Data-Driven Websites
From desktop GUIs to the World Wide Web!
From desktop GUIs to the World Wide Web!
Up to this point, we’ve mainly focused on developing an application that can be executed locally on a computer. To use an application like this, users would have to download it and possibly install it on their system. Likewise, as developers, we’ll have to create a release that they can install, and we may have to make sure that the release is compatible with various different operating systems and computer architectures.
For decades, this was really the state of the art of computer programming. However, starting in the 2000s, things began to drastically change with the rise of Web 2.0 and interactive website. Soon, a whole new type of application, the web application, became commonplace.
Today, outside of video games and a few specialized applications, many computer users primarily interact with web applications instead of applications installed locally on their computer. Some great examples are the various social media sites such as Facebook and YouTube, productivity tools such as Microsoft Office 365 or Google Drive, and even communication platforms such as Slack and Discord.
To make things even more complicated, many of those web applications include versions that you can install and run locally on your computer or smartphone, but in many cases they are simply a lightweight wrapper around the web application. In that way, it appears to be running as a local application, but it is really just a version of the same web application that is stored locally.
In this chapter, we’re going to pivot our focus to building a web application. To do that, we’ll have to introduce many new concepts to lay the foundation for working in the web, so there will be lots of new content and ideas in this chapter.
Some key terms that we’ll cover:
At the end of this chapter, you’ll be able to generate your own data driven web pages using a web framework and its built-in templating engine!
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
The World Wide Web was the brainchild of Sir Tim Berners-Lee. It was conceived as a way to share information across the Internet; in Sir Berners-Lee’s own words describing the idea as he first conceived it:
This project is experimental and of course comes without any warranty whatsoever. However, it could start a revolution in information access.
Clearly that revolution has come to pass. The web has become part of our daily lives.
There were three key technologies that Sir Tim Berners-Lee proposed and developed. These remain the foundations upon which the web runs even today. Two are client-side, and determine how web pages are interpreted by browsers. These are:
Hypertext Markup Language (HTML), is one of the three core technologies of the world wide web, along with Cascading Style Sheets (CSS) and Javascript (JS). Each of these technologies has a specific role to play in delivering a website. HTML defines the structure and contents of the web page. It is a markup language, similar to XML (indeed, HTML is based on the SGML, or Standardized General Markup Language, standard, which XML is also based on).
The structure of HTML consists of various tags. For example, a button in HTML looks like this:
<button onclick="doSomething">
Do Something
</button>HTML elements have and opening and closing tag, and can have additional HTML content nested inside these tags. HTML tags can also be self-closing, as is the case with the line break tag:
<br />Let’s explore the parts of an HTML element in more detail.
The start tag is enclosed in angle brackets (< and >). The angle brackets differentiate the text inside them as being HTML elements, rather than text. This guides the browser to interpret them correctly.
Because angle brackets are interpreted as defining HTML tags, you cannot use those characters to represent greater than and less than signs. Instead, HTML defines escape character sequences to represent these and other special characters. Greater than is >, less than is <. A full list can be found on mdn.
Immediately after the < is the tag name. In HTML, tag names like button should be expressed in lowercase letters. This is a convention (as most browsers will happily accept any mixture of uppercase and lowercase letters), but is very important when using popular modern web technologies like Razor and React, as these use Camel case tag names to differentiate between HTML and components they inject into the web page.
After the tag name come optional attributes, which are key-value pairs expressed as key="value". Attributes should be separated from each other and the tag name by whitespace characters (any whitespace will do, but traditionally spaces are used). Different elements have different attributes available - and you can read up on what these are by visiting the MDN article about the specific element.
However, several attributes bear special mention:
The id attribute is used to assign a unique id to an element, i.e. <button id="that-one-button">. The element can thereafter be referenced by that id in both CSS and JavaScript code. An element ID must be unique in an HTML page, or unexpected behavior may result!
The class attribute is also used to assign an identifier used by CSS and JavaScript. However, classes don’t need to be unique; many elements can have the same class. Further, each element can be assigned multiple classes, as a space-delimited string, i.e. <button class="large warning"> assigns both the classes “large” and “warning” to the button.
Also, some web technologies (like Angular) introduce new attributes specific to their framework, taking advantage of the fact that a browser will ignore any attributes it does not recognize.
The content nested inside the tag can be plain text, or another HTML element (or collection of elements). HTML elements can have multiple child elements. Indentation should be used to keep your code legible by indenting any nested content, i.e.:
<div>
<h1>A Title</h1>
<p>This is a paragraph of text that is nested inside the div</p>
<p>And this is another paragraph of text</p>
</div>The end tag is also enclosed in angle brackets (< and >). Immediately after the < is a forward slash /, and then the tag name. You do not include attributes in a end tag.
