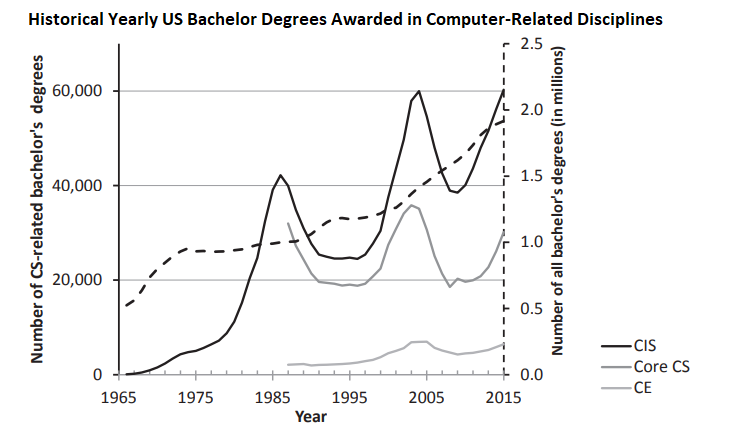
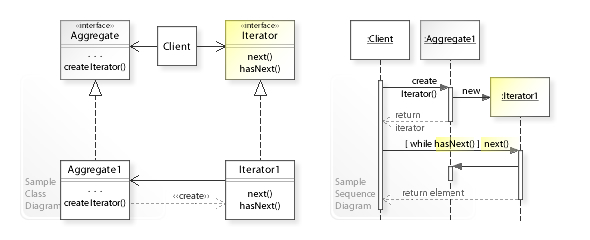
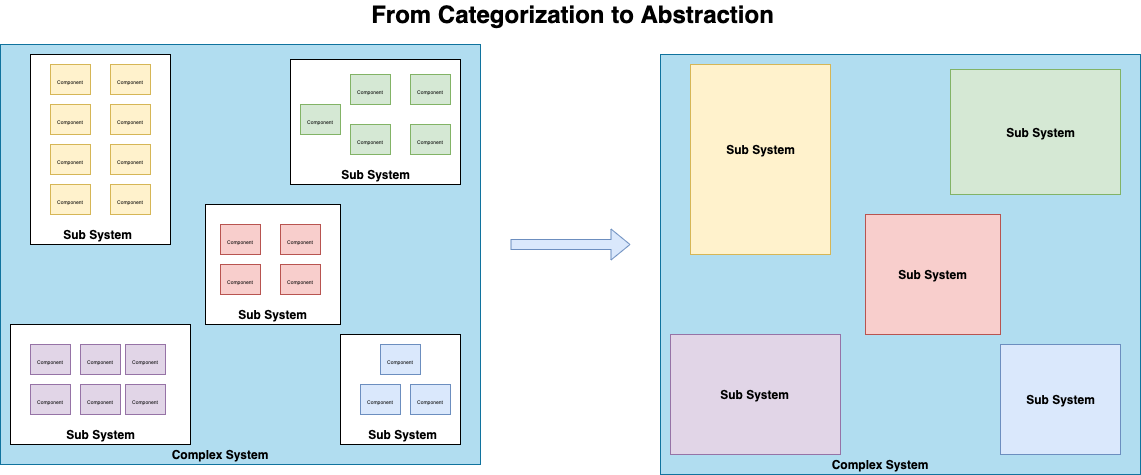
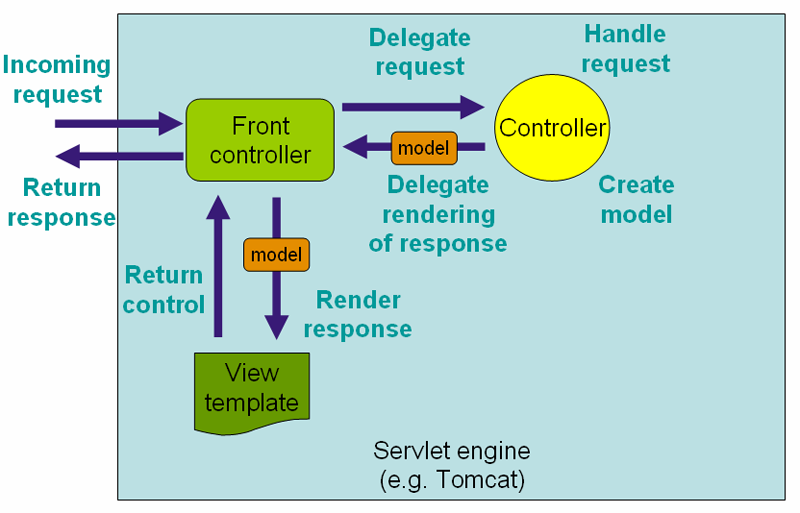
Subsections of Introduction
Course Introduction
YouTube Video
Resources
Video Script
Hello and welcome to the Computational Core program!
My name is Russ Feldhausen, and I’ll be one of the instructors for this program. My contact information is shown here, and is also listed on the syllabus
[Slide 2]
There are many other instructors and TAs for this program that you may interact with or see in the tutorial videos. They all have been instrumental in the development of this program. Specifically, I’d like to recognize the work of Nathan Bean, the developer of the CIS 400 course on which this course is based.
[Slide 3]
In this course we will primarily use a KSU email group (cc410-help or cc410-help@ksuemailprod.onmicrosoft.com) to communicate. Email sent to this address is forwarded to all instructors and TAs. Our replies to you will also be shared amongst the instructors and TAs so we all have access to the assistance you have already received. We will respond to you within a business day, so be aware that a question emailed Friday night may not receive an answer before Monday. Please read and adhere to the guidance on Netiquette in the syllabus for all electronic communications.
[Slide 3]
In addition to email and Canvas, we’ll be using the online learning platform Codio for most of the programming tutorials and projects in this program. We’ll also discuss how to use Codio later in this module.
[Slide 5]
The Computational Core program consists of several courses, and each course contains a number of learning modules. In general, there are about 12-15 modules per course. Each module will usually consist of an interactive tutorial using Codio, followed by a quiz through Canvas, and lastly a programming project in Codio. In CC 410, there will also be several guided examples for you to follow and submit. The modules themselves are gated, which means that you much complete each item in the module before continuing. In addition, the modules enforce prerequisite requirements from other modules. For CC 410 you must complete them in order starting with module 0.
You are welcome to work on this course at any time during the week as your schedule allows, provided that you complete each module before the listed due date. There will be roughly one module due each week. Unlike other Computational Core courses, CC 410 does not include many auto-graded assignments. This is primarily due to the open-ended nature of the course. Instead, your code will be reviewed by an instructor or TA and you’ll receive feedback through Canvas and Codio. In some instances, you may be encouraged to redo parts of an assignment for additional credit. We will strive to provide feedback on an assignment within one week of it being submitted.
[Slide 6]
Looking ahead to the rest of this introductory module, you’ll see that there are a few more items to be completed before you can move on. In the next video, I’ll discuss a bit more information about navigating through this course on Canvas and using the Codio learning environment.
[Slide 7]
One thing I highly encourage each of you to do is read the syllabus for this course in its entirety, and let us know if you have any questions. My view is that the syllabus is a contract between me as your teacher and you as a student, defining how each of us should treat each other and what we should expect from each other. We have made a few changes to the standard syllabus template for this program, and those changes are clearly highlighted. Finally, the syllabus itself is subject to change as needed as we adapt this program to meet the needs of its students, and all changes will be clearly communicated to everyone before they take effect.
[Slide 8]
One important section in the syllabus is this course’s policy on the use of generative artificial intelligence, or GenAI, tools, such as ChatGPT, Copilot, and Claude. While these tools are very powerful and are becoming commonly used in industry, they can also cause issues with your ability to confidently learn new skills, as well as my ability to assess how much you have actually learned in this course. So, my goal is to strike a balance between allowing reasonable usage of these tools where I can, and restricting their usage when I feel it is important for you to learn or demonstrate your own skills. Therefore, this course has adopted a simple stoplight model to let you know when the use of those tools is allowed and to what level you can use them in your submissions.
Each assignment is marked with one of these three colors, and additional information may be included. Assignments marked in red do not allow the use of GenAI during any part of the assignment. Generally these are assessments meant to check your level of understanding of the content, or example projects where you are building new skills. Assignments marked in yellow allow limited use of GenAI tools as “helpers” in the learning process. You are allowed to query GenAI for help on your work, but you may not directly include the GenAI output in your submission. Instead, you must learn to use GenAI as an assistant, but adapt the output you receive to be your own work and effort in the project. Finally, assignments marked in green encourage full use of GenAI, and GenAI results may be included directly in the assignment submission. This is where I really want to you explore how to use GenAI creatively, and often these tasks are repetitive or creative in nature, where GenAI can be especially useful.
In any instances where GenAI is used, you must include a proper citation for that usage. Please see the video later in this module for more information about properly citing the use of GenAI in this course. Likewise, I reserve the right to ask you to describe or explain any part of your submissions that I feel might have been produced by GenAI but isn’t cited, and failure to do so may be considered a violation of this policy.
Finally, when in doubt, please ask me if you have any questions or concerns about this policy. Ignorance of this policy is not an excuse for violating it.
[Slide 9]
In keeping with the new policy on the use of GenAI in this course, I will also disclose any times I use GenAI in the process of teaching this course. I have set the following rules in place for this course regarding my own use of GenAI: I will not use GenAI when communicating with students, nor will I use it to produce any grading feedback or comments. Everything you receive from me this semester will be completely my own work and in my own words.
I may make limited use of GenAI to produce new learning content for this course, such as assignment descriptions, fictional menu items, and simple graphics for use in my materials. Any usage of GenAI will be clearly noted and cited. As of this recording in January 2026, no GenAI content exists in this course.
[Slide 10]
Another important part of the syllabus that every student should read is the late work policy. First off, each module has a due date, and you may work on that module at any time before it is due, provided you have met the prerequisites. As discussed before, you must do all the readings and assignments in a module, preferably in listed order, before moving on, so you cannot jump ahead. A module is considered completed when all items have been completed.
If a module is completed after the due date, a penalty of 10% of the total points of each assignment will be deducted for each day the assignment is late. Therefore, if an assignment is submitted 3 days late, it will be subject to a 30% penalty of the total number of points possible on that assignment. After 10 days, no points will be awarded for a late submission.
However, even if a module is late, it still must be completed before you can move on to a later module. So, it is very important to avoid getting behind in this course, as it can be very difficult to get back on track. If you ever find that you are struggling to keep up, please don’t be afraid to contact either the instructors or GTAs for assistance. We’d be happy to help you get caught back up quickly.
[Slide 11]
The grading in this course is very simple. First, 10% of your final grade will depend on the grades you receive from each of the tutorials and quizzes throughout the course. Next, 10% of your grade will come from the interactive examples that precede several projects. The next 40% of your grade will come from the numerous project milestones throughout the course, of which there will be approximately 10. There will also be a couple of “concept quizzes” throughout the semester, which are a bit longer than a normal quiz and will ask you to apply what you’ve learned to a novel situation. Those are worth 15% of your grade. Finally, the last 25% of your grade will come from the final project in the course, which will be discussed in a later video. In this program, the standard “90-80-70-60” grading scale will apply, though I reserve the right to curve grades up to a higher grade level at my discretion. Therefore, you will never be required to get higher than 90% for an A, but you may get an A if you score slightly below 90% if I choose to curve the grades.
[Slide 12]
This is intended to be a completely online, self-paced course. There are no mandatory scheduled course times. All of the content is available online, so you can work whenever and wherever you want. It could be a 3-hour block once a week, or a few minutes here and there between classes. It’s really up to you and your schedule. However, remember that each module may require 12 to 16 or more hours of work to complete, so make sure you have plenty of time available to devote to this course.
In addition, due to the flexible online format of this class, there won’t be any long lecture videos to watch. Instead, each module will consist of a guided tutorial and several short videos, each focused on a particular topic or task. Likewise, there won’t be any textbooks required, since all of the information will be presented in the interactive tutorials through Codio. Finally, since we are using Codio as our learning platform, you won’t have to deal with installing and using a clunky integrated development environment, or IDE, just to learn how to program. Codio helps make learning to program quick and painless by moving everything to the web.
[Slide 13]
What hasn’t changed, though, is the basic concept of a college course. You’ll still be expected to watch or read about 6-9 hours of content to complete each module. In addition to that, each project assignment may require another 6-9 hours of work to complete. If you plan on doing a module each week, that roughly equates to 6 hours of content and 6 hours of homework each week, which is the expected workload from a 3-4 credit hour college course.
From my experience, I can definitely share that the number one reason students struggle in this class is due to poor time management, not the complexity of the material. So, make sure you are planning to dedicate enough time to this course, and strive to start assignments as soon as you receive them so you have lots of time to get help if you get stuck.
[Slide 14]
For this course, the only supplies you’ll need as a student are access to a modern web browser and a broadband internet connection. No other special hardware or software is necessary! However, in this course you will also be able to do some development on your own computer using Visual Studio Code and Ubuntu. We’ll provide some short videos to help you get started if you choose to go that route, but it is not required. Due to the complex nature of this course, we do not recommend using phones, tablets, or Chromebooks if you choose to do development on your own systems.
[Slide 15]
Finally, as you are aware, this course is always subject to change. This is a relatively new program here at K-State, and we’re always working on new and interesting ideas to integrate into the courses. The best advice I have is to look upon this graphic with the words “Don’t Panic” written in large, friendly letters. If you find yourself falling behind, or not understanding seek our help via cc410-help.
