we can already pass existing named functions as arguments to other functions! So, lambdas in Python are simply shortcuts we can use to create a new anonymous function where needed, but we can always use normal functions to perform the same task.
Python lambda functions are effectively the same as Python functions. For example, we can write an addition function in Python in the following way:
def addition(x, y):
return x + yThe same concept can be expressed as a lambda function, and we can even store it in a variable:
addition_lambda = lambda x, y: x + yThose two functions are effectively identical - they produce the same result, and can be treated as variables as well as callable functions.
The basic syntax of a lambda function in Python includes the following:
lambdareturn or pass.In addition, Python lambda functions are not compatible with type annotations. So, when working with object-oriented Python, we will almost always prefer to write our own functions using the normal syntax, which allows us to perform type checking using Mypy.
Here’s a quick example of using both lambda functions and normal class functions as first-class citizens in Python. This example is adapted from a similar example given in Lambda Expressions from the Oracle Java Tutorials:
class Calculator:
@staticmethod
def addition(x, y):
return x + y
def operate_binary(self, a, b, operation):
return operation(a, b)
@staticmethod
def main():
calc = Calculator()
subtraction = lambda x, y: x - y
print("40 + 2 = {}".format(calc.operate_binary(40, 2, Calculator.addition)))
print("20 - 10 = {}".format(calc.operate_binary(20, 10, subtraction)))
print("7 * 6 = {}".format(calc.operate_binary(7, 6, lambda: x, y: x * y)))
if __name__ == "__main__":
Calculator.main()In this code, we are defining two different functions that we’ll use later as arguments:
addition is a static method within the Calculator class that adds two values together.subtraction is a variable in the main function that is storing a lambda function that will subtract two values.Then, we’ve created a higher-order function operate_binary in the Calculator class, which accepts two integers as parameters a and b, as well as a callable object in the operation parameter. In effect, the operation parameter is meant to be a function, either a traditional Python function or a lambda function.
In our main function, we call calc.operate_binary in two different ways. On the first line, we provide Calculator.addition as the third argument. Notice that we are not including the parentheses at the end of the function name. In that way, we aren’t calling the function Calculator.addition, but we are referencing it as an attribute within the Calculator class. We can do this because functions are first-class citizens in Python, so we can treat them just like any other variable. Inside the calc.operate_binary function, we see that it calls the function stored in the operation variable by putting parentheses after the name, pass in any arguments as needed.
In the second example, we are passing the subtraction variable, which is a lambda function we created earlier, to the calc.operate_binary higher order function. So, it will be stored in operation and executed there.
Finally, we can create an anonymous lambda function directly within the function call to calc.operate_binary. This is why, typically, most lambda functions in Python are thought of as anonymous functions - we don’t give them a name or store them in a variable, we simply create them as needed when we pass them to higher-order functions.
For more information on using lambda functions in Python, check out the references linked below.
Lambda expressions are a very powerful tool that has been added to many different programming languages, including the ones we are studying in this course. However, there are some caveats that we should be aware of, and some best practices to follow.
For starters, lambda expressions can affect the readability of code. Even though lambda expressions are included in both Java and Python, and have been for quite a while at this point, many developers still have not learned how to use them. This is mainly due to the fact that lambda expressions are closely related to functional programming, which is a completely different programming paradigm than what most programmers are used to.
In addition, pretty much anything that can be done with a lambda expression can be achieved through strictly procedural code, so there is really nothing to be gained through the use of lambda expressions in terms of functionality or performance.
Instead, the use of lambda expressions in Java and Python really comes down to readability, and for that reason, many developers tend to avoid them. From a certain point of view, lambda expressions don’t really do anything except make the code harder to read for some developers, but possibly easier to read for others.
If we do choose to use a lambda expression, it is best to keep them as short and concise as possible. In effect, a lambda expression should be thought of as a single operation or expression. In Python, this is required, but Java allows lambda expressions to include multiple statements.
If we need to write more complex code, it is probably best to do so using procedural code and traditional functions instead of lambda expressions.
In general, while lambda expressions are very powerful and can be used in many different places in our code, in this course we’ll generally avoid their use in places where they are not required. However, as a developer, you are welcome to use your better judgment - if you feel that a piece of code is better expressed as a lambda expression instead of procedural code, you are welcome to do so. When you do, keep in mind that this may make your code more difficult to understand for novice programmers who are not experienced with lambdas, so you may wish to thoroughly document your code to explain how it works.
In this chapter, we introduced lambda calculus as the basis for the functional programming paradigm. In functional programming, programs are written in a declarative language, expressing the desired result as a composition of functions instead of a procedural set of steps to execute.
In Java and Python, this appears as lambda expressions or lambda functions - small pieces of code that can be used to create anonymous functions. In addition, those functions can be treated as first-class citizens in our language, so we can store them in variables, pass them as arguments, and more.
However, due to the fact that lambda expressions are not well understood by a large number of programmers who do not have experience with functional programming, we’ll generally avoid their use in our code. In most cases, anything that can be done in a lambda expression can also be done using procedural code and functions, and that is much more readable to the average programmer.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
Building more beautiful and repeatable software!
Up to this point, we’ve mainly been developing our programs without any underlying patterns between them. Each program is custom-written to fit the particular situation or use case, and beyond using a few standard data structures, the code and structure within each program is mostly unique to that application. In this chapter, we’re going to learn about software design patterns, a very powerful aspect of object-oriented programming and a way that we can write code that is more easily recognized and understood by other developers. By using these patterns, we can see that many unrelated programs can actually share similar code structures and ideas.
Some of the key terms we’ll cover in this chapter:
After reviewing this chapter, we should be able to recognize and use several of the most common design patterns in our code.
While the first discussions of patterns in software architecture occurred much earlier, the concept was popularized in 1994 with the publication of Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides. Collectively, the four authors of this book have been referred to as the “Gang of Four” or “GoF” within the software development community, so it is common to see references to that name when discussing the particular software design patterns discussed in the book.
In their book, the authors give their thoughts on how to build software following the object-oriented programming paradigm. This includes focusing on the use of interfaces to design how classes should appear to function to an outside observer, while leaving the actual implementation details hidden within the class. Likewise, they favor the use of object composition over inheritance - instead of inheriting functionality from another class, simply store an internal instance of that class and use the public methods it contains.
The entire first chapter of the book is a really great look at one way to view object-oriented programming, and many of the items discussed by the authors have been implemented by software developers as standard practice. In fact, it is still one of the best selling books on software architecture and design, even decades after its release!
Of course, it isn’t without criticism. One major complaint of this particular book is that it was developed to address several things that cannot be easily done in C++, which have been better handled in newer programming languages. In addition, the reliance on reusable software design patterns may feel a bit like making the problem fit the solution instead of building a new solution to fit the problem.
The most important part of the book by the “Gang of Four,” as evidenced by the title, are the 23 software design patterns that are discussed within the book.
A software design pattern is a reusable structure or solution to a common problem or usage within software development. Throughout the course of developing many different programs in the object-oriented paradigm, developers may find that they are reusing similar ideas or code structures within applications with completely different uses, which leads to the idea of formalizing these ideas into reusable structures.
However, it is important to understand that a design pattern is not a finished piece of code that can simply be dropped into a program. Instead, a design pattern is a framework, structure, or template that can be used to achieve a particular result or solve a given problem. It is still up to the developer to actually determine if the design pattern can be used, and how to make it work.