If the element has no content, the end tag can be combined with the start tag in a self-closing tag, i.e. the <input> tag is typically written as self-closing:
<input id="first-name" type="text" placeholder="Your first name" />
Text in HTML works a bit differently than you might expect. Most notably, all white space is converted into a single space. Thus, the lines:
<blockquote>
If you can keep your head when all about you
Are losing theirs and blaming it on you,
If you can trust yourself when all men doubt you,
But make allowance for their doubting too;
If you can wait and not be tired by waiting,
Or being lied about, don’t deal in lies,
Or being hated, don’t give way to hating,
And yet don’t look too good, nor talk too wise:
<i>-Rudyard Kipling, exerpt from "If"</i>
</blockquote>Would be rendered:
If you can keep your head when all about you Are losing theirs and blaming it on you, If you can trust yourself when all men doubt you, But make allowance for their doubting too; If you can wait and not be tired by waiting, Or being lied about, don’t deal in lies, Or being hated, don’t give way to hating, And yet don’t look too good, nor talk too wise: -Rudyard Kipling, exerpt from "If"
If, for some reason you need to maintain formatting of the included text, you can use the <pre> element (which indicates the text is preformatted):
<blockquote>
<pre>
If you can keep your head when all about you
Are losing theirs and blaming it on you,
If you can trust yourself when all men doubt you,
But make allowance for their doubting too;
If you can wait and not be tired by waiting,
Or being lied about, don’t deal in lies,
Or being hated, don’t give way to hating,
And yet don’t look too good, nor talk too wise:
</pre>
<i>-Rudyard Kipling, exerpt from "If"</i>
</blockquote>Which would be rendered:
If you can keep your head when all about you
Are losing theirs and blaming it on you,
If you can trust yourself when all men doubt you,
But make allowance for their doubting too;
If you can wait and not be tired by waiting,
Or being lied about, don’t deal in lies,
Or being hated, don’t give way to hating,
And yet don’t look too good, nor talk too wise:
-Rudyard Kipling, exerpt from "If"
Note that the <pre> preserves all formatting, so it is necessary not to indent its contents.
Alternatively, you can denote line breaks with <br/>, and non-breaking spaces with :
<blockquote>
If you can keep your head when all about you<br/>
Are losing theirs and blaming it on you,<br/>
If you can trust yourself when all men doubt you,<br/>
But make allowance for their doubting too;<br/>
If you can wait and not be tired by waiting,<br/>
Or being lied about, don’t deal in lies,<br/>
Or being hated, don’t give way to hating,<br/>
And yet don’t look too good, nor talk too wise:<br/>
<i>-Rudyard Kipling, exerpt from "If"</i>
</blockquote>Which renders:
If you can keep your head when all about you
Are losing theirs and blaming it on you,
If you can trust yourself when all men doubt you,
But make allowance for their doubting too;
If you can wait and not be tired by waiting,
Or being lied about, don’t deal in lies,
Or being hated, don’t give way to hating,
And yet don’t look too good, nor talk too wise:
-Rudyard Kipling, exerpt from "If"
Additionally, as a program you may want to use the the <code> element in conjunction with the <pre> element to display preformatted code snippets in your pages. There are even some JavaScript libraries available to automatically add syntax colors to your code.
HTML comments are identical to XML comments (as both inherited from SGML). Comments start with the sequence <!-- and end with the sequence -->, i.e.:
<!-- This is an example of a HTML comment -->HTML5 (the current HTML standard) pages have an expected structure that you should follow. This is:
<!DOCTYPE html>
<html>
<head>
<title><!-- The title of your page goes here --></title>
<!-- other metadata about your page goes here -->
</head>
<body>
<!-- The contents of your page go here -->
</body>
</html>Rather than include an exhaustive list of HTML elements, I will direct you to the list provided by MDN. However, it is useful to recognize that elements can serve different purposes:
There are more tags than this, but these are the most commonly employed, and the ones you should be familiar with.
The MDN HTML Docs are recommended reading for learning more about HTML.
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
Cascading Style Sheets (CSS) is the second core web technology of the web. It defines the appearance of web pages by applying stylistic rules to matching HTML elements. CSS is normally declared in a file with the .css extension, separate from the HTML files it is modifying, though it can also be declared within the page using the <style> element, or directly on an element using the style attribute.
A CSS rule consists of a selector and a definition block, i.e.:
h1
{
color: red;
font-weight: bold;
}A CSS selector determines which elements the associated definition block apply to. In the above example, the h1 selector indicates that the style definition supplied applies to all <h1> elements. The selectors can be:
p applies to all <p> elements.#. I.e. the selector #foo applies to the element <span id="foo">... I.e. the selector .bar applies to the elements <div class="bar">, <span class="bar none">, and <p class="alert bar warning">.CSS selectors can also be combined in a number of ways, and psuedo-selectors can be applied under certain circumstances, like the :hover psudo-selector which applies only when the mouse cursor is over the element.
