Hello Real World
Hello World, but like the pros do it!
Hello World, but like the pros do it!
Welcome to CC 410 - Advanced Programming. This course is designed to be a capstone experience at the end of the Computational Core program, building upon our prior knowledge and experience to help us become a truly effective programmer. In this course, we’ll not only learn new skills and techniques, but we’ll try to pull back the curtain and explain the history of programming and why we do some of the things we do.
In this course, we’re going to cover a lot of content. However, it can be grouped into a few big ideas in programming:
We’ll spend some time covering each of these in more detail as we go through the course. In this module, we’ll start working on the first two - writing professional code and minimizing bugs through testing and debugging.
Before we dive too deeply into this topic, let’s take a step back and examine some of the history of programming that lead to our current state of the art that revolves around object-oriented programming. To do that, we’ll need to explore the software crisis and the topic of structured programming.
The content on this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
By this point, you should be familiar enough with the history of computers to be aware of the evolution from the massive room-filling vacuum tube implementations of ENIAC, UNIVAC, and other first-generation computers to transistor-based mainframes like the PDP-1, and the eventual introduction of the microcomputer (desktop computers that are the basis of the modern PC) in the late 1970s. Along with a declining size, each generation of these machines also cost less:
| Machine | Release Year | Cost at Release | Adjusted for Inflation |
|---|---|---|---|
| ENIAC | 1945 | $400,000 | $5,288,143 |
| UNIVAC | 1951 | $159,000 | $1,576,527 |
| PDP-1 | 1963 | $120,000 | $1,010,968 |
| Commodore PET | 1977 | $795 | $5,282 |
| Apple II (4K RAM model) | 1977 | $1,298 | $8,624 |
| IBM PC | 1981 | $1,565 | $4,438 |
| Commodore 64 | 1982 | $595 | $1,589 |
This increase in affordability was also coupled with an increase in computational power. Consider the ENIAC, which computed at 100,000 cycles per second. In contrast, the relatively inexpensive Commodore 64 ran at 1,000,000 cycles per second, while the more pricey IBM PC ran 4,770,000 cycles per second.
Not surprisingly, governments, corporations, schools, and even individuals purchased computers in larger and larger quantities, and the demand for software to run on these platforms and meet these customers’ needs likewise grew. Moreover, the sophistication expected from this software also grew. Edsger Dijkstra described it in these terms:
The major cause of the software crisis is that the machines have become several orders of magnitude more powerful! To put it quite bluntly: as long as there were no machines, programming was no problem at all; when we had a few weak computers, programming became a mild problem, and now we have gigantic computers, programming has become an equally gigantic problem. – Edsger Dijkstra, The Humble Programmer (EWD340), Communications of the ACM
Coupled with this rising demand for programs was a demand for skilled software developers, as reflected in the following table of graduation rates in programming-centric degrees (the dashed line represents the growth of all bachelor degrees, not just computer-related ones):
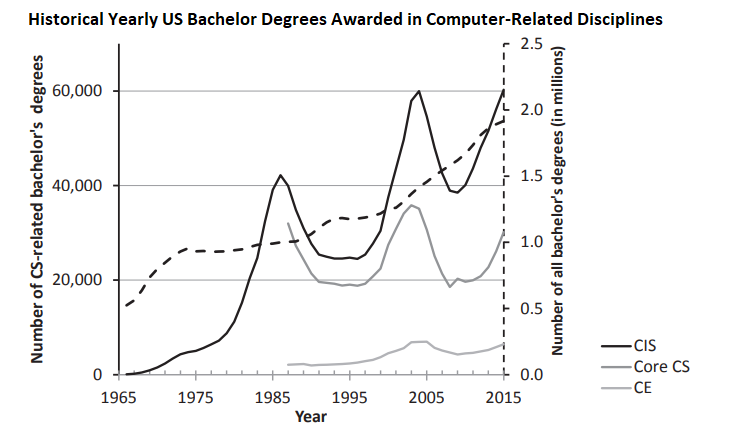
Unfortunately, this graduation rate often lagged far behind the demand for skilled graduates, and was marked by several periods of intense growth (the period from 1965 to 1985, 1995-2003, and the current surge beginning around 2010). During these surges, it was not uncommon to see students hired directly into the industry after only a course or two of learning programming (coding boot camps are a modern equivalent of this trend).
All of these trends contributed to what we now call the Software Crisis.