[Slide 16]
So, to complete this module, there are a few other things that you’ll need to do. The next step is to watch the video on navigating Canvas and Codio, which will give you a good idea of how to most effectively work through the content in this course.
[Slide 17]
To get to that video, click the “Next” button at the bottom right of this page.
Navigating Canvas & Codio
YouTube Video
Resources
Video Script
This course makes extensive use of several features of Canvas which you may or may not have worked with before. To give you the best experience in this course, this video will briefly describe those features and the best way to access them.
When you first access the course on Canvas, you will be shown this homepage. It contains quick links to the course syllabus and Piazza discussion boards. This is handy if you just need to jump to a particular area.
Let’s walk through the options in the main menu to the left. The first section is Modules, which is where you’ll primarily interact with the course. You’ll notice that I’ve disabled several of the common menu items in this course, such as Files and Assignments. This is to simplify things for you as students, so you remember that all the course content is available in one place.
When you first arrive at the Modules section, you’ll see all of the content in the course laid out in order. If you like, you can minimize the modules you aren’t working on by clicking the arrow to the left of the module name. I’ll do so, leaving the introductory module open.
As you look at each module, you’ll see that it gives quite a bit of information about the course. At the top of each module is an item telling you what parts of the module you must complete to continue. In this case, it says “Complete All Items.” Likewise, the following modules may list a number of prerequisite modules, which you must complete before you can access it.
Within each module is a set of items, which must be completed in listed order. Under each item you’ll see information about what you must do in order to complete that item. For many of them, it will simply say view, which means you must view the item at least once to continue. Others may say contribute, submit, or give a minimum score required to continue. For assignments, it also helpfully gives the number of points available, and the due date.
Let’s click on the first item, Course Introduction, to get started. You’ve already been to this page by this point. Many course pages will consist of an embedded video, followed by links to any resources used or referenced in the video, including the slides and a downloadable version of the video. Finally, a rough video script will be posted on the page for your quick reference.
While I cannot force you to watch each video in its entirety, I highly recommend doing so. The script on the page may not accurately reflect all of the content in the video, nor can it show how to perform some tasks which are purely visual.
When you are ready to move to the next step in a module, click the Next button at the bottom of the page. Canvas will automatically add Next and Previous buttons to each piece of content which is accessed through the Modules section, which makes it very easy to work through the course content. I’ll click through a couple of items here.
At any point, you may click on the Modules link in the menu to the left to return to the Modules section of the site. You’ll notice that I’ve viewed the first few items in the first module, so I can access more items here. This is handy if you want to go back and review the content you’ve already seen, or if you leave and want to resume where you left off. Canvas will put green checkmarks to the right of items you’ve completed.
Continuing down the menu to the left, you’ll find the usual Canvas links to view your grades in the course, as well as a list of fellow students taking the course.
===
Now, let’s go back to Canvas and load up one of the Codio projects. To load the first Codio projects, click the Next button at the bottom of this page to go to the next part of this module, which is the Codio Introduction tutorial. On that page, there will be a button to click, which opens Codio in a new browser window or tab.
Once Codio loads, it should give you the option to start the Guide for that module. You’ll definitely want to select that option whenever you load a Codio project for the first time.
From there, you can follow the steps in that guide to learn more about the Codio interface. The first page of the guide continues this video. I’ll see you there!
Where to Find Help
YouTube Video
Resources
Video Script
As you work on the materials in this course, you may run into questions or problems and need assistance. This video reviews the various types of help available to you in this course.
First and foremost, anytime you have a questions or need assistance in the Computational Core program, please send an email to the appropriate help group for this course. In this case, it would be cc410-help, or cc410-help@ksuemailprod.onmicrosoft.com. That email goes to the instructors and GTAs, and is your best chance to get a quick response. We’ll respond to your email within one business day.
Beyond email, there are a few resources you should be aware of. First, if you have any issues working with K-State Canvas, K-State IT resources, or any other technology related to the delivery of the course, your first source of help is the K-State IT Helpdesk. They can easily be reached via email at helpdesk@ksu.edu. Beyond them, there are many online resources for using Canvas, all of which are linked in the resources section below the video. As a last resort, you may also want to email the help group, but in most cases we may simply redirect you to the K-State helpdesk for assistance.
Similarly, if you have any issues using the Codio platform, you are welcome to refer to their online documentation. Their support staff offers a quick and easy chat interface where you can ask questions and get feedback within a few minutes.
If you have issues with the technical content of the course, specifically related to completing the tutorials and projects, there are several resources available to you. First and foremost, make sure you consult the vast amount of material available in the course modules, including the links to resources. Usually, most answers you need can be found there.
If you are still stuck or unsure of where to go, the next best thing is to post your question as an email to the help group. As discussed earlier, the instructors and GTAs will do their best to help you as soon as they can.
Of course, as another step you can always exercise your information-gathering skills and use online search tools such as Google to answer your question. While you are not allowed to search online for direct solutions to assignments or projects, you are more than welcome to use Google to access programming resources such as StackOverflow, language documentation, and other tutorials. I can definitely assure you that programmers working in industry are often using Google and other online resources to solve problems, so there is no reason why you shouldn’t start building that skill now.
Next, we have grading and administrative issues. This could include problems or mistakes in the grade you received on a project, missing course resources, or any concerns you have regarding the course and the conduct of myself and your peers. Since this is an online course, you’ll be interacting with us on a variety of online platforms, and sometimes things happen that are inappropriate or offensive. There are lots of resources at K-State to help you with those situations. First and foremost, please email me directly as soon as possible and let me know about your concern, if it is appropriate for me to be involved. If not, or if you’d rather talk with someone other than me about your issue, I encourage you to contact either your academic advisor, the CS department staff, College of Engineering Student Services, or the K-State Office of Student Life. Finally, if you have any concerns that you feel should be reported to K-State, you can do so at https://www.k-state.edu/report/. That site also has links to a large number of resources at K-State that you can use when you need help.
Finally, if you find any errors or omissions in the course content, or have suggestions for additional resources to include in the course, email the help group. There are some extra credit points available for helping to improve the course, so be on the lookout for anything that you feel could be changed or improved.
So, in summary, reviewing the existing course content should always be your first stop when you have a question or run into a problem, since most issues can be solved there. If you are still stuck, email cc410-help to ask for assistance, and we’ll get back to you within a business day. For issues with Canvas or Codio, you are also welcome to refer directly to the resources for those platforms. For grading questions and errors in the course content or any other issues, please email cc410-help or the instructors directly for assistance.
Our goal in this program is to make sure that you have the resources available to you to be successful. Please don’t be afraid to take advantage of them and ask questions whenever you want.
How to Learn Programming
YouTube Video
Resources
Video Script
Before we launch into the course itself, I wanted to take a few minutes to share some information with you regarding what we know about how students learn to program. This isn’t just anecdotal evidence from computer science teachers like me, but theories and research from education researchers who study how humans learn new skills and abilities throughout their lives.If I had to summarize all of this information in as few words as possible, I’d simply say “do the work.” Learning to program is difficult, and the only way to really get good at it is through constant practice and learning. However, that greatly oversimplifies the information that I want to share, and I’m hoping that you’ll find some helpful takeaways from this video that you can incorporate into your learning process.
Before I begin, I want go give all the credit to Nathan Bean for developing this information as part of his CIS 400 course. He graciously allowed me to use his hard work here, and I encourage you to check out his original version, which is available at the URL shown on this slide.
The statement “do the work” is a shorter version of a very common quote from educators, which is “the person doing the work is the person doing the learning.” I couldn’t find a solid reference for who said it first, so I’ll just attributed it to various educators throughout time. This really highlights one of the biggest struggles many students run into when learning to program. There are so many guides online, and the answer to many simple problems can be found through a quick Google search. You can just copy and paste the code, and then your program works. However, did you really learn how to write that program and what it does, or just how to find a quick answer? While this may be a useful tactic from time to time, if you rely too much on other people to do your coding, you really won’t learn it yourself. This is just like learning to shoot free throws on a basketball court or beating your best time in a speedrun - you can’t just watch someone do it and expect to do it yourself (believe me, I’ve tried). So, if you aren’t doing the work, you aren’t really learning.
Next, let’s address a major myth in computer science. I’ve heard this many times: “some people are just natural born programmers, and others simply cannot learn to program.” And yes, on the surface, it may appear to be this way. Some students just seem to have a knack for programming, and you may sit and struggle and not really get anywhere. However, there is no innate skill or ability that makes you good at programming.
Instead, let’s reframe what it means to learn programming. At its core, programming is learning to write steps to solve problems in a way that a computer can perform those steps. That’s really what we are doing when we learn programming.
So, we must focus on learning how to write those steps with the proper exactitude and precision so that they make sense, and we must understand how a computer functions to be able to program that computer effectively. So, when you see someone who is good at programming, it’s not because they are good at some esoteric skill that you’ll never have - they just know how to express their steps properly and know enough about how a computer works to make their program do what they want. That’s really it! And, to be honest, after a single semester of learning to program, you’ll have all the skills you need to do both of those things! If you know how to make conditionals, loops, functions, and use simple variables and arrays, that’s really all you need. Everything else that comes after that is just refining those skills to make your programs more powerful and your coding more efficient.
So, how do we learn these skills? Well, there are a couple of important pieces we need to make sure are in the right place first. For starters, we need to have the correct mindset. Many times I’ll see students struggle to learn how to program, and they’ll say things like what you see on this slide. “Its too hard.” “I don’t understand this.” “I give up.” Statements like this are the sign of a “fixed mindset,” and they can be one of the greatest blockers preventing you from really learning to program. Just like learning any other skill, you have to be open to instruction and willing to learn, or else you’ve failed before you even started.
Instead, we want to focus on building a growth mindset. In the TED talk by Carol Dweck that is linked below this video, which I encourage you to watch, she talks about the power of “yet.” We can turn these statements around by simply adding positive power of “yet” - “I don’t understand this yet.” “I love a good challenge.” “I’ll keep trying until I get it.” Going into a programming project with a mindset that is open to growth and change is really an important first steps. When I feel like I’m getting a fixed mindset, I like to think about how difficult it would be to teach a child to tie their shoes if they don’t want to learn. As soon as I realize that, it is pretty easy to recognize that same problem in myself and work to correct it.
So, once we have our growth mindset, how do we actually learn to program? To understand that, let’s dive a bit into the world of educational theory and the work of Jean Piaget. Piaget was a biologist and psychologist who studied how young children acquired new knowledge, and he helped pioneer the concept of Constructivism, one of the most influential philosophies in education. You can read more about Constructivism in the links below this video.
One particular thing that Piaget worked on was a theory of genetic epistemology. Epistemology is the term for the study of human knowledge, so genetic epistemology is the study of the origins, or genesis, of that knowledge. Put more clearly, it’s the study of how humans create new knowledge. This concept was inspired by research done on snails - he was able to prove that two previously distinct species of snails were actually the same by moving snails from one habitat to another and observing how they modified their behaviors and how their shells grew to match the snails in the new habitat. Put clearly, the snails displayed an altered behavior based on their environment. They tried to exist in equilibrium with their environment by adapting their behaviors to fit what they now experienced in the word.
Piaget suspected that something similar happens when humans try to learn something - the brain tries to adapt itself to maintain an equilibrium in its environment, which in this case is the existing knowledge it contains. So, when the brain is exposed to new ideas, it must somehow adjust to account for that new information. Piaget proposed two different mechanisms for how this occurs: assimilation and accommodation. In assimilation, new knowledge can be added to existing structures in the brain. For example, if you are exposed to a new color, such as periwinkle, you can see that it falls somewhere between blue and violet, two colors you already know. So, you can assimilate that new knowledge into the existing knowledge without a major disruption to your mental structure of existing colors. Accommodation, on the other hand, happens when your brain must radically adapt to new information for which no existing structures exist. This can be very difficult, and can lead to a lot of struggle and frustration when trying to get “over the hump” on a new subject. Think about learning algebra or a new language for the first time - you really don’t have anything you can use to help understand this new material, so you just have to keep at it until those new structures are formed in your brain.
Unfortunately, to achieve accommodation, your brain simply has to build brand new structures to store and represent all of this new information, and that process is difficult and takes time. Put another way, it takes significant stimulus, usually in the form of doing homework, struggling with difficult problems and wrestling with the new information to try and understand it all, to create enough disequilibrium in your brain that, coupled with a growth mindset, will allow accommodation to occur. However, when all the pieces are in the right place, and you work hard and have a growth mindset, then…
EUREKA! The structures will form, and you’ll get over that huge hurdle, and things will start falling into place. It may not happen all at once, but it does happen (you’ve probably had it happen to you several times already - think about some eureka moments from your past - were they related to learning a new skill?). Of course, there’s a good chance that your brain might form a few incorrect structures in the process, so you’ll have to overcome those as you continue to learn. I still struggle to spell some words because my brain formed incorrect structures when I was still learning. But, if you continue to work hard and be open to learning, you’ll eventually sort those errors out as well.