You can read more on MDN’s CSS Selectors Page.
A CSS definition block is bracketed by curly braces and contains a series of key-value pairs in the format key=value;. Each key is a property that defines how an HTML Element should be displayed, and the value needs to be a valid value for that property.
Measurements can be expressed in a number of units, from pixels (px), points (pt), the font size of the parent (em), the font size of the root element (rem), a percentage of the available space (%), or a percentage of the viewport width (vw) or height (vh). See MDN’s CSS values and units for more details.
Other values are specific to the property. For example, the cursor property has possible values help, wait, crosshair, not-allowed, zoom-in, and grab. You should use the MDN documentation for a reference.
One common use for CSS is to change properties about how the text in an element is rendered. This can include changing attributes of the font (font-style, font-weight, font-size, font-family), the color, and the text (text-align, line-break, word-wrap, text-indent, text-justify). These are just a sampling of some of the most commonly used properties.
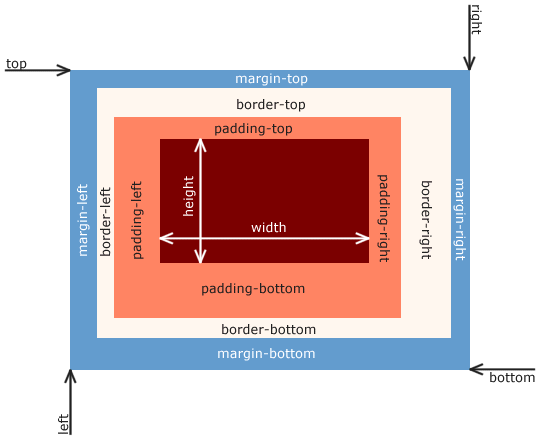
A second common use for CSS is to change properties of the element itself. This can include setting dimensions (width, height), adding margins, borders, and padding.
These values provide additional space around the content of the element, following the CSS Box Model:
The third common use for CSS is to change how elements are laid out on the page. By default HTML elements follow the flow model, where each element appears on the page after the one before it. Some elements are block level elements, which stretch across the entire page (so the next element appears below it), and others are inline and are only as wide as they need to be to hold their contents, so the next element can appear to the right, if there is room.
The float property can make an element float to the left or right of its container, allowing the rest of the page to flow around it.
Or you can swap out the layout model entirely by changing the display property to flex or grid. For learning about these two display models, the CSS-Tricks A Complete Guide to Flexbox and A Complete Guide to Grid are recommended reading. These can provide quite powerful layout tools to the developer.
This is just the tip of the iceberg of what is possible with CSS. Using CSS media queries can change the rules applied to elements based on the size of the device it is viewed on, allowing for responsive design. CSS Animation can allow properties to change over time, making stunning visual animations easy to implement. And CSS can also carry out calculations and store values, leading some computer scientists to argue that it is a Turing Complete language.
The MDN Cascading Stylesheets Docs and CSS Tricks are recommended reading to learn more about CSS and its uses.
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
JavaScript (or ECMAScript, which is the standard JavaScript is derived from), was originally developed for Netscape Navigator by Brendan Eich. The original version was completed in just 10 days. The name “JavaScript” was a marketing move by Netscape as they had just secured the rights to use Java Applets in their browser, and wanted to tie the two languages together. Similarly, they pushed for a Java-like syntax, which Brendan accommodated. However, he also incorporated functional behaviors based on the Scheme language, and drew upon Self’s implementation of object-orientation. The result is a language that may look familiar to you, but often works in unexpected ways.
Unlike the statically-typed Java language, JavaScript has dynamic types like Python. This means that we always declare variables using the var keyword, i.e.:
var i = 0;
var story = "Jack and Jill went up a hill...";
var pi = 3.14;The type of the variable is inferred when it is set, and the type can change with a new assignment, i.e.:
var i = 0; // i is an integer
i = "The sky is blue"; // now i is a string
i = true; // now i is a boolean
This would cause an error in C#, but is perfectly legal in JavaScript. Because JavaScript is dynamically typed, it is impossible to determine type errors until the program is run.
In addition to var, variables can be declared with the const keyword (for constants that cannot be re-assigned), or the let keyword (discussed below).
While the type of a variable is inferred, JavaScript still supports types. You can determine the type of a variable with the typeof() function. The available types in JavaScript are:
true or false)"I'm a string"), single quotes 'Me too!', or backticks `I'm a template string ${2 + 3}`) which indicate a template string and can execute and concatenate embedded JavaScript expressions.["I am", 2, "listy", 4, "u"]), which are a generic catch-all data structure, which can be treated as an array, list, queue, or stack.new keyword, discussed later)In JavaScript, there are two keywords that represent a null value, undefined and null. These have a different meaning: undefined refers to values that have not yet been initialized, while null must be explicitly set by the programmer (and thus intentionally meaning nothing).