The power of these design patterns lies in their common structure and the familiarity that other developers have with the pattern. For example, when building a program that requires a single global instance of class, there are many ways to do it. One way is the singleton pattern, which we’ll explore later in this chapter. If we choose to use that pattern, we can then tell other developers “this uses the singleton pattern” and, hopefully, they’ll be able to understand how it works as long as they are familiar with the pattern. If they aren’t, then the usefulness of the pattern is greatly reduced. So, it is very helpful for developers to be familiar with commonly-used design patterns, while constantly being on the lookout for new and interesting patterns to learn about and add to their ever growing list of patterns that can be used.
A great analogy is poetry. If we write a simple poem containing 5 lines, where the first, second, and fifth all end in a rhyming word and have the same number of syllables, and the third and fourth also rhyme and have fewer syllables, it could be very difficult to explain that structure to another writer. However, if we just say “I’ve written a limerick” to another writer, that writer might instantly understand what we mean, just based on their own familiarity with the format. However, if the writer is not familiar with a limerick, then referencing that pattern might not be helpful at all.
In Design Patterns, the “Gang of Four” introduced 23 patterns, which were grouped into three categories:
In addition, many modern references also include a fourth category: Concurrency Patterns, which are specifically related to building programs that run on multiple threads, multiple processes, or even across multiple systems within a supercomputer. We won’t deal with those patterns in this course since they are greatly outside the scope of what we’re going to cover.
Instead, we’re going to primarily focus on three creational patterns: the builder pattern, the factory method pattern, and the singleton pattern. Each one of these is commonly used in many object-oriented programs today, and we’ll be able to make use of each of them in our ongoing course project.
We’ll also look at a few of the structural and behavioral patterns: the iterator pattern, the template method pattern, and the adapter pattern.
The first pattern we’ll look at is the builder pattern. The builder pattern is used to simplify building complex objects, where the class that needs the object shouldn’t have to include all of the code and details for how to construct that object. By decoupling the code for constructing the complex object from the classes that use it, it becomes much simpler to change the representations or usages of the complex object without changing the classes that use it, provided they all adhere to the same general API.
The UML diagram above gives one possible structure for the builder pattern. It includes a Builder interface that other objects can reference, and Builder1 is a class that implements that interface. There could be multiple builders, one for each type of object. The Builder1 class contains all of the code needed to properly construct the ComplexObject class, consisting of ProductA1 and ProductB1. If a different ComplexObject must be created, we can create another class Builder2 that also implements the Builder interface. To the Director class, both Builder1 and Builder2 implement the same interface, so they can be treated as the same type of object.
A great example of this would be creating a deck of cards for various card games. There are actually many different types of card decks, depending on the game that is being played:
As we can see, even though each individual card is similar, constructing a deck for each of these games might be quite the complex process.
Instead, we can use the builder pattern. Let’s look a how this could work.
First, we’ll assume that we have a very simple Card class, consisting of three attributes:
SuitOrColor - the suit or color of the card. We’ll use a special color for cards that aren’t associate with a group of other cardsNumberOrName - the number or name of the cardRank - the sorting rank of the card (lowest = 1).public class Card{
String suitOrColor;
String numberOrName;
int rank;
public Card(String suit, String number, int rank) {
this.suitOrColor = suit;
this.numberOrName = number;
this.rank = rank;
}
}class Card:
def __init__(self, suit: str, number: str, rank: int) -> None:
self._suit_or_color: str = suit
self._number_or_name: str = number
self._rank: int = rankThe Deck class will only consist of an aggregation, or list, of the cards contained in the deck. So, our builder class will return an instance of the Deck object, which contains all of the cards in the deck.
The Deck class could also include generic methods to shuffle, draw, discard, and deal cards. These would work with just about any of the games listed above, regardless of the details of the deck itself.
import java.util.LinkedList;
import java.util.List;
public class Deck{
List<Card> deck;
public Deck() {
deck = new LinkedList<>();
}
void shuffle();
Card draw();
void discard(Card card);
List<List<Card>> deal(int hands, int size);
}from typing import List
class Deck:
def __init__(self) -> None:
self._deck: List[Card] = list()
def shuffle(self) -> None:
def draw(self) -> Card:
def discard(self, card: Card) -> None:
def deal(self, hands: int, size: int) -> List[List[Card]]:Our DeckBuilder interface will be very simple, consisting of a single method: buildDeck(). The type of the class that implements the DeckBuilder interface will determine which type of deck is created. If the decks created by the builder have additional options, we can add additional methods to our DeckBuilder interface to handle those situations.
Finally, we can create our builder classes themselves. These classes will handle actually building the different decks required for each game. First, let’s build a standard 52 card deck.
public class Standard52Builder implements DeckBuilder {
String[] suits = {"Spades", "Hearts", "Diamonds", "Clubs"};
public Deck buildDeck() {
Deck deck = new Deck();
for (String suit : suits) {
for (int i = 2; i <= 14; i++) {
if (i == 11) {
deck.add(new Card(suit, "Jack", i));
} else if (i == 12) {
deck.add(new Card(suit, "Queen", i));
} else if (i == 13) {
deck.add(new Card(suit, "King", i));
}else if (i == 14) {
deck.add(new Card(suit, "Ace", i));
} else {
deck.add(new Card(suit, "" + i, i));
}
}
}
return deck;
}
}from typing import List
class Standard52Builder(DeckBuilder):
suits: List[str] = ["Spades", "Hearts", "Diamonds", "Clubs"]
def build_deck(self):
deck: Deck = Deck()
for suit in suits:
for i in range(2, 15):
if i == 11:
deck.append(Card(suit, "Jack", i))
elif i == 12:
deck.append(Card(suit, "Queen", i))
elif i == 13:
deck.append(Card(suit, "King", i))
elif i == 14:
deck.append(Card(suit, "Ace", i))
else:
deck.append(Card(suit, str(i), i))
return deckAs we can see, the heavy lifting of actually building the deck is offloaded to the builder class. We can easily use this same framework to create additional Builder classes for the other types of decks listed above.
Finally, once we’ve created all of the builders that we’ll need, we can use them directly in our code anywhere we need them:
public class CardGame{
public static void main(String[] args) {
DeckBuilder builder = new Standard52Builder();
Deck cards = builder.buildDeck();
// game code goes here
}
}from typing import List
class CardGame:
@staticmethod
def main(args: List[str]) -> None:
builder: DeckBuilder = Standard52Builder()
cards: Deck = builder.build_deck()
# game code goes hereFrom here, if we want to use any other decks of cards, all we have to do is switch out the single line for the type of builder we instantiate, and we’ll be good to go! This is the powerful aspect of the builder pattern - we can move all of the complex code for creating objects to a builder class, and then any class that uses it can quickly and easily construct the objects it needs in order to function.
On the next page, we’ll see how we can expand this pattern by including the factory pattern to help simplify things even further.
The next pattern we’ll explore is the factory method pattern. The factory method pattern is used to allow us to construct an object of a desired type without actually having to specify that type explicitly in our code. Instead, we just provide the factory with an input specifying the type of object we need, and it will return an instance of that type. By making use of the factory method pattern, classes that require access to these object don’t need to be updated any time an underlying object type is modified. Instead, they can simply reference the parent or interface data types, and the factory handles creating and returning objects of the correct type whenever needed.
As we can see in the UML diagram for this pattern, it looks very similar to the builder pattern we saw previously. There is a Creator interface, which defines the interface that each factory uses. Then, the concrete Creator1 class is actually used to create the class required.
Let’s continue our deck of cards example from the previous page to include the factory method pattern.