Let’s look at one other concept in education, which is called stage theory. Piaget identified four stages that children go through as they learn to reason about the world. Those four stages are shown on this slide. In the sensorimotor stage, the child is just using their senses to interact with the world, without any real understanding of what will happen when they perform an action. This is best represented by babies and toddlers, who touch and taste everything in their surroundings. Next, the preoperational stage is represented in young children as they start to think symbolically about the world, using pictures and words to represent actions and objects. They then progress to the concrete operational stage, where they can begin to think logically and understand how concrete events happen. They can also start to think inductively, building the general principles of the world from their specific experiences. For example, if they observe that cooked spaghetti is better than raw spaghetti, they might reason that other foods like potatoes are better cooked than raw. Finally, the last stage is the formal operational stage. This stage is represented by the ability to work fully with an abstract work, formulating and testing hypotheses to truly understand how the world works and predict how new items will work before experiencing them firsthand.
Many later researchers built upon this model to show that adults learn in much the same way. They also discovered that the stages are not rigid, and you may exhibit behaviors from multiple stages at any given time. This is called the “overlapping waves” model, and is shown here in this diagram. So, as you learn new skills, you may be at the operational stage in some areas, but still at the preoperational stage in other areas. This explains why some concepts may make sense while others don’t for a while - you just have to keep going until it all fits together.
So, how can we apply all of this information to programming? One theory comes from the work of Lister and Teague, who proposed a developmental epistemology of computer programming. Put another way, they applied this theory to computer science education, and gave us a unique way to think about the different stages of learning to program.
At the sensorimotor stage, we’re just getting the basics. So, when given a piece of code and asked to trace what it does, we still make lots of errors and get the answer incorrect. If we want to get a program to work ourselves, it usually involves a lot of trial and error, and many times when it does end up working we don’t even know exactly why it worked that time, but we’re building up a baseline of information that we can use to construct our mental model of how a computer works.
As we progress into the preoperational stage, we become better at tracing code correctly, but we still struggle to understand what the program itself does. We see each line of code as a separate instruction, but not the entire program. A great analogy is reading a recipe that calls for flour, water, salt, and yeast. Will it make bread? Biscuits? Pie crust? We’re not sure yet, but at least we can recognize the ingredients. To solve problems at this stage, we typically will randomly adjust pieces of our code that we don’t quite understand and see what it does, trying to form a better idea of the importance of each line in the code.
Eventually, we’ll get to the concrete operational stage. At this stage, we can construct our own programs, but many times we are simply piecing together parts that we’ve used before and performing some futile patches and bugfixes as we refine the program. We can also work backwards to figure out what a program does from execution results, but we still aren’t very good at deducing the results from the code itself. However, we’re starting to work with abstraction, though we tend to simplify things to a level that we are more comfortable with.
Finally, we’ll reach the formal operational stage. At this stage, we can comfortable read and understand code without executing it, quickly seeing what it does and how it works without fully tracing it ourselves. We can also start to form hypotheses for how to build new programs and code, and reason about whether different approaches would work better or worse than others. This is the goal stage for any programmer! Once you have reached this stage, then you’ll feel totally at home working in code and developing your own programs from scratch.
So, how can we enable ourselves to be the best learners we can be? There is lots of interesting research in that area, best summarized in the book “The New Science of Learning” that is linked below this video. Let’s go through a few of the big concepts.
First, getting ample and regular sleep is important, because it allows your brain to build those knowledge structures we discussed earlier and store the memories from the day in long-term storage. Without enough sleep, your brain is unable to process memories offline and make them ready for retrieval later on, an important step in learning. Also, consuming large amounts of caffeine or alcohol can disrupt your sleep patterns, so keep that in mind before you pour that next cup of coffee or go out partying. You can also take advantage of modern technology to help you track your sleep - most smart watches and smartphones today can help with that!
Likewise, regular exercise is important to both your physical and mental health. When you exercise, especially aerobic exercise that gets your heart rate up, your body releases neurochemicals that help your brain cells communicate. In addition, just getting up and moving around regularly helps keep your body healthy, so take regular breaks, and consider getting a standing desk for some extra benefits.
Research also shows that engaging your senses is an important part in learning. This is why we, as teachers, try to vary our lessons with pictures, videos, activities, and more. It is also the basis of the cognitive apprenticeship style of learning that we use, which you can learn more about in the links below this video. We show you the code we are writing, engaging your sense of vision, while talking about it so you are also listening, and then you are writing your own version, using your sense of touch. You can build upon this by using your senses while you learn by taking notes during a lecture video, building concept maps, and even printing out and writing on your code and these lecture scripts. All of these processes help engage different parts of your brain and make it that much easier to build new knowledge structures.
Looking for patterns is another important way to understand programming. There are many common patterns in computer programs, such as using a for loop to iterate through an array, or an if-else statement to determine if a particular variable is set to a valid value. By recognizing and understanding those patterns, we can more quickly understand new programs that use slightly different versions of the same code. Humans are naturally very good at pattern recognition, and it is one of the reasons why we see the same code structures time and time again - not because they are the only way to accomplish that goal, but because that structure is commonly used across many programs and therefore is easier to understand.
There is quite a bit of research into how memories are formed and how we can adjust our studying habits to take advantage of that. For example, cognitive science shows that the parts of our brain responsible for memory creation are active up to one hour after a learning experience has ended, such as a lecture video or activity. So, instead of jumping to the next task, you may want to take a little while to reflect on what you just did and let it sink in before moving on. Likewise, to build strong memories, it is important to constantly recall the memory or use the skills you’ve learned to strengthen their structures in the brain. This is why teachers like to throw in a few questions from a previous exam or quiz every once in a while - it helps strengthen those structures by forcing you to recall information you’ve learned previously. On the other hand, many students try to “cram” a bunch of information right before an exam, only to forget it soon after because it wasn’t recalled more than once. As you progress further, we’ll continue to come back to concepts you’ve already learned and build upon them, a process called elaboration that helps reinforce what you’ve already learned while building new, related knowledge.
Finally, it is important to remember that we must give our brains the space it needs to focus on the task at hand. Multitasking while learning, such as watching YouTube or Twitch, chatting with friends, or listening to a lecture video while coding can all reduce your brain’s ability to form strong memories and do well. In fact, research shows that individuals who try to multitask tend to make 50% more errors and spend 50% more time on both tasks. So, instead of giving yourself distractions, try to find things that will help you focus better - there are some great playlists online for music without lyrics that can help you focus or code better, and you can easily mute notifications on your phone and on your computer for an hour or so while you work.
So, let’s summarize what we’ve covered here. First, and most importantly, remember that you can learn to program, just like the many students who have done it before you. However, it can be difficult and frustrating at times, and it will take lots of hard work on your part to make it happen. That means that you’ll need to read and write a lot of code before it really starts to make sense. In short, you must do the work to learn to program.
That said, you can help make the process easier by getting good sleep, exercising regularly, and engaging fully with all of the content in the course. That means you’ll need to take your own notes, maybe draw some diagrams, and annotate code you write and code you read to help you understand it. While you are working, try not to multitask so you can focus. If you are given some code to include in your program, don’t copy/paste it - rewrite it, and make sure you completely understand what each line does. Finally, take some time to read code written by others! GitHub is a great place to discover all sorts of code and see how others write code. If you want to write good poetry you have to read lots of good poetry, and the same goes for coding.
With that in mind, I hope you are able to make the best of this course and continue to develop your programming skills. If you are interested in this topic and would like to know more about things you can do to be a better learner, let us know! As you can imagine, teachers like me love to talk about this stuff, so don’t be afraid to ask. Good luck!
Spring 2026 Syllabus
CC 410 - Advanced Programming - Spring 2026
Previous Versions
- Instructor: Mr. Russell Feldhausen (russfeld AT ksu DOT edu)
- Office: DUE 2213, but I mostly work remotely from Kansas City, MO
- Phone: (785) 292-3121 (Call/Text)
- Website: https://russfeld.me
- Virtual Office Hours: By appointment via Zoom. Book time to meet with me
Preferred Methods of Communication:
- Email: Students should email cc410-help (cc410-help@KSUemailProd.onmicrosoft.com). We will try to respond within one business day.
- Ed Discussion: For short questions and discussions of course content and assignments, Ed Discussion is preferred since questions can be asked once and answered for all students. Students are encouraged to post questions there and use that space for discussion, and the instructor will strive to answer questions there as well.
- Phone/Text: Emergencies only! We will do our best to respond as quickly as we can.
Prerequisites
- CC 310 - Data Structures & Algorithms I (taken on or after Fall 2024)
- CC 315 - Data Structures & Algorithms II (taken prior to Fall 2024)
Course Overview
Advanced programming techniques and projects. Concepts from object oriented programming, inheritance and polymorphism. GUI programming and event-driven programming. Software development methodologies, processes, and design patterns. Practical experience with professional communication and collaboration.
Course Description
In this course students gain experience writing programs using a variety of advanced programming techniques. Projects cover a variety of application domains and use a variety of technologies to help students master advanced computer programming concepts.
The goal is not just to write software that compiles without errors, but to develop well-written and maintainable software. This goal demands extra attention to design, documentation, and testing. Additionally, we will explore some of the powerful features of the various languages used, as well as other professional tools like Git.
Major Course Topics
- Software Development Practices
- Software Engineering Methodologies
- Design Patterns and Architectures
- Computer Security
- Advanced Object-Oriented Design
- GUI Programming
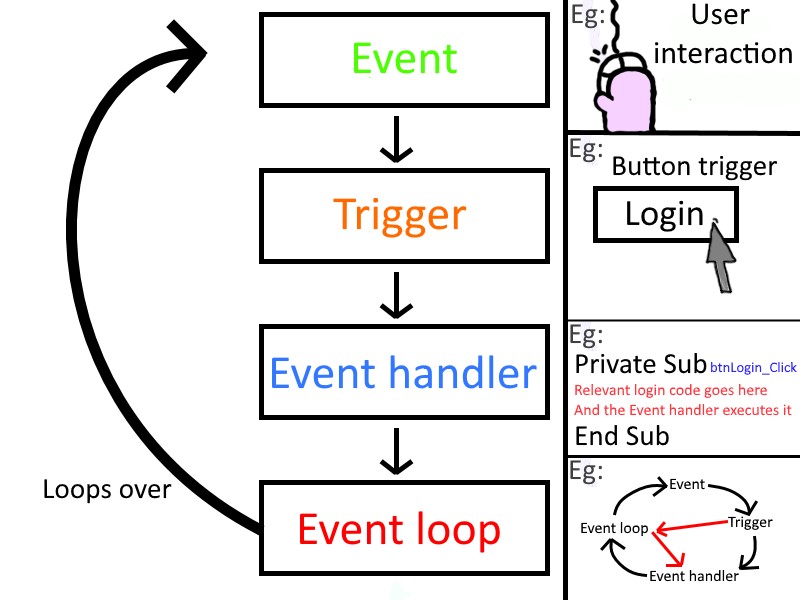
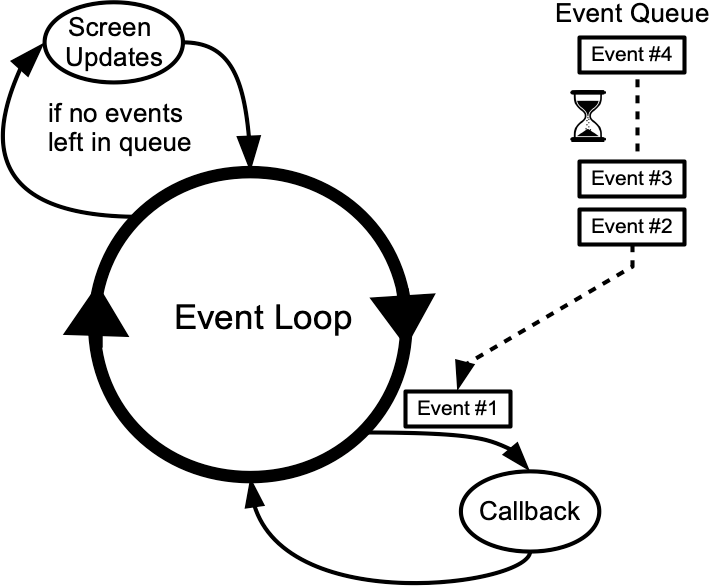
- Event-Driven Programming
- Professional Communication and Collaboration
Student Learning Outcomes
After completing this course, a successful student will be able to:
- Develop code following industry best-practices for code style and documentation
- Develop and execute unit tests that adequately test code for bugs and errors
- Make use of tools to determine the code coverage of a set of unit tests
- Make use of source code management tools to maintain and store a code base
- Create a class library following the object-oriented paradigm that makes effective use of inheritance and polymorphism where appropriate
- Develop a GUI for a given program that uses event-driven programming to respond to GUI events and manipulate underlying data models
- Apply common software development methodologies, processes and design patterns to create software that performs a desired task or solves a problem
- Communicate information about their code effectively with various audiences
Course Structure
These courses are being taught 100% online, and each module is self-paced. There may be some bumps in the road as we refine the overall course structure. Students will work at their own pace through a set of modules, with approximately one module being due each week. Material will be provided in the form of recorded videos, online tutorials, links to online resources, and discussion prompts. Each module will include a coding project or assignment, many of which will be graded automatically through Codio. Assignments may also include portions which will be graded manually via Canvas or other tools.
A common axiom in learner-centered teaching is “the person doing the work is the person doing the learning.” What this really means is that students primarily learn through grappling with the concepts and skills of a course while attempting to apply them. Simply seeing a demonstration or hearing a lecture by itself doesn’t do much in terms of learning. This is not to say that they don’t serve an important role - as they set the stage for the learning to come, helping you to recognize the core ideas to focus on as you work. The work itself consists of applying ideas, practicing skills, and putting the concepts into your own words.