As suggested in the description, JavaScript is a functional language incorporating many ideas from Scheme. In JavaScript we declare functions using the function keyword, i.e.:
function add(a, b) {
return a + b;
}We can also declare an anonymous function (one without a name):
function (a, b) {
return a + b;
}or with the lambda syntax:
(a,b) => {
return a + b;
}In JavaScript, functions are first-class objects, which means they can be stored as variables, i.e.:
var add = function(a,b) {
return a + b;
}Added to arrays:
var math = [
add,
(a,b) => {return a - b;},
function(a,b) { a * b; },
]Or passed as function arguments.
Variable scope in JavaScript is bound to functions. Blocks like the body of an if or for loop do not declare a new scope. Thus, this code:
for(var i = 0; i < 3; i++;)
{
console.log("Counting i=" + i);
}
console.log("Final value of i is: " + i);Will print:
Counting i=0
Counting i=1
Counting i=2
Final value of i is: 3Because the i variable is not scoped to the block of the for loop, but rather, the function that contains it.
The keyword let was introduced in ECMAScript version 6 as an alternative for var that enforces block scope. Using let in the example above would result in a reference error being thrown, as i is not defined outside of the for loop block.
JavaScript was written to run within the browser, and was therefore event-driven from the start. It uses the event loop and queue pattern we saw in C#. For example, we can set an event to occur in the future with setTimeout():
setTimeout(function(){console.log("Hello, future!")}, 2000);This will cause “Hello, Future!” to be printed 2 seconds (2000 milliseconds) in the future (notice too that we can pass a function to a function).
As suggested above, JavaScript is object-oriented, but in a manner more similar to Self than to C#. For example, we can declare objects literally:
var student = {
first: "Mark",
last: "Delaney"
}Or we can write a constructor, which in JavaScript is simply a function we capitalize by convention:
function Student(first, last){
this.first = first;
this.last = last;
}And invoke with the new keyword:
var js = new Student("Jack", "Sprat");Objects constructed from classes have a prototype, which can be used to attach methods:
Student.prototype.greet = function(){
console.log(`Hello, my name is ${this.first} ${this.last}`);
}Thus, js.greet() would print Hello, my name is Jack Sprat;
ECMAScript 6 introduced a more familiar form of class definition:
class Student{
constructor(first, last) {
this.first = first;
this.last = last;
this.greet = this.greet.bind(this);
}
greet(){
console.log(`Hello, my name is ${this.first} ${this.last}`);
}
}However, because JavaScript uses function scope, the this in the method greet would not refer to the student constructed in the constructor, but the greet() method itself. The constructor line this.greet = this.greet.bind(this); fixes that issue by binding the greet() method to the this of the constructor.
The Document Object Model (DOM) is a tree-like structure that the browser constructs from parsed HTML to determine size, placement, and appearance of the elements on-screen. In this, it is much like the elements tree we used with Windows Presentation Foundation (which was most likely inspired by the DOM). The DOM is also accessible to JavaScript - in fact, one of the most important uses of JavaScript is to manipulate the DOM.
You can learn more about the DOM from MDN’s Document Object Model documentation entry.
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
At the heart of the world wide web is the Hypertext Transfer Protocol (HTTP). This is a protocol defining how HTTP servers (which host web pages) interact with HTTP clients (which display web pages).
It starts with a request initiated from the web browser (the client). This request is sent over the Internet using the TCP protocol to a web server. Once the web server receives the request, it must decide the appropriate response - ideally sending the requested resource back to the browser to be displayed. The following diagram displays this typical request-response pattern.
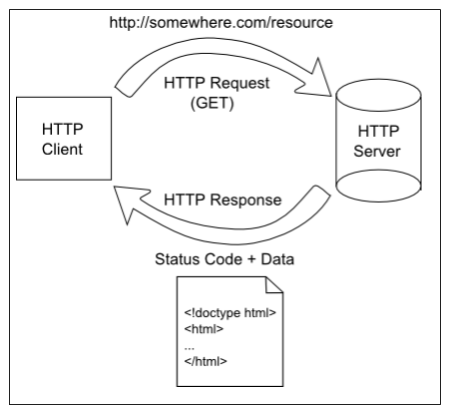
This HTTP request-response pattern is at the core of how all web applications communicate. Even those that use websockets begin with an HTTP request.
A HTTP Request is just text that follows a specific format and sent from a client to a server. It consists of one or more lines terminated by a CRLF (a carriage return and a line feed character, typically written \r\n in most programming languages).