To simplify this process, we’ll create a quick enumeration of the possible decks available in our system. This makes it easy to expand later and include more decks of cards.
public enum DeckType {
STANDARD52("Standard 52"),
STANDARD52ONEJOKER("Standard 52 with One Joker"),
STANDARD52TWOJOKER("Standard 52 with Two Jokers"),
PINOCHLE("Pinochle"),
OLDMAID("Old Maid"),
UNO("Uno"),
ROOK("Rook");
}from enum import Enum
class DeckType(str, Enum):
STANDARD52 == "Standard 52"
STANDARD52ONEJOKER == "Standard 52 with One Joker"
STANDARD52TWOJOKER == "Standard 52 with Two Jokers"
PINOCHLE == "Pinochle"
OLDMAID == "Old Maid"
UNO == "Uno"
ROOK == "Rook"Next, we’ll define a simple factory class, which is able to build each type of card deck. We’ll leave out the parent interface for now, since this project will only ever have a single factory object available.
import java.lang.IllegalArgumentException;
public class DeckFactory{
public Deck getDeck(DeckType deck) {
if(deck == DeckType.STANDARD52){
return new Standard52Builder().buildDeck();
}else if(deck == DeckType.STANDARD52ONEJOKER){
return new Standard52OneJokerBuilder().buildDeck();
}else if(deck == DeckType.STANDARD52TWOJOKER){
return new Standard52TwoJokerBuilder().buildDeck();
}else if(deck == DeckType.PINOCHLE){
return new PinochleBuilder().buildDeck();
}else if(deck == DeckType.OLDMAID){
return new OldMaidBuilder().buildDeck();
}else if(deck == DeckType.UNO){
return new UnoBuilder().buildDeck();
}else if(deck == DeckType.ROOK){
return new RookBuilder().buildDeck();
}else {
throw new IllegalArgumentException("Unsupported DeckType");
}
}
}class DeckFactory:
def get_deck(self, deck: DeckType) -> Deck:
if deck == DeckType.STANDARD52:
return Standard52Builder().buildDeck()
elif deck == DeckType.STANDARD52ONEJOKER:
return Standard52OneJokerBuilder().buildDeck()
elif deck == DeckType.STANDARD52TWOJOKER:
return Standard52TwoJokerBuilder().buildDeck()
elif deck == DeckType.PINOCHLE:
return Standard52Builder().buildDeck()
elif deck == DeckType.OLDMAID:
return OldMaidBuilder().buildDeck()
elif deck == DeckType.UNO:
return UnoBuilder().buildDeck()
elif deck == DeckType.ROOK:
return RookBuilder().buildDeck()
else:
raise ValueError("Unsupported DeckType");Now that we’ve created our factory class, we can update our main method to use it instead. In this case, we’ll get the type of deck to be used directly from the user as input:
public class CardGame{
public static void main(String[] args) {
// ask user for input and store in `deckType`
String deckType = "Standard 52";
Deck cards = DeckFactory().getDeck((DeckType.valueOf(deckType)));
// game code goes here
}
}from typing import List
class CardGame:
@staticmethod
def main(args: List[str]) -> None:
# ask user for input and store in `deck_type`
deck_type: str = "Standard 52"
cards: Deck = DeckFactory().get_deck(DeckType(deck_type))
# game code goes hereThis code is actually doing quite a bit in only two lines, so let’s go through it step by step. First, we’re assuming that we are getting user input to determine which deck should be used. This could be done via a GUI, the terminal, or some other means. We’re storing that input in a string, just to demonstrate the power of the factory method pattern. As long as the string matches one of the available deck types in the DeckType enum, it will work. Of course, this may be difficult to do, so our input code might need to verify that the user inputs a valid option.
However, if we have a valid option, we can convert it to the correct enum value, and then pass that as an argument to the getDeck() method of our DeckFactory class. The factory will look at the parameter, construct the correct deck using the appropriate builder class, and then return it back to our application. Pretty handy!
One of the most common places the factory method pattern appears is in the construction of database connections. In theory, we’d like any of our applications to be able to use different types of databases, so many database connection libraries use the factory method pattern to create a database connection. Here’s what that might look like - this code will not actually work, but is representative of what it looks like in practice:
public class DbTest{
public static void main(String[] args) {
// connect to Postgres
DbConnection conn = DbFactory.get("postgres");
conn.connect("username", "password", "database");
// connect to MySql
DbConnection conn2 = DbFactory.get("mysql");
conn2.connect("username", "password", "database");
// connect to Microsoft SQL Server
DbConnection conn3 = DbFactory.get("mssql");
conn3.connect("username", "password", "database");
}
}class DbTest:
@staticmethod
def main(args: List[str]) -> None:
# connect to Postgres
conn: DbConnection = DbFactory.get("postgres")
conn.connect("username", "password", "database")
# connect to MySql
conn2: DbConnection = DbFactory.get("mysql")
conn2.connect("username", "password", "database")
# connect to Microsoft SQL Server
conn3: DbConnection = DbFactory.get("mssql")
conn3.connect("username", "password", "database")In each of these examples, we can get the database connection object we need to interface with each type of database by simply providing a string that specifies which type of database we plan to connect to. This makes it quick and easy to switch database types on the fly, and as a developer we don’t have to know any of the underlying details for actually connecting to and interfacing with the database. Overall, this is a great use of the factory method pattern in practice today.
Finally, let’s look at one other common creational pattern: the singleton pattern. The singleton pattern is a simple pattern that allows a program to enforce the limitation that there is only a single instance of a class in use within the entire program. So, when another class needs an instance of this class, instead of instantiating a new one, it will simply get a reference to the single existing object. This allows the entire program to share a single instance of an object, and that instance can be used to coordinate actions across the entire system.
The UML diagram for the singleton pattern is super simple. The class implementing the singleton pattern simply defines a private constructor, making sure that no other class can construct it. Instead, it stores a static reference to a single instance of itself, and includes a get method to access that single instance.
Let’s look at how this could work in our ongoing example.
Let’s update our DeckFactory class to use the singleton pattern.
public class DeckFactory{
// private static single reference
private static DeckFactory instance = null;
// private constructor
private DeckFactory(){
// do nothing
}
public static DeckFactory getInstance() {
// only instantiate if it is called at least once
if DeckFactory.instance == null{
DeckFactory.instance = new DeckFactory();
}
return DeckFactory.instance;
}
public Deck getDeck(DeckType deck) {
// existing code omitted
}
}There are actually two different ways to implement this in Python. The first is closer to the implementation seen in Java above and in C++ in the original book.
class DeckFactory:
# private static single reference
_instance: DeckFactory = None
# constructor that cannot be called
def __init__(self) -> None:
raise RuntimeError("Cannot Construct New Object!")
@classmethod
def get_instance(cls) -> DeckFactory:
# only instantiate if it is called at least once
if cls._instance is None:
# call `__new__()` directly to bypass __init__
cls._instance = cls.__new__(cls)
return cls._instance
def get_deck(self, deck: DeckType) -> Deck:
# existing code omittedA more Pythonic way would be to simply make use of the __new__() method itself to create the singleton and return it anytime the __init__() method is called. In Python, when any class is constructed normally, as in DeckFactory(), the __new__() method is called on the class first to create the instance, and then the __init__() method is called to set the instance’s attributes and perform any other initialization. So, by ensuring that the __new__() method consistently returns the same instance, we can guarantee that only a single instance exists.
class DeckFactory:
# private static single reference
_instance: DeckFactory = None
# new method to construct the instance
def __new__(cls) -> DeckFactory:
if cls._instance is None:
# call `__new__()` on the parent `Object` class
cls._instance = super().__new__(cls)
return cls._instance
def get_deck(self, deck: DeckType) -> Deck:
# existing code omittedIn this way, any calls to construct a DeckInstance() in the traditional way would just return the same object. Very Pythonic!
See Singleton on the excellent Python Design Patterns website for a discussion of these two implementations.