The Work
There is no shortcut to becoming a great programmer. Only by doing the work will you develop the skills and knowledge to make you a successful computer scientist. This course is built around that principle, and gives you ample opportunity to do the work, with as much support as we can offer.
Tutorials, Quizzes & Examples: Each module will include many tutorial assignments, quizzes, and examples that will take you step-by-step through using a particular concept or technique. The point is not simply to complete the example, but to practice the technique and coding involved. You will be expected to implement these techniques on your own in the milestone assignment of the module - so this practice helps prepare you for those assignments.
Milestone Programming Assignments: Throughout the semester you will be building a non-trivial software project iteratively; every week a new milestone (a collection of features embodying a new version of a software application) will be due. Each milestone builds upon the prior milestone’s code base, so it is critical that you complete each milestone in a timely manner! This process also reflects the way software development is done in the real world - breaking large projects into more readily achievable milestones helps manage the development process.
Following along that real-world theme, programming assignments in this class will also be graded according to their conformance to coding style, documentation, and testing requirements. Each milestone’s rubric will include points assigned to each of these factors. It is not enough to simply write code that compiles and meets the specification; good code is readable, maintainable, efficient, and secure. The principles and practices of Object-Oriented programming that we will be learning in this course have been developed specifically to help address these concerns.
Concept Quizzes: There will be a couple of concept quizzes throughout the semester to check your understanding of various programming topics. These will allow you to demonstrate your problem-solving skills and your ability to apply what you’ve learned to novel situations.
Final Project: At the end of this course, you will design and develop a final project of your choosing to demonstrate your ability. This project can link back to your interest or other fields, and will serve as a capstone project for the Computational Core program.
Grading
In theory, each student begins the course with an A. As you submit work, you can either maintain your A (for good work) or chip away at it (for less adequate or incomplete work). In practice, each student starts with 0 points in the gradebook and works upward toward a final point total earned out of the possible number of points. In this course, each assignment constitutes a portion of the final grade, as detailed below:
- 10% - Tutorials & Quizzes
- 10% - Examples
- 40% - Programming Project Milestones
- 15% - Concept Quizzes
- 25% - Final Project
Up to 5% of the total grade in the class is available as extra credit. See the Extra Credit - Bug Bounty & Extra Credit - Helping Hands assignments for details.
Letter grades will be assigned following the standard scale:
- 90% - 100% → A
- 80% - 89.99% → B
- 70% - 79.99% → C
- 60% - 69.99% → D
- 00% - 59.99% → F
Submission, Regrading, and Early Grading Policy
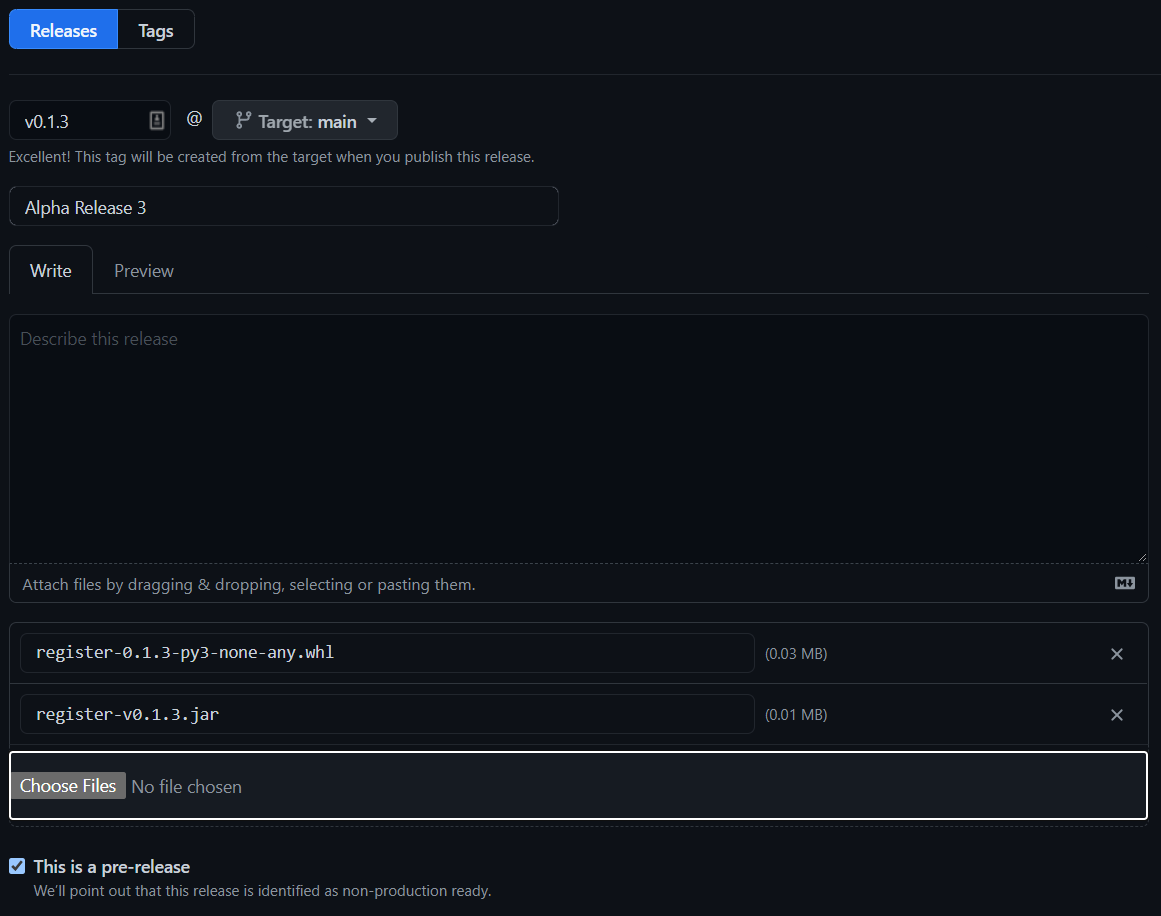
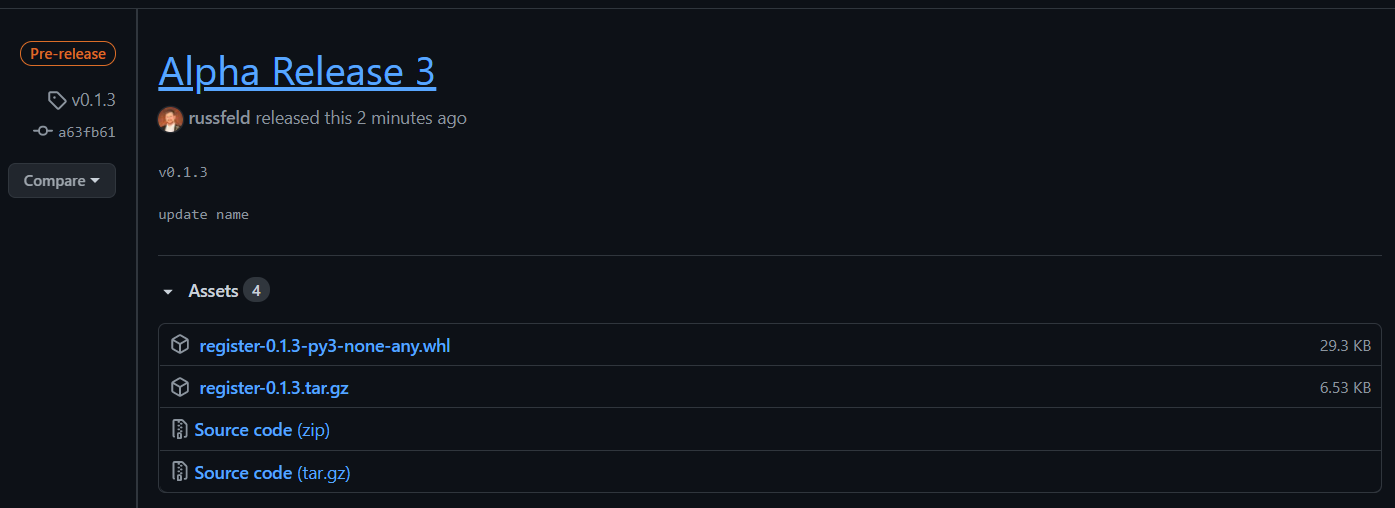
As a rule, submissions in this course will not be graded until after they are due, even if submitted early. Students may resubmit assignments many times before the due date, and only the latest submission will be graded. For assignments submitted via GitHub release tag, only the tagged release that was submitted to Canvas will be graded, even if additional commits have been made. Students must create a new tagged release and resubmit that tag to have it graded for that assignment.
Once an assignment is graded, students are not allowed to resubmit the assignment for regrading or additional credit without special permission from the instructor to do so. In essence, students are expected to ensure their work is complete and meets the requirements before submission, not after feedback is given by the instructor during grading. However, students should use that feedback to improve future assignments and milestones.
For the programming project milestones, it is solely at the discretion of the instructor whether issues noted in the feedback for a milestone will result in grade deductions in a later milestones if they remain unresolved, though the instructor will strive to give students ample time to resolve issues before any additional grade deductions are made.
Likewise, students may ask questions of the instructor while working on the assignment and receive help, but the instructor will not perform a full code review nor give grading-level feedback until after the assignment is submitted and the due date has passed. Again, students are expected to be able to make their own judgments on the quality and completion of an assignment before submission.
That said, a student may email the instructor to request early grading on an assignment before the due date, in order to move ahead more quickly. The instructor’s receipt of that email will effectively mean that the assignment for that student is due immediately, and all limitations above will apply as if the assignment’s due date has now passed.
Collaboration Policy
In this course, all work submitted by a student should be created solely by the student without any outside assistance beyond the instructor and TA/GTAs. Students may seek outside help or tutoring regarding concepts presented in the course, but should not share or receive any answers, source code, program structure, or any other materials related to the course. Learning to debug coding problems is a vital skill, and students should strive to ask good questions and perform their own research instead of just sharing broken source code when asking for assistance.
Artificial Intelligence Usage Policy
This course uses a stoplight approach regarding the use of generative artificial intelligence (GenAI) tools, such as ChatGPT, Claude, Copilot, and others. Each assignment or group of assignments will be clearly labelled with one of three labels, indicating what level of GenAI usage is allowed.
Details
RED: GenAI Prohibited You may not use any GenAI tools to complete this assignment. This assignment's main goal is to develop your own skills related to a particular task or topic, or to assess your own understanding of the concepts and skills required for this course. GenAI tools are therefore prohibited for these assignments, as they do not reflect or enhance your own learning journey.
Policy Violations: Any usage of GenAI for this assignment will be treated as a violation of the K-State Honor Pledge and may result in a grade of 0 for the assignment and other sanctions approved through the K-State Honor Council.
Details
YELLOW: Limited GenAI Usage Allowed You may use GenAI tools in a limited way to complete this assignment. The assignment description may provide additional information about what tools are allowed and how they can be used. The goal of this assignment is to allow you to work with GenAI to complete a task or achieve a goal, but the completed work should still be a majority your own effort.
Citations Required: Any usage of GenAI must be noted and cited directly in the work, either in source code comments or text citations in written work. Citations should include the tool used, the prompt(s) given, context provided to the tool (e.g. existing code), and a discussion of how the results were used to complete the assignment.
No Direct AI Results: For this assignment, you may not include the GenAI results directly in your submission - it must be used to inform and adapted to fit your own work. For example, you may not prompt GenAI tools to just write your code and submit that directly; instead, you should ask for help performing specific tasks and then use the results within your own work.
Understand Your Work: To ensure compliance with this policy, the instructor reserves the right to request additional discussion or explanation of any work submitted by a student. The student should understand and be able to clearly explain all submitted work and code, even materials directly or indirectly produced by GenAI. A student who is unable to explain a submission to the satisfaction of the instructor may be considered to be in violation of this policy.
Policy Violations: Any usage of GenAI that involves direct submission of the GenAI outputs without additional work done by the student, or use of GenAI without proper citation, may be treated as a violation of the K-State Honor Pledge and may result in a grade of 0 for the assignment and other sanctions approved through the K-State Honor Council.
Details
GREEN: GenAI Encouraged You may make unlimited use of GenAI tools to complete this assignment. The goal of this assignment is to ensure you are comfortable with using GenAI tools to specifically meet a need or achieve a goal.
Citations Required: Any usage of GenAI must be noted and cited directly in the work, either in source code comments or text citations in written work. Citations should include the tool used, the prompt(s) given, context provided to the tool (e.g. existing code), and a discussion of how the results were used to complete the assignment.
Direct AI Results Allowed: For this assignment, you may include the GenAI results directly in your submission. It is still your responsibility to ensure the submission meets the assignment’s goals and is correct and factual - remember that GenAI is not infallible and may produce incorrect results. You are still solely responsible for ensuring the submission meets the stated assignment goals, and assignments in this category may receive additional scrutiny for correctness and accuracy.
Understand Your Work: To ensure compliance with this policy, the instructor reserves the right to request additional discussion or explanation of any work submitted by a student. The student should understand and be able to clearly explain all submitted work and code, even materials directly or indirectly produced by GenAI. A student who is unable to explain a submission to the satisfaction of the instructor may be considered to be in violation of this policy.
Policy Violations: Any usage of GenAI without proper citation may be treated as a violation of the K-State Honor Pledge and may result in a grade of 0 for the assignment and other sanctions approved through the K-State Honor Council.