Similar to an HTTP Request, an HTTP response consists of one or more lines of text, terminated by a CRLF (sequential carriage return and line feed characters):
With our new understanding of HTTP requests and responses as consisting of streams of text that match a well-defined format, we can try manually making our own requests, using a Linux command line tool netcat.
In Codio, we can open a terminal window and type the following command:
nc google.com 80The nc portion is the netcat executable - we’re asking Linux to run netcat for us, and providing two command-line arguments, google.com and 80, which are the webserver we want to talk to and the port we want to connect to (port 80 is the default port for HTTP requests).
Now that a connection is established, we can stream our request to Google’s server:
GET / HTTP/1.1The GET indicates we are making a GET request, i.e. requesting a resource from the server. The / indicates the resource on the server we are requesting (at this point, just the top-level page). Finally, the HTTP/1.1 indicates the version of HTTP we are using.
Note that you need to press the return key twice after the GET line, once to end the line, and the second time to end the HTTP request. Pressing the return key in the terminal enters the CRLF character sequence (Carriage Return & Line Feed) the HTTP protocol uses to separate lines
Once the second return is pressed, a whole bunch of text will appear in the terminal. This is the HTTP Response from Google’s server. We’ll take a look at that next.
Scroll up to the top of the request, and you should see something like:
HTTP/1.1 200 OK
Date: Wed, 16 Jan 2019 15:39:33 GMT
Expires: -1
Cache-Control: private, max-age=0
Content-Type: text/html; charset=ISO-8859-1
P3P: CP="This is not a P3P policy! See g.co/p3phelp for more info."
Server: gws
X-XSS-Protection: 1; mode=block
X-Frame-Options: SAMEORIGIN
Set-Cookie: 1P_JAR=2019-01-16-15; expires=Fri, 15-Feb-2019 15:39:33 GMT; path=/; domain=.google.com
Set-Cookie: NID=154=XyALfeRzT9rj_55NNa006-Mmszh7T4rIp9Pgr4AVk4zZuQMZIDAj2hWYoYkKU6Etbmjkft5YPW8Fens07MvfxRSw1D9mKZckUiQ--RZJWZyurfJUyRtoJyTfSOMSaniZTtffEBNK7hY2M23GAMyFIRpyQYQtMpCv2D6xHqpKjb4; expires=Thu, 18-Jul-2019 15:39:33 GMT; path=/; domain=.google.com; HttpOnly
Accept-Ranges: none
Vary: Accept-Encoding
<!doctype html>...The first line indicates that the server responded using the HTTP 1.1 protocol, the status of the response is a 200 code, which corresponds to the human meaning “OK”. In other words, the request worked. The remaining lines are headers describing aspects of the request - the Date, for example, indicates when the request was made, and the path indicates what was requested. Most important of these headers, though is the Content-Type header, which indicates what the body of the response consists of. The content type text/html means the body consists of text, which is formatted as HTML – in other words, a webpage.
Everything after the blank line is the body of the response - in this case, the page content as HTML text. If you scroll far enough through it, you should be able to locate all of the HTML elements in Google’s search page.
That’s really all there is with a HTTP request and response. They’re just streams of data. A webserver just receives a request, processes it, and sends a response.
You can learn a bit more about HTTP and see a similar example in the HTTP lecture from the CIS 527 - Enterprise Systems Administration course.
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
Now that we’ve learned about all of the core technologies used to create and deliver webpages, let’s take a deeper look at the software that runs on the servers that are responsible for receiving HTTP requests and responding to them. We typically call these programs web servers.
The earliest web servers simply served files held in a directory, and in fact many web servers today are still capable of doing exactly that. For example, K-State Computer Science provides a basic web server that can be used to host a personal web page for any faculty, staff, or students in the department. According to the instructions, all you have to do is place the files in a special folder named public_html on the central cslinux.cs.ksu.edu server, and then they can be accessed at the address http://people.cs.ksu.edu/~[eid]/ where [eid] is your K-State eID.
Apache is one of the oldest and most popular open-source web servers in the world. Microsoft introduced their own web server, Internet Information Services (IIS) around the same time. Unlike Apache, which can be installed on most operating systems, IIS only runs on the Windows Server operating system. More recently, the nginx server has become very popular due to its focus on high performance.
As the web grew in popularity, there was tremendous demand to supplement these static pages with pages created on the fly in response to requests - allowing pages to be customized for a particular user, or displaying the most up-to-date information from a database. In other words, dynamic pages. We’ll take a look at these next.
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
Modern websites are more often full-fledged applications than collections of static files. These applications remain built upon the foundations of the core web technologies of HTML, CSS, and JavaScript. In fact, the client-side application is typically built of exactly these three kinds of files! So how can we create a dynamic web application?