The content on this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
At the 1968 NATO Software Engineering Conference held in Garmisch Germany, the term “Software Crisis” was coined to describe the current state of the software development industry, where common problems included:
The software development industry sought to counter these problems through a variety of efforts:
This course will seek to instill many of these ideas and approaches into your programming practice through adopting them in our everyday work. It is important to understand that unless these practices are used, the same problems that defined the software crisis continue to occur!
In fact, some software engineering experts suggest the software crisis isn’t over, pointing to recent failures like the Denver Airport Baggage System in 1995, the Ariane 5 Rocket Explosion in 1996, the German Toll Collect system canceled in 2003, the rocky healthcare.gov launch in 2013, and the massive vulnerabilities known as the Meltdown and Spectre exploits discovered in 2018.
The content on this page was adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
One of the strategies that computer scientists employed to counter the software crisis was the development of new programing languages. These new languages would often 1) adopt new techniques intended to make errors harder to make while programming, and 2) remove problematic features that had existed in earlier languages.
Let’s take a look at a working (and in current use) program built using Fortran, one of the most popular programming languages at the onset of the software crisis. This software is the Environmental Policy Integrated Climate (EPIC) Model, created by researchers at Texas A&M:
Environmental Policy Integrated Climate (EPIC) model is a cropping systems model that was developed to estimate soil productivity as affected by erosion as part of the Soil and Water Resources Conservation Act analysis for 1980, which revealed a significant need for improving technology for evaluating the impacts of soil erosion on soil productivity. EPIC simulates approximately eighty crops with one crop growth model using unique parameter values for each crop. It predicts effects of management decisions on soil, water, nutrient and pesticide movements, and their combined impact on soil loss, water quality, and crop yields for areas with homogeneous soils and management. -- EPIC Homepage
You can download the raw source code and the accompanying documentation. Open and unzip the source code, and open a file at random using your favorite code editor. See if you can determine what it does, and how it fits into the overall application.
Try this with a few other files. What do you think of the organization? Would you be comfortable adding a new feature to this program?
You probably found the Fortran code in the example difficult to wrap your mind around - and that’s not surprising, as more recent languages have moved away from many of the practices employed in Fortran. Additionally, our computing environment has dramatically changed since this time.
One clear example is symbol names for variables and procedures (functions) - notice that in the Fortran code they are typically short and cryptic: RT, HU, IEVI, HUSE, and NFALL, for example. You’ve been told since your first class that variable and function names should express clearly what the variable represents or a function does. Would rainFall, dailyHeatUnits, cropLeafAreaIndexDevelopment, CalculateWaterAndNutrientUse(), CalculateConversionOfStandingDeadCropResidueToFlatResidue() be easier to decipher? (Hint: the documentation contains some of the variable notations in a list starting on page 70, and some in-code documentation of global variables occurs in MAIN_1102.f90.).
Believe it or not, there was an actual reason for short names in these early programs. A six character name would fit into a 36-bit register, allowing for fast dictionary lookups - accordingly, early version of FORTRAN enforced a limit of six characters for variable names1. However, it is easy to replace a symbol name with an automatically generated symbol during compilation, allowing for both fast lookup and human readability at a cost of some extra computation during compilation. This step is built into the compilation process of most current programming languages, allowing for arbitrary-length symbol names with no runtime performance penalty.
Another common change to programming languages was the removal of the GOTO statement, which allowed the program execution to jump to an arbitrary point in the code (much like a choose-your-own adventure book will direct you to jump to a page). The GOTO came to be considered too primitive, and too easy for a programmer to misuse 2.
However, the actual functionality of a GOTO statement remains in higher-order programming languages, abstracted into control-flow structures like conditionals, loops, and switch statements. This is the basis of structured programming, a paradigm adopted by all modern higher-order programming languages. Each of these control-flow structures can be represented by careful use of GOTO statements (and, in fact the resulting assembly code from compiling these languages does just that). The benefit is using structured programming promotes “reliability, correctness, and organizational clarity” by clearly defining the circumstances and effects of code jumps 3.
The object-orientation paradigm was similarly developed to make programming large projects easier and less error-prone. We’ll examine just how it seeks to do so in the next few chapters. But before we do, you might want to see how language popularity has fared since the onset of the software crisis, and how new languages have appeared and grown in popularity in this animated chart from Data is Beautiful:
YouTube VideoInterestingly, the four top languages in 2019 (Python, JavaScript, Java, and C#) all adopt the object-oriented paradigm - though the exact details of how they implement it vary dramatically.