Please contact the instructor if you have any questions about this GenAI policy. It is your responsibility to understand it and proactively ask questions if you are unsure; ignorance of this policy is not an excuse for violating it.
Artificial Intelligence Disclosure
In keeping with the expectation for transparency and citation regarding the use of generative artificial intelligence (GenAI), the instructors of this course will clearly denote any usage of GenAI tools in the process of teaching this class. Specific policies for the usage of GenAI by the instructors and TAs of this course are given below:
- RED: GenAI Prohibited Grading and Feedback - GenAI will never be used to review student submissions or produce grading feedback. All grades and feedback will be provided by the instructors and TAs without any GenAI assistance.
- RED: GenAI Prohibited Student Communication - GenAI will never be used to when communicating with students. We believe it is important for students to receive real, authentic communication from instructors and TAs
- YELLOW: Limited GenAI Usage Allowed Lesson & Learning Content - GenAI may be used in a limited way to construct lessons and learning content, such as homework scenarios or simple graphics. All usage of GenAI will be clearly marked and cited. (As of January 2026, no GenAI content exists in the course).
Late Work
Warning
Read this late work policy very carefully! If you are unsure how to interpret it, please contact the instructors via email. Not understanding the policy does not mean that it won’t apply to you!
Since this course is entirely online, students may work at any time and at their own pace through the modules. However, to keep everyone on track, there will be approximately one module due each week. Each graded item in the module will have a specific due date specified. Any assignment submitted late will have that assignment’s grade reduced by 10% of the total possible points on that project for each day it is late. This penalty will be assessed automatically in the Canvas gradebook. For the purposes of record keeping, a combination of the time of a submission via Canvas and the creation of a release in GitHub will be used to determine if the assignment was submitted on time.
However, even if a module is not submitted on time, it must still be completed before a student is allowed to begin the next module. So, students should take care not to get too far behind, as it may be very difficult to catch up.
Finally, all course work must be submitted on or before the last day of the semester in which the student is enrolled in the course in order for it to be graded on time.
If you have extenuating circumstances, please discuss them with the instructor as soon as they arise so other arrangements can be made. If you find that you are getting behind in the class, you are encouraged to speak to the instructor for options to make up missed work.
Incomplete Policy
Students should strive to complete this course in its entirety before the end of the semester in which they are enrolled. However, since retaking the course would be costly and repetitive for students, we would like to give students a chance to succeed with a little help rather than immediately fail students who are struggling.
If you are unable to complete the course in a timely manner, please contact the instructor to discuss an incomplete grade. Incomplete grades are given solely at the instructor’s discretion. See the official K-State Grading Policy for more information. In general, poor time management alone is not a sufficient reason for an incomplete grade.
Unless otherwise noted in writing on a signed Incomplete Agreement Form, the following stipulations apply to any incomplete grades given in this course:
- Students who request an incomplete will have their final grade capped at a C.
- Students will be given a maximum of 8 calendar weeks from the end of the enrolled semester to complete the course. It is expected that students have completed at least half of the course in order to qualify for an incomplete.
- Students understand that access to instructor and TA assistance may be limited after the end of an academic semester due to holidays and other obligations.
- Any modules in a future CC course which depend on incomplete work will not be accessible until the previous course is finished
- For example, if a student is given an incomplete in CC 210, then all modules in CC 310 will be inaccessible until CC 210 is complete
- If a student fails to resolve an incomplete grade after 8 weeks, they will be assigned an ‘F’ in the course. In addition, they will be dropped from any other Computational Core courses which require the failed course as a prerequisite or corequisite.
Recommended Texts & Supplies
To participate in this course, students must have access to a modern web browser and broadband internet connection. All course materials will be provided via Canvas and Codio. Modules may also contain links to external resources for additional information, such as programming language documentation.
Students will make use of GitHub for source code management.
Students may choose to do some development work on their own computer. The recommended software is Visual Studio Code along with access to a system running Ubuntu. For Windows systems, Ubuntu can be installed via the Windows Subsystem for Linux. For Mac systems, Ubuntu can be installed in a virtual machine through VirtualBox.
Subject to Change
The details in this syllabus are not set in stone. Due to the flexible nature of this class, adjustments may need to be made as the semester progresses, though they will be kept to a minimum. If any changes occur, the changes will be posted on the Canvas page for this course and emailed to all students. All changes may also be posted to Canvas.
Standard Syllabus Statements
Info
The statements below are standard syllabus statements from K-State and our program. The latest versions are available online here.
Academic Honesty
Kansas State University has an Honor and Integrity System based on personal integrity, which is presumed to be sufficient assurance that, in academic matters, one’s work is performed honestly and without unauthorized assistance. Undergraduate and graduate students, by registration, acknowledge the jurisdiction of the Honor and Integrity System. The policies and procedures of the Honor and Integrity System apply to all full and part-time students enrolled in undergraduate and graduate courses on-campus, off-campus, and via distance learning. A component vital to the Honor and Integrity System is the inclusion of the Honor Pledge which applies to all assignments, examinations, or other course work undertaken by students. The Honor Pledge is implied, whether or not it is stated: “On my honor, as a student, I have neither given nor received unauthorized aid on this academic work.” A grade of XF can result from a breach of academic honesty. The F indicates failure in the course; the X indicates the reason is an Honor Pledge violation.
For this course, a violation of the Honor Pledge will result in sanctions such as a 0 on the assignment or an XF in the course, depending on severity. Actively seeking unauthorized aid, such as posting lab assignments on sites such as Chegg or StackOverflow, or asking another person to complete your work, even if unsuccessful, will result in an immediate XF in the course.
This course assumes that all your course work will be done by you. Use of AI text and code generators such as ChatGPT and GitHub Copilot in any submission for this course is strictly forbidden unless explicitly allowed by your instructor. Any unauthorized use of these tools without proper attribution is a violation of the K-State Honor Pledge.
We reserve the right to use various platforms that can perform automatic plagiarism detection by tracking changes made to files and comparing submitted projects against other students’ submissions and known solutions. That information may be used to determine if plagiarism has taken place.
Students with Disabilities
At K-State it is important that every student has access to course content and the means to demonstrate course mastery. Students with disabilities may benefit from services including accommodations provided by the Student Access Center. Disabilities can include physical, learning, executive functions, and mental health. You may register at the Student Access Center or to learn more contact:
- Manhattan/Olathe/Global Campus – Student Access Center
- K-State Salina Campus – Julie Rowe; Student Success Coordinator
Students already registered with the Student Access Center please request your Letters of Accommodation early in the semester to provide adequate time to arrange your approved academic accommodations. Once SAC approves your Letter of Accommodation it will be e-mailed to you, and your instructor(s) for this course. Please follow up with your instructor to discuss how best to implement the approved accommodations.
Expectations for Conduct
All student activities in the University, including this course, are governed by the Student Judicial Conduct Code as outlined in the Student Governing Association By Laws, Article V, Section 3, number 2. Students who engage in behavior that disrupts the learning environment may be asked to leave the class.
Mutual Respect and Inclusion in K-State Teaching & Learning Spaces
At K-State, faculty and staff are committed to creating and maintaining an inclusive and supportive learning environment for students from diverse backgrounds and perspectives. K-State courses, labs, and other virtual and physical learning spaces promote equitable opportunity to learn, participate, contribute, and succeed, regardless of age, race, color, ethnicity, nationality, genetic information, ancestry, disability, socioeconomic status, military or veteran status, immigration status, Indigenous identity, gender identity, gender expression, sexuality, religion, culture, as well as other social identities.
Faculty and staff are committed to promoting equity and believe the success of an inclusive learning environment relies on the participation, support, and understanding of all students. Students are encouraged to share their views and lived experiences as they relate to the course or their course experience, while recognizing they are doing so in a learning environment in which all are expected to engage with respect to honor the rights, safety, and dignity of others in keeping with the K-State Principles of Community.
If you feel uncomfortable because of comments or behavior encountered in this class, you may bring it to the attention of your instructor, advisors, and/or mentors. If you have questions about how to proceed with a confidential process to resolve concerns, please contact the Student Ombudsperson Office. Violations of the student code of conduct can be reported using the Code of Conduct Reporting Form. You can also report discrimination, harassment or sexual harassment, if needed.
Netiquette
Info
This is our personal policy and not a required syllabus statement from K-State. It has been adapted from this statement from K-State Online, and theRecurse Center Manual. We have adapted their ideas to fit this course.
Online communication is inherently different than in-person communication. When speaking in person, many times we can take advantage of the context and body language of the person speaking to better understand what the speaker means, not just what is said. This information is not present when communicating online, so we must be much more careful about what we say and how we say it in order to get our meaning across.
Here are a few general rules to help us all communicate online in this course, especially while using tools such as Canvas or Discord:
- Use a clear and meaningful subject line to announce your topic. Subject lines such as “Question” or “Problem” are not helpful. Subjects such as “Logic Question in Project 5, Part 1 in Java” or “Unexpected Exception when Opening Text File in Python” give plenty of information about your topic.
- Use only one topic per message. If you have multiple topics, post multiple messages so each one can be discussed independently.
- Be thorough, concise, and to the point. Ideally, each message should be a page or less.
- Include exact error messages, code snippets, or screenshots, as well as any previous steps taken to fix the problem. It is much easier to solve a problem when the exact error message or screenshot is provided. If we know what you’ve tried so far, we can get to the root cause of the issue more quickly.
- Consider carefully what you write before you post it. Once a message is posted, it becomes part of the permanent record of the course and can easily be found by others.
- If you are lost, don’t know an answer, or don’t understand something, speak up! Email and Canvas both allow you to send a message privately to the instructors, so other students won’t see that you asked a question. Don’t be afraid to ask questions anytime, as you can choose to do so without any fear of being identified by your fellow students.
- Class discussions are confidential. Do not share information from the course with anyone outside of the course without explicit permission.
- Do not quote entire message chains; only include the relevant parts. When replying to a previous message, only quote the relevant lines in your response.
- Do not use all caps. It makes it look like you are shouting. Use appropriate text markup (bold, italics, etc.) to highlight a point if needed.
- No feigning surprise. If someone asks a question, saying things like “I can’t believe you don’t know that!” are not helpful, and only serve to make that person feel bad.
- No “well-actually’s.” If someone makes a statement that is not entirely correct, resist the urge to offer a “well, actually…” correction, especially if it is not relevant to the discussion. If you can help solve their problem, feel free to provide correct information, but don’t post a correction just for the sake of being correct.
- Do not correct someone’s grammar or spelling. Again, it is not helpful, and only serves to make that person feel bad. If there is a genuine mistake that may affect the meaning of the post, please contact the person privately or let the instructors know privately so it can be resolved.
- Avoid subtle -isms and microaggressions. Avoid comments that could make others feel uncomfortable based on their personal identity. See the syllabus section on Diversity and Inclusion above for more information on this topic. If a comment makes you uncomfortable, please contact the instructor.
- Avoid sarcasm, flaming, advertisements, lingo, trolling, doxxing, and other bad online habits. They have no place in an academic environment. Tasteful humor is fine, but sarcasm can be misunderstood.
As a participant in course discussions, you should also strive to honor the diversity of your classmates by adhering to the K-State Principles of Community.
SafeZone Ally
I am part of the SafeZone community network of trained K-State faculty/staff/students who are available to listen and support you. As a SafeZone Ally, I can help you connect with resources on campus to address problems you face that interfere with your academic success, particularly issues of sexual violence, hateful acts, or concerns faced by individuals due to sexual orientation/gender identity. My goal is to help you be successful and to maintain a safe and equitable campus.
Discrimination, Harassment, and Sexual Harassment
Kansas State University is committed to maintaining academic, housing, and work environments that are free of discrimination, harassment, and sexual harassment. Instructors support the University’s commitment by creating a safe learning environment during this course, free of conduct that would interfere with your academic opportunities. Instructors also have a duty to report any behavior they become aware of that potentially violates the University’s policy prohibiting discrimination, harassment, and sexual harassment, as outlined by PPM 3010.
If a student is subjected to discrimination, harassment, or sexual harassment, they are encouraged to make a non-confidential report to the University’s Office of Civil Rights and Title IX (OCR & TIX) using the online reporting form. Incident disclosure is not required to receive resources at K-State. Reports that include domestic and dating violence, sexual assault, or stalking, should be considered for reporting by the complainant to the Kansas State University Police Department or the Riley County Police Department. Reports made to law enforcement are separate from reports made to OIE. A complainant can choose to report to one or both entities. Confidential support and advocacy can be found with the K-State Center for Advocacy, Response, and Education (CARE). Confidential mental health services can be found with Lafene Counseling and Psychological Services (CAPS). Academic support can be found with the Student Support and Accountability (SSA) office. SSA is a non-confidential resource. OCR & TIX also provides a comprehensive list of resources on their website. If you have questions about non-confidential and confidential resources, please contact OCR & TIX at civilrights@k-state.edu or (785) 532–6220.
Academic Freedom Statement
Kansas State University is a community of students, faculty, and staff who work together to discover new knowledge, create new ideas, and share the results of their scholarly inquiry with the wider public. Although new ideas or research results may be controversial or challenge established views, the health and growth of any society requires frank intellectual exchange. Academic freedom protects this type of free exchange and is thus essential to any university’s mission.