Now we can update our main method code to use our singleton DeckFactory instance instead of creating one when it is needed:
public class CardGame{
public static void main(String[] args) {
// ask user for input and store in `deckType`
String deckType = "Standard 52";
Deck cards = DeckFactory.getInstance().getDeck((DeckType.valueOf(deckType)));
// game code goes here
}
}from typing import List
class CardGame:
@staticmethod
def main(args: List[str]) -> None:
# ask user for input and store in `deck_type`
deck_type: str = "Standard 52"
cards: Deck = DeckFactory.get_instance().get_deck(DeckType(deck_type))
# Python method described above means the code doesn't change!
# cards: Deck = DeckFactory().get_deck(DeckType(deck_type))
# game code goes hereWhy would we want to do this? Let’s assume we’re writing software for a multiplayer game server. In that case, we may not want to instantiate a new copy of the DeckFactory class for each player. Instead, using the singleton pattern, we can guarantee that only one instance of the class exists in the entire system.
Likewise, if we need a system to assign unique numbers to objects, such as orders in a restaurant, we can create a singleton class that assigns those numbers across all of the point of sale systems in the entire store. This might be useful in your ongoing class project.
Let’s review three other commonly used software design patterns. These are either patterns that we’ve seen before, or ones that we might end up using soon in our code.
The first pattern is the iterator pattern. The iterator pattern is a behavioral pattern that is used to traverse through a collection of objects stored in a container. We explored this pattern in several of the data structures introduced in earlier data structures courses such as CC 310 and CC 315, as well as CIS 300.
In it’s simplest form, the iterator pattern simply includes a hasNext() and next() method, though many implementations may also include a way to reset the iterator back to the beginning of the collection.
Classes that use the iterator can use the hasNext() method to determine if there are additional elements in the collection, and then the next() method is used to actually access that element.
In the examples below, we’ll rely on the built-in collection classes in Java and Python to provide their own iterators, but if we must write our own collection class that doesn’t use the built-in ones, we can easily develop our own iterators using documentation found online.
In Java, classes can implement the Iterable interface, which requires them to return an Iterator object. In doing so, these objects can then be used in the Java enhanced for or for each loop.
import java.lang.Iterable;
import java.util.Iterator;
import java.util.List;
import java.util.LinkedList;
public class Deck implements Iterable<Card> {
List<Card> deck;
public Deck() {
deck = new LinkedList<>();
}
@Override
public Iterator<Card> iterator() {
return deck.iterator();
}
public int size() {
return this.deck.size();
}
}Here, we are making use of the fact that the Java collections classes, such as LinkedList, already implement the Iterable interface, so we can just return the iterator from the collection contained in our object. Even though it is not explicitly required by the Iterable interface, it is also a good idea to implement a size() method to return the size of our collection.
With this code in place, we can iterate through the deck just like any other collection:
public class CardGame{
public static void main(String[] args) {
String deckType = "Standard 52";
Deck cards = DeckFactory.getInstance().getDeck((DeckType.valueOf(deckType)));
for(Card card : cards) {
// do something with each card
}
}
}In Python, we can simply provide implementation for the __iter__() method in a class to return an iterator object, and that iterator object should implement the __next__() method to get the next item, as well as the __iter__() method, which just returns the iterator itself. Python does not define an equivalent to the has_next() method; instead, the __next__() method should raise a StopIteration exception when the end of the collection is reached.
For the purposes of type checking, we can use the Iterator type and the Iterable parent class (which works similar to an interface).
from typing import Iterable, Iterator
class Deck(Iterable[Card]):
def __init__(self) -> None:
self._deck: List[Card] = list()
def __iter__(self) -> Iterator[Card]:
return iter(self._deck)
def __len__(self) -> int:
return len(self._deck)
def __getitem__(self, position: int) -> Card:
return self._deck[position]Here, we are making use of the fact that the built-in Python data types, such as list and dictionary, already implement the __iter__() method, so we can just return the iterator obtained by calling iter() on the collection.
In addition, we’ve also implemented the __len__() and __getitem__() magic methods, or “dunder methods”, that help our class act more like a container. With these, we can use len(cards) to get the number of cards in a Deck instance, and likewise we can access each individual card using array notation, as in cards[0]. There are several other magic methods we may wish to implement, which are described in the link above.
With this code in place, we can iterate through the deck just like any other collection:
from typing import List
class CardGame:
@staticmethod
def main(args: List[str]) -> None:
deck_type: str = "Standard 52"
cards: Deck = DeckFactory.get_instance().get_deck(DeckType(deck_type))
for card in cards:
# do something with each cardSee Iterator on Python Design Patterns for more details.
Another pattern is the adapter pattern. The adapter pattern is a structural pattern that is used to make an existing interface fit within a different interface. Just like we might use an adapter when traveling abroad to allow our appliances to plug in to different electrical outlets around the world, the adapter pattern lets us use one interface in place of another, similar interface.
In the UML diagram above, we see two different approaches to using the adapter pattern. First, we see the object adapter, which simply stores an instance of the object to be adapted, and then translates the incoming method calls (or messages) to match the appropriate ones available in the object it is adapting.
The other approach is the class adapter, which typically works by subclassing or inheriting the class to be adapted, if possible. Then, our code can call the operations on the adapter class, which can then call the appropriate methods in its parent class as needed.
Let’s look at a quick example to see how we can use the adapter pattern in our code.
Let’s assume we have a Pet class that is used to record information about our pets. However, the original class was written to use metric units, and we’d like our program to use the United States customary units system instead. In that case, we could use the adapter pattern to adapt this class for our use.
To make it simple, we’ll assume that our Pet class includes attributes weight, measured in kilograms, as well as age, measured in years. Each of those attributes includes getters and setters in the Pet class.
First, let’s look at the adapter pattern using the object adapter approach. In this case, our adapter will store an instance of the Pet class as an object, and then use its methods to access methods within the encapsulated object.
import java.lang.Math;
public class PetAdapter{
private Pet pet;
public PetAdapter() {
this.pet = new Pet();
}
public int getWeight() {
// convert kilograms to pounds
return Math.round(this.pet.getWeight() * 2.20462);
}
public void setWeight(int pounds) {
// convert pounds to kilograms
this.pet.setWeight(Math.round(pounds * 0.453592));
}
public int getAge() {
// no conversion needed
return this.pet.getAge();
}
public void setAge(int years) {
// no conversion needed
this.pet.setAge(years);
}
}class PetAdapter:
def __init__(self) -> None:
self.__pet = Pet()
@property
def weight(self) -> int:
# convert kilograms to pounds
return round(self.__pet.weight * 2.20462)
@weight.setter
def weight(self, pounds: int) -> None:
# convert pounds to kilograms
self.__pet.weight = round(pounds * 0.453592)
@property
def age(self) -> int:
# no conversion needed
return self.__pet.age
@age.setter
def age(self, years: int) -> None:
# no conversion needed
self.__pet.age = yearsAs we can see, we can easily write methods in our PetAdapter class that perform the conversions needed and call the appropriate methods in the Pet object contained in the class.
The other approach we can use is the class adapter approach. Here, we’ll inherit from the Pet class itself, and implement any updated methods.
import java.lang.Math;
public class PetAdapter extends Pet{
public PetAdapter() {
super();
}
@Override
public int getWeight() {
// convert kilograms to pounds
return Math.round(super.getWeight() * 2.20462);
}
@Override
public void setWeight(int pounds) {
// convert pounds to kilograms
super.setWeight(Math.round(pounds * 0.453592));
}
// Age methods are already inherited and don't need adapted
}class PetAdapter(Pet):
def __init__(self) -> None:
super().__init__()
@property
def weight(self) -> int:
# convert kilograms to pounds
return round(super().weight * 2.20462)
@weight.setter
def weight(self, pounds: int) -> None:
# convert pounds to kilograms
super().weight = round(pounds * 0.453592)
# Age methods are already inherited and don't need adaptedIn this approach, we override the methods that need adapted in our subclass, but leave the rest of them alone. So, since the age getter and setter can be inherited from the parent Pet class, we don’t need to include them in our adapter class.