The term “Object Orientation” was coined by Alan Kay while he was a graduate student in the late 60s. Alan Kay, Dan Ingalls, Adele Goldberg, and others created the first object-oriented language, Smalltalk, which became a very influential language from which many ideas were borrowed. To Alan, the essential core of object-orientation was three properties a language could possess: 4
We’ll take a look at each of these in the next few chapters.
Weishart, Conrad (2010). “How Long Can a Data Name Be?” ↩︎
Dijkstra, Edgar (1968). “Go To Statement Considered Harmful” ↩︎
Wirth, Nicklaus (1974). “On the Composition of Well-Structured Programs” ↩︎
Eric Elliot, “The Forgotten History of Object-Oriented Programming,” Medium, Oct. 31, 2018. ↩︎
As we saw earlier in this module, the software development industry adopted many new processes and ideas to help combat the issues that arose during the software crisis. One of the major things they focused on was how to write code that is easy to understand, easy to maintain, and works as intended with a minimal amount of bugs. Let’s review a few of the concepts that came from those efforts, which we’ll learn more about throughout this semester.
The use of object-oriented programming languages was one major outcome of the software crisis. An object-oriented language allows developers to build code that represents real-world concepts and ideas, making it easier to reason about large software programs. In addition, the concept of encapsulation helped ensure data stored and manipulated by one part of the program wasn’t inadvertently changed by a bug in another part. Finally, through message passing and dynamic binding, we could write more advanced functions that allowed our code to be very modularized, flexible, and highly reusable. We’ll spend the next several modules in this course covering object-oriented programming in much greater detail.
Another major movement in the software industry was toward the use of automated testing frameworks and the use of unit testing. Unit testing involves writing detailed tests for small units of a program’s source code, often individual functions, that exercise the expected functionality of the code as well as checking for any edge cases or expected errors.
In theory, if the unit tests are properly written and perform all possible operations that the code should perform, than any code passing the tests should be considered complete and ready for use. Of course, coming up with a set of unit tests that can account for all possible scenarios is just as impossible as writing software that doesn’t contain any bugs, but it can be a great step toward writing better software.
A common software development methodology today is test-driven development or TDD. In test-driven development, the unit tests are developed first, based on the software specification, before the source code is ever written. In that way, it is easy to know if the software actually does what the requirements says it should, instead of the test simply being written to match the code that exists. (It is shockingly common for unit tests to be written based on the code it should test, which is equivalent of looking at the answers when doing a word scramble - you’ll find what you expect to find, but won’t actually learn anything useful from it.)
Another useful feature of unit tests is the ability to re-run tests on the program after an update has been developed, which is known as regression testing. If the program previously passed all available unit tests, then failed some of those tests after an update, we know that we introduced some unintended bugs in the code that can be repaired before publishing an update. In that way, we can avoid sending out an update that ends up making things even worse.
Along with unit testing, another useful technique is calculating the code coverage of a set of tests. Ideally, you’d like to make sure that each and every line of code in the program is executed by at least one test - otherwise, how can you really say that that line does what it should? This is especially difficult in programs that contain multiple conditional statements and loops, or any code that checks for and handles exceptions.
There are various ways to measure code coverage, including this list from Wikipedia:
true and false?There are various different ways to measure code coverage that we’ll discuss later in this course, but for now we’ll just look at statement coverage. Thankfully, there are some great tools for computing the code coverage of a set of unit tests. Our goal is always to get as close to 100% coverage as possible.
Another major focus among professional coders is the inclusion of documentation directly in the source code itself. Many languages, such as Java, Python, and C#, include standards for documenting what various pieces of the code are for. This includes each individual source code file, classes, functions, attributes, and more. In many cases, this is done by including specially structured code comments in various places throughout the source code.
To make those comments easier to read and understand, many languages also include tools to automatically create developer documents based on those comments. A prime example of this is the Java API Documentation, which is nearly entirely generated directly from comments in the Java source code. In fact, you can compare the source code for the ArrayList class and the ArrayList Documentation in the Java API to get an idea of how this works.
Finally, there are many tools available today that can perform static code analysis of source code, helping developers find and fix errors without ever even compiling and running the code. Some static code analysis tools are quite powerful, able to find logic errors or completely validate that the software meets a specification. These tools are commonly used in the development of critical software components, such as medical devices and avionics for aircraft, but they are also quite difficult to use.