Moreover, academic freedom supports collaborative work in the pursuit of truth and the dissemination of knowledge in an environment of inquiry, respectful debate, and professionalism. Academic freedom is not limited to the classroom or to scientific and scholarly research, but extends to the life of the university as well as to larger social and political questions. It is the right and responsibility of the university community to engage with such issues.
Campus Safety
Kansas State University is committed to providing a safe teaching and learning environment for student and faculty members. In order to enhance your safety in the unlikely case of a campus emergency make sure that you know where and how to quickly exit your classroom and how to follow any emergency directives. Current Campus Emergency Information is available at the University’s Advisory webpage.
Weapons Policy
Kansas State University prohibits the possession of firearms, explosives, and other weapons on any University campus, with certain limited exceptions, including the lawful concealed carrying of handguns, as provided in the University Weapons Policy.
You are encouraged to take the online weapons policy education module to ensure you understand the requirements of the policy, including the requirements related to concealed carrying of handguns on campus. Students possessing a concealed handgun on campus must be lawfully eligible to carry and either at least 21 years of age or a licensed individual who is 18-21 years of age. All carrying requirements of the policy must be observed in this class, including but not limited to the requirement that a concealed handgun be completely hidden from view, securely held in a holster that meets the specifications of the policy, carried without a chambered round of ammunition, and that any external safety be in the “on” position.
If an individual carries a concealed handgun in a personal carrier such as a backpack, purse, or handbag, the carrier must remain within the individual’s exclusive and uninterrupted control. This includes wearing the carrier with a strap, carrying or holding the carrier, or setting the carrier next to or within the immediate reach of the individual.
During this course, you will be required to engage in activities, such as interactive examples or sharing work on the whiteboard, that may require you to separate from your belongings, and thus you should plan accordingly.
Each individual who lawfully possesses a handgun on campus shall be wholly and solely responsible for carrying, storing and using that handgun in a safe manner and in accordance with the law, Board policy and University policy. All reports of suspected violation of the weapons policy are made to the University Police Department by picking up any Emergency Campus Phone or by calling 785-532-6412.
Student Resources
K-State has many resources to help contribute to student success. These resources include accommodations for academics, paying for college, student life, health and safety, and others. Check out the Student Guide to Help and Resources: One Stop Shop for more information.
Student Academic Creations
Student academic creations are subject to Kansas State University and Kansas Board of Regents Intellectual Property Policies. For courses in which students will be creating intellectual property, the K-State policy can be found at University Handbook, Appendix R: Intellectual Property Policy and Institutional Procedures (part I.E.). These policies address ownership and use of student academic creations.
Mental Health
Your mental health and good relationships are vital to your overall well-being. Symptoms of mental health issues may include excessive sadness or worry, thoughts of death or self-harm, inability to concentrate, lack of motivation, or substance abuse. Although problems can occur anytime for anyone, you should pay extra attention to your mental health if you are feeling academic or financial stress, discrimination, or have experienced a traumatic event, such as loss of a friend or family member, sexual assault or other physical or emotional abuse.
If you are struggling with these issues, do not wait to seek assistance.
For Kansas State Salina Campus:
For Global Campus/K-State Online:
University Excused Absences
K-State has a University Excused Absence policy (Section F62). Class absence(s) will be handled between the instructor and the student unless there are other university offices involved. For university excused absences, instructors shall provide the student the opportunity to make up missed assignments, activities, and/or attendance specific points that contribute to the course grade, unless they decide to excuse those missed assignments from the student’s course grade. Please see the policy for a complete list of university excused absences and how to obtain one. Students are encouraged to contact their instructor regarding their absences.
Copyright Notice
© The materials in this online course fall under the protection of all intellectual property, copyright and trademark laws of the U.S. The digital materials included here come with the legal permissions and releases of the copyright holders. These course materials should be used for educational purposes only; the contents should not be distributed electronically or otherwise beyond the confines of this online course. The URLs listed here do not suggest endorsement of either the site owners or the contents found at the sites. Likewise, mentioned brands (products and services) do not suggest endorsement. Students own copyright to what they create.
Plagiarism Policy
YouTube Video
Resources
Video Script
“On my honor, as a student, I have neither given nor received unauthorized aid on this academic work.” - K-State Honor Pledge
Plagiarism is a very serious concern in this course, and something that we do not take lightly. Computer programs and code are especially easy targets for plagiarism due to how easy it is to copy and manipulate code in such a way that it is unrecognizable as the original source but still performs correctly.
At its core, plagiarism is taking someone else’s work and passing it off as your own without giving appropriate credit to the original source. As a student at K-State, you are bound by the K-State Honor Code not to accept any unauthorized aid, and this includes plagiarized code.
When it comes to plagiarism in computer code, there is a fine line between using resources appropriately and copying code. In this program, you should strive to avoid plagiarism issues by doing the following:
- Do not search for or use any complete solutions to projects in this course found online or from fellow students.
- Small portions of code may be used or adapted from an online source with proper citation. To cite a piece of code, include a code comment section above it that contains the original source URL and a description of why it was used.
In general, copying or adapting small pieces of code to perform auxiliary functions in the assignment is permitted. Copying or adapting code that is the general goal of the assignment should be avoided. For example, if the assignment is to create a bubble sort algorithm, you should write the algorithm from scratch yourself since that is the goal of the assignment. If the assignment is to create a program for displaying data that you feel should be sorted, you may choose to adapt an existing sorting algorithm for your needs (or use one from a library).
If you aren’t sure about whether it is OK to use an online resource or piece of code in this course, please contact the instructors using the course discussion forums or help email address. You will not get in trouble for asking, and it will help you determine what the best course of action is. Plagiarism can really only occur when you submit the assignment for grading, so you are welcome to ask for clarification or a judgement on whether a particular usage is acceptable at any time before you submit the assignment.
Codio has features that will compare your submissions against those of your fellow students. Any submissions with a high degree of similarity may be subjected to additional scrutiny by the instructors to determine if plagiarism has occurred.
In this course, any violation of the K-State Honor Code will result in a 0 on that assignment and a report made to the K-State Honor Council. A second violation will result in an XF in this course, as well as any additional sanctions imposed by the K-State Honor Council.
For more information on the K-State Honor & Integrity system, please visit their website, which is linked in the resources section below this video.
GenAI Policy
YouTube Video
Resources
Video Transcript
In this video, I want to take a few minutes to discuss the generative artificial intelligence or Gen AI policy in this course. The use of generative artificial intelligence in coding is vastly becoming one of the most important things to learn how to do in industry. But at the same time, from an educational perspective, it produces a lot of struggles because using generative AI really shortcuts the learning process. And so it means you don’t learn the concepts quite as clearly if you had to do them yourself. There’s this concept in education called the productive struggle, where sometimes to really learn something well, you have to struggle your way through it the first few times before you finally get it. And so by relying too heavily on Gen AI to just get over that hump, you end up not learning the content quite as well as we’d like. And so from my perspective as an educator, I want you to learn how to use these tools effectively, but at the same time, I want to build your own skills so that you’re not wholly reliant on using these tools. I think they will make you a much better employee, a much better programmer down the road. And I think as these tools continue to change and modify, the more innate skill you have and the less you are dependent on the current generation of Gen AI, the better programmer you’re going to be down the road. And so that’s really the impetus behind this policy. And I want to take a little time to explain how I’m applying this policy so that you really understand where I’m coming from and how we’re going to work with it in this course.
So to make things really simple for Gen AI, I’ve adapted a three-tier policy that’s a stoplight policy for using Gen AI. Every assignment in this course is going to have a stoplight symbol with one of the three colors illuminated. It will also have some text description on it as well. And so it basically describes my expectation for how you should or should not use Gen AI in this course. Obviously, items that are marked as red, Gen AI use is prohibited. Items marked in yellow, you can make limited use of Gen AI. And items marked in green, you are encouraged to make full use of Gen AI. So let’s talk about these different levels.
The first level is red, where Gen AI is prohibited. Generally, you’re going to find items marked in red being the quizzes, being things like concept quizzes, and being the interactive examples. A lot of the reason I do that is because the examples are there to help you develop new skills. And so I really want you to go through all of the steps yourself. And then for the quizzes and concept quizzes, those are my assessments of your learning and understanding in this course. They’re not too heavily weighted towards your grade, so I really want to know what you understand and not what you can get ChatGPT to print out for you. And so those items are going to be marked in red. Any violations of the Gen AI policy in these items is going to result in a grade of zero immediately on the assignment and possibly referral to the Honor Council. Obviously, from my perspective, catching someone using Gen AI can be difficult in this course. And so there’s a little bit of back and forth. But the way that I generally do this is by asking you to discuss your work. And we’ll talk about that a little bit later. But sometimes it’s pretty obvious when I get an answer that is not anything we’ve covered in this course. It’s not using any of the terminology or anything that I’ve covered in the textbook. It sounds like it’s just regurgitated from an online source. Those answers will kind of get more scrutiny under this policy. So be aware, try not to use Gen AI. I know it’s really easy to do, but please try and follow this guide, especially on these assessments, so that I can really understand where your learning is and what your gaps are so I can help you get over those as we work through this course.
So the next policy is yellow. Yellow, I allow limited use of Gen AI to complete a task or achieve a goal. What I want you to think about is think of Gen AI as a partner that you can ask questions, that you can get advice from, that you can say, hey, hey, ChatGPT, how do I do this thing? And have it describe it to you and help you understand what’s going on. However, the assignment that you turn in for this, I still want it to be a majority of your own work. And so you’re not allowed to take the output of Gen AI and just directly copy it into your assignment. It’s really easy to ask Gen AI to write a piece of code for you and you just plop it into your assignment. I don’t want you to do that with these yellow items. Instead, you can ask ChatGPT. You can even have it print out code. But then I want you to take that code and adapt it to fit your scenario and make it your own work. A lot of times the only way you’re going to understand this code is by actually writing it and working with it yourself. And so I want you to be able to do that, but still have the opportunity to use Gen AI to help explain code, help explain concepts. It can be a really, really powerful tool and a tutor. And so when I mark things as yellow, I want you to think of Gen AI as a tutor or a partner that you can work with, but you still can’t just copy paste their code. You can’t have them do your homework for you, but you can interact with them to try and understand things. So for this policy, if you do use Gen AI in any way, I want you to include citations in your code or in your written assignments for this. I’ll talk about citations a bit later. You should not use any AI results directly in your work. So no copy-pasting answers from AI or code from AI. You should adapt it in your own words. And then once again, any violations of this policy will receive a grade of zero and possibly a referral to the Honor Council.
Finally, the last policy is green. Green is when I encourage you to use Gen AI to fully complete a task. You can just tell Gen AI, hey, do this for me, help me build this, write this code for me. Gen AI is not perfect, and so you’ll have to do some work to ensure accuracy. But a lot of times I allow you to use full use of Gen AI when we’re either doing something that’s highly repetitive or something that’s creative or design-based. This is not really a UI design course. It’s not really a UX design course. And so if you want to do things like have Gen AI help you make cool buttons and pretty colors and better interactivity and stuff on your web apps and on your GUI apps, that’s fine. That’s not really one of the points of this course. As long as you get the functionality working, the actual bells and whistles, you can use Gen AI to work on that. So again, if you do use Gen AI, citations are required. We’ll talk about that in a second. But this one, the difference between green and yellow is in green. Direct AI results can be submitted as your work. Again, it needs to be cited, but you can just copy paste the code from Gen AI. And then, of course, once again, violations will be referred to the Honor Council. Violations of this policy would be including work from Gen AI that is not cited. That’s really going to be the violation here.
The last big thing about this, at all three levels, you are expected to understand any submitted work. Any code that you submit, whether you wrote it, whether Gen AI wrote it, whether you follow the policy or not, you are expected to understand every single piece of code that you submit in this class. If I have a suspicion that you are using Gen AI that you shouldn’t be or you’re not citing it or I see code that I don’t understand, I may at any time ask you to meet with me on Zoom and explain different pieces of your code to me and explain how it works and what your thought process was as you were putting that together. As a programmer, you need to be able to do this. If you’re putting together code and just throwing code out there that you don’t understand, that’s not really effective. That’s not doing any good. And so I generally don’t want to do this very often, but I would imagine throughout the semester, most of you, I will have a couple of these meetings with you just to get a feel for how you’re doing. I will expect you to be able to explain things. And if you cannot explain it and I feel like that you really submitted code that you don’t understand, I could consider you in violation of this policy and have to issue sanctions on that. Again, proving that you have used Gen AI is really, really difficult. There are not any good tools out there that can just look at a piece of code and say that it’s built by Gen AI. It’s a lot of circumstantial evidence. But in my mind, even if you didn’t use Gen AI, if you’re submitting code that you don’t understand, that’s not any good in this course. And so I feel like that alone should be worth a zero because you really didn’t understand what you’re doing. So that’s really where this part of the policy comes from is you really need to understand what you’re coding, what you’re submitting, what you’re turning in. And if you don’t, work with me, work with ChatGPT if you’re allowed to do that and really make sure you understand what’s going on so that when you’re submitting code, you’re confident and able to explain it. Part of this is going to be comments. If you leave good comments in your code, you’re going to be able to explain it a lot better because you talked your way through it yourself when you wrote the code. So those are some things I want to see there.