One of the earliest approaches was to write a program to dynamically create the HTML file that was being served. Consider this method:
public String GeneratePage() {
StringBuilder sb = new StringBuilder();
sb.append("<!DOCTYPE html>\n");
sb.append("<html>\n");
sb.append("<head>\n");
sb.append("<title>My Dynamic Page</title>\n");
sb.append("</head>\n");
sb.append("<body>\n");
sb.append("<h1>Hello, world!</h1>\n");
sb.append("<p>Time on the server is ");
SimpleDateFormat formatter= new SimpleDateFormat("yyyy-MM-dd 'at' HH:mm:ss z");
Date date = new Date(System.currentTimeMillis());
sb.append(formatter.format(date) + "\n");
sb.append("</p>\n");
sb.append("</body>\n");
sb.append("</html>\n");
return sb.toString();
}def generate_page(self) -> str:
sb: List[str] = list()
sb.append("<!DOCTYPE html>")
sb.append("<html>")
sb.append("<head>")
sb.append("<title>My Dynamic Page</title>")
sb.append("</head>")
sb.append("<body>")
sb.append("<h1>Hello, world!</h1>")
sb.append("<p>Time on the server is ")
now = datetime.now()
sb.append(now.strftime("%d/%m/%Y %H:%M:%S"))
sb.append("</p>")
sb.append("</body>")
sb.append("</html>")
return "\n".join(sb)It generates the HTML of a page showing the current date and time. Remember too that HTTP responses are simply text, so we can generate a response as a string as well:
public String generateResponse() {
String page = generatePage();
StringBuilder sb = new StringBuilder();
sb.append("HTTP/1.1 200\n");
sb.append("Content-Type: text/html; charset=utf-8\n");
sb.append("ContentLength:" + page.length() + "\n");
sb.append("\n");
sb.append(page);
return sb.toString();
}def generate_response(self) -> str:
page: str = generate_page()
sb: List[str] = list()
sb.append("HTTP/1.1 200");
sb.append("Content-Type: text/html; charset=utf-8");
sb.append("ContentLength:" + page.length());
sb.append("");
sb.append(page);
return "\n".join(sb)The resulting string could then be streamed back to the requesting web browser. This is the basic technique used in all server-side web frameworks: they dynamically assemble the response to a request by assembling strings into an HTML page. Where they differ is what language they use to do so, and how much of the process they’ve abstracted.
For example, this approach was adopted by Microsoft and implemented as Active Server Pages (ASP). By placing files with the .asp extension among those served by an IIS server, C# or Visual Basic code written on that page would be executed, and the resulting string would be served as a file. This would happen on each request - so a request for http://somesite.com/somepage.asp would execute the code in the somepage.asp file, and the resulting text would be served.
You might have looked at the above examples and shuddered. After all, who wants to assemble text like that? And when you assemble HTML using raw string concatenation, you don’t have the benefit of syntax highlighting, code completion, or any of the other modern development tools we’ve grown to rely on. Thankfully, most web development frameworks provide some abstraction around this process, and by and large have adopted some form of template syntax to make the process of writing a page easier.
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
It was not long before new technologies sprang up to replace the ad-hoc string concatenation approach to creating dynamic pages. These template approaches allow you to write a page using primarily HTML, but embed snippets of another language to execute and concatenate into the final page. This is very similar to the formatted strings we’ve used in Java and Python, i.e.:
String output = String.format("%s, %d", "Computer", 410)output: str = "{}, {}".format("Computer, 410)The example above concatenates the string "Computer" and the number 410 with a comma between them. While the template strings above use either format specifiers like %s or curly braces {} to call out the script snippets, most HTML template libraries initially used some variation of angle brackets + additional characters. As browsers interpret anything within angle brackets (<>) as HTML tags, these would not be rendered if the template was accidentally served as HTML without executing and concatenating scripts. Two early examples are:
<?php echo "This is a PHP example" ?><% Response.Write("This is a classic ASP example) %>And abbreviated versions:
<?= "This is the short form for PHP" ?><%= "This is the short form for classic ASP" %>Template rendering proved such a popular and powerful tool that rendering libraries were written for most programming languages, and could be used for more than just HTML files - really any kind of text file can be rendered with a template. Thus, you can find template rendering libraries for JavaScript, Python, Ruby, and pretty much any language you care to (and they aren’t that hard to write either).
Classic PHP, Classic ASP, and ASP.NET web pages all use a single-page model, where the client (the browser) requests a specific file, and as that file is interpreted, the dynamic page is generated. This approach worked well in the early days of the world-wide-web, where web sites were essentially a collection of pages. However, as the web grew increasingly interactive, many web sites grew into full-fledged web applications, or full-blown programs that didn’t lend themselves to a page-based structure. This new need resulted in new technologies to fill the void - web frameworks. We’ll talk about these next.