The last pattern we’ll review in this course is the template method pattern. The template method pattern is a pattern that is used to define the outline or skeleton of a method in an abstract parent class, while leaving the actual details of the implementation to the subclasses that inherit from the parent class. In this way, the parent class can enforce a particular structure or ordering of the steps performed in the method, making sure that any subclass will behave similarly.
In this way, we avoid the problem of the subclass having to include large portions of the code from a method in the parent class when it only needs to change one aspect of the method. If that method is structured as a template method, then the subclass can just override the smaller portion that it needs to change.
In the UML diagram above, we see that the parent class contains a method called templateMethod(), which will in part call primitive1() and primitive2() as part of its code. In the subclass, the code for the two primative methods can be overridden, changing how parts of the templateMethod() works, but not the fact that primitive1() will be called before primitive2() within the templateMethod().
Let’s look at a quick example. For this, we’ll go back to our prior example involving decks of cards. The process of preparing for most games is the same, and follows these three steps:
Then, each individual game can modify that process a bit based on the rules of the game. So, let’s see what that might look like in code.
import java.util.List;
public abstract class CardGame {
protected int players;
protected Deck deck;
protected List<List<Card>> hands;
public CardGame(int players) {
this.players = players;
}
public void prepareGame() {
this.getDeck();
this.prepareDeck();
this.dealCards(this.players);
}
protected abstract void getDeck();
protected abstract void prepareDeck();
protected abstract void dealCards(int players);
}from abc import ABC, abstractmethod
from typing import List, Optional
class CardGame(ABC):
def __init__(self, players: int) -> None:
self._players = players
self._deck: Optional[Deck] = None
self._hands: List[List[Card]] = list()
def prepare_game(self) -> None:
self._get_deck()
self._prepare_deck()
self._deal_cards(self._players)
@abstractmethod
def _get_deck(self) -> None:
raise NotImplementedError
@abstractmethod
def _prepare_deck(self) -> None:
raise NotImplementedError
@abstractmethod
def _deal_cards(self, players: int) -> None:
raise NotImplementedErrorFirst, we create the abstract CardGame class that includes the template method prepareGame(). It calls three abstract methods, getDeck(), prepareDeck(), and dealCards(), which need to be overridden by the subclasses.
Next, let’s explore what this subclass might look like for the game Hearts. That game consists of 4 players, uses a standard 52 card deck, and deals 13 cards to each player.
import java.util.LinkedList;
public class Hearts extends CardGame {
public Hearts() {
// hearts always has 4 players.
super(4);
}
@Override
public void getDeck() {
this.deck = DeckFactory.getInstance().getDeck(DeckType.valueOf("Standard 52"));
}
@Override
public void prepareDeck() {
this.deck.suffle();
}
@Override
public void dealCards {
this.hands = new LinkedList<>();
for (int i = 0; i < this.players; i++) {
LinkedList<Card> hand = new LinkedList<>();
for (int i = 0; i < 13; i++) {
hand.add(this.deck.draw());
}
this.hands.add(hand);
}
}
}from typing import List
class Hearts(CardGame):
def __init__(self):
# hearts always has 4 players
super().__init__(4)
def _get_deck(self) -> None:
self._deck: Deck = DeckFactory.get_instance().get_deck(DeckType("Standard 52"))
def _prepare_deck(self) -> None:
self._deck.shuffle()
def _deal_cards(self, players: int) -> None:
self._hands: List[List[Card]] = list()
for i in range(0, players):
hand: List[Card] = list()
for i in range(0, 13):
hand.append(self._deck.draw())
self._hands.append(hand)Here, we can see that we implemented the getDeck() method to get a standard 52 card deck. Then, in the prepareDeck() method, we shuffle the deck, and finally in the dealCards() method we populate the hands attribute with 4 lists of 13 cards each. So, whenever anyone uses this Hearts subclass and calls the prepareGame() method that is defined in the parent CardGame class, it will properly prepare the game for a standard game of Hearts.
To adapt this to another type of game, we can simply create a new subclass of CardGame and update the implementations of the getDeck(), prepareDeck() and dealCards() methods to match.
In this chapter, we explored several software design patterns introduced by the “Gang of Four” in their 1994 book: Design Patterns: Elements of Reusable Object-Oriented Software. Design patterns are a great way to build our code using reusable, standard structures that can solve a particular problem or perform a particular task. By using structures that are familiar to other developers, it makes it easier for them to understand our code.
Software design patterns are loosely grouped into three categories:
We studied 6 different design patterns. The first three were creational patterns:
We also studied a structural pattern:
Finally, we looked at two behavioral patterns:
In the future, we can use these patterns in our code to solve specific problems and hopefully make our program’s structure easier for other developers to understand.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.
Mimicking and making a “mock"ery of testing!
Earlier in this course, we learned about unit testing and how we can write code to help us verify that parts of our program are performing as intended. However, what if the portion of our program we’d like to test depends on other parts working correctly? In that case, any errors in our tests might be due to our code having a bug, but it could also be due to a bug in another part of the program that our code depends on.
So, we need some way to test parts of our code in isolation from the rest of the program. In that way, we can make sure our code is working as intended, even if the parts it depends on to function aren’t working.
Enter test doubles - items such as stubs, fakes and mocks - which are temporary objects we can include in our unit tests to mimic, or “double,” the functionality of another part in our program. In that way, we can write our test as if the other portion is working, regardless of whether it is or not.
In this chapter, we’ll learn about the following key terms and ideas:
We’ll also see a brief example for how to create and use some of these items in our chosen programming language. After reviewing this content, we should be able to use some test doubles in our own unit test code.
As we build larger and larger applications, we may find that it becomes more and more difficult to see the entire application as a whole. Instead, it helps to think of the application as many different modules, and each module interacts with others based on their publicly available methods, which make up the application programming interface or API of the module.
Ideally, we’d like each module of the program to be independent from the others, with each one having a clear purpose or reason for inclusion in the program. This is a key part of the design principle separation of concerns, which involves breaking larger systems down into distinct sections that address a particular “concern” within the larger system.
So, by categorizing the individual classes in our application based on similarity, we can then start to organize our application into modules of code that are somewhat independent of each other. They still interact through the public APIs of each module, but the internal workings of one module should not be visible to another.
Once we start writing unit tests for our code, we can start to abstract away the details of other modules in the system, and focus just on the internal workings of the single unit of code, usually a class or method, that we intend to test.
However, this is difficult when our code has to call methods that are present in another module. How can we test our code and make sure it works, without also having to test that the module it is calling also works correctly and returns a correct value? If we cannot figure out a way to do this, then unit testing our code is not very helpful since it won’t allow us to accurately pinpoint the location of an error.
This is where the concept of test doubles comes in. Let’s say our code needs to call a method called getArea() that is part of the API of another module, which will calculate the area of a given shape. All our code needs to do is compare the returned value of that method with a few key values, and display a result.
Depending on the shape, calculating the area can be a computationally intensive process, so we probably don’t want to do that many times in our unit tests. In addition, since that method is contained in another module, we definitely don’t want to test that it actually returns the correct answer.
Instead, we just know that the API of that module says that the getArea() method will return a floating-point value that is non-negative. This is a postcondition that is well documented in the API, so as long as that module is working correctly, we know that the getArea() method will return some non-negative floating-point value.