Now let’s talk about a couple of citations. There is no real format for proper citations for Gen AI yet. I’m kind of hoping that some people come up with something. This is what I’d like to see. And so there are four big parts of a Gen AI citation. The first big thing is I want to know what tool you’re using. And so the tool, I’ve got OpenAI Chat GPT, the company, the tool, and then what language model it’s using. So this language model is using GPT 5.2. And then I just put in parentheses the date, the month, and the year when I worked with it. That way I kind of have an idea of when you were doing this. The prompt is whatever prompt you put into the text field. It’s whatever you did. The context is any additional context you provided to the AI, especially when you’re working with a coding agent like ChatGPT Copilot and Claude. You can give it access to individual code files. You can give it access to your entire code base. And so I want to know what context you provided as part of this chat. And then finally, I want you to discuss the usage of the output. You don’t necessarily have to list the full output because that’s going to be really long, but I want you to discuss how you took that output and applied it in your assignment following the policy that was set out for that assignment. So this is an example of if the policy was yellow, if you could have limited Gen AI usage. So you said, here, I use the output of ChatGPT to understand how the tool works and what limitations it presents. And then paraphrase that output in your discussion where cited. That’s great. That tells me a lot about you ask ChatGPT some questions, you use the output, but you put it in your own words.
This is an example of a more full-featured Gen AI usage if the policy is green. So here I was using GitHub Copilot with Claude and I asked it to help me write unit tests for an entree class. And so it described some of the unit tests. I gave it a context of the unit tests from the milestone assignment and also my existing source code. And then it was able to actually look at that code, look at that assignment and scaffold the unit tests. And then after that, I ensured each test was accurate and complete. Claude especially tends to hallucinate unit tests that are either trivially true or trivially false. And so it doesn’t actually do a good job of testing code sometimes. Sometimes it really does, but sometimes it make a test that, you know, true equals true. It’s not really useful. So I looked at each of the tests, made sure they were accurate, and edited it to make sure that it actually exercised all the code paths. So again, this makes me feel really comfortable of how you were using Claude, how you asked it to do things, and how you adapted and made those results your own in the work itself. So finally, hopefully this makes sense.
This is really, I’m recording this in January 2026. This is really a new policy that we’re trying to get a better handle on the use of Gen AI tools in programming. And I think that CC410 is a really great opportunity to take the training wheels off a little bit and let you openly use some of these tools in an effective way while still adding some of the guardrails to make sure that you’re really learning what you should be learning. And like I said, this is a balance between learning how to use the tools that you will undoubtedly use in industry, but also making sure that we’re not graduating students out of this program that only know how to use these tools and don’t really understand programming. That’s what we’re really trying to help you with. You know, the goal in education is not to get 100% on the assignment. The goal is to actually learn something. And then the 100% on the assignment is you proving that you learned it. So that’s really what I’m coming from on this policy. If you have questions or concerns or want to learn more about this policy, please contact me and ask for clarification. I would be happy to chat with you. Asking will not get you in trouble. If you’re like, hey, I want to do this for my assignment, but I’m not sure if I can. Is this okay or not? I will not come down on you and issue a policy violation just because you did not do things correctly. It’s only when you submit things that there will be policy violations. Asking me for clarification or, hey, I did this. Is this okay? That’s not going to get you in trouble. And like I said in my intro video, ignorance of this policy is not an excuse for violations. Just because you’re like, oh, I didn’t know I couldn’t do that. That’s not an excuse for violations. I’ve tried to make this very clear. So hopefully we don’t have any problems in this class, but I want to be very open about my approach to this and what you’re going to see from me throughout this semester. So hopefully this is useful to you. If you have any questions or concerns, please let me know. Otherwise, best of luck in this course. And I look forward to seeing all of the interesting ways that you’re able to use Gen AI where allowed in this course.
Codio Projects
YouTube Video
Resources
Video Script
At this point, you should have completed the “Hello Real World” example project. This module contains GitHub Classroom assignments and Codio projects for the rest of this course. In this video, I’ll briefly explain what these are for and how they work. As always, if you have any questions or are unsure what to do, contact the instructors via cc410-help for assistance.
Looking at this module, the first item you should see is the Codio Playground. This is a blank Codio project that you can use for just about anything. You can explore Codio’s interface, test new code snippets, and try new development tools. This Codio project starts with exactly the same setup as the two other projects in this course, so you’ll have the same experience here as in the others. Finally, if you ever have issues or want to start over, just contact the instructors and ask them to reset your playground project. Of course, you’ll lose all your content, but it is a great way to try things and make mistakes until you get them right.
The next four items in this module are for the two major programming projects in this course - the restaurant project and the final project. Before we discuss those individually, let’s talk about what they have in common. Both of those projects have a matching assignment in GitHub classroom that you’ll need to accept, just like you did for the Hello Real World project. Once you’ve accepted that assignment, you can clone the assignment’s repository into the associated Codio project and get started coding. Feel free to follow the guide from the Hello Real World project to set up your environment. You can even copy and paste the content from Hello Real World into these projects and use that as a starting point! For these two projects, you’ll be using the same Codio project all semester, which can always be accessed through this module. We’ve placed it toward the top of the module list so it is easy to get to quickly. Once you’ve completed a milestone for a project, you’ll follow the steps you learned in the Hello Real World project to create a release on GitHub, and then submit that URL via Canvas to complete the milestone assignment. The instructors will give you grades and feedback within a couple of days, but you’ll be able to move on and start working on the next milestone immediately. You can always update your release later with a new version if needed. Finally, this course will move pretty quickly, so you can expect to complete around 1 project milestone each week, in addition to the tutorials and examples for that week’s module. Most examples won’t be nearly as big as Hello Real World, but they’ll still require an hour or so of work.
Now, let’s talk about the individual projects. First, we have the restaurant project. In this project, we’ll build a point-of-sale system for a fictional restaurant. This is a guided project, and you’ll follow along with the tutorials and examples to complete each milestone. We’ll show you be basics, and then you’ll continue to build upon that in each milestone. There will be several milestones to complete for this project, and they include building a class library using object-oriented programming concepts, building a useful graphical user interface or GUI, and learning how to access and build your own web APIs to extend the usefulness of the project. So, starting in Module 2, you’ll learn all about building a class library and start working toward the first milestone.
There will also be a final project in this course. This is a self-directed programming project, where you get to choose the project and what it will do. This project will include just a few milestones spread throughout the course, roughly designed to coincide with work you are doing on the restaurant project. For this project, you will be asked to find a topic that fits with your interests. A good place to look would be within your major or concentration, but it could be anything that interests you. At the end of the semester, you’ll develop a presentation and present your work to the class. For students completing the CS certificate or in the integrated CS program, this project will also serve as a capstone project for those programs. Watch the course announcements and later modules for more information about the structure and requirements of the final project.
So, when you are ready to begin a project, where should you start? Here’s a quick rundown of the steps we recommend following. First, accept the assignment via GitHub classroom to create your own private repository for the code. Then, open the associated Codio project from this module, and follow the steps outlined in the Hello Real World example to set up the project. When you are asked to clone the GitHub repository, make sure you use the URL for correct assignment repository that you accepted in an earlier step. Then, once your project is all set up, write your code in Codio and make commits to the Git repository as you go. We highly recommend committing code often, usually many times per day, as it makes it easier to undo mistakes and fix bugs later on. Once you’ve completed work on a project milestone, follow the steps in the Hello Real World example project to create a GitHub release, and then submit the URL for that release to the project milestone assignment on Canvas. You will not submit the Codio project like you did in earlier CC courses - instead, you’ll be able to keep using the same Codio project for the entire semester. You’ll just create and submit additional GitHub releases for later milestones.
Hopefully that all makes sense, but if not feel free to forge ahead and ask questions as you go. At this point, you are ready to skip ahead to Module 2 in Canvas and start there. In that module, you’ll complete a tutorial and example, and then you’ll see the requirements for a project milestone. Once you are there, come back to this module and open up the relevant Codio project to start working on that milestone. Once you’ve completed work on that milestone, create a release in GitHub and submit the URL back in the milestone assignment in the module you are working in to complete it and move on to the next module. Once you’ve done this process a couple of times, it should be pretty easy to follow.
Finally, don’t forget to check the bottom of the Modules list in Canvas to find some additional content that may be useful in this course. We’ve included links to the textbooks for all prior CC courses, as well as a set of helpful Codio tutorials for learning the Linux command line. The first four are especially useful if you’ve not used Linux or the Linux terminal before. We’ll also be adding links to tutorials and helpful information for learning how to use tools like Git and GitHub, as well as some information for setting up your own integrated development environments, or IDEs, on your own computers. While all the work in this course can be done via Codio, you are welcome to use your own tools if you prefer, provided your project meets all the requirements. Basically, if it works in Codio, it should be fine.
Since this is a new course, we’re always looking for feedback. So, as you go through this course and work on the project milestones, please feel free to contact us via the cc410-help email address if you have any comments or suggestions for how we could better organize or explain the information in this course. You could even earn some “bug bounty” extra credit points!
So, feel free to move directly on to Module 2 in Canvas and start there, then come back here to begin working on the projects once you reach the appropriate points in the course. As always, if you have any questions, please let us know. Good luck!
Subsections of Extras
Installing Git on Windows
YouTube Video
Resources
Video Script
Hello and welcome to the first of a series of videos where I’m going to show you everything you need to know to be able to bring your CC 410 projects and other Computational Core projects outside of Codio and onto your local system. For these videos, I’m doing this all on Windows, which is the most complicated system to set up. For Mac and Linux users, there are similar things that you can do on those systems. If you want me to cover those in a future video, just let me know, and I’d be happy to do that, or you can find really good documentation online. In this video, we’re going to go through installing the Git tool on Windows and also how we can connect it to GitHub and download our projects using Git. So let’s get started with that.
On this system, I have a relatively recent version of Windows 10 that is fully updated, and I have downloaded a lot of the tools that we’re going to need for this project. The first tool I’ve downloaded is the Git tool which is available from the Git website. This is the 64-bit Windows Installer version, and I’m briefly going to go through the process of installing that tool. The Git installer presents many different options that you can choose from here, I’m going to make sure I choose the options for Windows Explorer integration, as well as the default associations. If you use the new Windows terminal, you can also check mark this option to have Git Bash added directly to your Windows terminal. Git will also ask you what you want to use as the default text editor. It defaults to the vim option, which I find to be the most difficult editor to use. If you have one of these other text editors installed, you can choose that or if nothing else, I’m going to choose the nano editor, which we’ve seen in Codio, to use that by default. You can also let Git decide whether it should use the name “master” for the default branch or a different branch names such as “main,” I’m going to go ahead and choose this option for it to use the “main” branch for any new projects that it creates. Likewise, Git gives you the option to use Git from Git Bash only or from third party software or from other tools, I’m going to choose the recommended option to allow me to use Git from the command line and also from third party software. We’re also going to choose to use the openSSH that is bundled in the Git installer instead of an external version. We will do the same with the openSSL library. We’ll also choose to check out Windows style line endings, but commit Unix style line endings. This makes our repositories a lot more compatible between Windows and Linux versions. And it makes it easier for Windows text editors to edit these files. We’ll allow Git to use minTTY as the default terminal and will use all of the other default behaviors. Once we’ve selected that, Git will go through the process of installing and we can move on to the next step.
Once Git has finished installing, I can check mark the option to launch Git Bash, which will let us load the Git terminal and we can make a couple other adjustments. The default Git Bash window looks an awful lot like a Linux terminal. It’s a small version of Linux that runs within Windows to make things easier to work with, although all of these Git commands will also work in the default Windows command prompt and in PowerShell. As with any Git installation, the first thing we need to do is configure our name and our email address using the Git configuration options. Once we run these two commands, Git will be configured with our username and our email address, which will get attached to any commits that we make. Now we need to generate an SSH key so that we can connect it to GitHub and be able to access our repositories directly. To do that, we’ll use the command ssh-keygen. And then we’ll simply press Enter for all of the options. Once it’s done, it will generate an SSH key for us. We can find that key by typing cat .ssh/id_rsa.pub. This is the SSH public key that we will copy and paste into GitHub so that we can access those files directly.
At this point, I’m going to close Git Bash, and I’m going to instead open PowerShell. Here in PowerShell, if we installed Git correctly, we should also have access to the Git command here. It looks like it’s working. So now I’m going to use Git to check out a couple of our CC 410 projects so that we can use those in the later videos. For the rest of the videos in the series, I’m going to use the model solutions for example nine in CC 410. So to check those out, I’m going to do git clone, followed by the SSH URL of that repository, and I’m cloning it directly into my home folder. There we go. That’s all it takes to install Git on Windows. In the next videos we’ll look at installing either Python or Java and configure using an IDE for each of those languages.
Installing Python
YouTube Video
Resources
Video Script
In this video, we’re going to go through the process of installing Python on Windows and configuring it to work with our CC 410 projects. To begin, I’ve downloaded the latest Python installer from the Python website, and I’m going to run that installer to install Python on Windows. In the Python installer, there are a couple of options that are not checked by default that we absolutely want to make sure we check. First, I’m going to check mark the option at the bottom that says Add Python 3.10 to PATH, which allows me to use Python in tools such as PowerShell, as well as additional IDEs. I’m also going to click the Customize Installation option to change a few of the other options. The first page I’m going to leave everything is the default. And then on the second page, I’m going to check mark the option that says install for all users. That will place Python in the C:\Program Files\Python folder instead of buried somewhere else. With that, I’ll click install and it will install Python. Once Python is installed, we’ll click Close to close the installer. We don’t need to disable the path length limit for most of our projects, but this is something you could do if you find you run into trouble later on.
