Hash Functions
A hash function converts a key into a hash code, which is an integer value that can be used to index our hash table array. Obviously, there are some hash functions that are better than others. Specifically, a good hash function is both easy to compute and should uniformly distribute the keys across our hash table array. Both of these are important factors in how fast our hash table operates, since we compute a hash code each time we insert or get a key-value pair from the hash table. If it takes too long to compute the hash code, we lose the benefits of having constant time insertion and retrieval operations. Likewise, if the function does not distribute the keys evenly across the table, we end up with several keys in the same bucket, which causes longer times to retrieve key-value pairs.
A good hash function should have three important properties.
- Uniform: the input values should uniformly map to the output range.
- Efficient: the hash function should be fast to compute.
- Deterministic: the hash function should always compute the same value for a given input.
Luckily, many modern programming languages provide native support for hash functions. Both Java and Python provide built-in hashing functions. These functions take any object and produce an integer, which we then use with the modulo operator to reduce it to the appropriate size for our array capacity. An example of how to use the Java hashCode function is shown below. More information on the Java hashCode function can be found here.
public int computeIndex(Object key){
return key.hashCode() % this.getCapacity();
}An example of using Python’s hash function is shown below. More information on hashing in Python and the hash function can be found here.
def compute_index(self, key):
return hash(key) % self.capacityAnother interesting use of hash functions deals with storing and verifying passwords. When we sign up for an account on a website, it asks us for a password that we’d like to use. Obviously, if that website just stored the password directly in their database, it could be a huge security problem if someone was able to gain access to that information. So, how can the website store a password in a way that prevents a hacker from learning our password, but the website can verify that we’ve entered the correct password?
In many cases, we can use a hash function to do just that. When we first enter our password, the website calculates the hash code for the password and then stores the result in the database.
Then, when we try to log in to the website in the future, we provide the same password, and the website is able to calculate the hash again and verify that they match. As long as the hash function is properly designed, it is very unlikely for two passwords to result in the same hash, even if they are very similar.
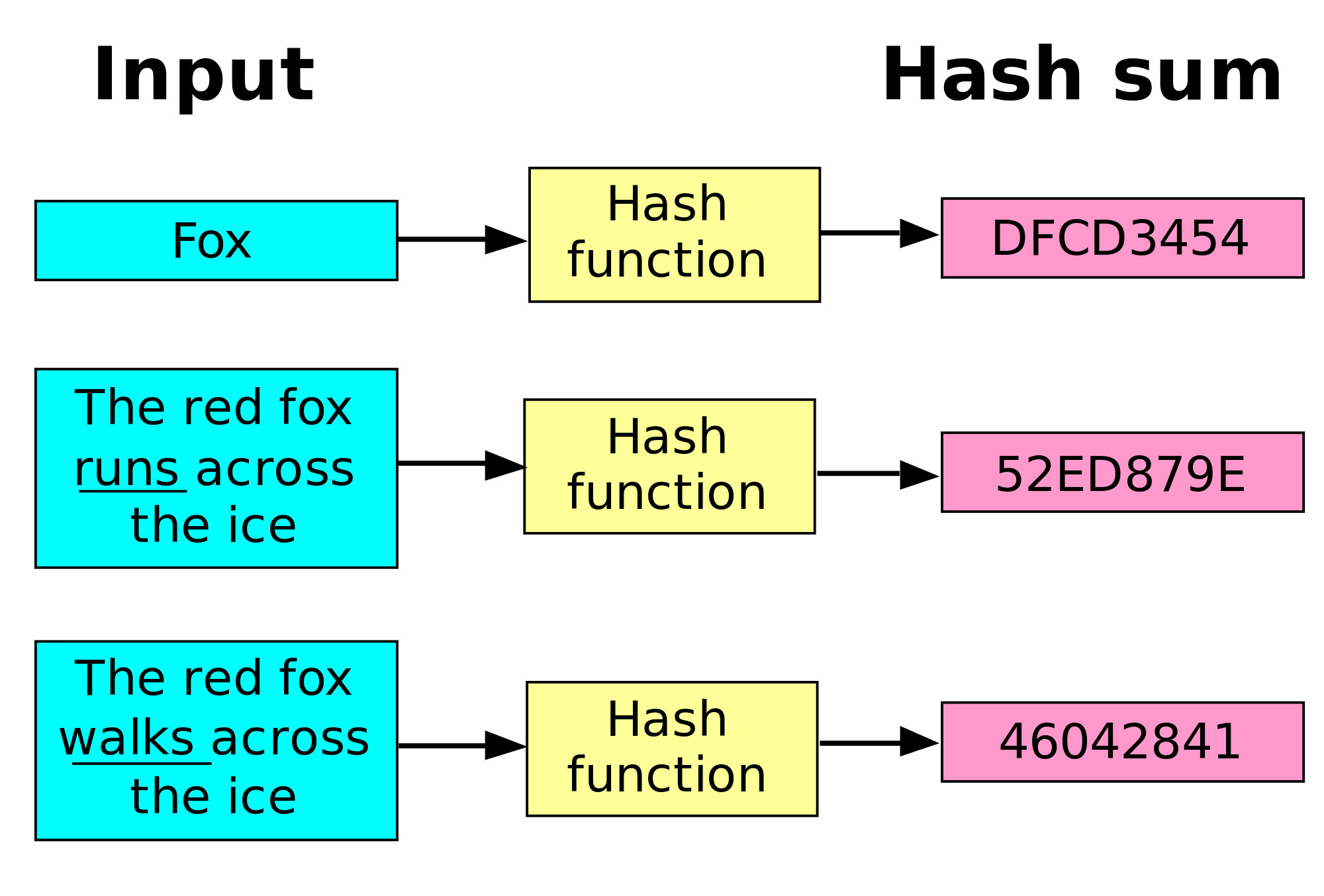
In practice, most websites add additional random data to the password before hashing it, just to decrease the chances of two passwords hashing to the same value. This is referred to as “salting” the password.
Keys
Keys allow us to easily differentiate between data items that have different values. For example, if we wanted to store student data such as first name, last name, date of birth, and identification number, it would be convenient to have one piece of data that could differentiate between all the students. However, some data are better suited to be keys than others. In general, the student’s last name tends to be more selective than the first name. However, the student identification number is even better since it is guaranteed to be unique. When a key is guaranteed to be unique, we call them primary keys. The efficiency of a key is also important. Numeric keys are more efficient than alphanumeric keys since computing hash codes with numbers is faster than computing them with characters.