Much of the content in this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
As web sites became web applications, developers began looking to use ideas and techniques drawn from traditional software development. These included architectural patterns like Model-View-Controller (MVC) and Pipeline that simply were not possible with the server page model. The result was the development of a host of web frameworks across multiple programming languages, including:
In this course, we’re going to explore a lightweight web framework that was built for our chosen language:
Both of these frameworks are very powerful, but most importantly, they are extremely flexible and allow us to structure our web application in a way that makes sense for our needs.
On the next pages, we’ll dive a bit deeper into how these web frameworks handle web requests and generate appropriate responses for them.
Earlier in this chapter, we discussed how HTTP is a request-response protocol, as shown in this diagram:
We also discussed how we could write a simple dynamic program to generate a response by concatenating strings together. It was definitely not efficient, but it demonstrated that it is possible to dynamically generate a response to a web request.
Web frameworks simplify this process greatly by handling most of the work for us. As developers, all we really need to do is collect the data that should be contained in the response, and create the template used to generate the web page.
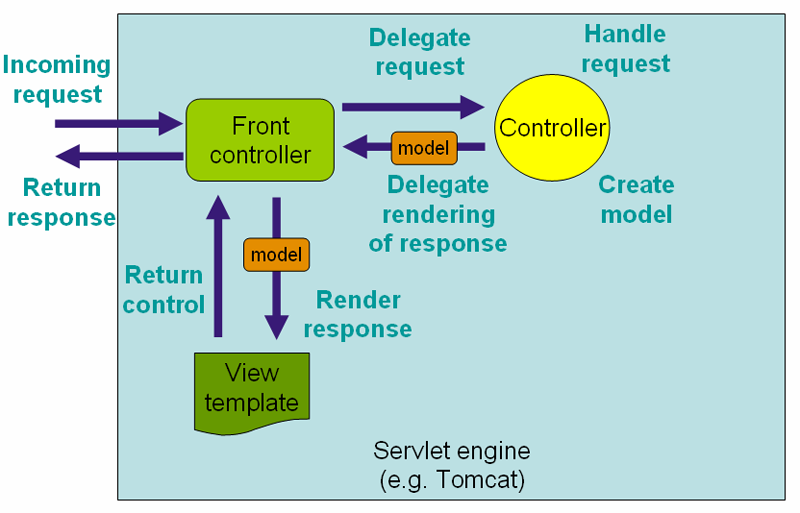
Let’s look at the diagram below, which shows the process that a MVC-based web framework, such as Spring, might follow:
First, the application will receive an incoming web request from a client, which will include a path and possibly some additional data. The framework will examine that request, and determine which part of the application should respond to it. This is a process known as routing, which we’ll cover on the next page.
At that point, the framework will delegate the request to a piece of code, usually called a controller, that can respond to it. In most web applications, the controllers are the main portion of the code written by the developer that isn’t part of the framework itself. So, in the controller, we can look at the request as well as the data that comes along with it, and we can collect the data needed to respond to it.
For example, the request might include information about the user that sent the request, as well as a search term used in a search box. So, our code might collect information about that user and the search term, and use it to populate a model that contains all of the data that is requested.
Once we have completed that task, we can return the model back to the framework, as well as specify a particular template that should be used to create the response. So, the next thing the framework will do is find the requested template and render it, substituting data from the model into the template based on the special markers included in the template. In most cases, the template is the other major part of the web application that is written by the developer.
Finally, the rendered template is placed into an HTTP response, and the response is sent back to the client.
Of course, one major question that we still need to resolve is “how does the web framework look at a web request and determine what code to execute?” To do that, most web frameworks introduce the concept of routing.
In a web framework, a route is usually a mapping from a path to a particular function in a controller.
For example, a simple web framework might match the path /, representing the top level page on the server, to a function called getIndex() in one of the controllers in the web application itself.
So, when an incoming HTTP GET request asks for the page at path /, the web framework will call the code in our getIndex() function, which will usually return a model and a template to render. Then, the framework will render that template using the data in the model, and send that as a response back to the user’s client web browser.
Routes in our web application can be much more complex than mapping simple paths to functions. For example, the route could specify one function when the path is requested using an HTTP GET request, and an entirely different function when the path is requested using an HTTP POST request, which includes some additional data.
A great example is logging in to a website. If the user sends an HTTP GET request to the /login path, it could call a function named getLoginPage() to render a login page that asks the user for a username and password.
When the user enters that information on the page and clicks the “submit” button, it will send an HTTP POST request to the same /login path, along with the username and password that the user entered. In that case, the web framework can be configured to send that request to a different function, postLogin() that will determine if the username and password match an existing user account. If so, the user will be logged in and the website will send an appropriate response. If not, it can even direct the web framework to render the same login template as before, including an extra message to let the user know that the information submitted was invalid.