In this course, we’re going to focus on a simpler form of static code analysis that will help us maintain good coding style. These tools are sometimes commonly referred to as “linters,” named for the old Unix ’lint’ tool that performed this task for code written in the C programming language. Of course, the use of the term “lint” is a reference to the tiny bits of fiber and fuzz that are shed by clothing, with the idea that by removing the “lint” that makes our code messy, we can have code that is cleaner and easier to read and maintain.
In fact, you may have already encountered these tools in your programming experience. Development environments such as the one used by Codio, as well as other integrated development environments (IDEs) such as Visual Studio Code, PyCharm, IntelliJ, and others all include support for static code analysis. Usually it takes the form of helpful error messages that show simple syntax and usage errors.
In this course, we’ll learn how to use some more powerful static code analysis tools to enforce a standard coding style across all of our source code. A [coding style] can be thought of as roughly equivalent to a dialect of a spoken or written language - it deals with common conventions and usage, beyond just the simple definitions and syntax rules of the language itself. By following a standardized style, our code will be easier to read and maintain for any developer who is familiar with that style.
Based on the previous page, it sounds like writing professional code can be quite difficult. There are so many tools and concepts to keep track of, and, in fact, you may end up spending just as much time working with everything else around your code as you do writing the code itself. The benefit of all of this work comes later, when you have to update or maintain the code. If you’ve done a good job writing unit tests, checking for coverage, documenting and styling your code, you’ll end up with fewer bugs overall, and hopefully it will be easier to patch and update the code over the long term that it is in use.
Thankfully, in this course, we’re going to start small in this module with a new project we’re calling “Hello Real World.”
Most programmers can recall the simple “Hello World” program they wrote when learning to program. For many of us, it is the first program we learned to write, and usually the first thing we write when learning a new language. It is almost a sacred tradition!
We’re going to build upon that in this module by learning to write a “Hello World” program of our own, but one that meets the following requirements:
That’s quite a tall order, but this is really how a professional software developer would approach writing good and maintainable code. In some languages, such as Java, a few parts of this process are pretty straightforward - Java is already fully object-oriented by default, and Java uses a common standard for creating in-code documentation. Other languages, such as Python, end up becoming more complex to work with as more requirements are added. For Python developers, a simple “Hello World” program is a single line of code, whereas this set of requirements requires multiple files to properly create a Python package. In addition, the Python language itself does not define a common standard for in-code documentation, so we must rely on external resources to determine what coding style we should follow.
Thankfully, we’ll go through this entire process step by step in the example portion of this module, and you’ll be able to follow along and build your own version of “Hello Real World.”
Portions of the content on this page were adapted from Nathan Bean’s CIS 400 course at K-State, with the author’s permission. That content is licensed under a Creative Commons BY-NC-SA license.
In this chapter, we’ve discussed the environment in which object-orientation emerged. Early computers were limited in their computational power, and languages and programming techniques had to work around these limitations. Similarly, these computers were very expensive, so their purchasers were very concerned about getting the largest possible return on their investment. In the words of Niklaus Wirth:
Tricks were necessary at this time, simply because machines were built with limitations imposed by a technology in its early development stage, and because even problems that would be termed "simple" nowadays could not be handled in a straightforward way. It was the programmers' very task to push computers to their limits by whatever means available.
As computers became more powerful and less expensive, the demand for programs (and therefore programmers) grew faster than universities could train new programmers. Unskilled programmers, unwieldy programming languages, and programming approaches developed to address the problems of older technology led to what became known as the “software crisis” where many projects failed or floundered.
This led to the development of new programming techniques, languages, and paradigms to make the process of programming easier and less error-prone. Among the many new programming paradigms was structured programming paradigm, which introduced control-flow structures into programming languages to help programmers reason about the order of program execution in a clear and consistent manner. Also developed during this time was the object-oriented paradigm, which we will be studying in this course.
Today, many software developers have adopted techniques designed to produce high quality code. These include the use of automated unit testing and test-driven development, as well as standardized use of code comments and linters to maintain good coding style and ample documentation for future developers. In the project for this module, we’ll explore what this looks like by building a simple “Hello World” program that uses all of these techniques.
Check your understanding of the new content introduced in this chapter below - this quiz is not graded and you can retake it as many times as you want.