To test Python on Windows, I’m going to open PowerShell. In PowerShell, we can type the command python followed by --version to see the version of Python that’s installed. Notice that on Windows, it uses the python command instead of python3. If you’ve installed it the way I’ve shown, the python3 command will instead send you to the Windows Store to install an older version of Python. We don’t want to do this. It’s unfortunate that this is how Python handles Python version three versus the Python command itself. But it’s something to be aware of. So on Windows, we always want to use the Python command if we if we’ve installed Python following the method I’ve shown here.
So now I’m going to open up my project that I downloaded from Git, and I should be able to run it. However, Python has one unique thing that we should talk about, which is the idea of environments. In Python, when we install all of our Python libraries, by default, they’ll get installed for the user across all of our Python projects. This can be a problem if we want to have multiple projects on our system, and so it’s considered a best practice to create a virtual environment in Python, and use that when we run our code. So to create a virtual environment in Python, I’m going to run the python command -venv for virtual environment. And then the argument that you give after that is the location to store your virtual environments. By convention, we typically use the folder name .venv, to store our virtual environment. So at this command, Python will create a new virtual environment for us containing all of the Python executables, and this will be a place where we can install all of our Python libraries just for this project. It’s also really nice because both the PyCharm and Visual Studio Code are able to detect this folder and — and automatically use that virtual environment for us. Once the virtual environment is created, we need to actually activate it in our terminal session in order to use it. In PowerShell, we will run the command .venv/Scripts/activate.ps1. When we try to run this script, however, PowerShell says that scripts are disabled on our system.
So we need to first allow scripts in order to be able to use this virtual environment. To do that, we’re going to open another PowerShell window, but this time we’re going to run it as Administrator. In the administrator PowerShell, we’re going to type the command Set-ExecutionPolicy Unrestricted. By setting the execution policy to unrestricted, it will allow us to run scripts directly on the system. When we do this, it will pop up a message and we will type Y to say yes, we would like to turn this off. Once we’ve done that, we can close PowerShell and we can close and reopen our basic PowerShell window to actually see the change.
To load our virtual environment, we will change directory into the project folder where the venv is located. I can confirm that we see that folder using ls, and then we can activate the environment by using .venv/Scripts/activate.ps1. If we did this correctly, we should sound now see the name of our virtual environment, the .venv folder here at the beginning of our PowerShell terminal. It’s really important to always make sure we see this before we try and run any Python commands for this project. Later on when we work with our IDEs, we’ll see how they do this automatically.
At this point, we now have our virtual environment. So we can now run our project. The first step is to install all of our requirements. So we’ll do pip install -r requirements.txt. Once we’ve done that, we can run our project just like normal by doing python -m src to load the src module. There we go.
We have to do one additional step in order to be able to run tox. The tox configuration file we’ve been using is not configured properly for Windows. So I’ve opened the project here in Windows Explorer, and I’m going to edit the tox file. I’m just going to use Notepad for this, and we’re going to make two changes. First, we’re using Python 3.10, so we need to change our environment to use Python 3.10. And then in all of these commands, right now we’re using python3, and we’ll need to change these to python. Now bear in mind that both of these changes will mean that the project won’t work in its current form on Codio. So you may wish to create multiple tox.ini files and switch between the two or do something similar in order to keep track. One other change we’ll need to make to our tox configuration file on Windows is to specify the specific folders we want flake to check. By default, flake will try and check everything on our system, and that can take a long time. So here I’m going to put src and test at the end of the flake command in our tox configuration file. So that only checks these two folders within our project for style violations. So once I’ve made those changes, I will save the file in Notepad using File > Save, and then I’ll close that and go back to PowerShell.
With those changes made, the tox I should be able to run our tox plan using tox -r and see everything run. You’ll only need to use tox -r the first time to recreate your environment. Afterwards, just like on Codio, you can use tox to reuse an existing environment, which will make this command run much faster.
There we go. We’ve successfully set up Python on our computer so that we can run Python directly and we can use tox to test our files. At this point, we have everything we need in our virtual environment to run our project. And we can use any text editor we want to edit the source code. One thing we may wish to do is add a few additional items to our Git ignore file so that they won’t get committed to Git. You’ll notice that PyCharm creates a folder as well as the virtual environment. So let’s open up our Git ignore file and quickly add those two items to it. We can simply list any folder names we want to exclude in our Git ignore file. And then the next time we commit this to Git we won’t have those files included.
In future videos, I’m going to show you how to install the PyCharm and Visual Studio Code IDEs to work with this project.
Installing Java
YouTube Video
Resources
Video Script
In this video, I’m going to go over installing Java and Gradle on Windows. So I’ve already downloaded the Java Development Kit directly from the Oracle website. So I’m going to briefly double click to install that.
I’ll also install Gradle. However, Gradle does not come with an installer, it just has a ZIP file. So to install Gradle, we’re going to extract this ZIP file, and we’re going to extract it to the folder C:\Gradle. Once I’ve extracted the Gradle files, I’ll open up the Gradle folder, and then the bin folder. And I’m going to click up here in the address bar and copy that path. We need to add this path to our Windows path so that we can actually access these files in the search bar. If I start typing environments, it should give me an option to edit my system environment variables. So I’ll choose that option, then click environment variables. And then under system variables, I’ll find the path variable and choose Edit. And then I’m going to create a new entry and paste in that path.
Now that we’ve installed both Java and Gradle, we can actually run this project. To do that, I’m going to start by opening PowerShell. And then in PowerShell, I’m going to change directory to our project folder. Once here, I can type java -version to confirm the version of Java, and gradle -version to confirm the version of Gradle. If everything looks correct, I should be able to run Gradle run to actually build and run my project using Gradle. If everything works correctly, we should see our application pop up on our screen.
That’s all it takes to get Java and Gradle running on Windows. In the next video I’ll talk about how we can configure two popular IDEs, IntelliJ and Visual Studio Code, to work with this project.
Python IDEs
YouTube Video
Resources
Video Script
Now let’s look at a couple of common IDEs for Python and see how we can use those with the projects that we’ve already configured. For this example, I’m going to install both PyCharm and Visual Studio Code. So to do that, I’m going to begin by installing both of those IDEs. When you’re installing PyCharm, it does present you with a quite a few options that you can choose from. Depending on your particular setup, you may wish to check mark things such as updating your PATH variable, updating your Windows context menu, and associating the .py file extension with this tool.
When installing Visual Studio Code, you may also want to check out some options to add different menu items to your Windows Explorer context menu.
Let’s first take a look at PyCharm and see what it takes to open this project in that IDE. Once PyCharm is open, we can click the Open button to open the folder containing our project inside of the IDE. In the dialog, I’ll select the folder containing our project. This is the same one that we downloaded using Git earlier. We’ll also choose to trust the project, which will allow it to actually run the code that it contains.
When PyCharm first loads a project, it has to go through and scan and configure a lot of different things. So just be patient and watch the bar at the bottom of the screen as PyCharm gets everything set up for the first time. As PyCharm scans the project, it may find the virtual environment and set that as the Python interpreter. You can see that down here at the bottom of the screen, where it shows the Python version and the location of the interpreter. You can hold your mouse over to confirm that it’s working in the .venv folder, which is what we want. By selecting this interpreter, this will tell PyCharm to use that virtual environment and install all of the packages there.
Once PyCharm is done configuring, we’ll need to add a run configuration so that knows how to run our projects. To do that, we’ll go to the Run menu, and then choose Edit Configurations. Then we’ll hit plus and choose Python. And then here in the dialog, instead of a script path, I wanted to run a module. So I’ll click this drop down choose Module Name, enter source or src for the module, to match the name of our module in our Python project. And I’ll also set the working directory to the default, which is just the package directory itself. Then we can click OK. And now if we want to run the project, we can go to the Run menu and choose Run src and it will run that Python module directly from within Python. We can also choose the debug option to debug this, which is a really powerful tool that we can use directly in PyCharm.
PyCharm also includes a terminal that will load the default PowerShell terminal in Windows. However, it will not by default load the virtual environment. So we’ll have to remember to type .venv/Scripts/activate.ps1 to load the virtual environment before we run any Python commands directly within the terminal. That’s a quick update on how to use PyCharm with this project. There are many many more things that we can do in PyCharm, including configuring it to work with tox. However, we won’t cover those things in this video, but you can find lots of good documentation online.
Now let’s quickly look how we can open this project in Visual Studio Code. To do that, I’ll go to our Start menu and load Visual Studio Code. In Visual Studio Code, the easiest way to open a project is to go to the File menu and then choose Open folder. Here we’ll select our project folder, and it will open it in Visual Studio Code. Visual Studio Code will ask us to confirm that we trust the authors of this project so that it can run the code directly inside of it.
Once the project is loaded, we can go open one of our Python files, and that will cause Visual Studio Code to prompt us to install a few additional extensions. I’m just going to click the button that says Install to install the recommended extensions for Python. Once the Python extension is installed, you’ll need to allow it to select a Python interpreter. So I’m going to click that option and choose Select Python interpreter. Thankfully, Visual Studio code is smart enough to immediately detect our virtual environment. So I’m going to choose that as our interpreter for this project. Once I’ve done that, I can go back to my files and I should be able to see them using Python. Notice down here at the bottom, it will tell us which interpreter it’s running just like we saw in PyCharm.
To run this project, we’ll need to add a configuration, and we’re going to choose a Python module and enter the module src as the name of our module. That will create a launch configuration that looks like this, which gets stored in a JSON file. Once that’s been done, we can go to the Run menu and choose Start Run without debugging to actually run our Python project. And there we go. We see Visual Studio can now run our Python project. One other neat feature of Visual Studio Code is then when we open a terminal with the Python extension turned on, it will automatically know to activate our virtual environment. So it will take care of that for us. It’s a really neat feature that it has.
So there we go. There’s a quick overview of how to load both PyCharm and Visual Studio Code IDEs with these Python projects. If you have any questions, please feel free to let us know.
Java IDEs
YouTube Video
Resources
Video Script
In this video, I’m going to discuss how to install and configure two popular IDEs for Java to work with our projects. Those IDEs are IntelliJ and VS Code. First, let’s look at installing those two IDEs. I’ve already downloaded the installers, and so now I’m going to install both the IntelliJ IDE, and Visual Studio code. When installing IntelliJ, it gives you many different options that you may want to enable depending on how you’re using the tool. I’m going to enable adding it to the PATH, adding open folders project and associating the .java file extension.
When installing Visual Studio code, you may also want to check mark some options to add different menu items to your Windows Explorer context menu.
At this point, we can open up IntelliJ and configure it to work with our project. So I’m going to find IntelliJ on my start menu, and click it to open it. When you first load IntelliJ, it will ask you if you want to import any settings, I’m just going to choose do not import settings and click OK. Once IntelliJ is loaded, I’ll click the Open button to open our projects folder as a project in IntelliJ. In the dialog, I’ll select our project that we downloaded directly from Git. The first time we load the project IntelliJ will ask us if we trust the authors. I’m going to click trust projects so that it can actually execute it properly. Once we select that project, IntelliJ will go through and configure everything it needs for the project. This may take a few minutes, so just hang tight while it does this work.
Once IntelliJ has done indexing, we can add a run configuration so we can actually run our project. In the configurations, we’re going to choose the option for a Gradle configuration. And then we can put in the Gradle task that we want to run. A very simple gradle run task we can type run here. But we can also create additional run configurations for check, and for test, and for any other Gradle tasks that we want to run. With that in place, we can run our project using that run configuration. If everything works correctly, we should see our project appear on the screen. IntelliJ also includes the Gradle tab, which gives us direct access to a lot of our Gradle tasks and configurations here. That’s just a quick overview of how we can use IntelliJ with this project. There are many many more features available, but you can find out more about that by reading the documentation for IntelliJ.
Now let’s look at how we can use Visual Studio Code to load this project in java. To load Visual Studio Code. I’ll simply find it on the start menu and click it to open it. The easiest way to open a project in Visual Studio Code is to go to the File menu and then choose Open Folder. We’ll select our project folder, and click select folder to open it. When we first open a project in Visual Studio, it will ask us if we trust the authors. Since we wrote this project, we’ll go ahead and click yes so that we can fully work with this project.
Once we’ve opened the project, we can go to one of our Java source files to get Visual Studio to prompt us to install all of the extensions we need to work with Java. So we’ll click this install button to install all the recommended extensions for Java. Once the extension pack is finished installing, we can go back to our project. Once the extensions are installed, it will eventually scan through and find all of the Java Development Kit and initialize the workspace. As Visual Studio Code builds the project, it will give you a prompt to upgrade Gradle. Go ahead and click that because that will upgrade the Gradle that is bundled with this extension. If everything works correctly, eventually Visual Studio will be done building the project.
There’s one more extension we can install, which is the Gradle extension. The Gradle extension from Microsoft allows us to interface directly with Gradle in our code. When the Gradle extension installs, you may have to allow a few things through the firewall. With the Gradle extension installed, we can choose that option from the options over on the left and watch it as it goes through and parses our Gradle project and eventually presents us with all of our tasks. Once it’s done configuring, we should be able to expand the Tasks list for our different apps, and we’ll be able to see all of the different Gradle tasks that we can run. This is a great way to explore how Gradle works in your project.
Finally, we can also add a launch configuration directly to VS Code to run our Java code directly outside of Gradle. A launch configuration will look something like this with the main class put in here. You can configure these by going to the Run menu and choosing Add Configuration. That’s a quick overview of how to work with Java in Visual Studio Code. If you have any questions with any of this feel free to let us know