Therefore, instead of calling the getArea() method that is contained in the external module, we can create a stub method that simply returns a non-negative floating-point value. Then, whenever our code calls getArea(), we can intercept that message and direct it instead to our stub method, which quickly returns a valid value that we can use in our tests. We can even modify the stub to return either the exact values we want, or just any random value.
There are many more powerful things we can do with these test doubles, such as:
Test doubles are a crucial part of writing more useful and advanced unit tests, especially as our programs become larger and we wish to test portions of the code that are integrated with other modules.
Most of our unit tests have been following a particular pattern, commonly called arrange, act, assert. Let’s quickly review that pattern, as it is very important to understand how it integrates with the use of test doubles later in this chapter.
A simple unit test following the arrange, act, assert pattern consists of three major steps:
In some instances, we may also include a fourth step, Teardown, which is used to reset the state back to its initial state, if needed. There are times when our arrange step makes some changes to the environment that must be reversed before we can continue.
Let’s go back to a unit test you may have explored in example 3 and see how it fits the arrange, act, assert pattern.
@Test
public void testSevenWrongGuessesShouldLose() {
// Arrange
GuessingGame game = new GuessingGame("secret");
// Act
game.guess('a');
game.guess('b');
game.guess('d');
game.guess('f');
game.guess('g');
game.guess('h');
game.guess('i');
// Assert
assertTrue(game.isLost());
}def test_seven_wrong_guesses_should_lose(self):
# Arrange
game = GuessingGame("secret")
# Act
game.guess('a')
game.guess('b')
game.guess('d')
game.guess('f')
game.guess('g')
game.guess('h')
game.guess('i')
# Assert
assert game.lostIn both of these tests, we start in the arrange portion by instantiating a GuessingGame object, which is the object we will be testing. Then, in the act phase, we call several methods in the GuessingGame object - in this case, we are checking that seven incorrect guesses should cause the game to be lost, so we must make seven incorrect guesses. Finally, in the assert section, we use a simple assertion to make sure the game has been lost.
One common alternative to this approach comes from behavior-driven development. In this development process, which is effectively an extension of the test-driven development process we’ve learned about, software specifications are written to match the behaviors that a user might expect to see when the application is running. Such a specification typically follows a given, when, then structure. Here’s a short example of a specification from Wikipedia.
Given a 5 by 5 game
When I toggle the cell at (3, 2)
Then the grid should look like
.....
.....
.....
..X..
.....The beauty of such a specification is that it can be easily read by a non-technical user, and allows quick and easy discussion with end users and clients regarding how the software should actually function. Once the specification is developed, we can then write unit tests that will use the specification and verify that the program operates as intended. Here’s an example from Wikipedia in Java using the JBehave framework.
private Game game;
private StringRenderer renderer;
@Given("a $width by $height game")
public void theGameIsRunning(int width, int height) {
game = new Game(width, height);
renderer = new StringRenderer();
game.setObserver(renderer);
}
@When("I toggle the cell at ($column, $row)")
public void iToggleTheCellAt(int column, int row) {
game.toggleCellAt(column, row);
}
@Then("the grid should look like $grid")
public void theGridShouldLookLike(String grid) {
assertThat(renderer.asString(), equalTo(grid));
}This testing strategy requires a bit more work than the unit testing we’ve covered in this course, but it can be very powerful when put into use.
Unfortunately, the naming of many of these test doubles, such as stubs, mocks, and fakes, are used either inconsistently or interchangeably within different systems, documentation, and other resources. I’m going to stick to one particular naming scheme, which is best described in the resources linked earlier in this chapter. However, in practice, these terms may be used differently in different areas.
There are three major types of test doubles that we’ll cover in this chapter. The first are stubs, sometimes referred to as stub methods or method stubs. A stub is simply an object that is used to return predefined data when its methods are called, without any internal logic.
For example, if the methods we are testing should sum up the data that results from several calls to a method that is outside of our module, we could create a stub that simply returns the values 1 - 5, and then verify that our method calculates the sum of 15. In this way, we’re verifying that our code works as intended (it sums the values), without really worrying whether the other module returns correct data or not.
The only thing we must be careful with when creating these stubs is that the data they return is plausible for the test we are performing. If the data should be valid, then we should be careful to return values that are the correct type and within the correct range. Likewise, if we want to test any possible error conditions or invalid values, we’ll have to make sure our stub returns the appropriate values as the real object would.
Another commonly used test double is a fake, sometimes referred to as a fake object. A fake is an object that implements the same external interface that the real object would implement - it includes all of the same publicly available methods and attributes. However, the implementations of those methods may take certain shortcuts to mimic pieces of functionality that are not really needed in order to produce valid results. (Many test frameworks use the term mock object for the same concept; however, we’ll use that term on the next page for a slightly different use.)
For example, if we have an object responsible for storing data in a database, we could create a fake version of it that can store data in a hash table instead. It will still be able to store objects and retrieve them, but instead of using a real database with millions of records, it will just store a few items in a hash table that can be reloaded for each unit test.
Likewise, if the object performs a long, complex calculation, a fake version of the object might include precomputed data that can be quickly returned without performing the computation. In that way, the data stored in the object corresponds to the results it provides, without the need to perform any costly computational steps during each unit test.
The third type of test double we’ll cover is the mock object, sometimes referred to as a test spy. A mock object is typically used to verify that our code performs the correct actions on other parts of the system. Usually, the mock object will simply listen for any incoming method calls, and then once our action is complete we can verify that the correct methods were called with the correct inputs by examining our mock object.
For example, if the code we are testing is responsible for calling a method in another module to update the GUI for our application, we can replace that GUI with a mock object, run the code, and then verify that the correct method in our mock object was called during the test. Likewise, we can make sure that other methods were not called.
This is another great example of an “indirect output” of our code. However, instead of data being the output, the messages sent as method calls are the data that our code is producing.
As we can see, test doubles are powerful tools we can use to enhance our ability to perform unit tests on our system. On the following pages, we’ll briefly review how to use different test doubles in both Java and Python. As always, feel free to skip to the page for the language you are learning, but both pages may contain helpful information.
To create test doubles in JUnit, we’ll rely on a separate library called Mockito. Mockito is a framework for creating mock objects in Java that works well with JUnit, and has become one of the most commonly used tools for this task.
To install Mockito, we just update the testImplementation line in our build.gradle file to include both the mockito-inline library, as well as the mockito-junit-jupiter library that allows Mockito and JUnit to work together seamlessly.
dependencies {
// Use JUnit Jupiter API for testing.
testImplementation 'org.junit.jupiter:junit-jupiter-api:5.6.2', 'org.hamcrest:hamcrest:2.2', 'org.junit.jupiter:junit-jupiter-params', 'org.mockito:mockito-inline:3.8.0', 'org.mockito:mockito-junit-jupiter:3.8.0'
// Use JUnit Jupiter Engine for testing.
testRuntimeOnly 'org.junit.jupiter:junit-jupiter-engine'
// This dependency is used by the application.
implementation 'com.google.guava:guava:29.0-jre'
}There are many different ways to use Mockito with JUnit. One of the easiest ways that works in the latest versions of Mockito and JUnit is to use the @ExtendWith annotation above our test class:
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.when;
import org.junit.jupiter.api.Test;
import org.junit.jupiter.api.extension.ExtendWith;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoExtension;
@ExtendWith(MockitoExtension.class)
public class UnitTestClass {
// tests here
}By including that annotation above our test class declaration, Mockito will automatically perform any setup steps required. In earlier versions of JUnit and Mockito, we would have to do these steps manually, but this process has been greatly simplified recently.