Finally, routes can also include placeholders for data, similar to wildcards. This is most commonly used in RESTful routing, short for “Representation State Transfer,” which we’ll cover in a later chapter.
For example, a web application might be configured with a route that matches the path /title/<id>, where <id> is a placeholder for some data that is provided as part of the path. So, if the user requests the item at path /title/123, the web framework will know that the user is requesting information about the title with the ID of 123.
In fact, if you look closely at many websites today, you’ll see this pattern all over! A great example is IMDb (the “Internet Movie Database”), where the url https://www.imdb.com/title/tt0076759/ takes you to this page about the original Star Wars movie. In that URL, we see the RESTful route /title/tt0076759, where tt0076759 is the identifier for Star Wars.
We can even explore this by changing the identifier a bit and seeing where that takes us. If we increment the identifier by 1, we get https://www.imdb.com/title/tt0076760/, which takes us to the page about the movie Starship Invasions, released in the same year as Star Wars. In fact, by trying several similar identifiers, we can quickly guess that some of the data on IMDb from movies was loaded alphabetically by year of release!
While RESTful routes using sequential identifiers such as this one are really useful, they can also cause issues. One common cause of this is attaching sequential identifiers to user uploaded data. In this way, any user who uses the platform can upload a piece of data, and then use the identifier attached to that piece of data to guess the identifier of data from other users. This is referred to as an Insecure Direct Object Reference or IDOR. If the website doesn’t properly limit access to this data, it could result in private data being publicly available.
This was most recently in the news when it was revealed that the data from the Parler social network was downloaded by exploiting this bug, among others. Wired does a good job describing how it happened.
One thing you may have also noticed is that many web applications use the same layout across many different pages. Since each page in a web framework requires a different template, it could be very difficult to make sure that each of those pages includes the same information, and updating them would be a major hassle if there were several hundred or thousands of pages in the application.
Thankfully, most web frameworks also include the ability for templates to be composed of other templates. In that way, we can create a hierarchical structure of templates, and even create smaller templates that we can reuse over and over again in our code.
One of the most common ways to accomplish this is through the use of a top-level layout template, which defines the overall layout of the pages used by the web application. This could include specific CSS and JavaScript files, metadata, and even a common header, navigation bar, and footer for each page.
For example, here is a short layout template for the Jinja2 template engine used with Flask in Python, which would be stored in the file layout.html:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>{% block title %}{% endblock %} - Web Application</title>
</head>
<body>
<header>
<nav>
<a href="/">Homepage</a>
</nav>
</header>
<main>
{% block content %}{% endblock %}
</main>
<footer>
<div>
<span>© 2021 Web Application</span>
</div>
</footer>
</body>
</html>This layout includes a header with a title and some metadata. In addition, the body includes both a header and a footer with some information that should be included on every page in the application. Between those, we see a main section.
In Jinja2, the sections surrounded by curly braces and percent signs {% %} define blocks that can be replaced by other content. So, when we use this layout template, we can replace the title and content block with information specific to that page.
To use this layout template, we can just specify it as part of another template. For example, here is a template for a home page, titled index.html:
{% extends "layout.html" %}
{% block title %}Home Page{% endblock %}
{% block content %}
<p>Hello World!</p>
{% endblock %}Pretty simple, isn’t it? This template basically defines the content to be placed in the title and content blocks, and at the top it specifies that it will use the template in layout.html as it’s layout template. So, when the template is rendered, we receive the following HTML:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Home Page - Web Application</title>
</head>
<body>
<header>
<nav>
<a href="/">Homepage</a>
</nav>
</header>
<main>
<p>Hello World!</p>
</main>
<footer>
<div>
<span>© 2021 Web Application</span>
</div>
</footer>
</body>
</html>This use of template inheritance can be done in most template engines used in web frameworks.
In addition, we can place other templates inside of our page template. We’ll see how to do that in the example project for this chapter.
In this chapter, we covered the background content for working with web applications. We learned about HTML, CSS and JavaScript, the three core technologies used on the World Wide Web today. We also learned about HTTP, the protocol used to request a website from a web server and then receive a response from that server.
We then explored static web pages, which made up the majority of the World Wide Web in the early days. However, as the web became more commonplace, the need for dynamic web pages increased. Initially, that process was very rudimentary, but eventually many web frameworks were created to simplify that process.
A web framework follows the same request-response model used by HTML. However, it uses the path of the web request, along with any additional data included in the request, to determine what page to render. This is a process called routing.
Finally, we saw how many template engines today support template inheritance, allowing us to define a hierarchical set of templates that make each page in our web application include the same basic information and structure.
With this information in hand, we can start building a web application as part of our semester project.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.