One thing we can do is modify this a bit to set Mockito to use STRICT_STUBS. This tells Mockito to print errors when we create any test doubles that aren’t used, and the ones that are used are created properly. So, instead of using @ExtendWith, we can instead use @MockitoSettings:
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.when;
import org.junit.jupiter.api.Test;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoSettings;
import org.mockito.quality.Strictness;
@MockitoSettings(strictness = Strictness.STRICT_STUBS)
public class UnitTestClass {
// tests here
}Since this is recommended by the Mockito documentation, we’ll go ahead and use it in our code.
Once we’ve added Mockito to our test class, we can create fake objects using the @Mock annotation above object declarations. This is commonly done on global objects in our test class:
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.when;
import org.junit.jupiter.api.Test;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoSettings;
import org.mockito.quality.Strictness;
@MockitoSettings(strictness = Strictness.STRICT_STUBS)
public class UnitTestClass {
@Mock
Person mockPerson;
@Mock
Teacher mockTeacher;
// tests here
}This will create fake objects that mimic the attributes and methods contained in the Person and Teacher class. However, by default, those objects won’t do anything, and most methods will just return the default value for the return type of the method.
Without doing anything else, we can use these fake objects in place of the real ones, as in this test:
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.when;
import org.junit.jupiter.api.Test;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoSettings;
import org.mockito.quality.Strictness;
@MockitoSettings(strictness = Strictness.STRICT_STUBS)
public class ClassroomTest {
@Mock
Person mockPerson;
@Mock
Teacher mockTeacher;
public void testClassroomHasTeacher() {
Classroom classroom = new Classroom()
assertTrue(classroom.hasTeacher() == false);
classroom.addTeacher(mockTeacher);
assertTrue(classroom.hasTeacher() == true);
}
}As we can see, we are able to add the mockTeacher object to our classroom, and it is treated just like any other Teacher object, at least as far as the system is concerned thus far.
However, if we want those fake objects to do something, we have to include method stubs as well.
To add a method stub to a fake object, we can use the when method in Mockito. Here’s an example:
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.when;
import org.junit.jupiter.api.Test;
import org.mockito.Mock;
import org.mockito.junit.jupiter.MockitoSettings;
import org.mockito.quality.Strictness;
@MockitoSettings(strictness = Strictness.STRICT_STUBS)
public class ClassroomTest {
@Mock
Person mockPerson;
@Mock
Teacher mockTeacher;
@Test
public void testClassroomGetTeacherName() {
// create a method stub for `getName`
when(mockTeacher.getName()).thenReturn("Teacher Person");
Classroom classroom = new Classroom();
classroom.addTeacher(mockTeacher);
// assert that the classroom returns the teacher's name
assertTrue(classroom.getTeacherName().equals("Teacher Person"));
}
}In this example, we are adding a method stub to our mockTeacher object that will return "Teacher Person" whenever the getName() method is called. Then, we are adding that fake Teacher object to the Classroom class that we are testing, and calling the getTeacherName() method. We’re assuming that the getTeacherName() method in the Classroom class calls the getName() method of the Teacher object contained in the class. However, instead of using a real Teacher instance, we’ve provided a fake object that only knows what to do when that one method is called. So, it returns the value we expect, which passes our test!
There is one more complex use case we may run into in our testing - creating a fake version of a class with static methods. This is a relatively new feature in Mockito, but it allows us to test some functionality that is otherwise very difficult to mimic.
import static org.junit.jupiter.api.Assertions.assertThrows;
import static org.junit.jupiter.api.Assertions.assertTrue;
import static org.mockito.Mockito.when;
import java.lang.IllegalArgumentException;
import org.junit.jupiter.api.Test;
import org.mockito.Mock;
import org.mockito.MockedStatic;
import org.mockito.Mockito;
import org.mockito.junit.jupiter.MockitoSettings;
import org.mockito.quality.Strictness;
@MockitoSettings(strictness = Strictness.STRICT_STUBS)
public class ClassroomTest {
@Mock
Person mockPerson;
@Mock
Teacher mockTeacher;
@Test
public void testTeacherFailsMinimumAgeRequirement() {
// Create mock static class
try (MockedStatic<TeacherRules> mockTeacherRules = Mockito.mockStatic(TeacherRules.class)) {
// Create method stub for static class
mockTeacherRules.when(() -> TeacherRules.getMinAge()).thenReturn(16);
// Create method stub for fake Teacher
when(mockTeacher.getAge()).thenReturn(15);
// Test functionality
Classroom classroom = new Classroom();
assertThrows(IllegalArgumentException.class, () -> classroom.addTeacher(mockTeacher));
}
}
}In this example, we have a TeacherRules class that includes a static method getMinAge() that returns the minimum age allowed for a teacher. To test this, we are creating a fake version of that class using the Mockito.mockStatic() method. We have to do this in a try with resources statement, which makes sure that the fake class does not persist outside of this test.
Once we’ve created the fake class mockTeacherRules, we can add a method stub for the static method. We’ll also add a method stub to return an invalid age on our fake Teacher object. Finally, when we try to add that teacher to a classroom, it should throw an exception since the teacher is not old enough.
This is a very brief introduction to using test doubles made with Mockito, but it should be enough for our use in this class. Feel free to refer to some of the documentation linked below for more examples and information.
To create test doubles in Python, we’ll rely on the built-in unittest.mock library. It includes lots of quick and easy methods for creating fake objects in Python, and it is compatible with the pytest testing framework that we’re already using.
There are many different ways to use the unittest.mock library. One of the easiest ways is to import the patch annotation
from unittest.mock import patch
class TestClassroom:
# tests here
Once we’ve imported the patch annotation, we can use it to create fake objects for our test methods.
from unittest.mock import patch
from people.Person import Person
from people.Teacher import Teacher
from places.Classroom import Classroom
class TestClassroom:
@patch('people.Teacher', spec=Teacher)
@patch('people.Person', spec=Person)
def test_classroom_has_teacher(self, fake_person, fake_teacher) -> None:
# test code
This will create fake objects fake_person and fake_teacher that mimic the attributes and methods contained in the Person and Teacher classes, respectively. However, by default, those objects won’t do anything, and most methods will not actually work by default.
Notice that the fake objects are added as parameters to our test method, but they are added in reverse order. This is because method annotations are interpreted “inside-out”, so the one at the bottom, closest to the method, is interpreted first. So, in this example, our fake_person will be created first, followed by our fake_teacher.
Without doing anything else, we can use these fake objects in place of the real ones, as in this test:
from unittest.mock import patch
from people.Person import Person
from people.Teacher import Teacher
from places.Classroom import Classroom
class TestClassroom:
@patch('people.Teacher', spec=Teacher)
@patch('people.Person', spec=Person)
def test_classroom_has_teacher(self, fake_person, fake_teacher) -> None:
classroom: Classroom = Classroom()
assert classroom.has_teacher == False
classroom.add_teacher(fake_teacher)
assert classroom.has_teacher == True As we can see, we are able to add the fake_teacher object to our classroom, and it is treated just like any other Teacher object, at least as far as the system is concerned thus far.
However, if we want those fake objects to do something, we have to include method stubs as well.
To add a method stub to a fake object, we can set the return_value of the method:
from unittest.mock import patch
from people.Person import Person
from people.Teacher import Teacher
from places.Classroom import Classroom
class TestClassroom:
@patch('people.Teacher', spec=Teacher)
@patch('people.Person', spec=Person)
def test_classroom_get_teacher_name(self, fake_person, fake_teacher) -> None:
# create a method stub for `get_name` method
fake_teacher.get_name.return_value = "Teacher Person"
classroom: Classroom = Classroom()
classroom.add_teacher(fake_teacher)
# assert that the classroom returns the teacher's name
assert classroom.get_teacher_name() == "Teacher Person"In this example, we are adding a method stub to our fake_teacher object that will return "Teacher Person" whenever the get_name() method is called. Then, we are adding that fake Teacher object to the Classroom class that we are testing, and calling the get_teacher_name() method. We’re assuming that the get_teacher_name() method in the Classroom class calls the get_name() method of the Teacher object contained in the class. However, instead of using a real Teacher instance, we’ve provided a fake object that only knows what to do when that one method is called. So, it returns the value we expect, which passes our test!
If our classes use properties instead of traditional getter and setter methods, we have to create our property stubs in a slightly different way:
from unittest.mock import patch, PropertyMock
from people.Person import Person
from people.Teacher import Teacher
from places.Classroom import Classroom
class TestClassroom:
@patch('people.Teacher', spec=Teacher)
@patch('people.Person', spec=Person)
def test_classroom_get_teacher_name(self, fake_person, fake_teacher) -> None:
# create a property stub for `get_name` property
type(fake_teacher).name = PropertyMock(return_value="Teacher Person")
classroom: Classroom = Classroom()
classroom.add_teacher(fake_teacher)
# assert that the classroom returns the teacher's name
assert classroom.get_teacher_name() == "Teacher Person"In this case, we are creating an instance of the PropertyMock class that acts as a fake property for an object. However, because of how fake objects work, we cannot directly attach the PropertyMock instance directly to the fake_teacher object. Instead, we must attach it to the mock type object, which we can access by using the type method. Thankfully, even if we have several fake instances of the same class, these properties will be unique to the fake instance, not to the class they are faking.
There is one more complex use case we may run into in our testing - creating a fake version of a class with static methods.
from unittest.mock import patch, PropertyMock
from people.Person import Person
from people.Teacher import Teacher
from places.Classroom import Classroom
from rules.TeacherRules import TeacherRules
import pytest
class TestClassroom:
@patch('people.Teacher', spec=Teacher)
@patch('people.Person', spec=Person)
def test_teacher_fails_minimum_age_requirement(self, fake_person, fake_teacher) -> None:
# create a fake version of the static method
with patch.object(TeacherRules, 'get_minimum_age', return_value=16):
# Add a fake property to the teacher
type(fake_teacher).age = PropertyMock(return_value=15)
classroom: Classroom = Classroom()
with pytest.raises(ValueError):
classroom.add_teacher(fake_teacher)In this example, we have a TeacherRules class that includes a static method get_minimum_age() that returns the minimum age allowed for a teacher. To test this, we are creating a fake version of that static method using the patch.object method. We have to do this in a with statement, which makes sure that the fake method does not persist outside of this test. In this case, we’ll set that method to return a value of 16.
We’ll also add a method stub to return an invalid age on our fake Teacher object. Finally, when we try to add that teacher to a classroom, it should raise an exception since the teacher is not old enough.
This is a very brief introduction to using test doubles made with the unittest.mock library, but it should be enough for our use in this class. Feel free to refer to some of the documentation linked below for more examples and information.
One other important topic to cover in unit tests is dependency injection. In short, dependency injection is a way that we can build our classes so that the objects they depend on can be added to the class from outside. In that way, we can change them as needed in our unit tests as a way to test functionality using test doubles.
Consider the following example:
public class Teacher {
private Gradebook gradebook;
private List<Student> studentList;
public Teacher() {
this.gradebook = new Gradebook("Course Name");
this.studentList = new List<>();
}
public void addStudent(Student s) {
this.studentList.add(s);
}
public void submitGrades() {
for (Student s : this.studentList) {
this.gradebook.gradeStudent(s);
}
}
}class Teacher:
def __init__(self) -> None:
self.__gradebook: Gradebook = Gradebook()
self.__student_list: List[Student] = list()
def add_student(self, s: Student) -> None:
self.__student_list.append(s)
def submit_grades(self) -> None:
for s in self.__student_list:
self.__gradebook.grade_student(s)In this Teacher class, we see a private Gradebook instance. That instance is not accessible outside the class, so we cannot directly interact with it in our unit tests, at least without violating the security principles of the class it is in. So, if we want to test that the submitGrades() method properly grades every student in the studentList, we would need some way to replace the gradebook attribute with a test double.
This is where dependency injection comes in. Instead of allowing this class to instantiate its own gradebook, we can restructure the code to inject our own gradebook instance. There are several ways we can do this.
Of course, one way we could accomplish this, even without dependency injection, would be to simply reduce the security of these objects. In Java, we could make them either public, which is generally a bad idea for something so secure as a gradebook, or package-private, with no modifier. We’ve used the package-private trick in one of the earlier example videos to access some GUI elements, but in this case we probably want something better.
In Python, we know that any attribute can be accessed externally, so this isn’t as big of a concern. However, since we are using a double-underscore in the name, we’d have to get around the name mangling. We could switch it to a single underscore, which is still marked as internal to the class but would at least be more easily accessible to our tests. However, as with the Java example, there are other ways we could accomplish this.
The first method of dependency injection is via the constructor. We could simply pass in a reference to a Gradebook object in the constructor, as in this example:
public Teacher(Gradebook grade) {
if (grade == null) {
throw new IllegalArgumentException("Gradebook cannot be null")
}
this.gradebook = grade
this.studentList = new List<>();
}def __init__(self, grade: Gradebook) -> None:
if grade is None:
raise ValueError("Gradebook cannot be None")
self.__gradebook: Gradebook = grade
self.__student_list: List[Student] = list()The benefit of this approach is that we can easily replace an actual Gradebook instance in our unit tests with any test double we’d like, making it every easy to test the submitGrades() method.
Unfortunately, this does require any class that instantiates a Teacher object to also instantiate a Gradebook along with it, making that process more complex. This complexity can be reduced using some design patterns such as the builder pattern or factory method pattern.
Finally, the class that instantiates the Teacher object would also have a reference to the Gradebook that teacher is using, so it could allow a malicious coder to have access to data that should be kept private. However, typically this isn’t a major concern we worry about, since we must always assume that any programmer on this project could access any data stored in a class, as nothing is truly private as we’ve already discussed.
Alternatively, we can provide a setter method and allow injection via the setter. This could be done either in lieu of building a Gradebook object in the constructor, or in addition to it.
public void setGradebook (Gradebook grade) {
if (grade == null) {
throw new IllegalArgumentException("Gradebook cannot be null")
}
this.gradebook = grade;
}def set_gradebook(grade: Gradebook) -> None:
if grade is None:
raise ValueError("Gradebook cannot be None")
self.__gradebook: Gradebook = grade`You may recognize this approach from several earlier courses in this program - we use this technique for grading some of the data structures and programs by injecting our own data and seeing how your code interacts with it. We typically include debug in the name of these methods, to make it clear that they are only for debugging and should be removed from the final code.
In addition to the three methods listed above, there are some other ways we can accomplish this:
Many of these are discussed in greater detail in the dependency injection article on Wikipedia.
In general, we want to build our code in a way that it can easily be tested, and that means providing some way to perform dependency injection that doesn’t interfere with the normal operation of our program.
Here are some quick tips that you may be able to use when you need to implement dependency injection:
Dependency injection is a very powerful testing technique, but one that must be used carefully to prevent introducing additional bugs and complexity to your application.
In this chapter, we learned about test doubles and how they can use them in our unit tests to mimic functionality from other parts of our program. In short, there are three different common types of test doubles:
We also explored how we can use these in our code both Java and Python. Finally, we learned about dependency injection and how we can use that technique to place our test doubles directly in our classes. Now, we’ll be able to update the unit tests in our ongoing project to help separate the classes being tested from other classes that it depends on.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.